
Joinpoint回归模型及其在传染病流行趋势分析中的应用
2019-11-12 12:24广东省疾病预防控制中心广东省公共卫生研究院511430
中国卫生统计 2019年5期
广东省疾病预防控制中心 广东省公共卫生研究院(511430)
曾四清
时间序列数据趋势分析的经典方法包括移动平均模型、回归模型、差分自回归移动平均模型等,常用的回归模型包括线性模型、指数模型、对数模型等。传统回归分析主要反映全局数据总体趋势,可能无法揭示局部数据的特定趋势。因此,分段回归模型应运而生[1],但如何分段又成为新的问题。Kim等提出的Joinpoint Regression(JPR)模型提供了解决方法[2]。近年来,JPR模型在癌症和慢性病流行病学趋势研究领域得到广泛应用,主要用于分析发病率和死亡率时间趋势变化特征,也用于分析其年龄趋势、空间趋势、疾病负担,建立时空预测模型等[3-7];也有少数用于伤害、传染病等发病率和死亡率流行病学趋势变化研究,以及文献计量学研究等[8-12]。其分析结果可用于探讨疾病流行趋势变化规律及其影响因素,还可用于疾病预测、疾病负担和干预效果评价等[3-12]。本文主要介绍JPR模型的基本原理和分析方法、应用条件、分析步骤和实现程序,并以2014年广东省登革热大流行疫情为例进行分析,探讨该方法用于传染病大流行疫情时间趋势变化特征分析及预测方面的适用性,以便为相关专业人员正确选用该分析模型提供参考。
原理和方法
1.JPR模型的基本原理和分析方法
JPR模型分析的基本思想是通过模型拟合将一个长期趋势线分成若干有统计学意义的趋势区段,各段用连续的线性进行描述[2]。JPR模型分为线性数据模型和对数线性数据模型两类[13]。
假设有一序列观察值(x1,y1),…,(xn,yn),其中,x1≤…≤xn,线性数据模型表达式为:
E[yi|xi]=β0+β1xi+δ1(xi-τ1)++…+δk(xi-τk)+
(1)
对数线性数据模型表达式为:
E[yi|xi]=eβ0+β1 xi+δ1(xi-τ1)++…+δk( xi-τk)+
(2)
式中,yi(i=1,2,…,n)为因变量,xi(i=1,2,…,n)为自变量;β0表示不变参数,β1表示斜率参数(回归系数);δk=βn+1,1-βn,1表示分段函数的回归系数;τk为未知转折点,k为转折点个数,当(xi-τk)>0时,(xi-τk)+=(xi-τk),否则,(xi-τk)+=0。
进行JPR分析时,要解决三个关键问题[13-14],即选择模型类别,确定转折点数量、位置及模型参数,优选模型。
(1)模型类别选择基本原则和方法
如果系列数据样本量在100以上,经过分布一致性检验,因变量服从正态分布或近似正态分布,宜选用模型(1)分析;如果因变量服从泊松分布或指数分布,则选用模型(2)分析[13-14]。如果分布不明确,宜同时采用模型(1)和(2)进行预分析,比较二者的均方差(mean squared errors,MSE),选择MSE较小者为优选的拟合模型[13]。
(2)转折点数量、位置及模型参数分析方法
采用网格搜索法(grid search method,GSM),也可采用Hudson’s法,本文只介绍GSM。GSM是将参数所处的空间划分成网格,每一个交点对应一个规划方案,然后在设定的区间内以固定步长逐点计算对应方案的性能指标,以确定最优参数[1]。进行JPR模型分析时,GSM创建“转折点”全部可能位点的网格,计算每种情况下的误差平方和(the sum of squared errors,SSE)及MSE,选择MSE最小时的网格位点为最优转折点。JPR模型的回归系数β0、β1、δ1、…、δk等参数估计值均采用GSM计算。
(3)优选模型分析方法
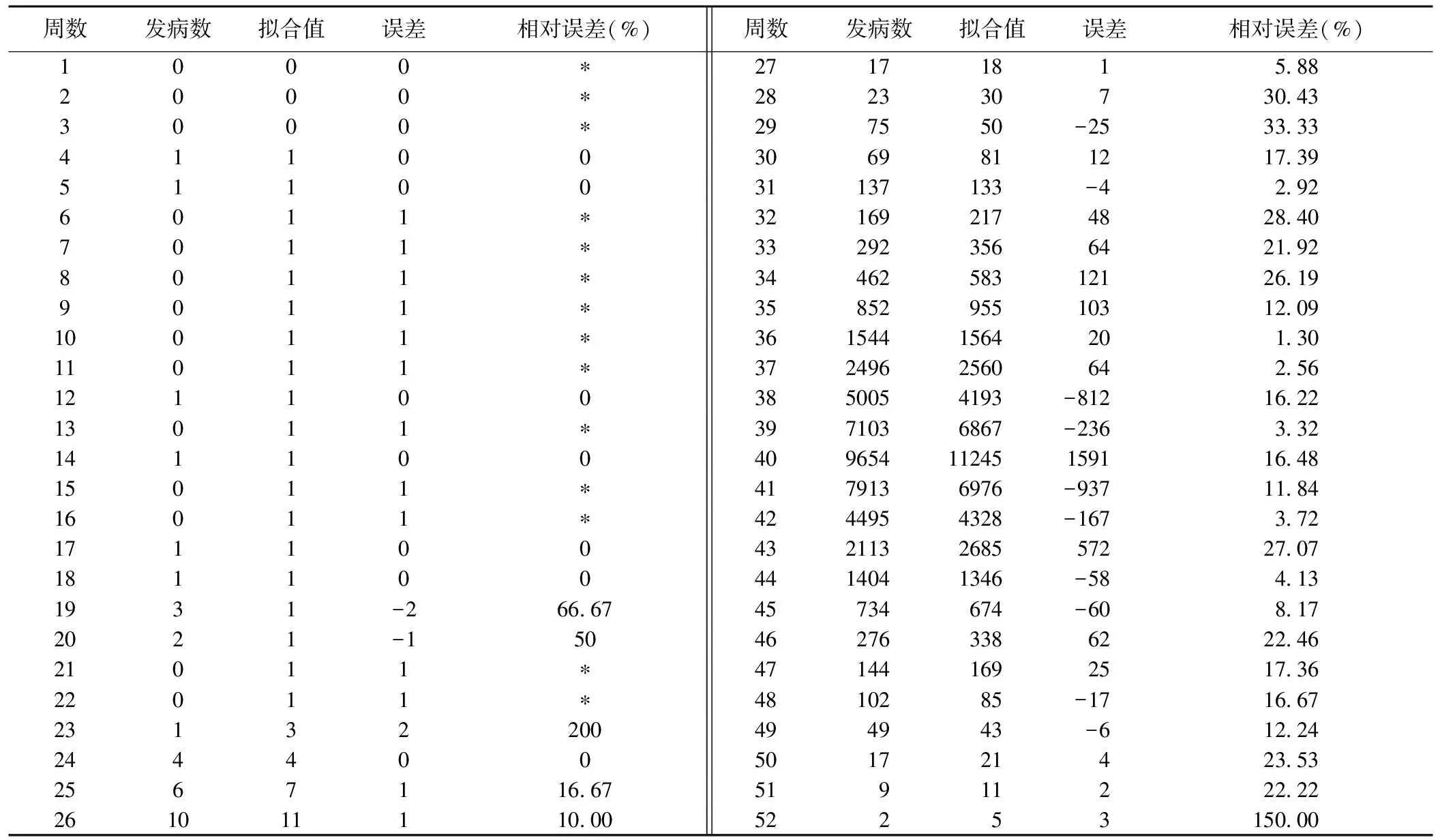
采用Monte Carlo置换检验(permutation test)、贝叶斯信息准则(Bayesian information criterion,BIC)或修正BIC方法(modified BIC,MBIC)。
①置换检验:基本原理是:设定转折点的最小值为MIN,最大值为MAX;无效假设H0设转折点个数为ka,备选假设H1设转折点个数为kb,其中ka 以线性数据模型为例说明如下[2]:假定某时间序列观察值(x1,y1),…,(xn,yn)最多有2个转折点。首先,无效假设 H0为没有转折点,即回归模型E[yi|xi]=β0+β1xi;备选假设H1为有2个转折点τ1和τ2(τ1<τ2),即回归模型E[yi|xi]=β0+β1xi+δ1(xi-τ1)++δ2(xi-τ2)+。如果经过统计学检验拒绝H0,再假设H0为有1个转折点τ1,即E[yi|xi]=β0+β1xi+δ1(xi-τ1)+;H1不变。如果经过检验不拒绝H0,H0不变;再假设H1为有1个转折点τ1,即E[yi|xi]=β0+β1xi+δ1(xi-τ1)+。这样经过多次置换检验,最后得出有统计学意义的转折点个数为1,回归模型为E[yi|xi]=β0+β1xi+δ1(xi-τ1)+。 进行置换检验时,如果对所有的拟合模型都直接进行全数据集计算,计算量大、耗时长。因此,采用随机数值生成器抽取Monte Carlo置换数据集样本进行简化计算,利用Bonferroni校正法设定多重检验的显著性水平[14]。 ②贝叶斯信息准则和修正贝叶斯信息准则[14]:有k个转折点的JPR模型BIC值计算公式如下: BIC(k)=ln{SSE(k)/#Obs}+{#Parm(k)/#Obs}×ln(#Obs),其中,SSE是误差平方和,#Parm(k)=2×(k+1)是参数个数,#Obs是观察值个数。 Zhang等[15]认为传统BIC计算公式存在一些问题,提出其修正公式如下: (3) 式中n为观察记录数,Γ(z)为gamma函数。 (4) BIC值或MBIC值最小时的模型即为最优模型。 (4)年度变化百分比和平均年度变化百分比及其可信区间的计算[14] JPR模型中,年度变化百分比(annual percent change,APC)的计算公式如下,其中β为回归系数。 APC={exp(β)-1}×100 (5) (6) (7) JPR模型中,平均年度变化百分比(average annual percent change,AAPC)的计算公式如式(8),其中wi为每个分段包括的年度数,βi为回归系数。 (8) (9) (10) 如果转折点为0,则AAPC=APC。 (5)预测精度评价 采用均方差(MSE)和平均相对误差绝对值(mean absolute percentage error,MAPE)衡量预测的精确度。 (11) (12) 2.JPR模型的应用条件和注意事项 (1)适用条件[14] JPR模型主要用于时间序列数据或其他有序数据的趋势变化特征分析。分析变量包括因变量、自变量,还可有分组变量。因变量数据类型包括:例数或“事件”数,如癌症病例数、死亡人数等;粗发病率或死亡率、年龄标准化发病率或死亡率;构成比、百分比;或其他类型的数值变量,如气温值等。因变量可以在数据文件中直接提供(如发病数、死亡数等绝对数),也可以由数据文件提供的数据计算获得(如发病率、标准化发病率、百分比、构成比等相对数)。自变量应是有序变量,最常见的是时间,如年度、月份等;也可以是其他有序观察值,如年龄等。可以对自变量进行重新编码,但编码必需是有序数值。若有分组变量,建立数据文件时必需先按分组变量进行排序才能正常分析。 如果需要比较两组系列数据的分段回归方程是否等价或趋势一致性,可选用JPR模型中的“成对比较分析”(pairwise comparison)方法;如果由于疾病/死因编码系统的改变等原因,引起监测数据发生系统性的“跃变”,但并不影响所研究“事件”的潜在变化趋势,可选用其中的“跃变”模型/可比性比例模型分析(jump model/comparability ratio(CR)model)方法[14,16]。 (2)注意事项 如果因变量观察值是百分比,就不能大于100%;当有因变量观察值为0时,不能直接计算,一般用“0.5”替换后再分析[14]。对因变量进行正态性检验时,Kolmogorov-Smirnov(K-S)检验法适用于样本量大于100的连续型计量资料的分布一致性检验;当样本量较小(小于100)时,不能直接使用其检验结果,应用Lilliefors修正临界值表加以判断[17]。 使用GSM时,需设定转折点数的最小值(0)和最大值(≤9)。GSM允许最大转折点数为9,但计算很耗时,一般设定不宜超过5;转折点不可以是起始观察值或末尾观察值的位置;两个转折点之间至少有1个观察值,转折点之间的观察值平均个数要在2个以上[14]。如果想得到一个转折点,序列数据至少应有7个观察值。 表1 观察值个数和默认最大转折点数关系表[14] JPR模型是分析序列数据有显著性意义变化的转折点、变化方向和速度的理想方法,但并不表明模型的拟合度最优[13]。在应用JPR模型时,其分析长期趋势结果较为可靠,分析短期趋势则会很大程度上受所分析的观察值个数影响。如果以年度为单位进行趋势分析,就无法揭示年度内短时间的变化特征和季节混杂因素的作用[8],但可以通过改变时间维度进行深入分析;粗发病率(或死亡率)的趋势变化不能直接反应人口构成对趋势的影响,因此仍需通过标准化法排除人口构成变化引起的趋势变化,或者按照年龄组分别进行趋势分析;同时,分析长期趋势时,还要考虑不同时期来源资料间的可比性问题[6]。 3.JRP软件和JPR分析步骤[14] (1)JRP软件(joinpoint regression program) JRP是美国国立癌症研究所(National Cancer Institute)开发的基于Windows 操作系统进行JPR模型分析的专用软件包,于2000年开始使用,2018年4月发布最新4.6.0.0版,可在“https://surveillance.cancer.gov/joinpoint/”网站免费下载安装使用。 (2)分析步骤 使用JRP软件进行JPR分析有五个基本步骤:创建数据文件、设置模型参数、运行程序、查看和选择输出结果,以及整理分析和解释结果。数据文件须是ASCⅡ文本文件或excel文件。可以使用SAS、SPSS、Excel、Word或其他软件(如SEER*Stat Software)创建的文件。Excel文件须转换为.CSV文件才可以使用。模型参数设置主要在“输入文件”(input file)模块设置因变量、自变量和模型类别等,在“方法和参数”(method and parameters)模块设置模型拟合方法(GSM)、最大转折点数和优选模型分析方法(BIC、MBIC、permutation test)等。在高级分析(advanced analysis tools)模块,可选择进行趋势“成对比较分析”(pairwise comparison)或“跃变”模型/可比性比例模型分析(jump model/CR Model)。 以2014年广东省登革热大流行疫情为例,进行周发病数的趋势变化特征分析及预测。 1.数据来源 资料来源于国家“传染病报告信息管理系统”,各周发病数见表2,全年发病数共计45188例。 2.分析过程及主要结果 采用excel 2013建立Dg2014.xlsx数据表和Dg2014.CSV数据文件,将其中“发病数”为“0”的值用“0.5”替代;采用SPSS 19.0软件对Dg2014.xlsx周发病数进行Lilliefors修正K-S检验,统计量Z=0.377,df=52,P<0.01,表明周发病数不服从正态分布,故采用JRP软件选择模型(2)对Dg2014.CSV周发病数进行趋势分析,最大转折点数设置为5。采用permutation test和MBIC进行优选模型分析时MSE分别为22.30(有2个转折点)、17.20(有3个转折点)。后者值较小,拟合精度优于前者,因此,采纳MBIC分析结果。拟合回归方程为:E[yi|xi]=e-0.757+0.055xi+0.438(xi-22)+-0.971(xi-40)+-0.213(xi-43)+。yi为周发病数,xi为周数,i=1~52,xi=1~52,如果(xi-22)+>0,则(xi-22)+=xi-22,如果(xi-22)+≤0,则(xi-22)+=0;如果(xi-40)+>0,则(xi-40)+=xi-40,如果(xi-40)+≤0,则(xi-40)+=0;如果(xi-43)+>0,则(xi-43)+=xi-43,如果(xi-43)+≤0,则(xi-43)+=0;MBIC=1.468。有3个有统计学意义的转折点将周发病数分成了4个趋势区段。转折点分别在第22周(95%CI:7~33)、第40周(95%CI:39~41)和第43周(95%CI:42~46)。在第1~22周期间,APC=5.64%(95%CI:-10.6%~24.8%,P>0.05);在第22~40周期间,APC=63.76%(95%CI:61.0%~66.6%,P<0.01);在第40~43周期间,APC=-37.96%(95%CI:-42.8%~-32.7%,P<0.01);在第43~52周期间,APC=-49.88%(95%CI:-52.9%~-46.6%,P<0.01)。结果见图1。 根据拟合方程进行周发病数预测,结果见表2,平均相对误差绝对值MAPE为17.05%。 JPR模型主要应用于时间序列数据或其他有序数据的趋势变化特征分析,主要采用网格搜索法、置换检验和贝叶斯信息准则等数理运算法则,进行疾病流行趋势变化拟合模型筛选和参数估计,分析趋势改变的转折点数量、确定转折点位置、明确变化方向、计算变化速度等特征[2,14]。因此,比仅根据常用数据列表和统计图直观描述疾病流行趋势变化更加科学。JRP软件为JPR模型运算提供了简便适用的程序包。 图1 2014年广东省登革热周发病数趋势变化JPR分析图 2014年广东省发生了登革热大流行疫情,总报告病例数超过4.5万例[18-19]。科学分析了解传染病大流行疫情的趋势变化特征和规律,将有利于相关部门及时采取有效的应对策略和干预措施,更好预防控制疫情发生发展。目前,国内对于登革热的流行病学研究,大多采用传统流行病学方法描述其三间分布[18-19];也有少数采用空间自相关和时空扫描聚类等分析方法进行病例时空聚集性研究,或采用SARIMA 模型及其与GRNN的组合模型预测登革热的月发病数等[20-21]。因此,采用JPR模型分析2014年广东省登革热疫情发生发展的时间趋势变化特征具有特殊意义。 结果显示,2014年广东省登革热大流行时的周发病数拟合JPR模型的MBIC、MSE和MAPE值均较小,而且在爆发期的预测精度较高,说明拟合模型基本有效,此类疫情对JPR模型拟合有较好的适用性。登革热周发病数的趋势变化有3个非常关键的转折点,即第22周(5月26日-6月1日)、第40周(9月29日-10月5日)和第43周(10月20-26日)。登革热的潜伏期为1~15d[22],分别将以上3个转折点时间往前推移一个最长潜伏期(按2周计),即是第20周(5月12日-18日)、第38周(9月15-21日)、第41周(10月6-12日),此三个时段应当是2014年登革热防控工作的关键时期。结果表明,如果不采取“早预防”措施,即使早期病例不多,也可能隐藏较大的疫情大流行风险;如果发展到疫情快速上升期,周发病数平均增长速度可达很高(APC超过60%),疫情进展将十分迅猛,极易形成爆发,控制难度加大,时间延续较长;经过采取全面有效的控制措施以后,疫情下降速度也较快(APC超过-30%)。而且,随着各项防控措施的持续全面深入开展,效果进一步显现,疫情下降速度加快(APC超过-40%)。可见,JPR模型对于揭示登革热大流行时有显著性意义的时间趋势变化特征,包括关键控制期、疫情变化方向和速度等是较理想的分析方法。虽然该模型的拟合度并不一定最优[13],但可以用于疫情趋势分析和预测,从而为防控工作提供重要参考。 表2 2014年广东省登革热各周发病数及拟合值比较(例) *:实际发病数为0,不能计算相对误差,也未列入平均相对误差绝对值计算。 JPR模型是一种较新的趋势分析方法,具有传统回归分析方法不具备的某些分析功能和特点[13,23];它可以用于分析某些传染病大流行期间的时间趋势变化特征和预测,其分析结果能为防控工作提供决策参考。因此,它在各种传染病流行趋势变化特征分析和预测中的应用价值值得深入探讨。在应用时,要充分了解其基本原理、分析方法、适用条件和注意事项,科学解释并合理运用其分析结果为传染病防控工作服务。




实例分析
讨 论

猜你喜欢
中国药房(2022年7期)2022-04-14
现代临床医学(2022年1期)2022-02-12
皮肤病与性病(2021年3期)2021-07-30
中国医药指南(2017年3期)2017-11-13
学生导报·高中版(2017年23期)2017-09-10
学生导报·中职周刊(2017年23期)2017-09-10
文理导航(2017年20期)2017-07-10
卷宗(2017年6期)2017-06-06
课程教育研究·新教师教学(2016年23期)2017-04-10
青春期健康(2016年6期)2016-07-21
