
改进型基于LSTM的股票预测方法
2019-11-06 09:30韩星煜
安徽大学学报(自然科学版) 2019年6期
方 红,韩星煜,徐 涛
(1.上海第二工业大学 文理学部,上海 201209;2.伦敦大学学院 计算机科学系,伦敦 WC1E 6BT;
股票市场是一个高度复杂的非线性动力系统,影响其波动的内部因素及外部因素众多且多数难以量化.同时,与股票相关的信息及数据量十分庞大,使得传统的非人工智能的方法在股票价格预测上往往不尽如人意.随着人工智能及大数据技术的发展,涌现越来越多的机器学习算法,如决策树[1]、遗传算法[2]、支持向量机[3]、逻辑回归[4]及深度学习网络模型(如卷积神经网络(convolutional neural networks,简称CNN)[5]、循环神经网络(recurrent neural network,简称RNN)[6]及长短时循环神经网络(long short-term memory,简称LSTM)[7])等.其中,LSTM克服了RNN随着时间推移会忘记之前状态信息的缺点,具备适合处理和预测时间序列中间隔和延迟较长的重要事件的特性,近年来在众多领域,包括语音识别、文档识别、手写识别及图像分析中得到广泛应用[8-9].文献[10]将LSTM与18种经典模型进行上证综指波动率预测结果对比,实验表明LSTM在预测上具有明显优势.然而,作为时间序列预测模型的一种,LSTM在股票预测中仍以历史数据输入为主,因此普遍存在滞后性问题.论文针对这种滞后性,分别通过多维向量输入、特征工程及情感分析3个步骤改进LSTM预测方法,在输入变量和特征方面进行筛选,优化模型输入,降低因输入历史数据造成的滞后性,同时提升模型预测效率,提高模型预测精度.
1 LSTM的结构及计算原理
LSTM是一种特定形式的RNN,而RNN在处理长期依赖即时间序列上距离较远的节点时会遇到梯度消失或梯度膨胀的问题,而LSTM采用控制门的机制,通过增加记忆细胞、输入门、遗忘门和输出门,使得自循环的权重非固定,从而在模型参数固定的情况下,不同时刻的积分尺度发生动态改变,避免了梯度消失或膨胀现象.图1为LSTM的结构示意图.
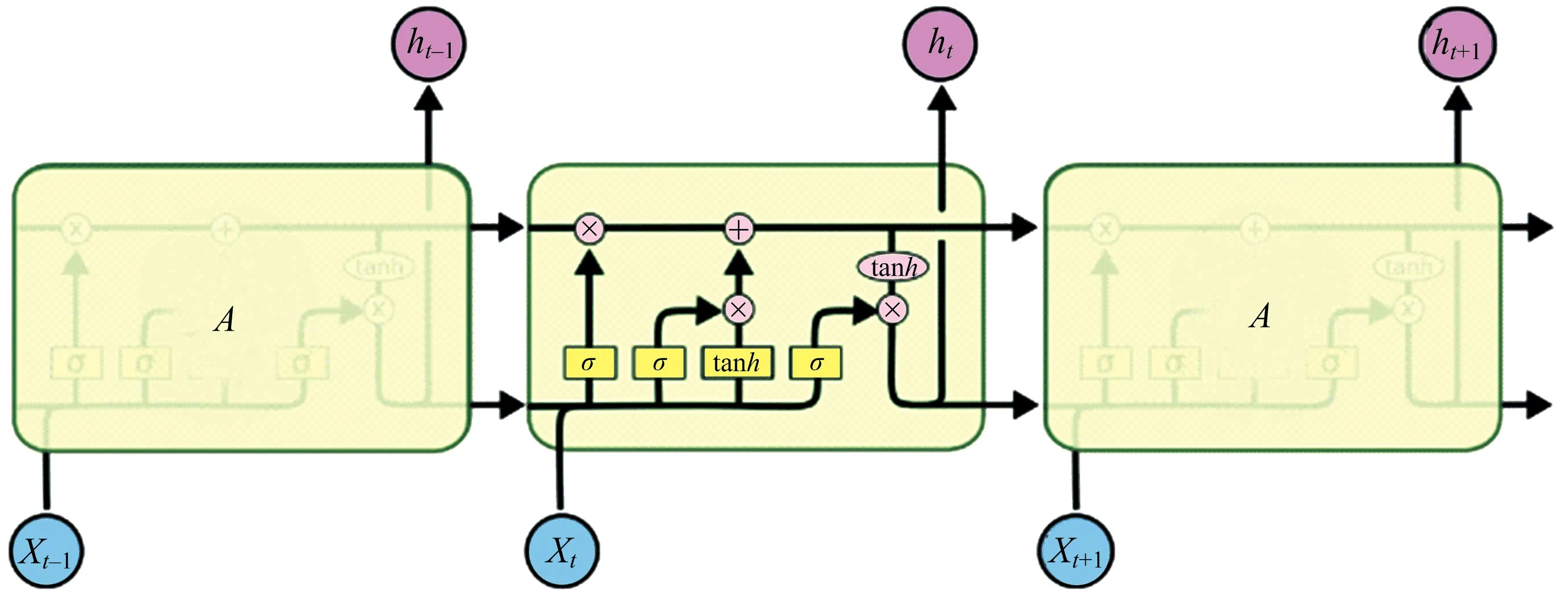
图1 LSTM结构示意图
(1) 细胞状态
LSTM在每个序列索引位置t时刻,除了向前传播隐藏状态ht,还增加了另一个隐藏状态即细胞状态,记为Ct,如图2所示.

图2 LSTM的细胞状态
(2) 输入门、遗忘门及输出门的计算原理
LSTM在每个序列索引位置t的门包括遗忘门、输入门和输出门.输入门负责处理当前序列位置的输入,共由两个部分组成:第一部分使用了sigmoid激活函数,输出为it;第二部分使用了tanh激活函数,输出为at.公式如下
it=σ(Wi*ht-1+Ui*Xt+bi),
(1)
at=tanh(Wa*ht-1+Ua*Xt+ba),
(2)
其中:Wi,Ui,bi,Wa,Ua及ba为线性关系的系数和偏倚;σ为sigmoid激活函数.
遗忘门在LSTM模型中的作用是通过一定的概率控制是否遗忘上一层的隐藏细胞状态.t时刻遗忘门的激活值ft公式如下
ft=σ(Wf*ht-1+Uf*Xt+bf),
(3)
其中:Wf,Uf,bf为线性关系的系数和偏倚.
根据输入门和遗忘门的计算结果可以得到t时刻的细胞状态更新值Ct,公式如下
Ct=Ct-1*ft+it*at.
(4)
由细胞状态更新值可以计算输出门的值,公式如下
Ot=σ(Wo*ht-1+Uo*Xt+bo),
(5)
ht=Ot*tanh(Ct),
(6)
其中:Wo,Uo,bo为线性关系的系数和偏倚.
通过以上的计算,LSTM 就可以有效利用输入来使其具有长时期的记忆功能.
2 基于LSTM的股票价格预测方法
2.1 预测流程
以预测腾讯公司股票的每日收盘价为例,给出基于LSTM的预测股票价格的流程及实现.基于LSTM的股票价格预测方法通过学习历史数据,找到股票每日收盘价和输入变量的非线性关系,并将这个非线性关系代入到用于预测的输入数据,得到未来的收盘价.预测流程如下:
(1) 收集腾讯公司股票收盘价的历史数据,确定训练集及测试集数据;
(2) 将训练集的股票前一天收盘价作为输入向量,第二天的收盘价作为目标值输入LSTM模型;
(3) 训练模型并对测试集数据进行预测.
论文将腾讯公司2016年3月29日至2018年3月29日的每日股票收盘价(休息日除外)用于训练与预测,其中,前400天的数据作为训练集,其余数据作为测试集.预测结果的评价指标为:
2.2 预测结果及分析
将测试集收盘价的预测值和真实值显示在图3中,其中蓝色曲线为真实值,红色曲线为预测值.输出结果为acc=0.027,lag=51.

图3 预测结果(单维度输入)
观察图3可见:在准确度方面,部分日期(第0~20天)的预测值和真实值偏差较大;在滞后性方面,预测值曲线与真实值曲线明显存在“延后平移”,即预测结果的变化往往落后于实际的变动,滞后性明显.
3 改进型基于LSTM的股票预测方法
由上文可知,基于LSTM的股票价格预测在精确度和滞后性方面有较大提升,主要原因是公司股票的收盘价不仅与其自身的历史数据有关,还可能与其他诸多因素有关.从内部因素考虑,公司内部的管理层结构、公司政策变化、主要持股人股份变动、公司财报等都可能影响投资者的投资策略,从而对股票价格产生影响;从外部因素考虑,宏观经济运行情况、相关竞争者和合作者的行为、新闻舆情等也会影响到股票价格.基于LSTM的股票价格预测,需要输入以“天”为单位的数字形式的数据,对于以上提到的诸多影响因素,不适合作为预测的数据来源.论文主要考虑与其具有投资或合作关系的公司及新闻舆情等方面的因素,来进行预测方法的改进.
3.1 多维度向量输入
仍以腾讯公司股票价格预测为例. 采用统计指标相关系数r来确定哪些公司的股票价格与腾讯公司的股票价格有着高度的相关性,r的取值范围为-1~1,越接近1,说明正相关性越高.
需要计算相关性的数据有以下几种: 投资腾讯的公司,有数据来源的主要是摩根大通公司; 腾讯投资的公司,主要有58同城、阿里影业、京东等; 腾讯平台概念股, 指与腾讯有合作关系的公司,主要有常山北明、信息发展、安妮股份等.将上述公司历史股票收盘价与腾讯的历史收盘价按日期一一对应,分别形成两个数列,采用SPSS统计分析软件计算相关系数,并给出了显著性水平p.当p不大于0.05时,相关性系数具有显著性意义.将得到的正相关性从高到低排列前3名分别为:摩根大通公司,0.898;京东,0.887;华南城,0.734.表1展示了部分公司的相关性计算结果,对应公司分别为摩根大通、京东、华南城、阿里影业、信息发展、常山北明、58同城、安妮股份、掌趣科技、中青宝和乐居.

表1 相关系数计算结果
以摩根大通公司为例,给出其与腾讯历史股票价格的变动示意图4.为了更方便地显示其相关关系,纵轴采用对数坐标.

图4 股票价格相关性示意图
由图4可见,蓝色曲线为腾讯收盘价的对数值变化,红色为摩根大通公司收盘价的对数值变化,两条价格对数曲线具有较为一致的变化趋势.
将上述3家公司从2016年3月29日至2018年3月29日的每日股票收盘价与腾讯自身的收盘价作为4维输入向量,同时输入LSTM模型用于训练与预测.前400天的数据作为训练集,其余数据作为测试集,得到的预测准确度和滞后性均有改善.输出结果为acc=0.023,lag=12.如图5所示.

图5 预测结果(多维输入)
3.2 特征工程
特征是数据中抽取出来的对结果预测有用的信息,特征工程的主要用途在于寻找到更有利于任务实现的特征.通过对特征进行选择,消除不相关或者冗余的特征,减少特征维度,提高算法的精确度,同时降低了程序运行所需要的时间.
基于LSTM的股票预测应用存在滞后性,其原因主要在于输入的数据均为前一天的股票价格数据.在模型训练过程中发现,当处理这些数据的神经元权重达到很高的水平以后,训练误差会降到很小的水平,导致训练好的神经网络算法实际上变成了“平移过去的数据”.论文考虑股票的每日收盘价与当日的开盘价、最高价、最低价也存在相关,因此把当日数据也作为输入的特征向量,使得参与输入的前一天数据对应的权重就变小,从而降低预测的滞后性.
将摩根大通、京东、华南城前一天的股票收盘价和腾讯当天的开盘价、最高价、最低价作为6维输入向量,前400天的数据作为训练集,其余数据作为测试集,运用LSTM进行训练与预测,准确度和滞后性进一步得到改善.输出结果为acc=0.016,lag=-108.如图6所示.

图6 预测结果示意图
3.3 新闻情感分析
新闻舆论是影响股价的重要因素之一,它影响着投资者的决策,因此也应作为特征之一.舆论的量化分析需要情感分析技术.论文利用网络爬虫程序爬取新浪财经网站与腾讯公司有关的新闻文本,并运用已有的新闻文本分析工具——“腾讯文智”对爬取的新闻进行情感分析,得到每日新闻的情感得分值Q.Q=正面分数-负面分数,且Q越接近100,说明情感倾向越正面,Q越接近-100,说明情感倾向越负面.图7为运用“腾讯文智”进行新闻情感分析图.

图7 运用“腾讯文智”进行新闻情感分析图
将摩根大通、京东、华南城前一天的股票收盘价,以及腾讯当天的开盘价、最高价、最低价即腾讯公司前一天的情感得分值等作为7维输入向量,前400天的数据作为训练集,其余数据作为测试集,运用LSTM进行训练与预测,再次改善了预测准确度和滞后性.输出结果为acc=0.010,lag=-189.如图8所示.

图8 预测结果示意图(增加新闻情感分析)
部分测试集预测值与实际值的数值对比见表2.

表2 部分测试集预测值与实际值对比 股
4 结束语
论文针对基于LSTM进行股票预测普遍存在的滞后性问题,通过问题成因分析,采用多维度向量输入、特征工程及新闻情感分析3个步骤,对模型输入变量及特征进行评价及筛选,优化模型输入,提升模型效率.腾讯公司股票的预测结果表明,该方法在滞后性和准确度方面均得到显著改善.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
四川工商学院学术新视野(2021年3期)2021-11-05
股市动态分析(2018年21期)2018-06-07
股市动态分析(2017年40期)2017-11-01
股市动态分析(2017年22期)2017-06-19
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
时代金融(2016年29期)2016-12-05
股市动态分析(2016年32期)2016-10-25
