
压缩感知理论在小样本量蛋白质组学变量筛选研究中的应用*
2019-11-12 12:24哈尔滨医科大学卫生统计学教研室150081
中国卫生统计 2019年5期
哈尔滨医科大学卫生统计学教研室(150081)
张 薇 张秋菊 王玉鹏 谢 彪 孙 琳 高 兵 叶 倩 田 伟 侯小文 刘美娜△
【提 要】 目的 探索基于压缩感知理论变量筛选方法在小样本量蛋白质组学研究中应用的效果和特点,为小样本量的蛋白质组学的变量筛选提供更灵敏、可靠的方法。方法 模拟实验比较基于CS理论的变量筛选方法与偏最小二乘(PLS)及随机森林(RF)筛选变量的能力,通过灵敏度、特异度及平衡准确度评价其变量筛选效果;利用CS变量筛选方法筛选非小细胞肺癌两亚型组(腺癌和鳞状细胞癌)的差异蛋白。结果 模拟实验表明,CS理论的变量筛选方法在样本量较小时具有较好的变量筛选效果,灵敏度、特异度及平衡准确度均较高;利用基于CS理论的变量筛选方法筛选,获得肺腺癌和鳞状细胞癌间差异表达蛋白22种,被证明是肺腺癌和鳞状细胞癌间有差异的蛋白为:Cytokeratin 6A、Cytokeratin 6B、Cytokeratin 6C、PKP1、P63、MCT1。结论 基于CS理论的变量筛选方法在样本量特别少时,筛选变量的效果优于PLS和RF,更适用于小样本蛋白质组学数据变量筛选研究。
目前使用的蛋白质组学定量技术多以质谱为基础,主要分成两类:第一种是稳定同位素标记的定量蛋白质组学(如iTRAQ、TMT);第二种是非标记的定量蛋白质组学技术即label-free。通过质谱技术获得高维的蛋白质组学数据,可利用单变量或多变量等统计学分析方法筛选患者和健康对照之间的差异蛋白质。由于蛋白质之间的相互作用,单变量特征筛选方法(如t检验、ANOVA等)会忽略变量之间的相关性,损失重要的生物学信息,同时存在多重比较问题;目前常用的多变量特征筛选方法有偏最小二乘(PLS)、随机森林(RF)等,能够考虑到变量之间的多重相关性,但蛋白质组学的检测费用昂贵,尤其是当研究某些罕见疾病时,样本量通常很小 (有时样本量不足10),此时PLS、RF等方法筛选差异变量的能力可能受到限制[1]。因此本研究介绍一种基于压缩感知(compressive sensing,CS)理论变量筛选方法,通过模拟实验,比较基于CS的变量筛选方法和PLS、RF在小样本蛋白质组学数据变量筛选研究中的效果;并将该方法应用于实际数据,进行肺腺癌和鳞状细胞癌差异蛋白筛选。
CS原理与方法
1.CS理论简介
Candés和Donoho在相关研究的基础上于2006年正式提出了压缩感知的概念,为信号采集技术带来了革命性的突破[2]。CS理论的主要原理是只要信号在某个变换域是稀疏的,就可以用一个与变换基无关的测量矩阵将稀疏的高维变换域信号投影到低维空间,通过优化求解从低维空间以高概率重构出原信号,极大地降低了存储空间和计算复杂度。
CS理论将信号采样与压缩相结合,在信号处理领域应用广泛。Wang A等人将可配置的节能压缩感知结构应用于人体传感网络,解决了人体传感网络应用中无线电通讯部分耗能大的问题[3];在雷达信号处理方面,Tivive FHC等人提出了一种基于多重测量向量压缩感知模型的复值信号压缩感知方法,并将其应用于压缩传感穿墙雷达成像问题[4];在医学上压缩感知理论用于核磁共振成像,降低噪声信号干扰[5],也用于CT断层扫描以缩短扫描时间,降低辐射剂量[6]。
2.基于CS理论的变量筛选方法
(1)基于CS理论变量筛选的基本思想
CS的主要思想是从线性测量y=Aω中重构未知向量ω,在高维蛋白质组学中,A∈Rn×d是由包含n个样本和d个变量的高维蛋白质组学质谱数据构成的测量矩阵,y∈Rn为由n个样本的应变量测量值组成的向量,通过测量矩阵A和测量值y重构向量ω。
现阶段CS的重构算法大致可以分为以下几类:第一类是贪婪迭代算法,该类算法基本原则就是通过迭代的方式寻找稀疏向量的支撑集,并使用受限支撑最小二乘估计来重构信号,计算速度快但是需要的测量数据多且精度低;第二类是凸优化算法,这类方法通过将非凸问题转化为凸问题求解找到信号的逼近,其中最常用的方法为基追踪算法,该类算法计算速度慢,但需要的测量数据少且精度高;第三类算法是基于贝叶斯框架提出的重构算法,该类算法考虑到了信号的时间相关性,特别是当信号具有较强的时间相关性时,能够提供比其他重构算法更优越的重构精度[7]。本研究的目的是利用CS理论筛选两组之间差异表达的蛋白质,未涉及时间相关性问题,且蛋白质组学研究中样本量通常是非常小的,所以选择凸优化基追踪算法作为本研究的CS重构方法。
CS方法的先验信息是假设向量ω是稀疏的,即其中大部分元素值为0,或者特别小,当样本量n远小于变量数d时,用基追踪方法求y=Aω的最稀疏解ω:
(1)
随着CS及其相关领域研究的发展,新的算法如核范数最小化、1-bit压缩感知等相继被提出,这些方法在理论研究和真实数据研究方面效果都非常好。其中1-bit压缩感知将测量值y进行分类化,研究应变量为二分类的问题,只保留其符号信息:
yi=sign(〈ai,ω〉),i=1,…,n
(2)
其中a1,…,an∈Rd是测量矩阵A∈Rn×d每一个样本的各变量值组成的向量。
(2)基于CS理论筛选变量的步骤
原始数据的样本量为n,每个样本预处理后蛋白质组学质谱数据xi∈Rd,i=1,…,n由其d个变量相应的强度值组成的向量进行归一化、平滑化及标准化得到,已知每个样本的分类标签yi∈{-1,+1},i=1,…,n。基于CS的变量筛选方法实际上就是要重构出能够将两组正确分开的稀疏向量ω,并找到其中非零元素所在位置的集合。
①对原始质谱数据进行预处理,包括归一化、平滑化及标准化,得到预处理后蛋白质组学数据xi∈Rd,i=1,…,n;

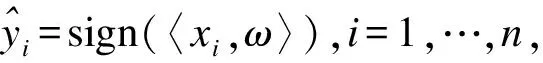

(3)

上述过程可以用Matlab软件实现。
模拟实验
构建具有相关性的差异变量,加入一定数目的噪声变量,设置不同的样本数,考察基于压缩感知理论变量筛选方法的筛选效果,同时与常用方法PLS及RF进行比较,因为这两种方法是目前高维组学进行变量筛选常用的方法,筛选出的变量有重要性排序[8],在与本研究的变量筛选方法利用平衡准确度比较筛选变量的效果时更有可比性。
1.模拟实验条件设置
设置模拟数据的总样本数分别为N=6,8,10,12,18,24,30,病例组和对照组的样本量相等;样本中总变量数为1000,差异变量比例设为3%、5%、8%、10%;变量之间的相关性设为0.2、0.4、0.6、0.8。不同差异变量比例及变量之间相关性进行组合,抽取符合多元正态分布的数据组成模拟数据,每种情况重复100次,分别利用基于CS的变量筛选方法、PLS和RF进行变量筛选,计算每种方法在各种差异变量比例与变量相关性组合的情况下筛选变量的平均平衡准确度(平衡准确度=(灵敏度+特异度)/2)。
2.模拟实验结果
不同差异变量比例与相关系数的组合有很多,以p=50为例,不同相关系数条件下三种方法筛选变量的效果比较(图1)和以r=0.4为例,不同差异变量比例条件下三种方法筛选变量的效果比较(图2)如图所示。结果显示:在样本量较小时,基于CS理论的变量筛选方法筛选变量的效果均为三种方法中最优,其次为PLS,RF最差,不同差异变量比例以及相关系数条件下均得到同样结果;尤其是当样本量N≤12时,基于CS理论的变量筛选方法优势更为明显;随着样本量增加,其变量筛选效果与PLS越来越接近。

图1 p=50为例,不同相关系数条件下三种方法筛选变量的效果比较

图2 r=0.4为例,不同差异变量比例条件下三种方法筛选变量的效果比较
实例应用
实例数据分析中,使用的是ProteomeXchange数据库中的PXD002622数据集,用于非小细胞肺癌的两种亚型(腺癌和鳞状细胞癌)间的差异蛋白质筛选研究。其中腺癌(ADC)和鳞状细胞癌(SCC)患者各3例,采集患者组织学样本,利用TMT标记定量蛋白质组学技术及MaxQuant软件,鉴定出51001个多肽和7241个蛋白质。将基于CS理论的变量筛选方法应用于上述数据,阈值设为0.09,筛选出22个ADC和SCC之间的差异蛋白质,表1为其相对应的蛋白质名称。

表1 筛选出的22个差异蛋白质鉴定结果
P63是一种肿瘤蛋白,在Terry J等[9]的研究中,用单个生物标志物区分ADC和SCC时,P63是最有意义的(灵敏度为84%,特异度为85%);PKP1为血小板亲和蛋白1,Schwarz J等[10]认为它是SCC中的特异表达标志物,其表达水平与癌症的恶性程度成反比;Cytokeratin 6A、Cytokeratin 6B、Cytokeratin 6C是常用的肿瘤免疫组织化学标记物,在本研究中ADC和SCC之间的表达差异与Terry J等[9,11-13]研究的结果一致;MCT1为单羧酸转运蛋白1,是一类跨膜转运蛋白,涉及多种生物学功能,包括促进营养物质吸收、影响代谢动态平衡、调节胞内pH值以及参与药物输送等,Stewart PA等[14]认为MCT1可能是腺癌和鳞状细胞癌的潜在诊断标志物及药物治疗靶向蛋白。
讨论与结论
本方法不仅能应用于蛋白质组学数据,对于具有相似数据结构的其他具有小样本量(尤其是N≤12当时)的高维组学数据(如转录组学、代谢组学等)的差异变量筛选也具有一定的应用意义,为小样本量高维组学数据的研究提供了新思路。
本研究基于CS理论的变量筛选方法的核心是解决一个有约束的最优化问题,本文的约束条件使用的是L2范数,实际上也可以根据分析需要,使用L1范数或L1范数与L2范数结合的约束条件对本方法进行优化。
本文模拟小样本量蛋白质组学变量筛选研究,在样本量小时(尤其是当N≤12时),基于CS的变量筛选方法筛选差异变量的能力优于PLS和RF,随着样本量增加,其变量筛选效果逼近PLS,在不同的差异变量比例及相关系数条件下结果一致。模拟实验为了验证小样本量时三种变量筛选方法的效果,设置的最大样本量为30,所以当继续增大样本量时本方法与PLS的优劣还需要进一步研究。
本文用基于CS理论的变量筛选方法分析了非小细胞肺癌数据,筛选出的差异蛋白集合中变量数目少,同时又包含了Cytokeratin 6A、Cytokeratin 6B、Cytokeratin 6C、PKP1、P63、MCT1等已经被验证是ADC与SCC之间差异表达的蛋白质。其中Cytokeratin 6系列是常用的肿瘤免疫组织化学标记物;PKP1为血小板亲和蛋白,与表皮的形态形成有关;P63是肿瘤蛋白63,由一段结合转录激活剂或抑制剂的特异DNA序列翻译而来;MCT1为单羧酸转运蛋白1,是一类跨膜转运蛋白,涉及多种生物学功能,包括促进营养物质吸收、影响代谢动态平衡、调节胞内pH值以及参与药物输送等。
猜你喜欢
心理学报(2022年10期)2022-10-12
昆明医科大学学报(2022年3期)2022-04-19
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
内蒙古统计(2021年4期)2021-12-06
昆明医科大学学报(2021年4期)2021-07-23
智慧健康(2021年33期)2021-03-16
天津医科大学学报(2021年1期)2021-01-26
中国生殖健康(2020年7期)2020-12-10
中国卫生统计(2019年3期)2019-07-10
