
借用“平行宇宙”的算力
——量子计算现状与展望
2019-10-30 05:31:42李亦超
自然杂志 2019年5期
李亦超
深兰科学院,上海 200336
1 量子计算的诞生
19世纪末,欧洲物理学家们普遍保持着一种乐观的态度,认为物理学的理论大厦已经落成,所剩给后人的只是一些像确定参数等修饰性的工作。在一次年会上,英国著名物理学家威廉·汤姆生(开尔文男爵)在肯定了物理学的完善后,敏锐地提到:“物理学美丽而晴朗的天空现在被两朵乌云笼罩了。”
当时的开尔文男爵自己也不会想到,他所说的两朵乌云恰恰促进了人类物理学的两次大突破。第一朵“乌云”,迈克耳逊-莫雷实验与“以太”说的破灭,这直接导致爱因斯坦提出了著名的相对论;第二朵“乌云”,热学中能量均分理论与实验不符,这推动一众天才们建立了量子力学。
一提到“量子力学”,大多读者会紧锁眉头,觉得这个过于深奥的学科和自己的生活毫无关系,就让那些外表木讷、专注宇宙奥秘的物理学家研究去吧!其实,我们日常使用的电脑和手机里的零件,如晶体管、激光蚀刻技术都是在量子力学理论指导下才在实验室中被设计、生产出来的,直到现在形成了成熟的产业,彻底改变了我们的生活,这便是所谓的“第一次量子革命”。在今日,如何发展新的量子技术是各个国家及联合体,包括中国、欧盟、美国、日本、英国、加拿大等科学团体的主要目标之一。力图将理论的成果转化为应用并实现“第二次量子革命”,这便引出了我们今天的主角——量子计算。
2 经典计算机和量子计算机的区别
在现在这个信息爆炸的时代,几乎人人都有高性能的手机和计算机,其中最重要的核心元件就是作为计算处理器的芯片。电脑芯片上的晶体管数量遵守着一条众所周知的摩尔定律:每18个月就翻一倍。电子计算机前50年的发展情况与摩尔定律的预测十分接近,但随着电子元件集成工艺的技术和成本越来越高,集成电路的发展进度已愈发显出疲态。另外,当电子元件的尺寸达到纳米级别时,量子效应将越来越明显,电子的隧穿效应会导致回路失灵。科学家预测,到2025年摩尔定律将不再奏效,因此,人们将目光逐渐投向了量子计算机。
目前,公认的量子计算机想法的提出者是1981年诺贝尔获得者物理学家 Richard Feynman。他在一次演说中指出:当使用使用经典计算机处理一些原子分子问题出现计算量大的困难时,也许可以“用量子机器解决量子问题”。那么经典计算机和量子计算究竟有何不同呢?
比特(bit)是经典计算机和信息论中最基本的概念之一,一个比特代表了一个基本单位的信息量。在经典计算机中,一个0和1构成的比特由不同的电压实现,0代表低电压信号,1代表高电压信号(图1)。
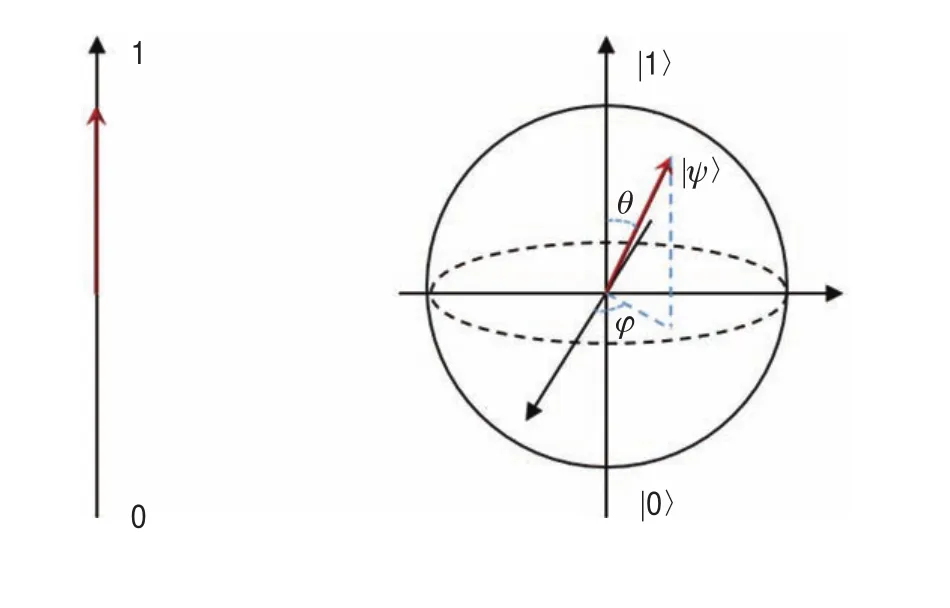
图1 经典比特(左)与量子比特(右)的对比
在量子系统中,我们也可以寻找天然的双态系统来实现这两种可区分的状态。比如自旋系统,一个电子的自旋有上下之分,我们可以把测量到“上”定义为1,而测量到“下”则定义为0,这就构成了一个量子比特。神奇的地方在于,量子力学告诉我们一个量子比特可以制备在两个逻辑态0和1的相干叠加态上,换句话讲,它可以同时存储0和1。考虑一个有N个物理比特的存储器:若它是经典存储器,则它只能存储2N个可能数据当中的任一个;若它是量子存储器,则可以同时存储2N个数,这意味着随着N的增加,其存储信息的能力将指数上升。例如,一个250量子比特的存储器(由250个原子构成)可能存储的数量达2250,比目前已知的宇宙中全部原子的数目还要多。
由于数学操作可以同时针对存储器中全部的数据进行,因此量子计算机在实施一次的运算中可以同时对2N个输入数进行数学运算。其效果相当于经典计算机要重复实施2N次操作,或者采用2N个不同处理器实行并行操作。可见,量子计算机可以节省大量的运算资源(如时间、记忆单元等)[1]。
3 量子算法——Shor和Grover算法
为开拓出量子计算机巨大的并行处理能力,还必须要寻找适用于这种量子计算的有效算法。Shor于1994年发现了第一个量子算法,它可以有效地用来进行大数因子分解。目前,广泛用于电子银行、网络等领域的公开密钥体系“RSA”,其安全性的前提便是“大数因子难以用经典计算机分解”。现有计算机对一个长度为n的大数做因子分解,其运算时间以2(n/2)的指数增长。迄今,在实验中被分解的最大数为129位,1994年在世界范围内同时使1 600个工作站花8个月时间才成功地完成这个分解。用同样计算功能来分解250位的数要用80万年,而对于1 000位的数,则要用1025年。采用Shor算法的量子计算机所需时间仅以n2(lgn)(lglgn)增长,大大减少了时间复杂度,可以在几分之一秒内实现对1 000位数的因子分解。可见, Shor量子算法将这类“难解”问题(NP问题)变成“易解”问题(P问题)。这意味着在量子计算机面前,现有公开密钥RSA体系将成为摆设!Shor算法的开创性工作有力地刺激了量子计算机和量子密码术的发展,成为量子信息科学发展的重要里程碑之一。
另一个非常有用的量子算法是1997年Grover提出的搜寻算法,即所谓的量子搜寻算法,也称Grover算法。它专注于解决在N个未分类的客体中寻找出某个特定的个体。通俗地说,它可解决如下问题:要从有着100万个号码的电话本中找出某个指定号码,该电话本是以姓名为顺序编排的。经典方法是一个个找,平均要找50万次,才能以50 %概率找到所要电话号码。而Grover的量子算法每查询一次就可以同时检查所有100万个号码。100万量子比特处于叠加态,量子干涉的效应会使前次的结果影响到下一次的量子操作,这种干涉生成的操作运算重复1 000(即次后,获得正确答案的概率为50 %。若再多重复操作几次,那么找到所需电话号码的概率接近于100 %[1]。
4 实现量子计算的物理系统
我们现在找到了实用性的算法,那么如何在物理上实现量子计算机的硬件呢?科学家们开始的设想是从传统电路的逻辑出发,只要能找到一个易于测量的双态体系,如光子的偏振方向,电子、原子核的自旋方向或原子、离子本身任意两个离散的能级构成的二能级系统,将它们组成大规模的阵列,再通过光、电、磁场等干涉方法组成一系列“量子逻辑门”对其进行操控,就可以构建出初步的量子计算机(图2)。
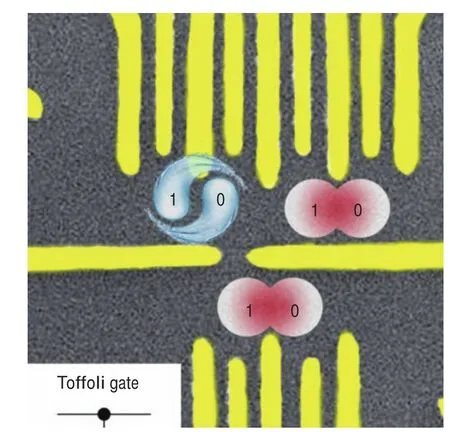
图2 中国科学技术大学实现的半导体三量子比特Toffoli逻辑门(图中黄色部分为操控电极)[2]
遗憾的是在实际中,原子尺度的粒子很容易受到环境中噪声的干扰,从而失去量子效应(退相干)进而导致量子比特发生错误,因此必须将环境温度控制在-273 K左右(与绝对零度相差不到一度)。另外由于测量引起的“坍塌效应”,我们无法直接读取一个量子位的状态,只能通过测量与其纠缠的其他粒子来推测出它的状态。所以为了纠错和读取,每一个逻辑比特都需要5 000~10 000个物理比特来进行辅助。
目前,备受人们期待能实现量子计算的物理系统有离子阱系统、超导约瑟夫森结系统、金刚石自旋系统、半导体量子点系统以及我国潘建伟教授研发的国际领先的光子系统等。它们各有优缺点,比如:离子阱系统“干净”(相干时间长)且精密(量子态制备保真度高),但其所需操控时间长且大规模集成困难;超导量子系统对量子比特和量子逻辑门的操控可达到纳秒(十亿分之一秒)级别,但抗噪声能力不能令人满意。种种诸如此类的困难,使得多年过去人们也只能在实验室内做到数十个量子比特的量子计算原型机。
5 野心勃勃的量子计算挑战者
即使困难重重,量子计算巨大的潜力仍如同希腊神话中的“金苹果”,诱使着无数科研工作者以及各大科技公司竞相争夺。根据最新报道,谷歌、IBM、英特尔和微软等科技巨头成为推动量子计算原理样机研发加速的重要力量,其中谷歌更是提出了所谓“量子霸权”的概念。各大公司采取了不同的技术体系和策略,谷歌、IBM致力于超导体系,英特尔同时涉猎硅半导体和超导体系,而微软布局全新的拓扑量子计算路线。
从研究成果来看,量子比特数量由2015年的9位迅速拓展至2019年3月谷歌宣布的72位(图3),4年内提升至8倍,迭代速度明显加快。在2019年1月的CES上,IBM宣布推出IBM Q System OneIBM,发布了世界上第一台商用量子计算机(图4)。最近,谷歌突然在NASA网站上泄露一篇论文,宣布最新量子计算机Sycamore已达成“量子霸权”,即量子计算机已在某一个特殊问题上超越经典计算机。虽然该论文还没有经同行评议,其有效性值得时间检验,但仍然给全球量子计算领域添了一把火。在国内,百度、阿里巴巴、腾讯和华为等大型互联网及电子信息公司不甘示弱,纷纷开始了自己的量子计算研究[3-5]。中国科学技术大学的郭光灿院士团队也在合肥成立本源量子计算科技有限公司。目前,国内的机构大多还处于使用经典计算机进行模拟量子计算的阶段,无论是规模还是深度,都与国际科技巨头的成果有较大差距。

图3 谷歌的72比特量子计算机Bristlecone(图片来自Google AI Blog)

图4 IBM的50比特量子计算机,绝大部分部件的作用是将系统保持在接近绝对零度(图片来自IBM DeveloperWorks Blog)
另外值得一提的是加拿大的递波公司(D-Wave System),他们在2007年突然宣布做出了一台量子计算机的原型机Orion(图5)。Orion不是一台基于逻辑门的通用量子计算机,而是一台量子退火机 (Quantum Annealer)。它不对量子比特做单独控制,而是用绝热演化的结果求解一些特定问题。它一经诞生就被许多科学家质疑:这并非一台真正意义上的通用量子计算机。首先,D-Wave声称利用了量子纠缠效应,但大部分物理学家对此持怀疑态度。其次,绝大部分测试表明D-Wave机器没有量子加速,但对于某些特定问题,它被证明可以比经典计算机更快。特别在2015年12月,Google对当时最新型号 D-Wave two 进行了测试,并宣称它比经典计算机快了1亿倍[6]。但必须强调的是,他们选择了一个特别的问题——模拟退火问题,这个问题用经典算法在短时间内解决十分困难,而D-Wave恰巧在这个特别问题上具有优势,所以它取得了比普通计算机快1亿倍的骄人成绩。对于其他通用问题,D-Wave并没有表现出明显的优势。

图5 饱受争议的“黑盒子”——D-wave量子退火机(图片来自www.dwavesys.com)
即使它只是一台量子退火机,D-Wave仍然有足够的吸引力驱使人们研究其量子退火算法。2011年推出128比特的D-Wave One,就是世界第一个量子计算商品,售价1 000万美元,被军火巨头洛克希德·马丁 (Lockheed Martin) 公司买下。2013年推出512比特的 D-Wave Two,被Google、NASA、USRA 联合买下。之后,2015和2017年又分别推出了1 000比特和2 048比特的D-Wave 2X和D-Wave 2000Q,其中一台被谷歌买下(上文谷歌测试所用)。
6 量子计算与人工智能的碰撞
众所周知,人工智能(artificial intelligence)是当下最火热的研究领域之一。尽管它从20世纪70年代就开始发展,但在初期的高速发展后遇到了瓶颈期,并在很长一段时间里人们只是在机器人推翻人类的科幻小说中看到这个词。但是,在远离大众视线的计算机科学领域,人工智能一直在默默发展。直到杰弗里·辛顿于2006年发表一篇重要论文[7]后,“深度学习”——原本只是机器学习的一个分支研究方向——逐渐吸引了人工智能研究者们的目光(许多人以为是辛顿提出深度学习,实际上这个概念在1965年就被提出了[8]),在之后一系列关键研究论文被发表,进一步加强了深度学习的实用性。从2012年开始,深度学习在语音识别、视觉识别等领域大显身手。但说到真正引爆全球人工智能热潮的,可能还是从2016年谷歌使用基于深度学习技术的AlphaGo战胜李世石这一事件开始,这使得一般民众和大量资本也开始关注人工智能。
那么当量子计算邂逅人工智能会碰撞出什么样的火花呢?这就要从深度学习的原理谈起。深度学习的概念源于人工神经网络的研究,它受人脑启发将每个数据节点抽象为一个个“神经元”,并将神经元分为多层排布,每个高层节点根据一定的权重基于下层的神经元取值。这样高层神经元可抽象地提取出低层数据的“特征”,从而一层层地将数据分类(图6)。在经典的计算机上,神经元之间的互联都是用数字矩阵表示的,也就是说神经元之间的数据计算即进行矩阵运算,传统上这些矩阵操作可由专门设计的GPU(图形处理器)处理。这样的运行速度远逊于量子计算机。麻省理工学院物理学家、量子计算先驱塞斯·劳埃德(Seth Lloyd)表示:“在量子计算机上,大型矩阵的操作速度堪称呈指数级增长。”[9]
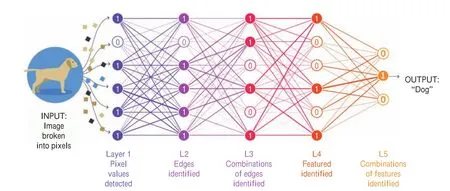
图6 一次典型的使用深度学习技术提取图片特征的过程,途中节点即神经元(图片来自Lucy Reading-Ikkanda/Quanta Magazine)
根据大数据预测,到2025年全球的数据量将达到27.49 TGB(1 TGB=1012GB)[10],其中约有30 %的数据,将具有大数据价值。基于目前的计算能力,在如此庞大的数据面前,人工智能的训练学习过程将变得相当漫长,甚至无法实现最基本的人工智能,因为数据量已经超出了内存和处理器的承载上限,这极大限制了人工智能的发展,这就需要量子计算机来帮助我们处理未来海量的数据。
基于以上事实,近年来科学家提出了量子机器学习[11]和量子深度学习[12]的概念。即使是前文所介绍那并不尽人意的量子退火机D-Wave,也可加速机器学习。这是因为机器学习和深度学习的过程本质上是一个寻找全局最小值的优化问题,而D-Wave的量子退火方案在解决这个问题上要快得多[13]。
综上所述,量子机器学习技术可能会对许多技术领域产生深远的影响,从航空到农业——Lockheed Martin、NASA和谷歌等都已加入。量子机器学习通过优化金融资产的收益率或信用评级计算,显示出其商业前景。尽管通用量子计算机的研发之路漫长且险阻,它仍然是最吸引人类眼球的新科技之一。也许正如当年的蒸汽火车之于马车,仅取决于某个关键技术被攻破,而量子计算机与当下迅猛发展的人工智能的结合或许能给我们的生活带来如隔世般的变革。
猜你喜欢
青少年科技博览(中学版)(2023年3期)2023-05-11 07:36:58
小学科学(学生版)(2021年7期)2021-07-28 06:44:42
小学科学(学生版)(2020年1期)2020-01-19 06:02:08
科技传播(2019年22期)2020-01-14 03:06:34
科学大众(中学)(2019年2期)2019-04-08 02:26:40
消费导刊(2017年20期)2018-01-03 06:26:40
海峡姐妹(2017年10期)2017-12-19 12:26:20
三联生活周刊(2017年33期)2017-08-11 04:35:44
银行家(2017年1期)2017-02-15 20:27:20
西安工程大学学报(2016年6期)2017-01-15 14:08:28
