
基于机器学习模型的P2P网贷平台风险预警研究
2019-10-23 05:45冯凌秉蒋志慧
金融与经济 2019年9期
■严 武,冯凌秉,蒋志慧,孔 雯
本文利用大数据网络爬虫技术收集了网贷第三方网站平台的公开数据,利用机器学习模型对网贷平台的非法集资风险进行了预警研究,比较了传统机器学习方法(以逻辑回归和决策树模型为代表)与前沿机器学习模型(以随机森林模型和XGBoost模型为代表)在多个预测指标上的静态预警效能,并在动态预警框架下研究了网贷平台全生命周期内各模型的动态预警效果。研究表明,传统与前沿机器学习模型均表现出了优良的预警效果,传统模型的准确率略低于前沿模型,但决策树模型在重要检出率指标上的表现优于其他模型。在动态预警框架下,本文发现在平台全生命周期内,所采用机器学习模型的预警效果随时间的变化呈现波动上升并在2017年后缓慢下降的趋势。虽然该趋势与我国网贷行业的发展和监管现状相符,但也表明预警模型的使用者应积极寻找表外指标,进一步挖掘网贷平台的深层次指标以稳定预警效果。
一、引言与文献综述
近年来,以P2P网贷为代表的新兴金融模式因其利率不受限制,提供远超银行存款的高额回报受到投资者的普遍青睐。同时,因为平台的灵活放贷模式能在一定程度上解决中小企业和个人“融资难、融资贵”的难题,从而很好的弥补了传统金融体系在“末端”的缺位,一定程度上推动了普惠金融的创新发展。然而,由于P2P平台进入门槛低、监管滞后等原因导致平台安全问题频发,非法集资诈骗问题严重,极大损害了投资者的利益,扰乱了金融市场秩序。因此,如何及时有效侦测P2P平台的非法集资风险成为了业界和学界讨论的重点。
由于不同国家在宏观经济政策、行业制度、社会环境等方面存在着较大差异,导致国内外学者在对P2P研究的整体方向上存在着一定差异。相对而言,国外的社会征信体系建设比较健全且监管体制和法律法规比较完善,其研究以借款人违约及借款成功率的影响因素为主。在借款人违约率方面,Lin et al.(2009)基于Prosper平台的数据研究指出平台了解借款人的社会网络关系能有效降低借贷中的信息不对称问题。在借款成功率方面,Greiner et al.(2009)发现借款人社会网络关系越复杂,借款利率相对越低,借款成功率越高,但与其相关的借款违约率并不能降低。Sonenshein et al.(2011)指出借贷双方之间的沟通能有效提高信用度较低的借款人的借款成功率,但不能明显降低其借款违约率。Freedman&Jin(2017)指出,P2P平台较传统借贷中介而言,其信息透明公开度低,会加剧借贷的道德风险及逆向选择问题。
国内对P2P网络借贷的研究主要集中在P2P网贷风险,较早期是借款人违约风险和行业风险,后期研究集中关注P2P平台自身的风险。多数学者认为P2P网络借贷中借款人存在着很高的信用风险。李悦雷(2013)、王会娟和廖理(2014)的实证研究表明信用认证机制对平台的借款成本和借款成功率都有重要的影响。何德旭和王进成(2013)将我国P2P网络借贷平台内外的风险归分为六类,分别是平台声誉风险、法律风险、利率管理风险、操作风险、区域集中度等层面的风险和资金使用方面的信用风险。张巧良和张黎(2015)指出网贷平台存在法律风险、市场风险、信用风险、技术风险、无序竞争风险、内部管理风险、声誉风险与机构合作风险等八大风险。唐艺军和葛世星(2015)还指出了操作风险、流动性风险和信息污染风险。
目前仅有个别学者研究P2P问题平台风险影响因素。李先玲(2016)基于231个P2P网络借贷平台数据研究发现相关人员金融行业从业背景、注册资本和平台自我监管能够有效降低平台出现问题的机会比率,而过度行业竞争则会增加风险概率。彭劭志(2016)等将平台出现的失联、提现困难和终止营运等行为定义为P2P网络借贷平台的违约行为,并运用实证方法探讨了平台违约行为的影响因素。范超和王磊(2017)等用我国444家P2P平台基本信息与交易信息研究了P2P网络借贷的风险甄别问题。巴曙松(2018)等以网贷之家披露的3176家P2P平台为研究样本,定量测算注册资本、注册地、业务模式、风险保障模式等因素是如何影响P2P平台的生存状态,并据此提出了针对性的监管措施。
国内外关于P2P网络借贷平台的研究主要集中在影响因素的描述性分析,对于P2P网贷平台风险预警的研究较为缺乏。鉴于此,本文基于互联网信息爬取技术,整理收集了数家大型主流网贷网站上的P2P网贷平台数据,利用主流机器学习模型进行风险预警研究,探讨了机器学习模型在网贷平台风险预警上的优越性,并特别提出决策树模型在检出率指标上表现出了优良的性能,应予以重视。同时,本文设计了特殊的动态预警框架以产生训练集和测试集,动态观测机器学习模型在平台全生命周期内的动态预测效果,并结合我国网贷平台的监管实际,为进一步提升网贷平台的风险预警提出了经验证据与改进意见。
二、指标分析与模型选择
(一)指标分析
本文研究的核心被解释变量是如何根据事先已经公开的信息识别出平台是否为“问题平台”。若平台出现提现困难、停业、经侦介入、跑路等问题,则定义为问题平台,赋值为1;非“问题平台”及认定为“正常平台”,赋值为0。借鉴已有关于网络借贷平台风险因素的研究,本文主要从预测P2P平台风险因素考量,结合数据的可得性,将所有指标分6个一级指标及30个二级指标的P2P平台风险预警体系指标。指标含义及变量类型如表1所示。

表1 一级与二级指标类型及其含义一览表

续表1
(二)模型选择
已有风险预警的研究方法可以分为两大类,即传统的统计模型和机器学习算法模型。本文选择逻辑回归和决策树模型作为传统模型,选择随机森林和XGBoost模型作为前沿模型,其中逻辑回归模型、决策树模型和随机森林模型参考周志华(2016);XGBoost模型参考Chen&Guestrin(2016)。
三、数据处理与预警评估
(一)数据处理
本文数据来源于网贷之家、网贷天眼及51网贷等第三方网站,利用Python爬虫技术抓取这些网站上公布的所有P2P平台数据,数据截止日期为2018年11月30日。剔除无效样本,共得到样本6424家,抓取各样本平台30项指标。所有平台中问题平台为5262家,正常平台有1162家。本文随机抽取60%的观测值作为静态分析的训练集,40%的数据为测试集,实证使用训练集共3854家,包括719家正常平台,3135家问题平台。测试集中共含有2670家平台,正常平台443家,问题平台2172家。
本文同时从动态预警的角度出发,评估预警模型随时间变化的学习效果,动态产生训练集和测试集。近年来各项P2P平台监管法规的出台会使得平台风险特征随时间发生变动,早期问题平台特征可能会对当前的训练准确性产生影响。因此,本文预警模型的移动窗口是1个月,单个训练集由两年内发生问题的平台,与当时仍正常经营的平台共同构成。由于2011年之前P2P平台数量较少,本文第一个训练集是在2011年1月1日~2013年1月1日年之间出现问题的问题平台,以及当时正常经营的平台;而第一个测试集是该时点仍在正常经营的平台,测试结果为在2013年1月1日之后的180天之内,该平台是否转变为问题平台,如果180天之内仍为正常平台(即使之后成为问题平台),则视为正常平台,否则作为问题平台。2013年2月1日则重新产生一次训练集和测试集,以此类推①由于数据截止时间为2018年11月30日,2018年7月1日之后的测试集不满足180天的“问题暴露期”要求,预测准确性的评估效果可能会受到影响。因此,动态预警框架下的数据截止日期为2018年6月31日。。
(二)预警评估
对于数据集的每一个测试样本,模型都有4种可能的预测结果,在预警模型中,混淆矩阵是一种可视化工具,适用于有监督的学习方法,是评价分类器性能的重要工具。混淆矩阵是一张二维表,根据预测值是否与真实值一致来对预测样本进行分类。混淆矩阵的每一行表示样本实际分类的实例,每一列表示样本的预测类别。当预测值与真实值一致时,预测样本分类正确,当预测值与真实值不一致时,预测样本分类有误。
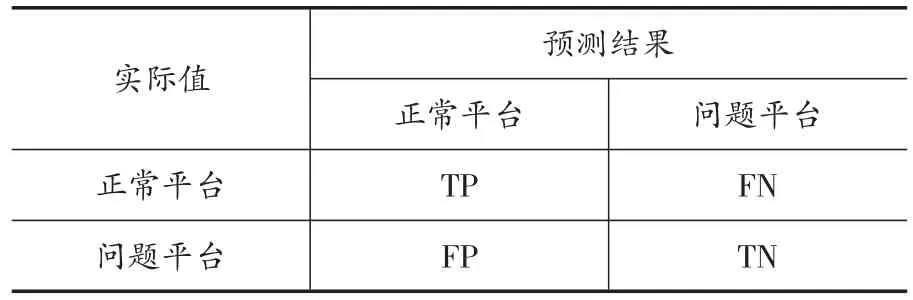
表2 混淆矩阵示例
如表2所示,TP(True Positive)是指正确预测的正类样本数,即正常平台被预测为正常平台的数量;FN(False Negative)是指错误预测的正类样本数,即正常平台被预测为问题平台的数量;FP(False Positive)是指错误预测的负类样本数,即问题平台被预测为正常平台的数量;TN(True Negative)是指正确预测的负类样本数,即问题平台被预测为问题平台的数量。同时,在本文的动态预警框架中,TP表示预测为正常平台,实际180天内未发生问题的平台数量;FN为预测为问题平台,实际180天内未发生问题的平台数量;FP为预测为正常平台,实际180天内发生问题的平台数量;TN为预测为问题平台,实际180天内发生问题的平台数量。本文主要关注以下两个衡量模型表现的指标。
准确率(accuracy)定义为预测正确的样本数量占总样本数量的比例:
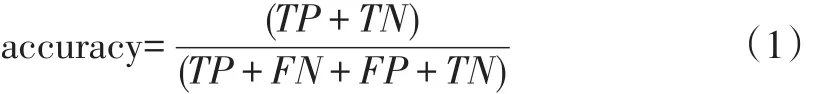
检出率(discovery)定义为所有问题平台被预测为问题平台数量的比例:

四、实证分析
(一)描述性统计分析
把样本分为正常运营平台和问题平台两组,对比分析这两组平台在每一个变量上的对照情况。表3为平台之间在分类变量上的对比结果,表4展示了在连续变量上的对比结果。对比发现:相比正常运营平台来说,问题平台和正常平台之间存在着明显差异。在平台实力方面,正常平台非民营系占比相对较大,平台注册区域在省会城市的占比、上市平台、有ICP经营号平台的占比也比问题平台大。在产品特征因素方面,问题平台允许自动投标和允许债权转让占比相对较小,业务类型单一。正常运营平台有银行存管、加入监管协会、有逾期赔付和投标保障占比分别为53%、21%、38%和71%,而问题平台占比分别为6%、2%、23%和36%。高管学历和高管是否从事金融行业经验的占比方面,正产平台和问题平台之间也存在一定差距。
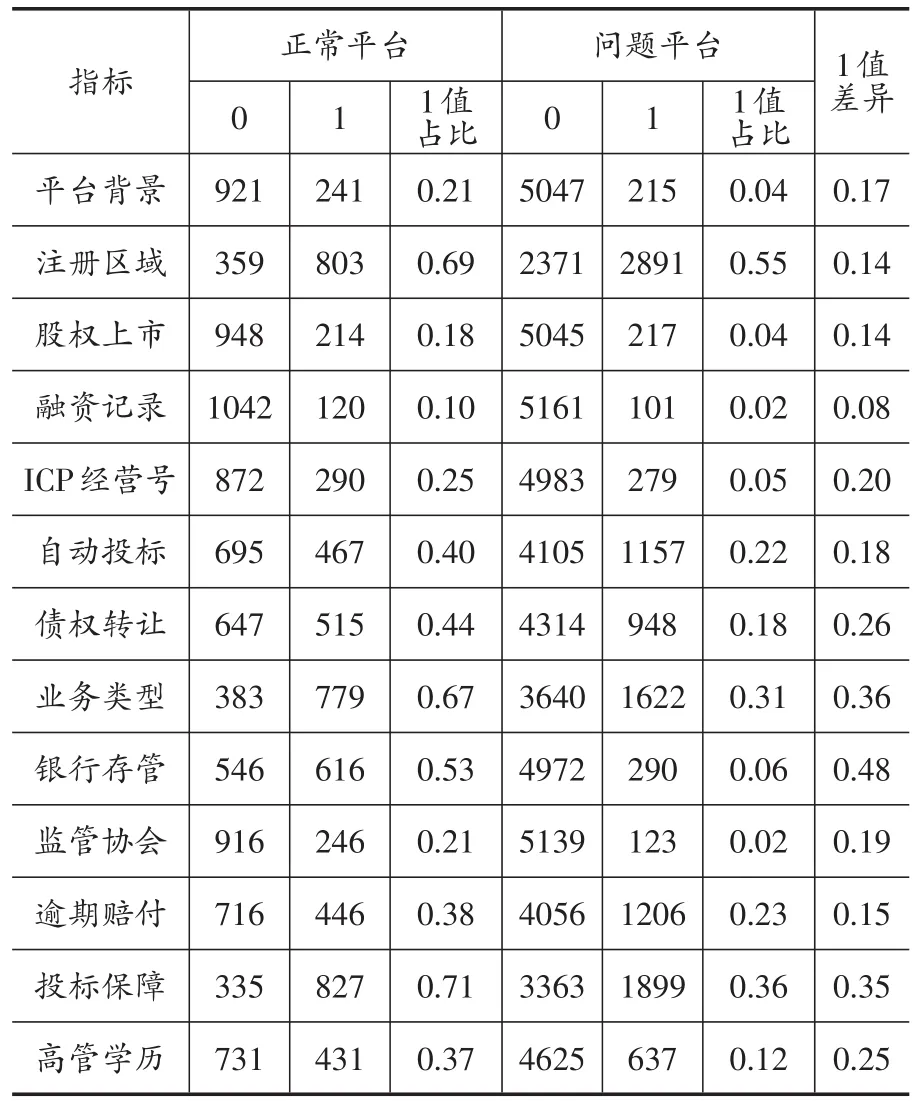
表3 正常平台与问题平台在分类型变量上的分析对比表
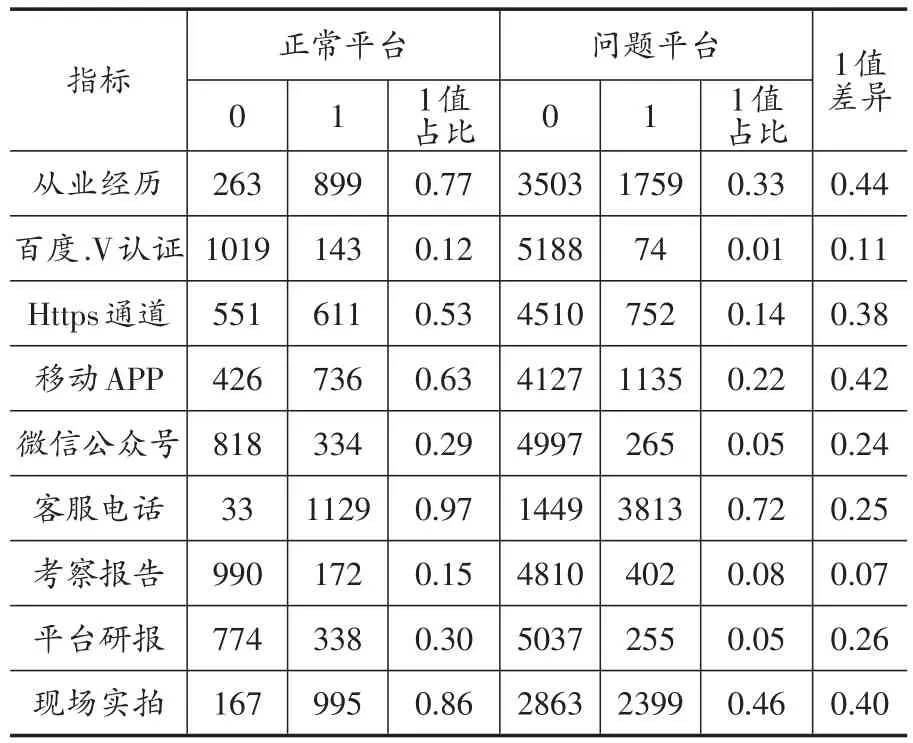
续表3
通过表4可以看出,相比正常运营平台来说,问题平台注册资本平均值、投资期限平均值较小,总体运营天数的均值较短,而参考收益率平均值较大,投资期限相对较短,投友关注量及投友评分方面两个也存在明显差异。值得注意的是,正常运营平台的参考收益率最大值为25%,而问题平台的参考收益率最大值达到48%。此外,正常平台的变更记录比问题平台多,可能由于运营时间普遍较长;而问题平台的异常经营次数多于正常平台。
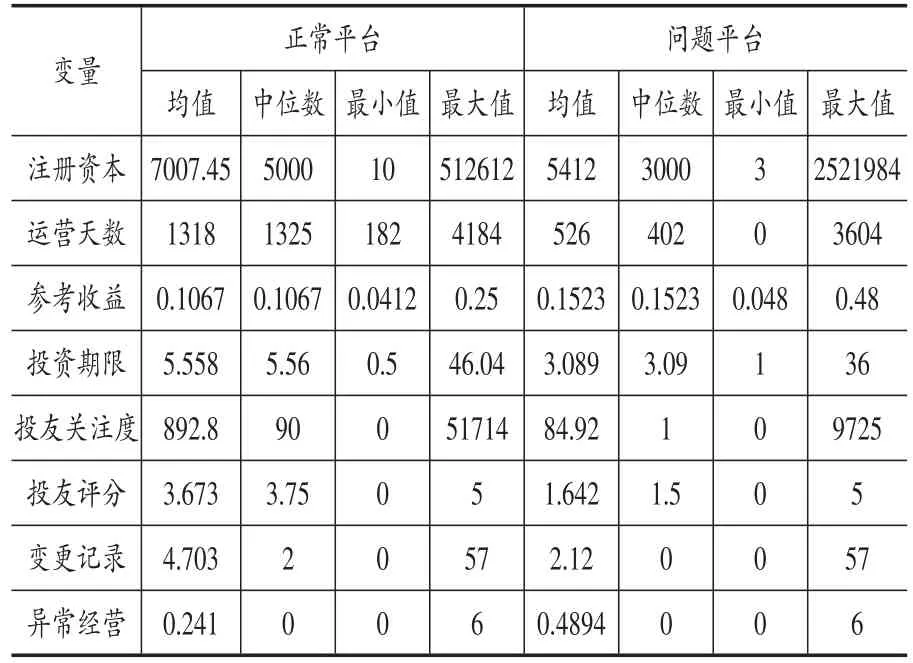
表4 正常平台与问题平台在连续型变量上的分析对比表
(二)预警效果评价
表5为四类分类算法模型的整体分类结果,即分别在测试集和训练集上的混淆矩阵;表6为四类模型在准确率和检出率两个预测评价指标上的预警表现。可以看出,逻辑回归模型对负类样本(问题平台)有很好的预测,但对正类样本(正常平台)的预测不佳,测试集中误判数量达到了225家,该模型的准确率在训练集和测试集上面分别为0.8939和0.8977,检出率在训练集和测试集上面分别为0.8953和0.9028。决策树模型对正类样本(正常平台)有很好的预测,但对负类样本(问题平台)的预测效果不好,测试集中误判数量达122家。其准确率在训练集和测试集上面分别为0.9385和0.9346,检出率在训练集和测试集上面分别为0.9859和0.9776。决策树模型的检出率指标表现在所有模型中表现最好。这一点应引起模型使用者的关注,因为决策树模型的数学形式简单,模型训练速度快,需要调整的参数较少,并且模型结果为分叉树结构,具有优良的可解释性①决策树模型的分叉树图结果本文不列出,可向作者索取。。
相比传统机器学习模型,随机森林模型和XGBoost模型整体表现都更加优良。随机森林模型对正类样本(正常平台)和负类样本(问题平台)都有很好的预测,其准确率在训练集和测试集上面分别为0.9556和0.9510,检出率在训练集和测试集上面分别为0.9747和0.9726。XGBoost模型的静态预测表现与随机森林十分类似,其准确率显著优于传统模型。与随机森林模型相比,其准确率在训练集上的表现显著更优,为0.9831,在测试集上的表现略好于随机森林。其检出率在训练集上的表现也显著优于随机森林,但在测试集上则没有随机森林的表现好。
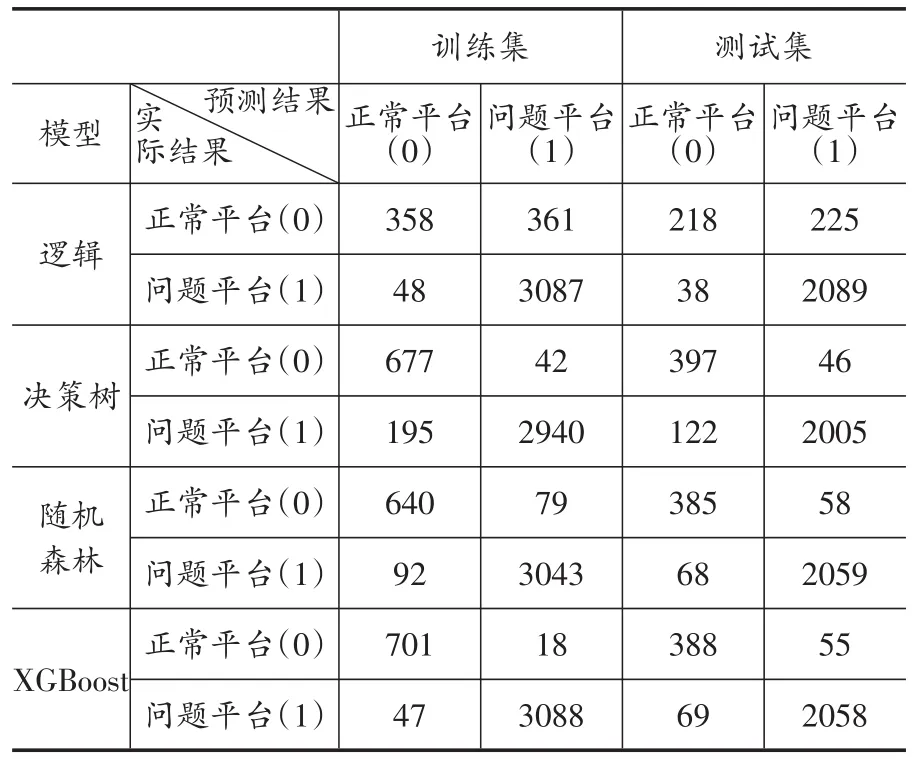
表5 四类模型静态预警模型的混淆矩阵表
综合来看,随机森林模型和XGBoost在准确率和检出率上有着更为均衡的表现,其准确率比传统机器学习模型更高。但在检出率指标上,决策树模型表现优良,其在测试集上达到了接近98%的检出率。因此,当关注的指标是检出率时,应将决策树模型作为首选模型。
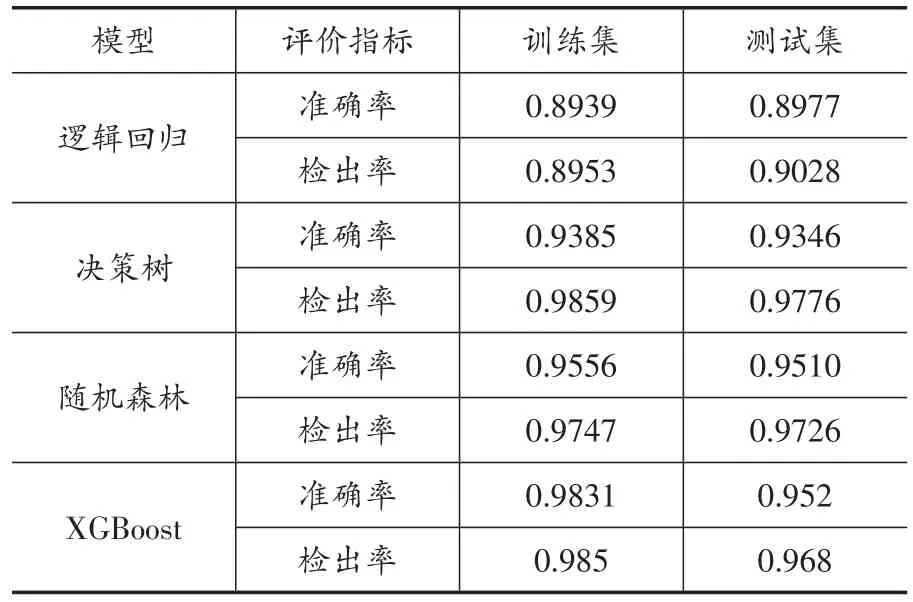
表6 四类模型静态预警效果评价表
(三)指标重要性分析
XGBoost模型可以根据每个变量对模型的贡献给出变量的重要性排序,其结果见表7。本文结合每个指标的含义及其重要性排序情况做进一步分析②随机森林模型也可以给出指标重要性排序表,其结果与XGBoost十分类似,限于篇幅不在此处列出,留存备索。。重要性排名前三的指标分别为参考收益、投资期限与投友评分,其中参考收益的重要性最高,且其重要性指标值为第二名投资期限指标的近6倍,可以看出问题平台往往给出较高的参考收益以吸引投资者,但过高的参考收益往往也是导致平台爆雷的关键因素。与此相关的指标是“投资期限”,参考收益设置越高的平台往往也将投资期限设置的较长,最长达46个月。此外应注意到,第三方平台上的“投友评分”以及“投友关注度”也是较为重要的两个指标,投友评分越低以及投友关注度越低的平台,其出现问题的概率也越大,故而投资者和监管平台也应重视第三方网站上提供的舆论数据。此外,运营天数长短(是否为老平台),是否有银行存管,注册资本大小也都是较为重要的指标。
值得注意的是,“融资记录”和“移动APP”并非重要的预测指标。个人投资者在考察网贷平台的安全性时往往重视该平台是否获得过机构的投资,或者其是否开发有手机端APP。表7的结果显示,这两个指标都不能作为判断平台风险的指标。另外,类似是否允许“债权转让”,公司的“注册区域”等指标在预测模型中的重要性也十分微弱。因此,投资者和监管者在关注网贷平台时不能被平台的这些“伪装”指标所迷惑,而应该关注表中排名靠前的指标。
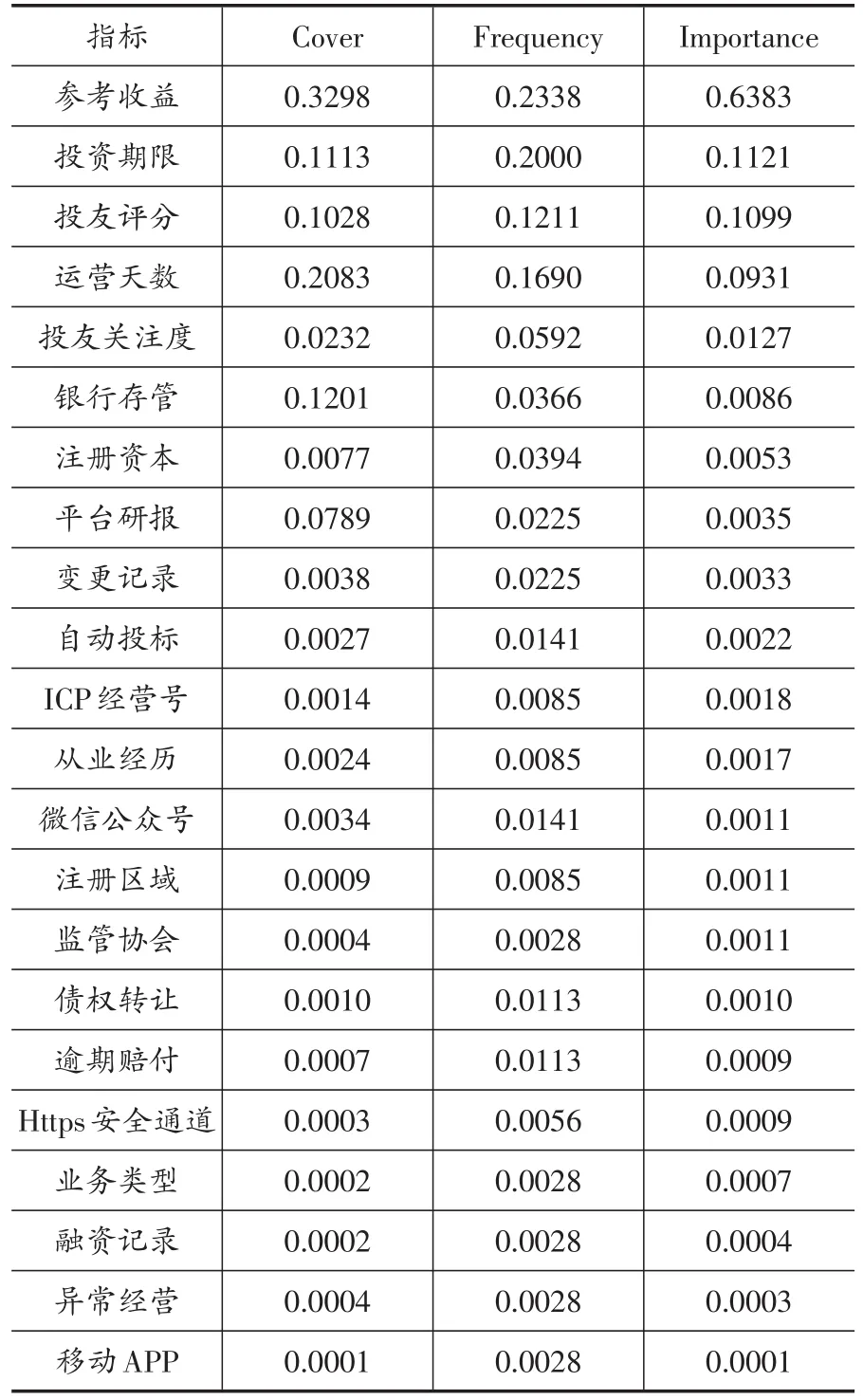
表7 XGBoost模型指标重要性排序表
(四)动态预警分析
从2007年第一家P2P平台拍拍贷成立到2018年底平台上线和问题数的动态变化情况如图1所示。鉴于机器学习模型的预测效果会受到训练用样本量大小以及被解释变量中的样本均衡程度(问题平台数和非问题平台数的比例),本文基于动态预警的视角来分析在整个平台近10年的生命周期内模型预警效果的动态变化模式。
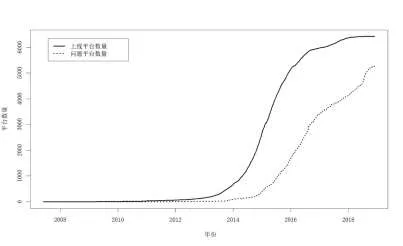
图1 网贷平台上线平台数与问题平台数动态变化图
考虑到2013年之前行业内平台数量较少,平台出问题的概率很小,不满足机器学习样本量的要求,因而将开始时点设置为2013年1月1日,结束时点设置为2018年6月31日,共计可获取66个训练集及对应的测试集。此外,为了方便进行动态描述统计,根据平台的注册资金设置一个虚拟变量,即平台规模,按照平台注册资金分类,高于1亿元为大平台,1千万至1亿为中等平台,低于1千万的为小平台。为了呈现我国P2P平台的生存情况,本文结合我国P2P行业的五个发展阶段①五个阶段分别设定为:行业导入期(2007~2011年),快速发展期(2011~2013年),野蛮生长期(2014年1月~2015年7月),规范成长期(2015年8月~2017年1月)和行业整顿期(2017年2月~至今)。其中行业整顿期的截止日期为样本截止期。,统计出各个时期新上线平台的生存情况。从表8可以看到,在P2P平台的不同发展阶段,新上线P2P平台的类型是不同的,大平台比例增长保持稳定,小平台增长比例下降,中等规模平台占比不断上升。而平台能够持续经营(超过1000天)的比例不断下降,存续期较短(低于一年)的比例不断上升。问题平台平均存续天数也一直下降,显示出P2P行业在进入整顿期之前,的确是有着严重的问题,已经到了不得不进行整顿的地步。
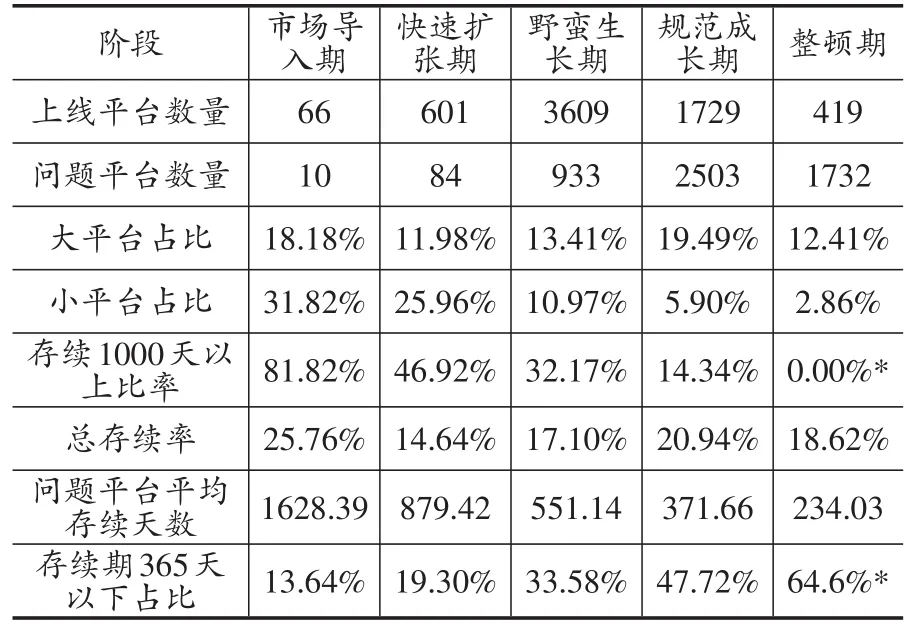
表8 P2P平台存续情况概览
图2展示了在平台目前的全生命周期内四种机器学习模型预警效果(准确率和检出率)的动态变化模式。由图可知,逻辑回归模型的动态预警准确率能维持75%左右的水平,检出率在2015年以前很低,在2015年之后逐渐攀升,到2016年底可以达到75%的水平。决策树算法的准确率波动与逻辑回归模型十分接近,但其检出率的表现要显著优于其他算法,在2016~2017年可达到95%的水平。意外的是,随机森林模型的准确率与逻辑回归模型和决策树模型非常接近,其检出率的波动特征也与逻辑模型相似,但一直略低于后者。其检出率在2016年底可以达到60%。XGBoost模型的准确率和检出率表现与随机森林十分相似,检出率表现略好于后者①值得说明的是,XGBoost模型中有众多的可调参数,笔者在动态模型中并未根据窗口移动对每一个XGBoost模型进行最优调参。在xgb.train函数使用时,除特意设定nrounds=50,eta=0.1,其他均为默认设置。。
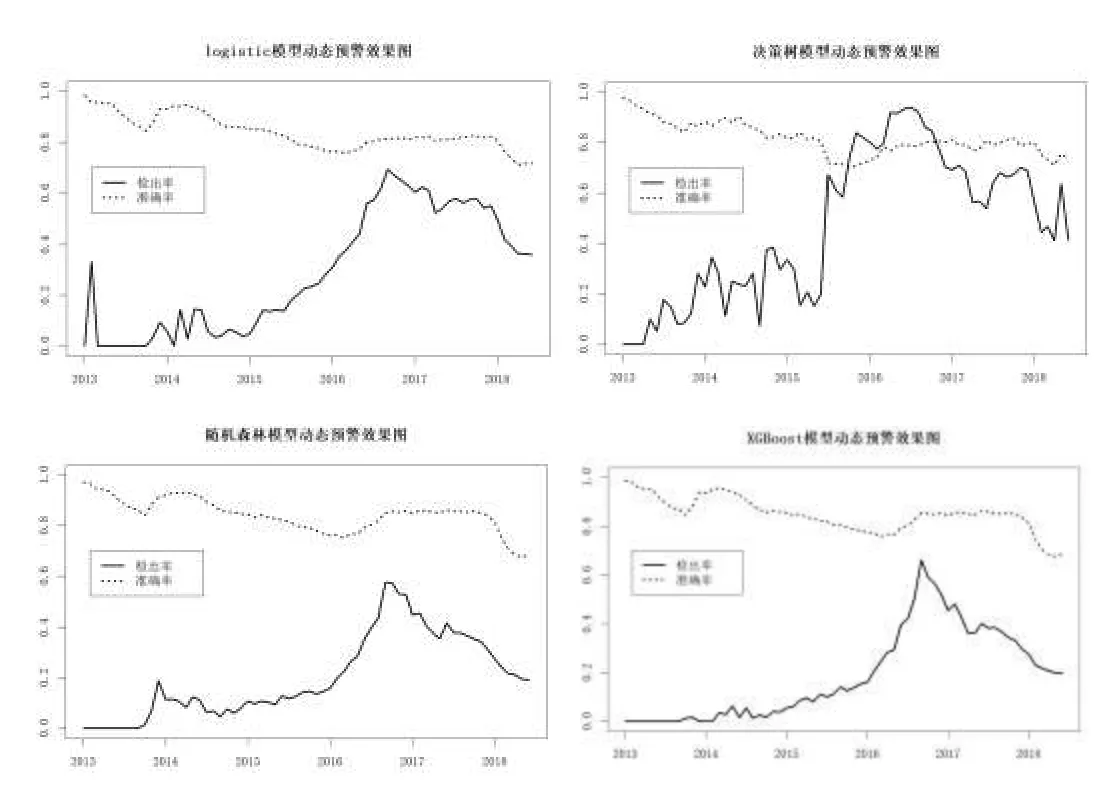
图2 四种机器学习模型的动态预警效果图
四种预警方法在两个评价指标上都显示出了相同的趋势。就准确率来说,四种方法相差不大,均在80%左右波动,并呈现逐渐递减的整体趋势。检出率总体呈现先波动上升后下降的趋势。在2013~2015年期间,四种预警方法的检出率均较低,模型的学习效果较差,这是训练集中问题平台的样本数量不足造成的。回顾问题平台的出现趋势可以发现,问题平台从2015年才开始大量出现,2016年之后出现爆发式增长,才满足一定检出率要求的训练集样本量,此后模型的训练效果较好。2016~2017年上半年,模型的准确率较高,检出率也较高,决策树算法能达到80%以上的检出率。
自2017年下半年,也就是平台进入全面整顿期开始,机器学习模型的检出率开始逐渐下降,即便图1中显示问题平台数在这个时期是持续增加的。通过提取动态预警模型过程中XGBoost模型以及随机森林模型的变量重要性排序情况,发现在整个生命期内,变量重要性的排序情况并没有显著的变动,最重要的三个指标的排序情况(参考收益,投资期限和投友平分)基本没有发生过变化。出现这种情况原因可能在于训练集中的指标均为“表层指标”,代表了平台的特征,却无法代表平台的业务和风险特征。2017年之后,监管机构密集出台新的P2P平台监管要求和业务规范,平台的竞争和发展进入新的阶段,一些目的在于“圈钱”和投机的问题平台无法生存,逐步暴露。剩余的平台在表层指标的范畴内基本都是达标的,导致这一阶段平台出现问题的原因不包含在本文已有的指标库中,比如贷款坏账率、项目逾期率等基础的财务指标。如果需要提升模型的预测力,则需要引入更多指标,如具体贷款质量、贷款去向、监管合规性等指标,但是此类信息往往不公开披露。因此,即便是前沿的学习模型在指标信息不足的情况下也很难有良好的检出率表现。
五、结论及政策建议
本文结合P2P网贷行业在我国的发展和研究现状构建了我国P2P网贷平台风险预警指标体系,并选择基于传统机器学习模型(逻辑回归和决策树模型)以及前沿机器学习模型(随机森林和XGBoost)四种分类算法对P2P网贷平台风险预警问题进行了静态和动态分析。静态研究结果表明基于传统机器学习模型的静态预测效果普遍低于基于前沿机器学习模型,说明平台是否违约与其相关影响因素之间存在较为复杂的非线性关系。静态对比的结果还表明,前沿机器学习模型的准确率相对较高,但是传统机器学习模型中的决策树模型的检出率相对较高。
其次,本文通过动态划分训练集和测试集的方式研究了四种机器学习模型对于网贷平台全生命周期内非法集资风险的动态预警效果,结果显示四种预警方法平均准确率在80%左右。检出率随时间的变化总体呈现波动上升后下降的趋势,在2013~2015年期间,四种预警方法的检出率均较低,模型的学习效果较差,这是由于训练集中问题平台的样本数量不足造成的。2016~2017年上半年,各个模型的准确率较高,检出率也较高。2017年下半年开始,模型的检出率开始下降。发生这种现象的原因在于训练集中的指标均为“表层指标”,代表了平台的特征,却无法代表平台的业务和风险特征,无法体现监管对平台产生的影响。
本文的研究显示,前沿机器学习模型在准确率上显著优于传统的机器学习模型,但检出率并不是它们的强项。预警方法的选择是否合理会对预警的效果产生影响。因此,应结合网贷行业的实际情况不断优化预警模型,平台自身的风控体系以及政府监管模型都应综合考虑各种预警方法,尤其是随机森林和XGBoost等已经在实战中得到充分检验的模型应得到进一步充分的应用,但传统的机器学习模型,如决策树模型,在检出率上有着优良的表现,并且其调参成本更低,运算速度更快,更适合用于平台算法的部署。
本文模型动态预警效果下降的现象也表明现有的公开信息已经不足以为P2P平台监管者和投资人提供足够的参考,也就是说监管机构应转变监管方向,从资质监管向业务监管转变。随着一系列法律法规和行业规章制度的密集出台,P2P领域的正常平台和问题平台在合规性的表现上已相差不大,无法单纯的通过某一平台是否满足法律法规的要求来判断是否存在问题,这也为构建有效的监管模型提出了新的方向。
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
昆明医科大学学报(2021年12期)2021-12-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
现代临床医学(2021年2期)2021-03-29
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
中国外汇(2019年10期)2019-08-27
名人传记·财富人物(2017年9期)2017-11-02
名人传记·财富人物(2017年9期)2017-11-02
