
海量短信快速查询系统
2019-10-25 00:57喻丽春
长春工业大学学报 2019年4期
喻丽春
(福州外语外贸学院, 福建 福州 350202)
0 引 言
目前4 G网络已经全面普及,随着移动互联网的发展,电信运营商的用户量和业务量急剧增多。由于移动支付等移动手机应用的增多,短信验证码的使用日益广泛,用户对短信详单的查询需求也越来越多。为了支撑用户在发生短信收发丢失问题时,随时随地进行短信详单数据查询,迫切需要建立一个查询速度快、周期长、方式多样化的海量短信详单查询系统[1]。由于用户量较大,每天产生的短信数据量达到数千万级别。如何在海量的短信数据中根据用户手机号和时间范围快速查询短信收发详情成为当前需要解决的首要问题。
传统的短信查询系统一般采用关系数据库(如oracle,mysql等)。由于数据量较大,传统数据库在短信数据保存时一般只保留一周,无法支撑周期较长的短信数据查询,而且查询速度较慢,无法满足用户快速查询短信收发情况的需求,在用户投诉短信收发故障时,客服人员无法及时对用户投诉进行响应和处理。
海量短信数据如何高效地存储、组织、管理与发布,提高处理和分发效率,已成为迫切需要解决的问题。非关系型数据库HBase的产生为这些问题提供了一种良好的解决方案[2-3]。
HBase是一种基于分布式文件系统hadoop的开源分布式数据库,它是Google Bigtable架构设计的一个开源实现,目前,最新版本几乎实现了Bigtable的所有功能。和传统的基于行模式的数据库不同,HBase是基于列模式非结构化数据存储的数据库,具有稳定可靠、性能较高、灵活伸缩等特点[4],比较适合用来实现海量短信快速查询系统。
基于HBase的海量短信快速查询系统包括三个部分;1)短信采集入库;2)短信数据存储模型设计;3)短信查询接口实现。
1 短信采集入库
要实现海量短信查询系统,首先要实现短信数据采集入库。
1.1 原始数据采集
短信按照类型分类可以分为P2P短信、在信短信、互通短信。这些短信通过短信网关采集。根据短信网关数据源采集协议的分类可以分为文件采集和数据库采集。为了统一处理过程,针对数据库采集,使用jdbc方式采集生成原始文件保存到采集服务器。针对FTP文件采集程序保存到采集服务器。为了保证数据的及时性,根据数据源特点,采用主动式采集,即通过定时轮训,发现数据源产生新数据,并且马上启动采集。
1.2 数据解析转换
针对数据原始文件,使用文本处理工具awk解析文件,统一解析转换为统一的tsv文件格式。统一转换后的数据格式见表1。
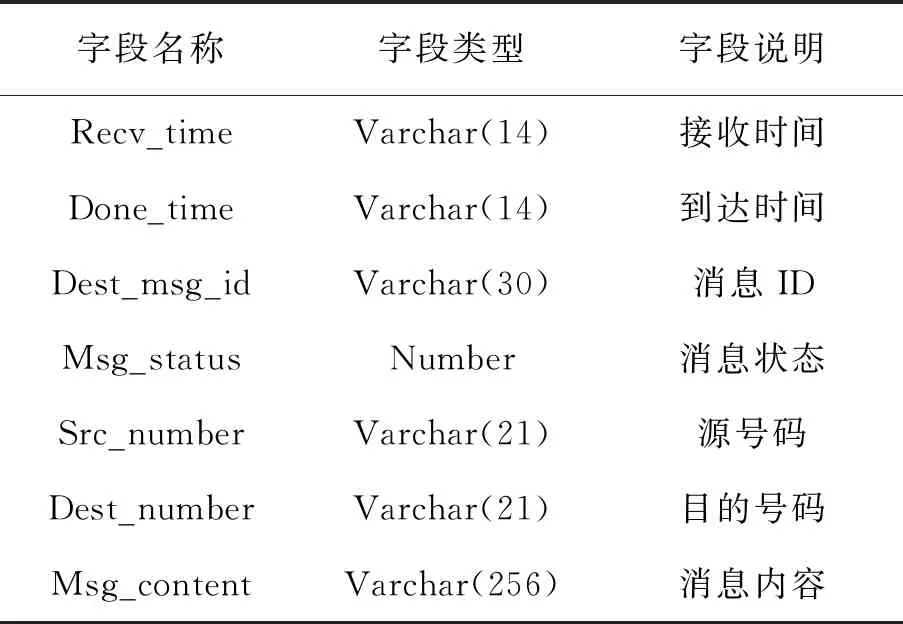
表1 短信入库统一格式
1.3 短信数据入库
采集的数据最终要保存到HBase数据库。研究发现,采集数据存储到HBase的方法有以下三种[5]。
1)将采集数据格式化,转换为HFile格式(即HBase在hadoop系统上的存储格式)。然后通过HBase自带的bulkload工具导入到HBase数据库。这种导入方式生成HFile较慢,但生成文件后导入速度非常快,几乎与文件拷贝速度一样。
2)通过Map Reduce的方式导入HBase数据库,这种方式导入速度相对较快,但占用资源较大,当系统资源不足时,导入方式明显较慢。
3)通过JAVA编码调用HBase API,使用多线程、多客户端入库。该入库方式同样存在占用系统资源较高问题。
三种入库方式对比发现,方式1)入库效率最高,能够保证数据采集和入库的及时性。具体采集入库步骤如图1所示。

图1 短信采集入库流程
1)针对数据库短信数据源,按数据源提供的最小数据粒度导出短信数据到文件,同时进行预处理。生成HBase数据库能够识别的HFile格式文件。针对文件格式的短信数据源,通过awk脚本,对原始文件进行预处理转换为HFile格式文件。
2)将HFile格式文件put到hadoop分布式文件系统。
3)使用HBase自带的批量导入工具importTsv将HFile文件导入到HBase数据库。
2 短信数据存储设计
与关系数据库一样,HBase也是用表来存储数据。HBase的表可以很大,单个表可以存储上百亿行的数据。表由行和列组织,一行可以包含一个或多个列。一个或多个列又形成一个列族(column family),每个列族对应唯一的一个行键(row key)。同一个列族的数据按照行键的字典顺序存储在同一个HFile里面。因此,库表行键的设计将直接影响数据的查询性能。经常一起读取的数据最好保存在一起,以提高查询速度。
要实现海量短信的秒级查询,rowkey的设计是最为重要的环节。在客服进行短信查询时,查询条件涉及以下几个条件:
1)短信类型:包含SP、在信、互通、点对点。
2)短信收发:短信接收、短信发送、同时查询接收和发送。
3)短信范围:短信发送的时间范围,可以支持6个月时间跨度的短信查询。
要查询的短信结果内容字段如下:
发送时间,到达时间,发送状态,发送号码,接收号码,短信内容。
当前短信数据量预估大概每天3 000万条,按1条1 k计算,预估1 d有30 G左右的数据量。性能要求上尽量做到准实时采集,前台查询响应时间需控制到2 s左右,数据保存周期半年以上。
为了高效率利用存储空间,在对短信数据存储时,使用HBase提供的压缩存储功能。综合比较了几种压缩效率和压缩比,这里选择Snappy算法[6]进行压缩,压缩比大约为22%。为了达到快速查询的目标,在存储时将短信数据分为短信索引表和短信详单表。
2.1 短信索引表设计
短信索引表设计见表2。

表2 短信索引表
根据查询条件,结合rowkey设计原则,长度越短越好,唯一性、散列性,rowkey采用如下组合字符串:
rowkey=手机号+业务类型(0-sp,1-行业,2-互通,3-点对点)+发送状态(0-发送,1接收)+发送日期(yyyymmddhh24miss)+短信序列末尾四位。
正常情况下,普通手机号码同一秒内发送的短信条数较少,因此,通过取短信序列号末尾四位足以保证rowkey的唯一性,同时也能尽可能地缩短rowkey。表数据压缩算法采用snappy算法,设置库表的TTL为15 552 000 s,即数据超时时间为180 d。当数据入库后超过180 d,数据将被自动删除。
短信索引表建表语句如下:
create ‘t_sms_index‘, {name => ’cf’, COMPRESSION => 'SNAPPY', TTL => ‘15552000’}
2.2 短信详单表设计
根据要查询的短信结果内容字段,短信详单设计见表3。

表3 短信详单
短信详单表建表语句如下:
Create ‘t_sms_info‘,{name => ’cf’, COMPRESSION => 'SNAPPY', TTL => ‘15552000’}
3 短信查询接口设计
3.1 远程Web调用协议
目前为止,REST、SOAP、XML-RPC是三种最常用的远程Web调用协议[7-8]。其中,SOAP和XML-RPC都是基于XML进行消息交换,性能差不多,但由于SOAP更为成熟,目前已经逐渐取代XML-RPC协议。REST协议虽然在成熟度上不如SOAP,但其具有调用效率高、简单易用等突出特点。考虑到短信查询接口的运行效率和查询性能。这里选择REST协议作为短信查询接口实现协议,同时为了减少传输过程中的数据冗余,选择使用json消息代替XML消息作为数据传输格式。
3.2 查询接口设计实现
为了接口的易用性,接口需要实现分页查询功能,支持的查询参数见表4。

表4 查询参数表
REST接口设计如下:
public SmSInfoList getSmsList(@QueryParam("phonenum")String phonenum, @QueryParam("msgtype")String msgtype, @QueryParam("querytype")String querytype, @QueryParam("fromdate")String fromdate, @QueryParam("todate")String todate, @QueryParam("pagesize")int pagesize, @QueryParam("pagenum")int pagenum)
客户端通过请求如下url:
http://127.0.0.1:50000/smsservice/query?phonenum=13000000001&querytype=0&msgtype=1&fromdate=20180109134500&todate=20180109140000&pagesize=100&pagenum=1
即可返回消息采用json格式如下:
{
"currentnum": 2, ##表示当前返回条数
"errormsg": "", ##错误信息,result字段为1时,该字段有值。
"pagenum": 1, ##页码
"pagesize": 100, ##每页条数
"result": 0, ##查询结果,0表示成功,1表示失败
"size": 2, ##总条数
"smsList": [{ ##短信列表
"destNum": 1300000001, ##被叫号码
"msgContent": "简单!下载点******", ##短信内容
"msgStatus": "成功", ##短信中心状态
"msgType": "接收", ##短信类型
"recvTime": 20180109134502, ##短信中心接收时间
"srcNum": 10010, ##主叫号码
"transTime": 20180109134504 ##短信中心发送时间
}, {
"destNum": 1300000001,
"msgContent": "******",
"msgStatus": "成功",
"msgType": "接收",
"recvTime": 20180109134500,
"srcNum": 10010,
"transTime": 20180109134502
}]
}
Apache CXF 是一个开源的 WebService 框架,可以用来构建和开发 WebService,这些服务可以支持SOAP、HTTP等多种协议,这里采用Apache CXF框架来实现REST接口。查询接口的实现流程如图2所示。

图2 查询接口实现流程图
4 查询性能验证
Apache Jmeter是Apache组织开发的基于Java的压力测试工具[9]。为了验证接口的调用效率,这里使用Apache Jmeter对接口进行测试。首先在测试计划里创建线程组,线程数为100,共调用接口100次,设置好http请求参数后,点击运行,测试结果图形如图3所示。
从图3可以看出,多次调用,每次接口调用时长总体较为稳定,耗时均小于1 s。
测试聚合报告见表5。

表5 测试聚合报告
从表5可以看出,总共调用了100次http请求,全部调用成功。其中调用最长耗时为1.043 s,最短耗时为0.540 s,平均每次请求响应时间为0.685 s。实验结果表明,海量短信查询设计能够满足短信秒级快速查询的要求。
5 结 语
基于HBase的海量短信快速查询,充分利用HBase数据库特点,通过查询条件设计构造rowkey,将短信存储分为索引表和短信详情表分开存储。查询时先范围扫描索引表,再批量通过Key值获取详细短信信息。该查询设计极大地提升了查询速度,相对于传统海量数据查询系统是一个巨大的改进,为客服人员快速解决客户投诉问题带来了巨大的便利。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
商品与质量(2019年34期)2019-11-29
当代陕西(2019年14期)2019-08-26
计算机系统应用(2019年3期)2019-03-11
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中学数学杂志(初中版)(2016年5期)2016-11-01
导航定位学报(2015年2期)2015-06-05
浙江大学学报(工学版)(2015年2期)2015-05-30
土木建筑工程信息技术(2013年4期)2013-10-17
