
机器学习领域研究热点与前沿演进
2019-10-18 02:57张福俊赵文斌叶权慧
软件导刊 2019年9期
关键词:机器学习
张福俊 赵文斌 叶权慧


摘 要:基于CiteSpace采用文献计量法,分析总结机器学习领域近十年研究热点与技术前沿演进。研究结果显示,该领域热点算法有Classification(分类算法)、Support Vector Machine(支持向量机)等,热点框架有sorFlow、Caffe、PaddlePaddle等;数据库、序列等突变词共同组成了近十年的研究新兴领域。
关键词:CiteSpace;科学知识图谱;机器学习;前沿演进;文献计量法
DOI:10. 11907/rjdk. 191877 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2019)009-0005-04
Research Hotspots and Frontier Evolution in the Field of Machine Learning
——Visual Analysis Based on CiteSpace
ZHANG Fu-jun,ZHAO Wen-bin,YE Quan-hui,GAO Xue,WAN Hao
(Computer Science and Engineering,Shandong University of Science and Technology, Qingdao 266590, China)
Abstract: In order to acquaintance?the gradual progress?of research hotspots and technology?forward position?in the field of machine learning in recent ten years, this paper uses Cite Space's bibliometric method to analyze?the results. It is found that hot algorithms include classification (classification algorithm), support vector machine (support vector machine), and so on; hot frameworks include sorFlow, Caffe, Paddle Paddle etc. Mutation words such as databases and sequences have together made up?a new and developing domain of study?in the past decade.
Key Words: CiteSpace; mapping knowledge domain; machine learning; evolution of frontier; bibliometric method
0 引言
随着科学技术的不断发展,所需处理的数据量也呈几何倍数增长[1],海量数据的复杂性和快速变化给人们检索有价值的信息带来了许多新问题,由此知识可视化研究方法应运而生[2]。当前,国际上被广泛应用的知识可视化软件[3]有Thomson Reuters 公司开发的Pajek[4],以及陈超美教授团队研发的 CiteSpace[5]等。在空间上,图谱分析软件可以通过共现以及社会网络分析等方法分析文献所属区域,机构、作者等结构关系;在时间上,通过动态的时间维度,绘制“知识发展进程谱”,直观展示知识演变进程[6]。随着人工智能应用的日益广泛与机器学习技术的不断精进,相关研究也不断深入,只有了解和把握学科发展前沿动态,积极探究学科研究热点才能对该领域研究整体方向有更加准确的定位。本文利用文献计量学方法对机器学习关键词进行共现分析和突变分析,挖掘机器学习研究热点,并对機器学习文献作耦合分析,进行领域前沿挖掘。
1 研究设计
1.1 数据来源
研究的原始数据来源于 Web of Science 平台上的核心合集数据库,包括SCI-EXPANDED、SSCI、A&HCI、CPCI-S、ESCI、CCR-EXPANDED、IC)。为确保研究数据的客观性和全面性,选择Machine Learning为检索主题词,检索策略为:数据库选择Web of Science核心合集,输入主题词TS=“machine learning”,选择检索时间跨度为2008-2018年;将文献类型精炼为“ARTICLE”,筛选得到34 835条检索结果;选择导出数据格式为全著录格式分次下载(每次下载条目<=500),CiteSpaces规定格式 download*.txt 命名,保存在同一个文件 data 内,作为绘制图谱的基础数据,并在同一文件夹建立project。
1.2 研究方法与工具
文献计量分析主要以文献为数据源,包括搜集、整理和分析三大基本过程。本文以Web of Science数据库中2008-2018年机器学习论文作为数据源,对其作除重清洗,并以不同的视角和维度进行计量分析。知识图谱分析是可视化分析的一个分类,是将分析结果以节点和连线的形式展现出来,节点代表被研究对象,连线表示两个研究对象之间的关系强度,使得分析结果更加美观和直接。本文运用的知识图谱工具是由美国 Drexel大学陈超美博士基于Java 平台开发的 CiteSpace,该软件可对科学文献的新趋势和新动态进行识别与可视化分析,被广泛应用于科学文献计量领域。基于CiteSpace运用文献计量学方法挖掘机器学习领域的时空分布、作者合作网络、研究热点及研究前沿。
2 机器学习研究热点与前沿趋势分析
2.1 研究热点分析
关键词是对文献主旨内容与作者意图的概括,是文献中的核心和精髓。某领域的研究热点往往是指在某一阶段该领域文献出现的高频次、高中心度以及高突现强度的主题词。共词分析法基于该领域近十年文献绘制机器学习领域的关键词共现图谱,并统计其中高频次关键词,明确近十年机器学习领域研究热点,进而分析其演化发展过程。将数据导入 CiteSpace,调整参数后结果如图1所示(见封三彩图)。
机器学习领域关键词共现知识图谱中共有节点N(42)个,连线E(94)条,中心度(Density=0.109 2)。首先圈的大小代表着该关键词在2008-2018年这10年间出现的频率,圈从大到小依次为: machine learning(机器学习)、classification(分类)、support vector machine(支持向量机)、algorithm(算法)、model(模型)、neural network(神经网络)、system(系统)等等。由于该文献主要研究机器学习,因此第一个关键词没有分析意义,也即classification(分类)、support vector machine(支持向量机)、algorithm(算法)、model(模块)、neural network(神经网络)、system(系统)等组成了近十年机器学习的研究热点。每一个圈最外围的紫色越重,则证明该关键词的中心性越高,说明该关键词在近十年研究中起到了不可或缺的作用,例如图中紫色最深的为分类,说明分类这个词足以称为该领域的热点词,有着重要贡献,代表了研究热点。点与点之间的连线颜色表明这两个词首次共现的年份,连线的粗细则证明了这两个关键词的联系紧密程度,联系越紧密连线越粗,否则相反,从图1中可以看出,classification(分类)和support vector machine(支持向量机)这两个关键词的连线为深蓝色,也即这两个关键词首次共现的时间是2008年。将图1聚类后如图2所示(见封三彩图)。
将关键词进行聚类后,出现了六大类,这其中最大的群集(#0)有9个成员,轮廓值为0.488。它被LLR标记为users skill level(用户技能水平),由TFIDF算法得出的标签是classifing(分类),最活跃的聚类引用是论文Scheduling Jobs with an Exponential Sum-of-Actual-Processing-time- based Learning Effect[12]。
第二大聚类(#1)有9名成员,轮廓值为0.671。它被称为由LLID算法得到classifying human physical activity (人体力活动),由TFIDF算法标记为 machine(机器分类)。其中最活跃的文章是Machine Learning Methods for Classifying Human Physical Activity from On-body Accelerometers[13]。
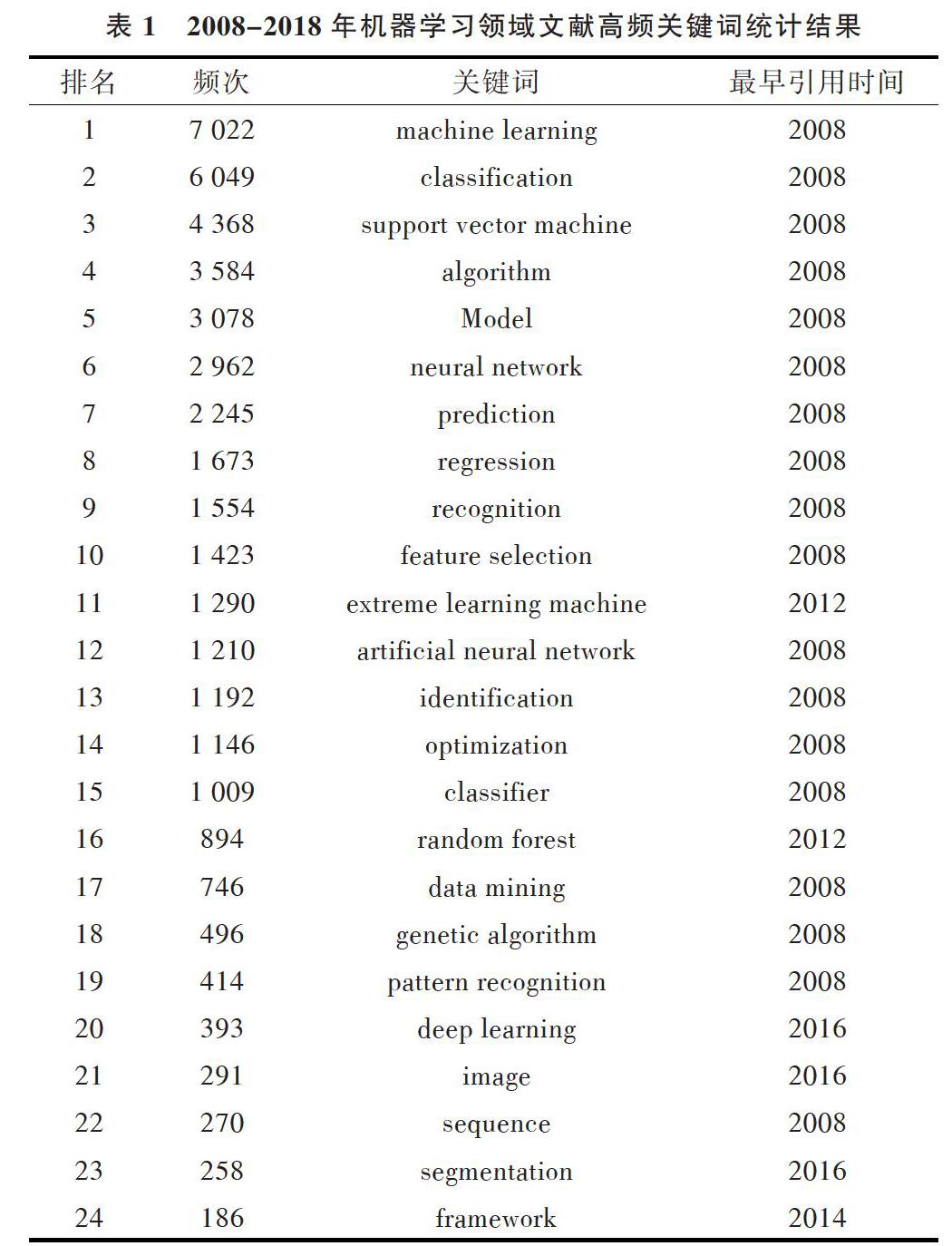
将上述CiteSpaces中提供的数据进行整理统计如表1所示。
由于本文研究的主题就是机器学习,因此排名第一的machine learning可以忽略,其热点词可分为两大类:algorithm(算法)、framework(框架)。这些热点词仅仅是最基本的词汇,本文将逐一分析,以找出近十年机器学习领域的研究热点。
近十年流行的机器学习算法中,表1中呈现的有如下:
(1)表中排名第二的热点词classification(分类算法)。分类算法中有一种很简单且目前也很流行的算法为朴素贝叶斯分类。朴素贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。其主要应用于论文分类处理、舆情分析等。
(3)表中排名第三的热点词support vector machine(支持向量机)。支持向量机(SVM)是二元分类算法,给定一组两种类型的N维地方点,SVM产生一个(N - 1)维超平面到这些点并分成2组。假设你有两种类型的点,且它们是线性可分的。 SVM将找到一条直线将这些点分成2种类型,并且这条直线会尽可能地远离所有点。当下使用support vector machine(支持向量机)处理的主要问题为商业广告显示、面部识别剪接位点处理、数据量差大的图片处理等。
(4)表中排第八位的热点词regression(回归算法)。回归算法中的逻辑回归是一种强大的统计方法。通过估算使用逻辑运算的概率,测量分类依赖变量和一个(或多个)独立变量之间的关系,是累积的逻辑分布情况。目前,逻辑回归主要用于车流分析、使用评分、衡量营销活动的成功率等。
(5)表中排名第六的热点词 neural network(神经网络)。属于神经网络的算法有很多,近十年比较突出的为递归神经网络,实际上递归神经网络是两种人工神经网络的总称, 一种是时间递归神经网络(Recurrent Neural Network),另一种是结构递归神经网络(Recursive Neural Network)。随着电脑硬件的不断提升,可以处理的神经网络层数不断加深,这为后续研究Deep Learning(深度学习)打下了基础。
(6)表中排名第十六的热点词 random forest(随机森林)。随机森林算法结合了多个树,使用随机挑选的数据子集,以提升决策树的分析准确率。随机森林算法的优势在于能够处理大規模数据集,以及大量看似不相关的数据,可以用于风险评估和客户信息分析。
目前,机器学习领域的Deep Learning(深度学习)受到广泛关注。Deep Learning(深度学习)领域常用四大框架: ①TensorFlow,它最初由谷歌的Machine Intelligence research organization 中Google Brain Team的研究人员和工程师开发;②Neon,它是Nervana开发的基于Python的深度学习库,它易于使用,同时性能也处于最高水准;③Caffe,它是一个重在表达性、速度和模块化的深度学习框架,由 Berkeley Vision and Learning Center和社区贡献者共同开发;④DeepLearning4J,它和ND4J、DataVec、Arbiter及RL4J一样,都是Skymind Intelligence Layer的一部分。
2.2 研究前沿演進分析
利用CiteSpace中突变检测(Burst Detection)功能,对近十年全部文献中的关键词探测出突变词术语,利用词频的时间分布、变化趋势并结合词频,找出该领域研究前沿演进[14]。2008-2018 年机器学习研究领域突变词如表2所示。
在2008-2018年期间共出现了12个突变词,分别为database (数据库)、sequence(序列)、framework(框架)、deep learning (深度学习)、segmentation(分割处理)、image(镜像)即图像识别、genetic algorithm(遗传算法)、pattern recognition(模式识别)、scheduling(时序安排)、learning effect(学习效果)、pattern(模式)、decision tree(决策树),这些突变词共同组成了近十年机器学习领域的研究前沿和研究新兴领域。
将这12个关键词分为两个时间段,以更好地呈现机器学习在这十年中的前沿演进。2008-2009年,机器学习相关研究还仅仅停留在Decision Tree(决策树)和Pattern(模式)方面,主要原因在于当时硬件设备不能满足数据运算要求。随着技术的不断更新和计算机硬件设备的发展,2010-2011年,机器学习的研究重点也发生了变化,Scheduling(时序安排)、Learning Effect(学习效果)这两个词占据了研究前沿位置,机器学习迎来了一个全新的研究领域。2014-2015年,framework(框架)再度成为当时的研究热点,主要研究框架有TensorFlow、Keras、Caffe等,这些框架为神经网络发展和后续深度学习打下了基础。
2016-2018年,研究者更倾向于机器学习的进一步探索,也即对多层神经网络进行深入发掘,机器学习领域来到了Deep Learning (深度学习)时代,许多学者相继提出了新的算法模型,例如卷积神经网络、深层神经网络、深层信念网络等,同时深度学习也开始应用于不同的领域,如图像物体分类、Image(镜像)即图像识别、Segmentation(分割处理)、Pattern Recognition(模式识别)等不同层面。由此可知,目前机器学习领域的研究侧重点在深度学习领域,深度学习仍处于不断发展和应用阶段,深度学习领域更快速、便捷、合适的算法也有待进一步研究和提出。
3 结语
本文通过在Web of Science核心合集下载2008-2018年的文献数据,结合机器学习、知识图谱、研究前沿的相关理论与技术构建机器学习知识图谱。研究结论为:根据知识图谱共现和表中信息将近十年的热点按Algorithm(算法)和Framework(框架)两大类进行分析,热点算法有:Classification(分类算法)、Support Vector Machine(支持向量机)、Regression(回归算法)、Neural Network(神经网络)、Random Forest(随机森林)等;热点框架有:sorFlow、Caffe、PaddlePaddle等。数据库、序列、框架、深度学习、分割、镜像、遗传算法、模式识别、时序安排、学习效果、决策树,这些突变词共同组成了近十年机器学习领域的研究前沿和研究新兴领域。
在前期准备工作时,由于数据库所提供的论文作者都是拼音简写,使得数据核对十分繁琐且容易出错,希望Web of Science数据库在收录文章时能使用作者全称,以保证查询的精准性。
参考文献:
[1] 机器学习发展现状及应用的研究[EB/OL]. http://www.fx361.com/page/2018/0601/3608221.shtml.
[2] 史纪元. 基于CiteSpaceⅢ输血医学研究领域知识图谱分析[D]. 西安:第四军医大学,2015.
[3] 杜文龙. 引文分析软件的应用比较分析研究[D]. 西安:西北大学,2013.
[4] 李杰,陈超美. CiteSpace:科技文本挖掘及可视化[M]. 北京:首都经济贸易大学出版社,2016.
[5] 刘则渊,陈超美,侯海燕,等. 迈向科学学大变革的时代[J]. 科学学与科学技术管理,2009,30(7):5-12.
[6] 赵玉鹏. 基于知识图谱的机器学习研究前沿探析[J]. 情报杂志, 2012,31(4):28-31.
[7] 焦李成,杨淑媛,刘芳,等. 神经网络七十年:回顾与展望[J]. 计算机学报,2016,39(8):1697-1716.
[8] 张福俊,周忠学,尹燕霞,等. 青岛理工大学基于SCI论文的文献计量学分析[J]. 青岛理工大学学报,2013,34(4):115-119.
[9] ZHANG Y. I-TASSER: fully automated protein structure prediction in CASP8[J]. Proteins Structure Function & Bioinformatics, 2009,77(Supplement S9):100-113.
[10] LIU Q, WANG J. A one-layer recurrent neural network with a discontinuous hard-limiting activation function for quadratic programming[J]. IEEE Transactions on Neural Networks, 2008,19(4):558-70.
[11] MALLAPRAGADA P K, JIN R, JAIN A K, et al. SemiBoost: boosting for semi-supervised learning[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2009,31(11):2000-2014.
[12] WANG J B, SUN L H, SUN L Y. Scheduling jobs with an exponential sum-of-actual-processing-time-based learning effect[J]. Computers & Mathematics with Applications,2010,60(9):2673-2678.
[13] NNINI A,SABATINI A M.Machine learning methods for classifying human physical activity from on-body accelerometers[J]. Sensors,2010,10(2):1154-1175.
[14] 张福俊,叶权慧,于路云. 基于知识图谱的海洋科学领域技术机会分析[J]. 科技管理研究,2017,37(24):165-170.
[15] CHANG C C, LIN C J. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011(2):1-27.
[16] DEPRISTO M A,BANKS E,POPLIN R E,et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data[J]. Nature Genetics,2011,43(5):491-8.
[17] HUANG G B,ZHOU H,DING X,et al. Extreme learning machine for regression and multiclass classification[J]. IEEE Transactions on Systems Man & Cybernetics Part B, 2012, 42(2):513-529.
[18] 張福俊,刘桂仁,刘谦,等. 山东省国内专利文献计量学分析[J]. 科技管理研究,2013,33(1):60-63.
[19] 王声培,云雅娟. 洛特卡定律、普赖斯定律和我国数学科学文献[J]. 图书情报工作,1994(3):21-24.
[20] 张福俊. 基于SCI论文引证的学术期刊信息服务——以《山东科技大学学报(自然科学版)》为例[J]. 山东科技大学学报:自然科学版,2013,32(5):107-110.
[20] 于路云. 基于知识图谱的国际海洋习研究前沿与技术机会分析[D]. 青岛:山东科技大学,2017.
[21] 张润,王永滨. 机器学习及其算法和发展研究[J]. 中国传媒大学学报:自然科学版, 2016,23(2):10-18.
(责任编辑:孙 娟)
猜你喜欢
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
