
一种基于深度学习的夜间车流量检测方法
2019-10-18 02:57张海玉陈久红
软件导刊 2019年9期
张海玉 陈久红


摘 要:当车流量较少时,降低路灯亮度可以达到能源节约目的。为此,采用深度学习中的R-FCN目标检测网络完成夜间车辆检测任务。R-FCN网络相比传统深度学习网络,不仅是基于区域推荐模型的网络,而且引入了平移变化特性,所以对目标检测效果更好。为了占用更少硬件资源,缩小模型规模,采用ShuffleNet通道分组与组间通信机制,压缩原始残差网络。同时,对NMS(非极大值抑制)算法进行修改,从而可以更好地筛选重叠目标,降低网络漏检率。实验结果表明,该方法准确率较高,在UA-DETRAC数据集的夜间图片检测中精度最高可达到90.89%。
关键词:车流量检测;深度学习;计算机视觉;模型压缩;R-FCN
DOI:10. 11907/rjdk. 182680 开放科学(资源服务)标识码(OSID):
中图分类号:TP306文献标识码:A 文章编号:1672-7800(2019)009-0033-05
Research on Night Traffic Flow Detection Method Based on Deep Learning
ZHANG Hai-yu,CHEN Jiu-hong
(School of Electronics and Communication,Hangzhou Dianzi University, Hangzhou 310018, China)
Abstract: When the traffic flow is small, reducing the brightness of the street light can achieve the purpose of energy saving. For night vehicle detection tasks, this paper uses the R-FCN detection network in deep learning. Compared with the traditional deep learning network, the R-FCN network is not only a network based on the regional recommendation model, but also introduces translational variation characteristics, so the network has better effects on detection task. In order to take up less hardware resources and reduce the size of the model, we used ShuffleNet's channel grouping and inter-group communication mechanism to compress the original residual network. At the same time, the NMS algorithm is modified in this paper, so that the overlapping targets can be better filtered and the network's missed detection rate can be reduced. The experimental results show that the accuracy of the method is high, and the accuracy in the night image of the UA-DETRAC data set can reach 90.89%.
Key Words: traffic flow detection; deep learning; computer vision; model compression; R-FCN
0 引言
在計算机视觉与深度学习飞速发展的今天,各种物体分类、目标检测方法不断创新和完善,使得利用计算机快速识别、解读图片的深刻含义成为可能。
传统图像算法先通过人对图像进行分析,提取出有意义的特征,并对其进行有效判断,提取场景的语义表示,以此让计算机具有人的眼睛与大脑。由此可以看出,传统图像检测方法是有缺陷的:人的参与度太大,无论是特征选取,还是特征提取方法,都需要大量项目经验作指导。随着机器学习与深度学习算法研究进入快速发展阶段,尤其是在计算机视觉方面,深度学习算法发挥了越来越大的作用,甚至在某些领域已经超越了传统图像算法,使得计算机视觉学科进入一个新阶段,人为干预程度越来越低,计算机真正可以自己去思考。
深度学习是由多个处理层组成的计算模型,可通过学习获得数据的多抽样层表示[1]。目前,利用深度学习进行目标检测算法主要有两种类别:一种是以区域建议为基础开发的卷积神经网络算法系列;另一种是以深度回归卷积神经网络为代表的模式。前者主要特点是可以取得很高的精度,但是检测速度有待提升,对需要实时检测的问题有待进一步优化,典型代表有R-CNN系列(R-CNN网络[2]、SPP-Net网络[3]、Fast R-CNN网络[4]等)。后者主要特征是检测速度快,一般可以达到实时性要求,但检测精度方面不如前者,其典型代表有YOLO网络[5]、SSD网络[6]以及由清华大学和英特尔中国研究院提出的RON网络[7]等。
本文基于检测精度考虑,采用基于区域推荐的卷积神经网络系列中的R-FCN网络[8],引入Soft-NMS算法[9],用于进一步提高检测精度,并采用ShuffleNet技术[10]更改原始残差网络,用于缩小模型[11]。
1 R-FCN目标检测网络
目前,全卷积网络结构具有平移不变性,在物体分类中倍受青睐,因为物体分类要求平移不变性越大越好 。然而,在物体检测任务中需要一些具有平移特性的定位表示,即物体发生平移时,网络应该产生对应响应,这些响应对定位物体是有意义的。
假设全卷积网络层数越多,网络对平移变化越不敏感。为解决该问题,人们尝试在网络卷积层间插入 RoI 池化层。因此,区域与区域之间不再具有平移不变性。然而,该设计因引入过多区域操作层,从而牺牲了训练和测试效率。所以,为引入更多平移变化,R-FCN网络在此基础上设计了特殊的卷积层以构建位置敏感分数特征图,依靠RoI池化层获取感兴趣区域,然后利用每个位置敏感特征图尝试对相对空间位置信息进行编码[12]。
1.1 网络架构
仿照Faster R-CNN网络,R-FCN网络首先经过残差网络产生特征图,然后通过两个阶段对目标进行检测,包括区域建议和区域分类[13]。基础网络结构如图1所示。
1.2 残差网络
从2012年AlexNet网络到2014年VGGNet网络,网络结构越来越复杂[14,15]。网络层数越深就越具有超强学习能力,也就可以拟合出更好的数学模型。然而,随着网络层数加深,网络训练难度越来越大,残差网络将对此进行优化。模型结构如图2所示。
假设需要某一层网络学会这样一个映射[H(x)],现在只让它学会映射[F(x):=H(x)-x]即可,其中x为本层输入数据,那么最初要学习的映射就是[F(x)+x]。假设学习F映射比学习H映射更容易,则只需要每一层训练出F映射,然后人为加入x的恒等映射。在某种极端情况下,若某个恒等映射最优,则可将权值层的参数变为0,这样比用传统层拟合恒等映射更简单。当然在实际情况下,恒定映射不太可能最优,但是若最优表达式接近于恒等映射,则对于网络模型来说,寻找一个关于恒等映射扰动比找到一个新映射要容易得多。其中,该恒等映射可以跳过一个或者多个层,在跳过多个层时,若x和F的维度不同,则需要一个线性映射W匹配两者维度。实验证明,残差网络解决了随着网络层数加深引起的模型退化问题。
1.3 位置敏感分数图
类似于Faster R-CNN网络,R-FCN网络有一个单独RPN网络寻找特征图的ROI(感兴趣区域)。为了将位置信息编码进每一个RoI矩形中,可将每个感兴趣区域划分成[k2]个格子(bin)。对于一个大小为[w?h]的RoI矩形,格子大小约为[wk?hk]。同时,R-FCN网络最后一个卷积层为每一类及其位置信息重组了[k2]个分数图。定义第[(i,j)]个格子[(0i,jk-1)]的池化操作函数为:
1.4 分类与定位
对于分类问题,假设共有[c]类目标,利用[k2]個位置敏感分数特征图进行投票,可以产生一个[(c+1)]维向量(包含一个背景类)。
然后,使用softmax函数跨类别计算每个类别的概率值。
对于定位问题,对每个感兴趣区域的每一类产生4[k2]个元素向量,并进行投票。利用Faster R-CNN网络的位置回归参数化方法,可得到一个一维向量[(tx,ty,tw,th)],此为检测目标的定位信息。
2 网络优化
2.1 模型压缩
深度学习网络相对于传统图像处理技术,运行速度较慢,主要原因是网络过于臃肿庞大、计算量大,不适宜应用到嵌入式设备上。因此,进行适当的模型压缩是加速网络运行速度的一种可行方法。近年来,模型压缩算法从压缩方式上可以大致分为两大类:权值压缩和网络结构压缩。权值压缩方法包括Deep Compression方式、XNorNet方式等,网络结构压缩方法包括SqueezeNet方式、Distilling方式和ShuffleNet方式等[16-19]。
本文采用ShuffleNet技术对前端残差网络进行压缩。相对于传统权值压缩方法,ShuffleNet更容易平衡精度与压缩程度之间的矛盾。同时,该模型既可以对网络存储空间进行压缩,又可以提高运行速度。ShuffleNet网络由MobileNet分组思想演化而来,主要优化策略是分组卷积和组间通信,如图3所示[20]。
标准卷积层一般对输入数据的所有通道进行卷积计算,然而在小型网络中,计算代价昂贵。为了解决该问题,一个简单方式是使用通道稀疏连接方式,例如组卷积。通过确保每个卷积只在相应输入通道组上运行,组卷积可以大大降低计算成本。然而,如果多个层的组卷积叠加在一起,就会产生一个副作用:来自某个通道的输出只能从一小部分输入通道中获得,该属性将阻止通道组之间的信息流动。
如果允许组卷积从不同组获得输入数据,如图3(a)所示,则输入和输出通道将完全互相依赖。具体来说,对于上一层生成的特征图,可以先将其划分为几个组,然后用不同组的部分通道填充下一层的每个组。如此,就可以通过一个shuffle操作高效而简单地实现组间通信,如图3(b)。此外,通道shuffle也是可微分的,意味着它可以嵌入到网络结构中,实现端到端训练。
本文利用ShuffleNet机制对R-FCN的残差网络进行压缩。假设残差网络输入维度是[c*h*w],瓶颈层通道数为[m],则该结构单元计算量为[hw(2cm+9m2)]FLOP,而经过ShuffleNet压缩后,计算量仅为[hw(2cm/g+9m)]FLOP,其中[g]为分组个数。所以,给定计算预算,ShuffleNet可以使用更广泛的特征映射,这对于小网络至关重要,因为小网络通常没有足够的通道处理信息。
2.2 Soft-NMS算法
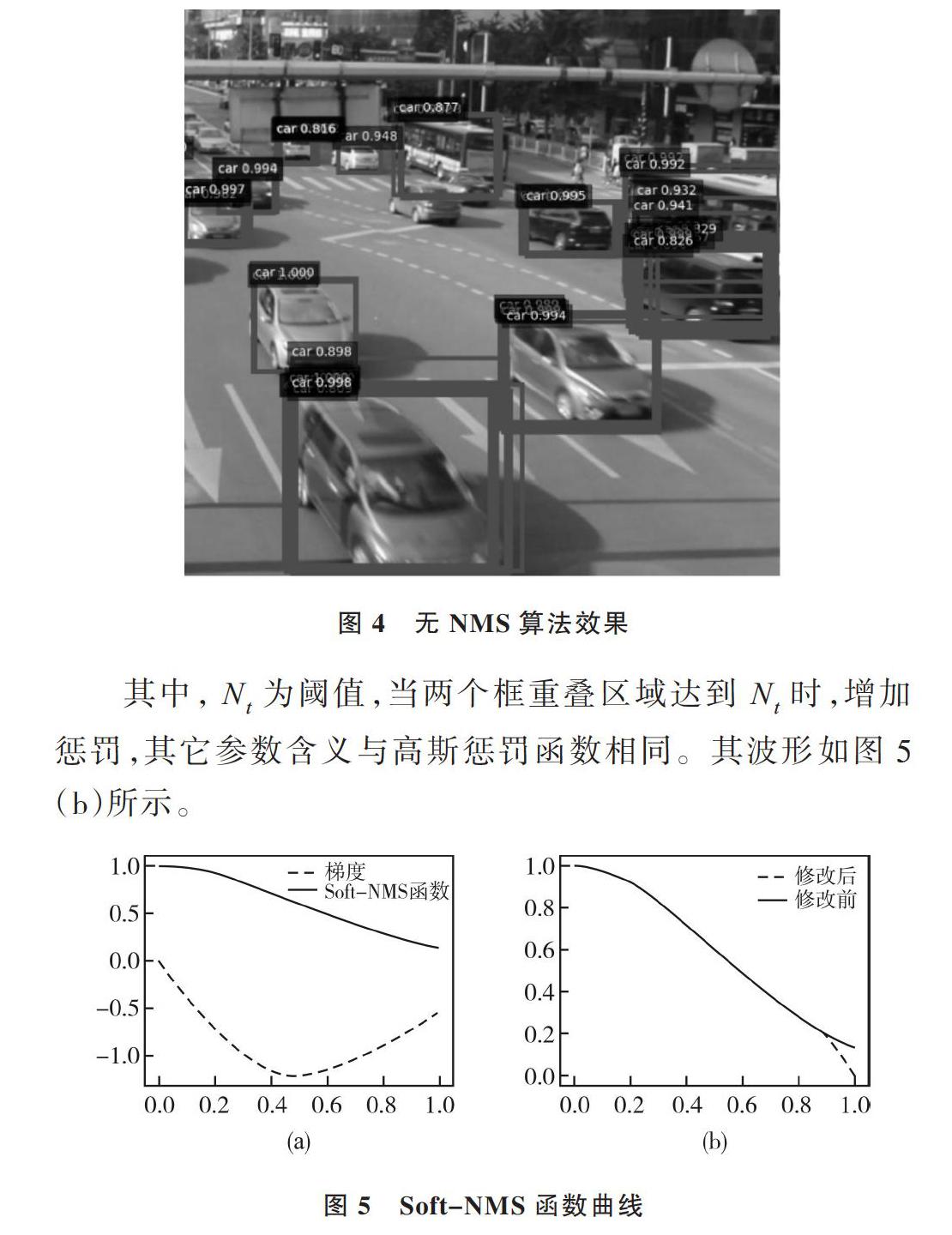
NMS算法是目标检测网络的重要组成部分,主要用于减少预测框,对重叠的预测框进行非极大值抑制。首先,它会根据预测框的得分从大到小排序,选择得分最高的预测框作为极大值框,当其它预测框与其重叠程度超过一定阈值时,在排序列表中将非极大值框排除。该过程会被递归调用到下一个得分最大的预测框,直到遍历完所有框。预测框减少将会大大降低网络计算量,同时预防同一目标产生多个预测框。NMS算法的一个主要问题是,它将相邻预测框的得分强制设为0。因此,若两个目标实际上相互重叠,而且其重叠度大于NMS算法所设定阈值,其中一个将会被遗漏,导致精度下降。然而,如果不强制设为0,而是降低得分,它依然会出现在排序列表中,依然可能被检测到,提高网络检测精度。
[10] ZHANG X Y, ZHOU X Y, LIN M X, et al. Shufflenet: an extremely efficient convolutional neural network for mobile devices[C]. Salt Lake City: CVPR,2018.
[11] HE K, ZHANG X,REN S,et al. Deep residual learning for image recognition[C]. Las Vegas:CVPR,2016.
[12] 周俊宇,趙艳明. 卷积神经网络在图像分类和目标检测应用综述[J]. 计算机工程与应用,2017,53(13):34-41.
[13] REN S Q,HE K M,GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,39(6):1137-1149.
[14] KRIZHEVSKY A, SUTSKEVER I, HINTON G. Imagenet classification with deep convolutional neural networks[C]. Lake Tahoe: NIPS,2012.
[15] SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. San Diego:ICLR,2015.
[16] HAN S, MAO H, DALLY W J, et al. Deep compression:compressing deep neural networks with pruning, trained quantization and huffman coding[C]. San Juan:ICLR,2016.
[17] MOHAMMAD R,VICENTE O,JOSEPH R, et al. XNOR-Net: ImageNet classification using binary convolutional neural networks[C]. Amsterdam:ECCV,2016.
[18] IANDOLA F N, HAN S, MOSKEWICZ M W,et al. Squeezenet:alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size[C]. Toulon:ICLR,2017.
[19] HINTON,GEOFFREY,VINYALS,et al. Distilling the knowledge in a neural network[C]. Montreal:NIPS,2014.
[20] HOWARD A G, ZHU M, CHEN B,et al. MobileNets: efficient convolutional neural networks for mobile vision applications[DB/OL]. https://arxiv.org/pdf/1704.04861.pdf.
[21] WEN L Y, DU D W,CAI Z W,et al. UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking[EB/OL]. http://detrac-db.rit.albany.edu.
[22] RICHARD,SZELISKI. 计算机视觉——算法与应用[M]. 艾海舟,兴军亮,译. 北京:清华大学出版社,2012.
(责任编辑:何 丽)
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
现代电子技术(2016年22期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
