
基于大数据的精准扶贫信息管理系统设计
2019-10-21 08:08冀昊悦高迎
现代信息科技 2019年12期
关键词:精准扶贫
冀昊悦 高迎

摘 要:随着我国信息化建设的不断发展,在扶贫开发领域已经积累了大量具有实际指导意义的扶贫数据,如何有效管理和利用这些日益增长的扶贫大数据是当前亟待解决的问题。为实现高性能的扶贫大数据管理平台的建设,本文针对精准扶贫工作中产生的扶贫数据管理问题,提出基于Hadoop架构的精准扶贫大数据系统设计方案,研究使用FP-Growth算法实现精准扶贫数据的深入挖掘,保证数据的安全可靠和智能化利用,为精准扶贫工作提供有力依据。
关键词:精准扶贫;扶贫数据管理;Hadoop架构
中图分类号:TP311.52;F323.8 文献标识码:A 文章编号:2096-4706(2019)12-0018-03
Abstract:With the continuous development of information construction in China,a large number of practical poverty alleviation data has been accumulated in the field of poverty alleviation and development. How to effectively manage and utilize these growing poverty alleviation big data is an urgent problem to be solved. In order to realize the high-performance poverty alleviation big data management platform construction,this paper proposes a design scheme for accurate poverty alleviation big data system based on Hadoop architecture for the poverty alleviation data management problem generated in the precision poverty alleviation work,and research on the use of FP-Growth algorithm to achieve in-depth mining of precise poverty alleviation data to ensure the safe,reliable and intelligent use of data,providing a strong basis for precise poverty alleviation work.
Keywords:precision poverty alleviation;poverty alleviation data management;Hadoop architecture
0 引 言
精准扶贫是对贫困地区的环境、居民和资源进行综合统筹,利用科学有效的信息化手段进行精准识别、精准帮扶和精准管理脱贫治理方法。早在2013年,习近平总书记在湖南湘西考察时就提出“实事求是、因地制宜、分类指导、精准扶贫”的重要指示。经过多年的精准脱贫政策实施,各级部门通过观察、走访、调研等方式积累了大量的精准扶贫开发领域数据,这对于决战扶贫攻坚工作有着重要的指导意义。
1 构建基于大数据的精准扶贫信息管理系统的必要性
尽管在扶贫开发工作过程中各地都先后开发了扶贫信息管理系统,但普遍存在以下几点问题:
(1)各扶贫工作部门相对独立,信息系统对数据的关联性处理不够,“信息孤岛”问题严重存在;
(2)扶贫数据与户籍、医疗、交通、教育、矿产资源等各领域数据息息相关,现有的信息管理系统无法构建与各个领域数据相关联的知识库;
(3)扶貧信息的利用率较低,各级部门只可以在系统内查看扶贫统计信息,信息系统也只满足数据存储和查询的功能需求,对数据的深度发掘利用程度不高;
(4)扶贫信息系统内的数据多由人工填写或导入,数据较为分散,难以保证数据的准确性和可靠性。
针对上述问题从技术层面分析可知,现有的扶贫信息管理系统采用的是集中式数据管理架构,数据库在不断增容的情况下会出现数据处理能力不足的情况,对硬件系统的处理能力提出了很大挑战;不同领域的非结构化扶贫数据形成了海量的数据群,但这些数据之间缺乏关联性,从而形成了数据孤岛。综上所述,在原有的存储和统计功能的基础上,扶贫信息系统要在数据可靠性管理和数据深度挖掘利用等方面进行进一步设计,将传统的扶贫数据仓库利用到精准服务工作中去,实现科学有效的大数据策略支持。
2 精准扶贫大数据信息系统架构
Hadoop是一种被广泛使用的大数据集分布处理技术框架,是由著名的非营利性组织Apache软件基金会提出和开发的。Hadoop架构的核心技术是HDFS和MapReduce,具有高可靠性、高性能、可伸缩特性等数据处理技术优势。HDFS(Hadoop Distributed File System,分布式文件系统)实现了海量大数据仓库的存储和维护服务,具有极高的容错性和自主性,在保证Hadoop架构的高性能的同时也可以为供应商提供成本较为低廉的分布式服务。MapReduce是一种利用集群技术进行高速高效运算的技术,它具有支持领域搜索、海量数据计算等特点。
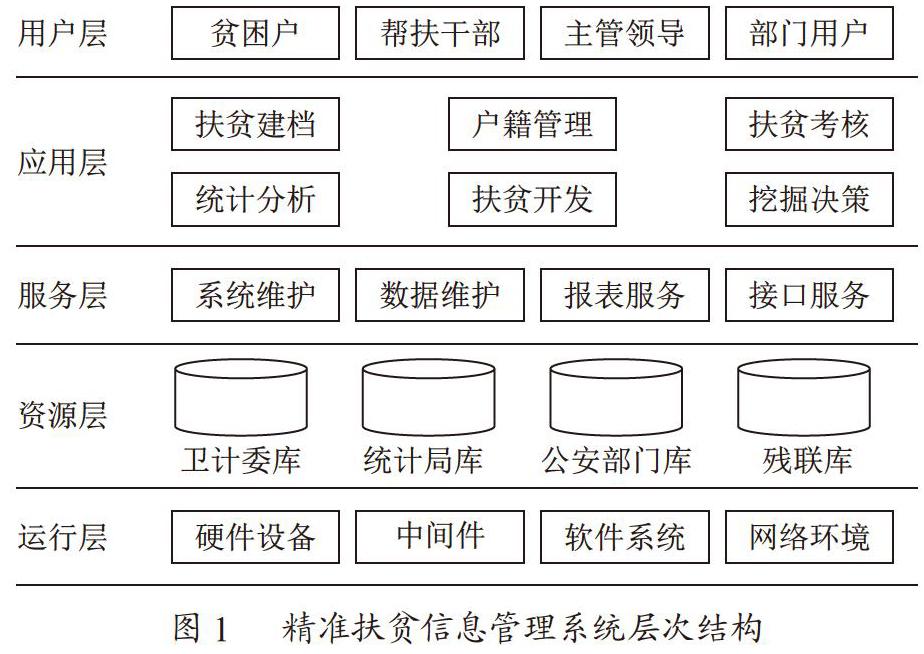
通过技术研究可知,Hadoop架构的使用可以很好地解决原有扶贫信息系统数据可靠性难以保证和数据深度挖掘能力不足的问题。因此,在进行基于大数据的精准扶贫信息系统设计的过程中决定采用Hadoop结构来实现分层结构,如图1所示。
从图1可以看出,精准扶贫信息管理系统分为用户层、应用层、服务层、资源层和运行层5个层次。用户层实现了人机交互界面,通过不同地点和版本号的客户端来访问应用层的各个业务系统;应用层实现了精准扶贫工作的基本业务,同时基于MapReduce对各个数据仓库中的海量数据进行大数据计算和分析;服务层提供了系统通用的业务功能实现服务,如系统用户信息维护、系统数据备份还原、报表输出打印、数据接口交互服务等;资源层负责将各业务系统的业务数据库进行有效整合;运行层在整个架构最底部,实现了系统运行所需的软硬件、中间件和网络环境的综合管理。
3 精准扶贫信息的数据挖掘过程
精准扶贫信息的数据挖掘过程可以概括为业务分析、统一存储、计算转换、模型分析、模式评估和知识表示等,精准扶贫数据挖掘过程如图2所示。
从图2可以看出,精准扶贫信息的数据挖掘过程要按照数据转换、预处理、算法挖掘和决策输出等步骤进行。由于扶贫信息的元数据具有容量大、内容多、结构复杂等特点,在进行数据转换的过程中要首先进行业务分析来确定数据挖掘对象和具体指标,然后按照分析结果进行数据收集和存储;初步转换得到的挖掘数据群数据的完整性、格式和有效性无法保证,还要进行进一步的预处理和清晰才能进行后续操作,因此在此阶段要按照前边制定的挖掘指标进行计算转换,通过平滑聚集、数据概化、规范约束等方式得到适用于数据挖掘算法的清洗后数据;得到清洗数据后就要根据所选的算法构建计算模型,此阶段要根据业务需要来有针对性地选择数据挖掘算法,这样才能保证后续的模式评估和知识表达的正确性,为领导层的决策支持找到有价值的规则和模式,最终以图标的方式呈现给用户层的相关用户。
4 精准扶贫数据挖掘FP-Growth算法
FP-Growth是一种基于分治策略的关联分析算法,FP-Growth在数据挖掘中的应用是通过频繁模式树(FP树)形成的树状结构实现的,具体做法就是将频繁项集压缩至频繁模式树上,再根据模式树得出划分模式的一组或多组条件数据库,分别进行数据挖掘从而得出结论。频繁模式树的主要过程可以概括为FP树构建和计算挖掘两部分,当数据集容量不断增大时,频繁模式树的存储会占用大量的内存空间,此时就会造成频繁模式树的挖掘效率降低。本文针对FP-Growth算法进行优化设计,提高算法的数据挖掘效率。
本次对FP-Growth算法的改进分为5个步骤,将原有的单次数据库扫描和MapReduce计算变为两组执行,以事务数据集和最小支持度为输入,以所有支持度技术大于最小支持度的频繁模式集合为输出,快速得到数据挖掘结果。
步骤1:数据分片。将数据挖掘数据集以片段的形式存在便于读取的多个节点上。
步骤2:并行计算。扫描目标数据库,计算出每个节点上的支持度数量并同步至频繁项集合,该并行计算过程由第一次组MapReduce任务完成。
步骤3:数据分组。将步骤2同步得到的频繁项集合划分为M组,每个组包含若干项频繁项集合的子集。
步骤4:并行挖掘。对步骤3中得到的子集进行Map-Reduce计算,得出由组号和事务组成的数据对组别,划分完成后将结果生成FP树进行进一步的挖掘,得到频繁模式。
步骤5:聚合。在步骤4的挖掘计算得出结果后,通过聚合的方式形成最终结果。
5 结 论
本分分析了精准扶贫信息管理的重要性,研究了现有信息管理系统的弊端,提出了基于Hadoop架构的大数据精准扶贫信息系统架构,介绍了精准扶贫信息的数据挖掘过程和核心算法FP-Growth算法的使用方法,最后通过改进FP-Growth算法实现了数据挖掘的高效性改进。基于大数据的精准扶贫信息管理系统的构建,可以有效打破各部门的“信息孤岛”枷锁,实现扶贫开发工作的全过程透明化管理和跟踪,为精准扶贫工作打造良好的信息通道,实现数据的共建、共享和挖掘利用。
参考文献:
[1] 张航,张欣,张平康,等.基于Hadoop的精准扶贫大数据信息系统 [J].电子科技,2018,31(7):59-62+71.
[2] 陈小宁,郭进,李俊松,等.基于大数据的旅游精准扶贫信息系统设计研究 [J].科技展望,2016,26(36):7.
[3] 孙红,郝泽明.大数据处理流程及存储模式的改进 [J].电子科技,2015,28(12):167-172.
[4] 陈吉荣,乐嘉锦.基于Hadoop生态系统的大数据解决方案综述 [J].计算机工程与科学,2013,35(10):25-35.
[5] 刘党朋.不均衡环境下面向Hadoop的负载均衡算法研究 [D].北京:北京邮电大学,2015.
[6] 张栗粽,崔园,罗光春,等.面向大数据分布式存储的动态负载均衡算法 [J].计算机科学,2017,44(5):178-183.
[7] 申利民,陈真,李峰.考虑数据变化范围的Web服务服务质量协同预测方法 [J].计算机集成制造系统,2017,23(1):215-224.
[8] 梁弼.基于Struts2的Web控制層研究及应用 [J].计算机与数字工程,2016,44(5):912-916.
[9] 崔妍,包志强.关联规则挖掘综述 [J].计算机应用研究,2016,33(2):330-334.
[10] 郭晓波,赵书良,王长宾,等.一种新的面向普通用户的多值属性关联规则可视化挖掘方法 [J].电子学报,2015,43(2):344-352.
作者简介:冀昊悦(1998-),女,汉族,北京人,本科,研究方向:大数据扶贫。
猜你喜欢
民生周刊(2016年20期)2016-11-11
人间(2016年28期)2016-11-10
人间(2016年28期)2016-11-10
知音励志·社科版(2016年8期)2016-11-05
人间(2016年26期)2016-11-03
商(2016年27期)2016-10-17
科技视界(2016年20期)2016-09-29
