
基于机器学习的阿尔茨海默病病程分类
2019-11-20 07:17:56范炤李彩
中国医学影像学杂志 2019年10期
范炤,李彩
1.山西医科大学转化医学中心,山西太原 030001;2.山西医科大学基础医学院,山西太原 030001; *通讯作者 范炤fanzhao316@163.com
阿尔茨海默病(Alzheimer's disease,AD)是一种起病隐匿、慢性神经系统的退行性病变,其病因及发病机制尚不清楚,且病情多样,目前临床诊断主要依靠对患者的 MRI图像分析以及神经量表评分判断病情,这种方式具有很强的主观性,耗时费力,且存在误诊的风险[1]。AD的进展是不可逆的,但治疗AD的早期阶段轻度认知障碍(mild cognitive impairment,MCI)可延缓病情进程[2]。因此,如何准确区分正常认知(normal cognitive,NC)、MCI和AD,早期诊断疾病处于哪个阶段,以便进行干预辅助治疗,在临床实践中至关重要。
支持向量机(support vector machine,SVM)是目前AD领域机器学习的热点,随机森林(random forest,RF)在很多领域表现出优势。目前针对NC、MCI、AD进行分类的研究较多,本研究以期识别更早期的MCI患者,将MCI进程分为早期轻度认知障碍(early mild cognitive impairment,EMCI)和晚期轻度认知障碍(late mild cognitive impairment,LMCI)。本文基于SVM和RF的方法,利用结构性磁共振(structural magnetic resonance imaging,sMRI)数据,分别构建AD病程分类预测模型,然后对这两种模型进行比较,选择出更好的AD分类模型应用于临床辅助诊断工具。
1 资料与方法
1.1 数据来源 本研究所用数据来源于美国大型 AD公共数据库 ADNI(Alzheimer Disease Neuroimaging Initiative)编号为4018~5210的数据。共543例受检者,其中NC组139例、EMCI组220例、LMCI组108例、AD组76例。选用数据库中Philips 3.0T MRI扫描仪的sMRI图像,成像参数:TR 6.8 ms,TE 3.1 ms,FA 9°,视野:L=204 mm/AP=240 mm/FH=256 mm,体素1 mm×1 mm×1.2 mm,层厚1.2 mm,共170层。数据库用 Freesurfer工具箱对 sMRI图像进行经空间标准化、图像平滑、分割、调制的预处理后,每一例受检者的 sMRI图像资料转化为 272个 sMRI数据,包括海马各亚区体积16个、皮层体积69个、皮层表面积70个、皮层下体积49个、皮层厚度68个。
1.2 特征提取方法 采用SPSS 22.0软件,首先对NC、EMCI、LMCI、AD 4组sMRI数据进行正态性和方差齐性检验。其次,若满足正态性、方差齐条件,采用单因素方差分析[3],将 4组间总体有统计学差异的数据,两组间再采用最小显著性差异检验[4]进行比较,其中有显著性差异的数据形成特征组的一部分,记为A。如果不满足正态性和方差齐性,则应用完全随机设计多个样本比较的 Kruskal-Wallis H检验[5],将 4组间总体有统计学差异的数据用多个独立样本两两比较的Nemenyi检验[6]进行组间比较,其中有显著性差异的数据组成特征组的另一部分,记为B。将A和B整合起来的特征作为训练模型的输入特征。P<0.05表示差异有统计学意义。
1.3 SVM和RF分类模型
1.3.1 SVM 分类模型 该模型广泛应用于临床分类诊断且表现出良好的效果[7],其目的是找到一个最优分类超平面,该超平面既满足分类要求,又能确保分类精度,还能满足超平面两侧的空白区域最大化。SVM的判定函数见公式(1)。
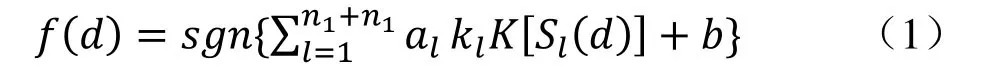
其中,sgn{}表示符号函数,Sl(d)表示特征选择后的特征集,d=1,2,3,…,28;yi∈{-1,1}表示样本类别,即代表NC与EMCI、NC与LMCI、NC与AD、EMCI与LMCI、EMCI与AD、LMCI与AD组的判别;K[ ]为核函数。
1.3.2 RF分类模型 该模型在处理高维非线性的生物数据方面有很大优势,有很高的预测准确率[8],在分类精度、泛化误差、算法强度等性能方面较决策树等单分类器有较大的提升[9]。RF的决策函数见公式(2)。
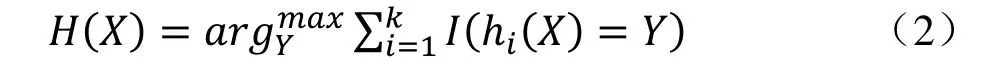
其中,H(X)为组合分类模型,hi为单个决策树的分类模型,Y为目标变量,经过k轮训练投票选出最多决策树支持的类别。
本研究选择 10-折交叉验证训练模型,可以确保小样本训练结果无偏差估计,从而确保测试精确度。即机器分类模型自动随机将两组待分类的数据分成10份,抽取其中9份组成训练集,剩余1份作为测试集,每次训练SVM、RF模型后都得到一个训练和测试准确率,重复10次,将10次训练和测试结果的平均值作为SVM和RF模型最终的分类准确率。用受试者工作特征(ROC)曲线得到的敏感度和特异度评价两种分类模型的分类效能,通过曲线下面积(AUC)评价SVM、RF分类准确率效果,AUC值越大,表示分类正确率越高。
机器学习算法流程(图1):①从ANDI数据库获取经预处理的sMRI数据;②282项sMRI经统计学分析选出特征集作为训练模型的输入特征;③采用函数映射,将 sMRI数据映射到[0,1],进行归一化处理;④将数据集进行 10-折交叉验证划分训练集与测试集,训练SVM和RF模型;⑤综合模型的准确率、特异度、敏感度、AUC值评价模型性能。
2 结果

图1 SVM和RF模型构建流程
2.1 特征选择结果 272项 sMRI特征值经统计学分析,获得有统计学意义(P均<0.01)的28项特征,包括左颞下回皮层体积、左颞上回皮层厚度、左侧脑室下角表面积、左海马CA2-3区体积、左海马下托回皮层厚度、右海马CA1区体积、右颞中回皮层厚度、左海马前下托体积、左杏仁核表面积、右颞下回皮层体积、左海马表面积、右内嗅皮层厚度、右海马CA4-DG区体积、右海马表面积、右颞下回皮层厚度、右侧脑室下角表面积、右海马前下托体积、左颞极皮层厚度、左海马CA4-DG区体积、右杏仁核表面积、右颞极皮层厚度、右海马CA2-3区体积、左内嗅皮层厚度、右内嗅皮层体积和左颞下回皮层体积。
2.2 SVM、RF分类模型结果 对4组(NC、EMCI、LMEI、AD)两两分类,根据10-折交叉验证进行分类预测分析,获得SVM和RF分类模型的准确率。基于28项sMRI特征的RF预测模型准确率均高于SVM(表1)。

表1 SVM和RF模型分类在不同组间的准确率比较(%)
SVM和RF高预测准确率均集中在NC与 AD组、EMCI与AD组和NC与LMCI组,其中RF和SVM分类器均在NC与AD组表现出最高的准确率,分别为96.45%和90.90%。RF和SVM在NC与EMCI组、EMCI与LMCI组均表现出较低的准确率,分别为65.28%和77.78%、81.82%和70.91%,其中RF和SVMNC与EMCI组准确率最低。
SVM、RF两种分类模型的分类效果比较见表2。RF分类模型的 AUC值在每一组分类模型中均最大(表2)。基于28项sMRI特征的RF分类器在NC与EMCI、NC与LMCI、NC与AD两两分类预测中整体表现优于SVM分类器。
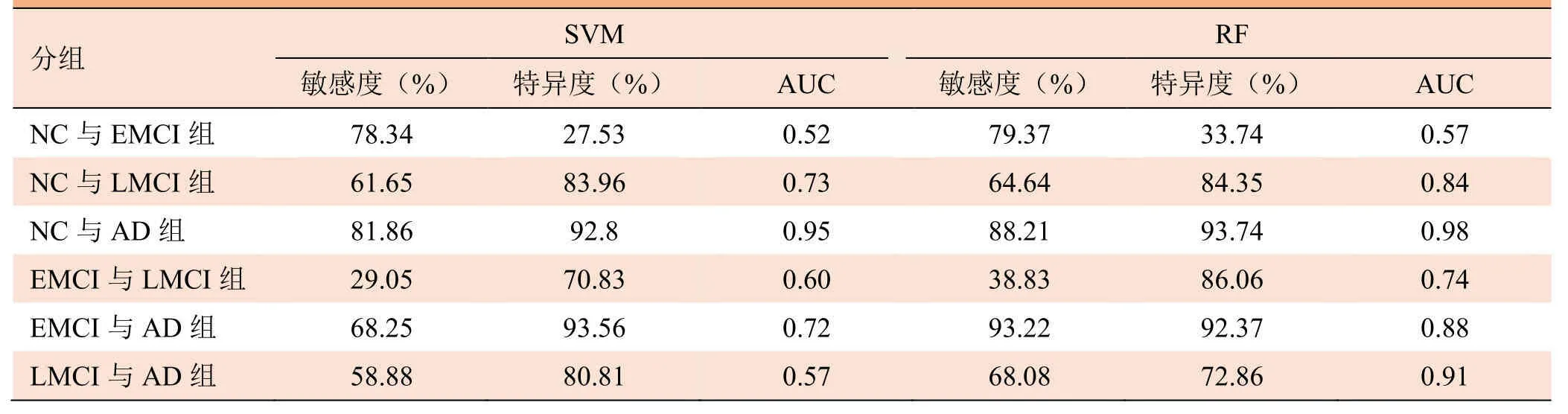
表2 SVM和RF模型分类效果比较
3 讨论
sMRI可检测出MCI患者早期局灶性萎缩,有研究[10]通过提取脑部特征用于AD、MCI的分类,如果使用全脑特征过于冗余,会影响分类效果[11],因此本文先对特征进行提取后再进行模型构建。特征提取在AD病程的临床诊断中有重要意义,仅检测观察对病情影响大的主要指标,剔除对病情影响微小的指标,不但能减少诊断程序、降低患者诊断经济成本和医院诊断的时间成本,还具有较好的分类预测效果,并且提供影响诊断的主要因素,为临床提供参考依据。
本文特征选取的指标与多数文献报道一致,其中杏仁核表面积、海马CA4-DG区体积、海马前下托体积、海马表面积、颞极皮层厚度、颞下回皮层体积、内嗅皮层厚度、海马下托体积、海马CA2-3区体积、颞下回皮层厚度、脑室下角表面积在左右半脑均有明显差异,表明这11对指标在疾病发展中变化明显,建议在临床观察中对上述指标进行全面分析,尤其是对比左、右脑的数值变化。同时,其余指标的明显变化发生在单侧大脑,建议临床上重点关注这些单侧指标的特异性变化,有助于准确诊断。
本研究通过构建SVM、RF模型,分别对NC与EMCL、NC与LMCI、NC与AD、EMCI与LMCI、EMCI与AD、LMCI与AD组进行分类识别预测。与SVM相比,RF在6组分类中,特别是对病情很相似的 LMCI、EMCI的分类预测中均表现更为优秀。有研究[12]应用不同的机器学习方法对NC与AD进行分类,准确率均低于本研究采用的RF对NC与AD分类的准确率(96.45%);还有研究[13-16]报道对NC与MCI、MCI与AD的分类准确率也低于本文应用RF分类模型的准确率。进一步得出,基于28项sMRI特征的RF分类预测模型可用于临床进行NC、EMCI、LMCI与AD的分类识别。本文提出的RF分类预测模型根据客观测量数据进行分类诊断,比现有的诊断依据即通过有经验的医师阅片观测判断更为客观、合理和准确。
RF和SVM分类模型在NC-AD组识别中预测准确率最高,其原因可能是正常老年人和AD患者脑部结构差异很大、认知功能、行为活动差异明显、易于识别。RF和SVM在NC与EMCI组、EMCI与LMCI组识别的准确率低于NC与AD组,其中NC与EMCI组分类识别中准确率最低,可能与EMCI和正常人难以区分,常被忽视有关。EMCI与LMCI组较低的预测率可能因为两组在多维信息上有差别,且无公认的理论解释这一现象。
sMRI是AD进行分类研究的基础,本研究后续将通过增加认知评价、人口统计学资料、正电子发射型计算机断层显像、功能磁共振成像、脑脊液检查等数据类型形成多模态数据,同时加大实验数据量,以获得更高精度、更稳定的分类器用于预测AD病程分类,以期延缓疾病进展,提高患者的生活质量,减轻国家和个人负担。
猜你喜欢
发明与创新(2023年30期)2023-10-11 01:37:12
小学生学习指导(高年级)(2023年3期)2023-03-31 06:03:22
作文周刊·小学二年级版(2022年20期)2022-05-05 01:33:06
小学生学习指导(高年级)(2022年3期)2022-03-29 07:49:16
中国现代医药杂志(2020年3期)2020-05-08 04:33:08
创新作文(小学版)(2019年10期)2019-09-25 08:12:28
中国生物医学工程学报(2019年6期)2019-07-16 07:52:48
小学生导刊(高年级)(2017年2期)2017-06-10 02:40:42
小学生学习指导(低年级)(2017年5期)2017-05-04 04:14:38
中外医疗(2016年15期)2016-12-01 04:25:39
