
基于Labeled-LDA的列控车载设备故障特征提取与诊断方法研究
2019-10-18 08:02上官伟袁亚辉胡福威
铁道学报 2019年8期
上官伟,袁亚辉,王 剑,胡福威
(1.北京交通大学 电子信息工程学院,北京 100044;2.北京交通大学 轨道交通控制与安全国家重点实验室,北京 100044)
高速铁路以其特有的快捷性与舒适性,得到大众的普遍认可。进一步提高列控系统的可靠度对于保证高速铁路长时间无故障运行以及改善旅客的满意度具有重要意义。车载设备的可靠度直接影响整个列控系统的可靠度,是列控系统的核心组成部分。车载设备的正常运行,对于确保铁路运输有序进行具有重要意义。在列车运行过程中,车载设备一旦发生故障,不仅会影响运输效率,严重时还会导致人员伤亡。车载设备的故障日志数据记录了车载设备的运行情况,专业技术人员据此可以得到车载设备所发生故障的具体类型,但此方法严重依赖现场的经验知识。不同厂家的车载设备对于故障数据的记录各不相同,再加上诱发车载设备故障的因素也多种多样,这给技术人员准确诊断出车载设备所发生的具体故障类型带来了挑战。因此,进一步研究车载设备的故障诊断算法对于降低故障分析人员的技术门槛,实现车载设备故障的及时检修与维护,提高高铁运行的安全性意义重大。
故障诊断是利用有效的手段检测系统是否有故障发生,并进一步确认故障发生的位置和类型等。针对研究的对象和诊断方式的不同,故障诊断方法可以分为以下三类:基于经验知识的方法、基于解析模型的方法和基于数据驱动的方法[1-2]。针对列控系统的复杂性和实时性,文献[3]采用贝叶斯网络模拟列控系统的结构,以此为基础提出了列控系统的故障诊断和维修方法。文献[4]针对车载设备故障数据中含有的冗余信息,引入粗糙集算法,在一定程度上剔除了故障数据的重复属性,采用专家知识与解析模型结合的故障诊断方法对车载设备进行故障诊断。文献[5]将模糊理论引入故障诊断中,建立了基于模糊理论和贝叶斯推理的故障诊断模型。
传统的故障诊断方法针对不同型号的车载设备适应性差,为了提高故障诊断算法的适应性,直接分析具体型号的车载设备记录的故障数据,利用数据挖掘的方法识别车载设备的故障类型已成为一个新的研究方向。主题模型对于文本语义提取方面具有特有优势,文献[6]提出了基于主题模型和支持向量机的故障诊断方法,相比传统的缺乏先验知识的文本挖掘故障诊断方法有较大改善。文献[7]将主题模型引入车载设备的故障诊断中,但是未考虑铁路领域先验知识的影响,其实用性亟需改善。文献[8]分析列控系统的结构,研究系统不同部分之间的信息流向。在此基础上进一步分析系统日志文件构建知识库,结合现场实际情况实现了列控系统的故障诊断。
本文采用主题模型(Topic Models)实现对日志数据的语义特征提取。主题模型是一种无监督机器学习模型,能够有效挖掘文档中的主题之间的相互联系。文献[9]利用LDA模型解决了文本聚类问题,并采用F-measure值评估聚类效果。文献[10]利用WNTM模型对维基百科的数据信息进行话题分析,从中抽取主题,进而实现按照主题对文本的分类。文献[11-13]在处理文本分类问题时,也引入主题模型并达到了预期效果。主题模型能够有效提取文本的语义信息,挖掘文档和词项之间的潜在语义关联信息[14]。
本文通过对300T车载日志的特点进行分析,采用改进的LDA模型构建特征向量空间,实现日志文本数据的特征提取;由于样本日志数据的不均衡分布,采用粒子群优化算法对SVM的分类参数进行优化,用以改善分类器的诊断性能。以300T车载设备为分析对象,以300T车载日志为故障诊断样本数据,最终实现对车载设备的故障诊断。车载设备的结构组成如图1所示。
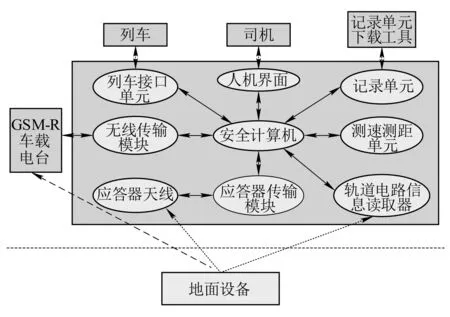
图1 车载设备结构组成
1 车载日志数据分析
常见的车载设备类型有300T、300S、300H、200H、200C、C3D六种,其中300T的故障数据是以txt形式存储,可读性较强且易于分析。
为了较为清晰地对车载设备进行分类诊断,参考高铁技术人员培训教材,并结合专家的经验知识,车载设备的故障类型被划分为两个等级。一级故障的故障类型主要是构成车载设备的某一模块发生故障的集合,较为笼统;二级故障在一级故障的基础上更为具体地定位到单个的故障种类。车载设备常见故障等级划分如图2所示。
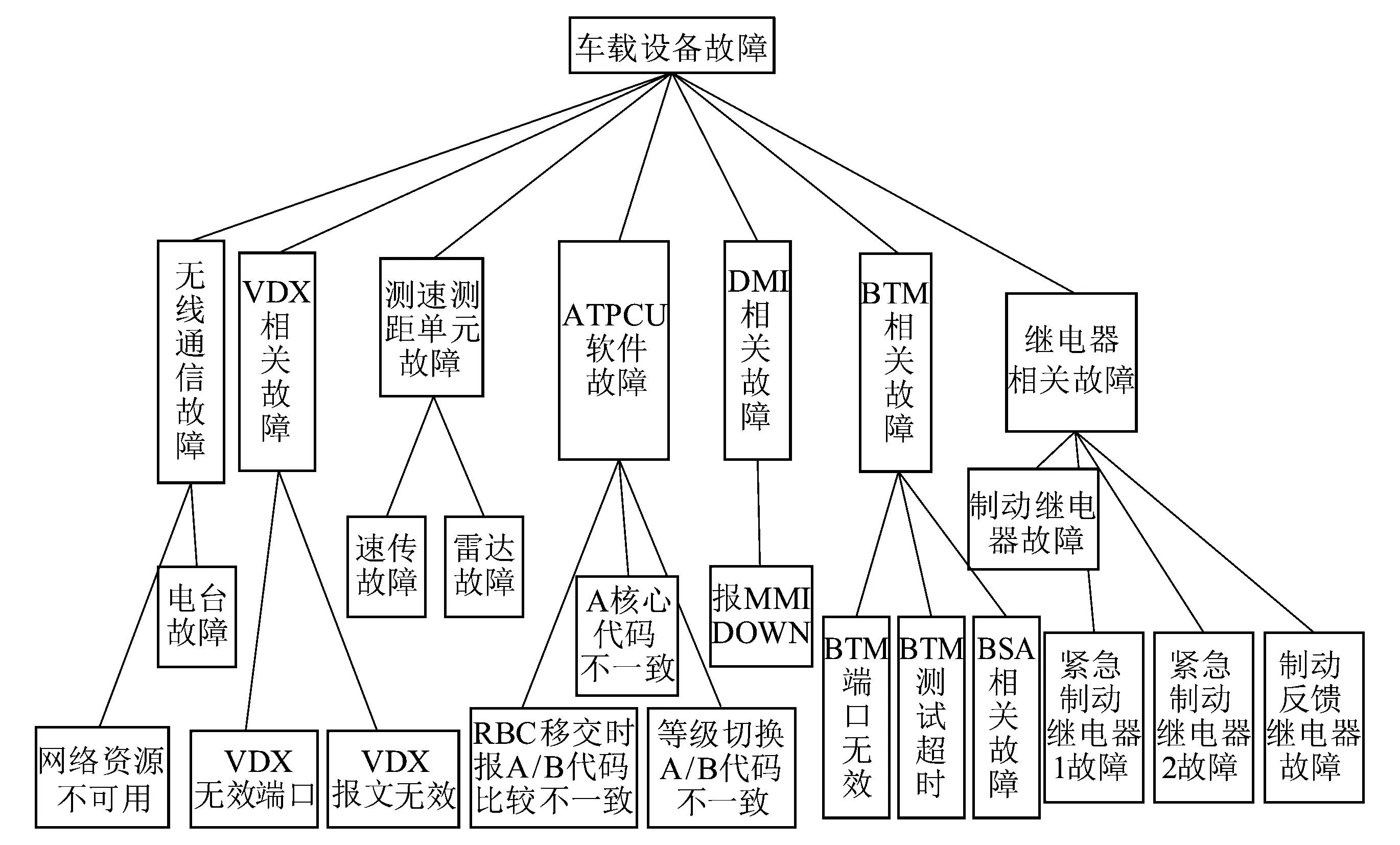
图2 车载设备常见故障等级划分
1.1 车载日志数据
300T车载日志数据能够有效记录系统运行的状态,系统的正常启机过程以及故障状态均会以特定的语句记录在一块非易失存储区中。Tracing Log和AE Log均可从该储存区中使用相应的命令导出。Log文件的记录采用堆栈的方式,最先发生的事件记录在文件末端。因此,在阅读日志文件时,需注意文档的阅读顺序。
日志数据是以txt文档的形式进行存储的,在对Log数据进行分析时,需要从系统的启机语句开始分析,即“Initialised and Started”之后向上查询车载设备的运行状态变化,分析车载设备的故障类型及发生时间。但是在分析故障类型时需要一个长时间经验的积累,因此,本文在后续的故障诊断中将结合专家经验进行分析诊断。为了较为清晰地说明日志数据的内容,表1列举了车载设备中部分故障类型的相关故障语句。
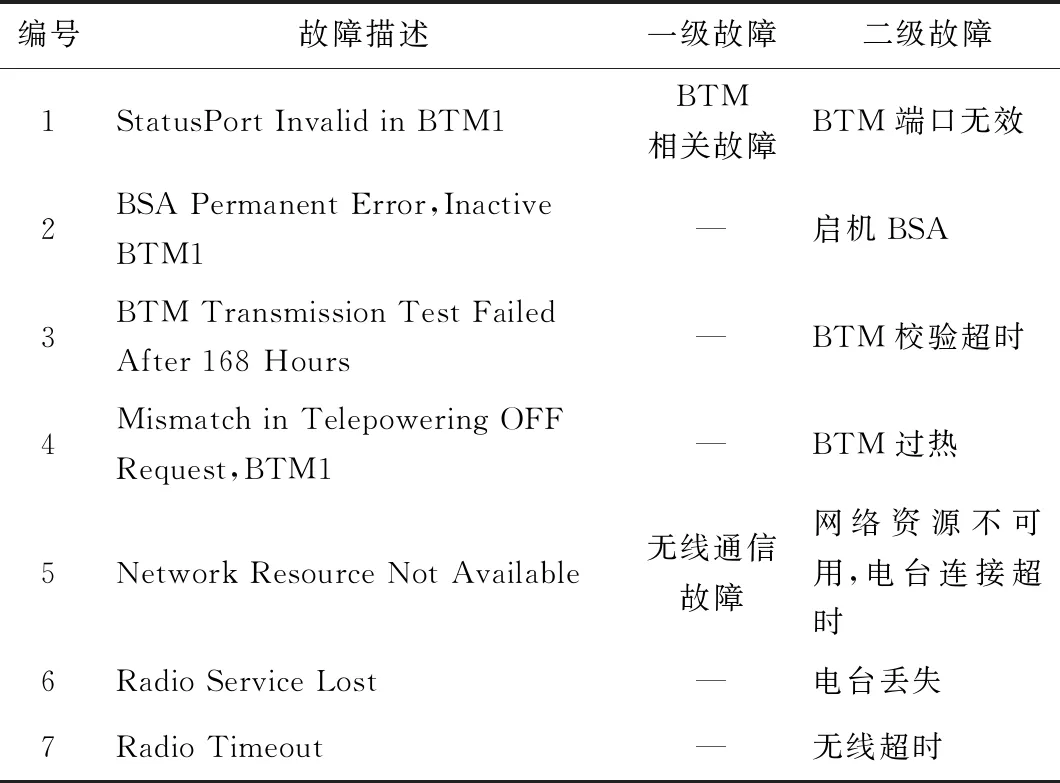
表1 故障语句实例
1.2 样本数据分布的不均衡性
本文以300T车载设备的2015全年和2016年上半年数据作为样本数据。通过统计样本数据各种故障类型的数目发现,车载设备在不同的故障模式之间具有明显的不均衡性。具体的故障类型所占比例见表2、表3。

表2 一级故障类型及样本比例 %
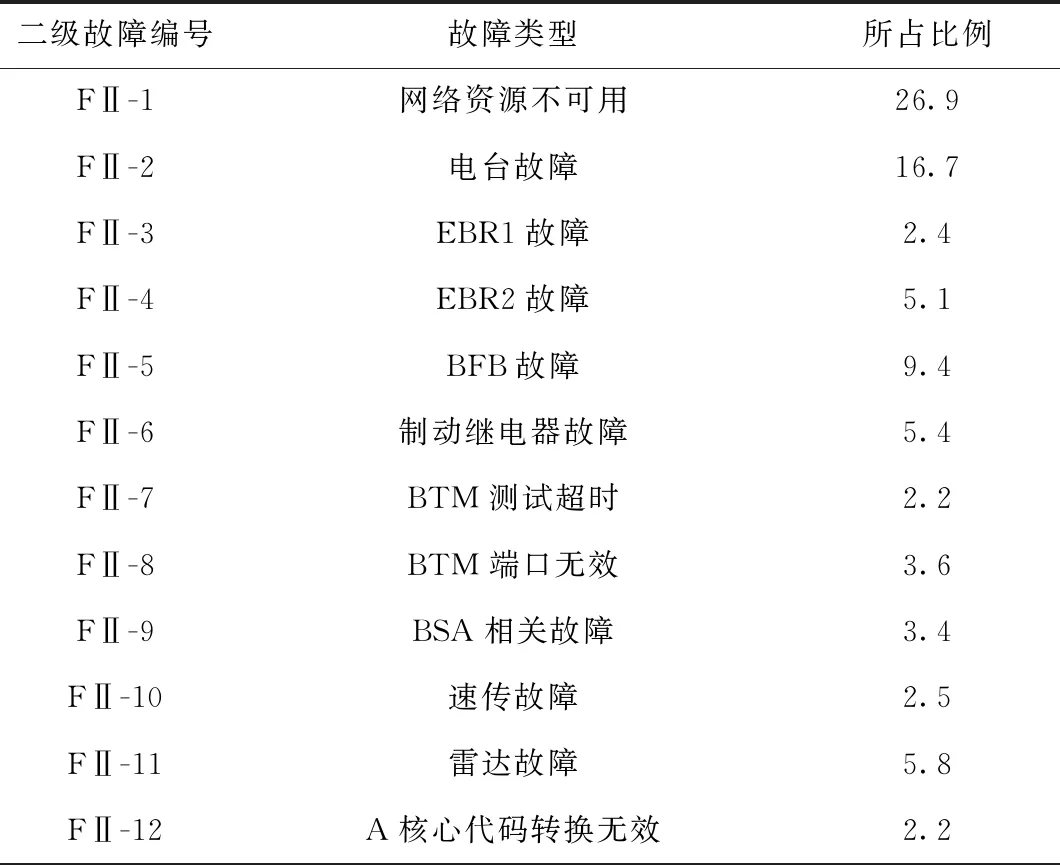
表3 二级故障类型及样本比例 %

表3(续)
通过表2可以得出,无线通信故障和继电器相关故障占据的比例较大,属于大类别故障;相对的其他几种故障类型比例较小,属于小类别故障。其中,FⅠ-1和FⅠ-7的样本比例接近10∶1;而FⅡ-1和FⅡ-14的样本比例接近18∶1。在进行诊断分类时,这种样本分布的不均衡性易将小类别的样本错误地诊断为大类别的故障类型,虽然诊断结果对于整体的准确率影响较小,但是对于分类器的分类性能是不可忽视的缺陷。
2 基于Labeled-LDA的车载日志特征提取
2.1 Labeled-LDA模型
Labeled-LDA以LDA模型为基础,在介绍Labeled-LDA(LLDA)模型之前,需要先了解LDA模型。
LDA是一种典型的语义分析模型。它认为一篇文档往往包含不止一个主题,文档中的每一个词均由特定的主题生成。文档到主题,主题到词项均服从多项式分布。LDA模型的概率图模型如图3所示。
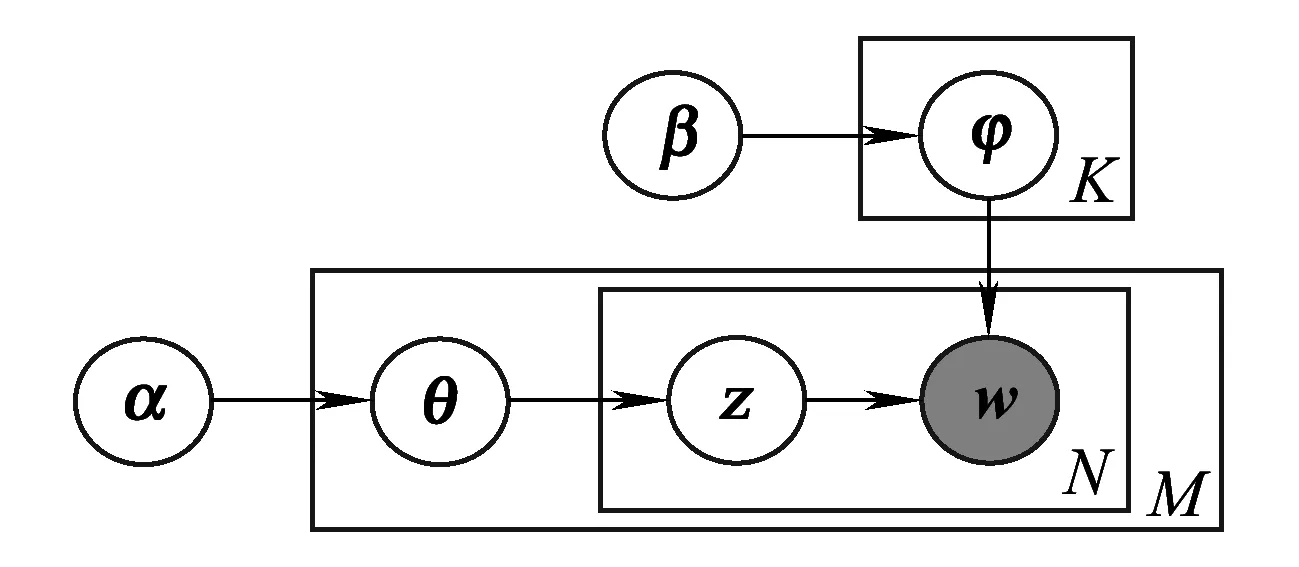
图3 LDA概率图模型
LDA模型中生成一篇文档的方法如下:对Dirichlet分布α进行取样,即可得到文档i的主题分布θi;对主题分布θi取样,得到第i个文档中第j个词项的主题zi,j;对Dirichlet分布β取样,生成第i个文档第j个主题的词语分布φzi,j;对φzi,j采样生成词项wi,j[15]。
LDA概率图模型中,已知参数为先验分布α和β,待求参数为文档主题和主题词项的分布即z和w,可以使用吉布斯采样估计LDA参数。具体过程如下[15]:
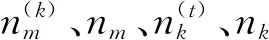
p(zi=k|z,w)=
(1)

当Gibbs采样过程收敛时,可输出文档-主题矩阵θ和主题-词项参数矩阵φ。
(2)
(3)
式中:θm,k为文档m中主题k的概率;φk,t为文档m中被分配到主题k的词项个数。
Labeled-LDA模型是一种改进的LDA模型,与LDA模型的区别在于,Labeled-LDA通过添加文本标签信息实现了标签与主题之间的映射关系。从图4能够明显看出LDA与LLDA之间的区别。
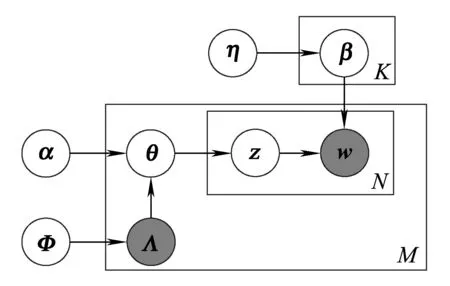
图4 LLDA概率图模型
LLDA的采样公式为
(4)
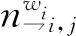
(5)
在已知LLDA模型的参数时,处理新的文本可采用吉布斯采样得到收敛后的文档主题分布为
(6)
2.2 改进的LLDA模型的特征提取方法
尽管利用主题模型分析文本自动化程度较高,但其作为一种无监督的机器学习算法,在提取信息的过程中仍然具有一定的盲目性,因此提出了改进的LLDA模型用于提取文本的故障特征。
为了使主题模型更好地应用到300T的故障数据分析中,先验知识被应用到特征提取过程。根据已知的车载设备常见的故障个数,预先设置文档的主题个数。将故障主题与现场技术人员的经验结合起来,构建故障特征词库,进一步简化提取文档主题的过程。不同的特征词项与主题关联的程度各不相同,使用卡方统计度量不同特征词项与主题关联的强弱,公式如下
(7)
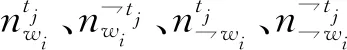
词项主题关联矩阵归一化后能够更加清晰地显示出每一个词项与主题之间的关联程度,初始化公式为
(8)
式(4)和式(5)可更新为
p(zi=j|z)=
(9)
(10)
基于改进的LLDA模型提取故障文本特征的流程如图5所示。
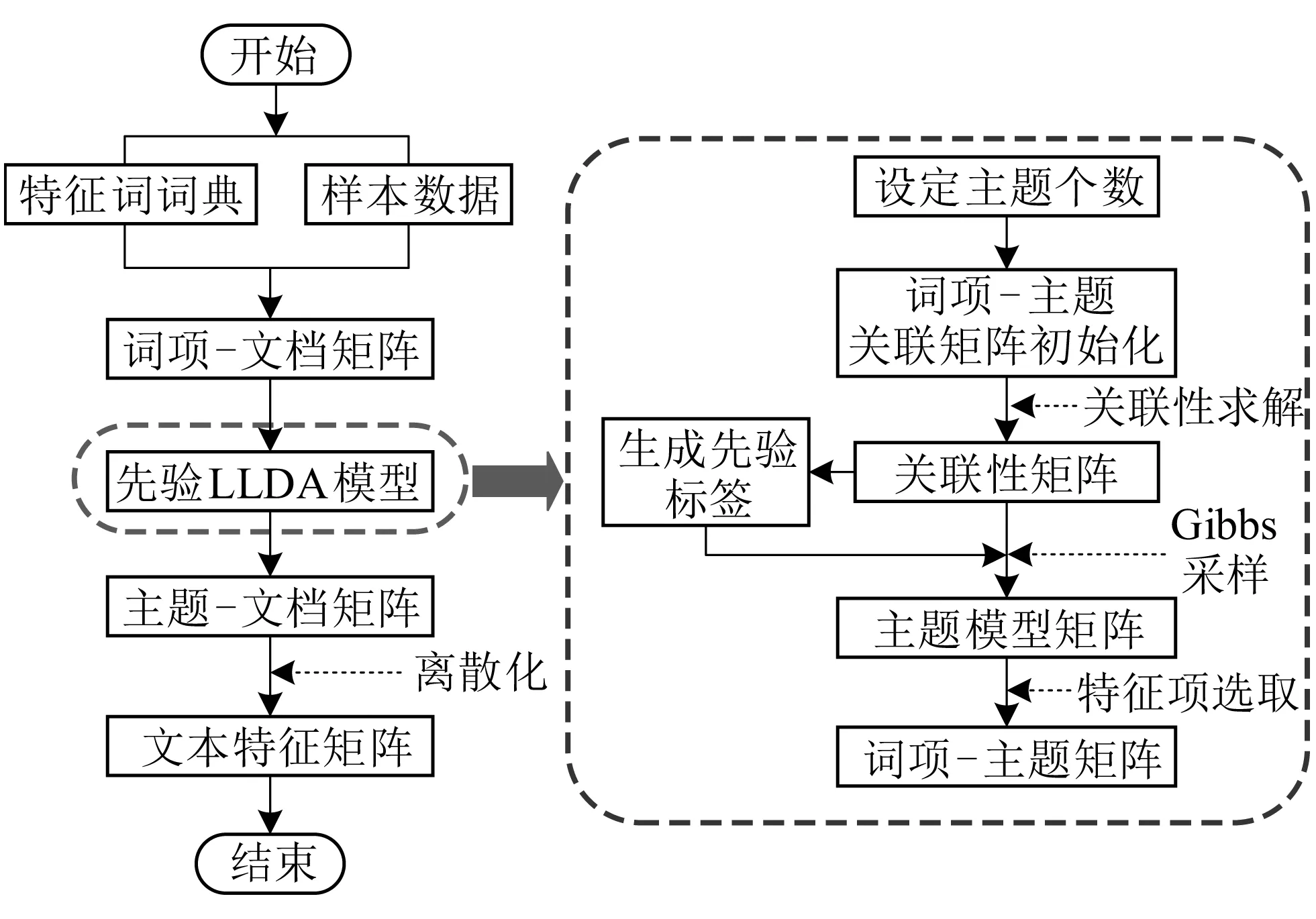
图5 LDA模型特征提取流程
3 基于SVM算法的故障诊断
3.1 SVM算法描述
支持向量机是在分类与回归分析中应用较为广泛的一种分类器方法。SVM模型将实例映射为空间中的点,能够有效地以明显的间隔将不同类别的实例区分出来。SVM不仅能够有效处理线性分类问题,也可以引入核函数方便地进行非线性分类。以二分类为例,分类平面如图6所示。
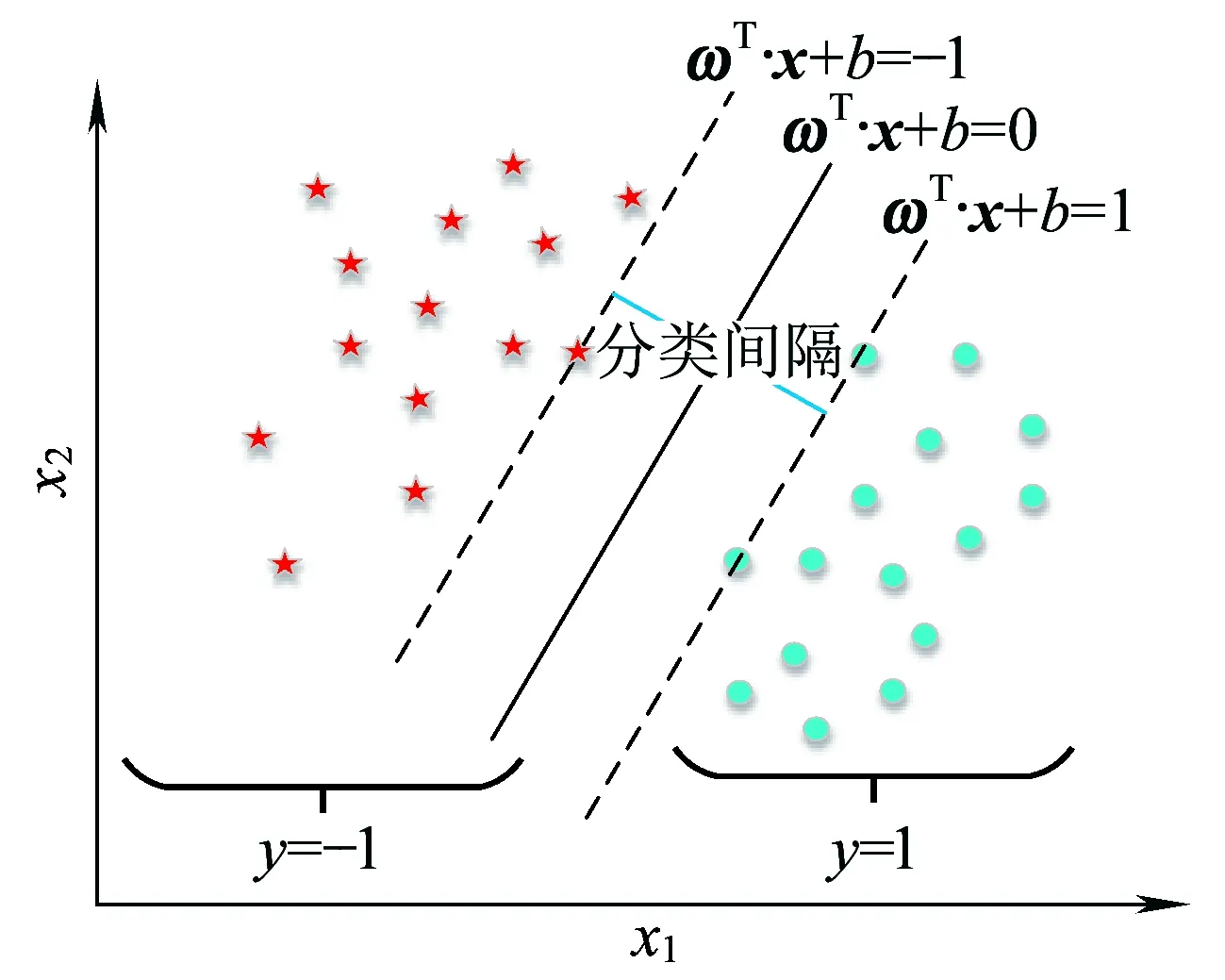
图6 SVM线性分类示意
其中,分类决策函数为
f(x)=ωTx+b
(11)
为了优化分类效果,可依据最大化分类间隔得到最优分类平面。
s.t.yi(ωTxi+b)≥1i=1,…,n
(12)
为了求解式(12),引入拉格朗日对偶性
(13)
由于在实际情况中,存在一些偏离决策平面的数据点,引入松弛变量ξi。因此式(13)可变换为
(14)
式中:C为惩罚因子,用于约束松弛变量。
对式(14)求偏导,整理后得到
(15)
s.t. 0≤ai≤Ci=1,…,n
(16)
为了获取向量a的值,引入序列最小最优化算法[16]SMO(Sequential Minimal Optimization),已知a可求得ω的值。根据式(17)求出b。
(17)
将数据点映射到高纬度空间,能够解决非线性不可分的情况,从而实现数据分类。但是,非线性映射会使得计算量大幅度增加。而在支持向量机中引入核函数的概念,则能够有效减少计算量。本文采用高斯核函数将其输入隐式映射到高纬度空间中,有效地进行非线性分类。
上述算法描述是针对二分类的情况,在现实生活中,大部分情况下数据点的类别多于两个。目前,SVM算法实现多分类方法的方式主要有两种:一对多方式和一对一方式。
3.2 SVM算法评价指标
在分类器的设计过程中,一个好的评价分类器性能的指标,既利于对模型的优化又可以直观说明分类器分类效果的优劣。混淆矩阵能够以可视化的形式展现分类的好坏程度。矩阵中的每一行代表了预测类别,每一列代表数据的真实归属类别。
准确率这一指标常被用来评价分类器的性能。准确率代表正确预测的样本数占预测总样本数的百分比。但是,当样本数据不同类别的比例存在较大差异时,准确率并不能全面反映分类器分类效果的好坏。这是因为小比例类别的样本易被误归类为大类别样本,但由于小比例样本数据较少,即使小类别样本的分类效果较差,分类器整体的准确率依然会很高。为了弥补准确率这一指标的缺陷,特引入F-measure作为评估指标,从而更加全面地评价分类器的优劣。
已知精确率Precison和召回率Recall可以计算出F-measure。精确率是指正确识别的个体总数占据识别出的个体总数的百分比。精确率能够直观表示预测类别中准确预测样本所占的比例。
P=Precision=TP/(TP+FP)
(18)
式中:TP为实际正类被预测为正类的个数;FP为实际负类被预测为正类的个数。
召回率是指正确识别的个体总数占据测试集中存在个体总数的百分比。
R=Recall=TP/(TP+FN)
(19)
式中:FN为正类被预测为负类的个数。
单独考虑每一故障类别的分类效果时,Precision和Recall有时会出现矛盾的情况;F-measure是Precision和Recall的加权调和平均,能够有效解决这一矛盾。F-measure的表达式为
(20)
式中:当参数μ=1时,就是常见的F1-measure,即
(21)
3.3 基于LDA故障特征提取的仿真分析
利用改进的LLDA模型提取日志文本特征后,采用SVM算法作为分类器,以词频方法WF(Word Frequency)和卡方统计CHI作为改进LLDA模型的比对算法进行仿真。
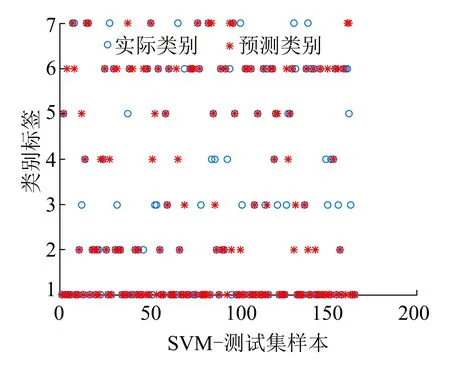
对比图7~图9可以发现,小类别样本数据的诊断结果出错的较多,并且在分类器一致的情况下,改进的LLDA模型的诊断准确率最高;同时,由于样本分布的不均衡性,可以发现,在诊断分类过程中小类别样本易被误诊断为大类别样本。在三种算法的混淆矩阵中,可以发现被错误分类的样本倾向于诊断为F1和F6两种类别。
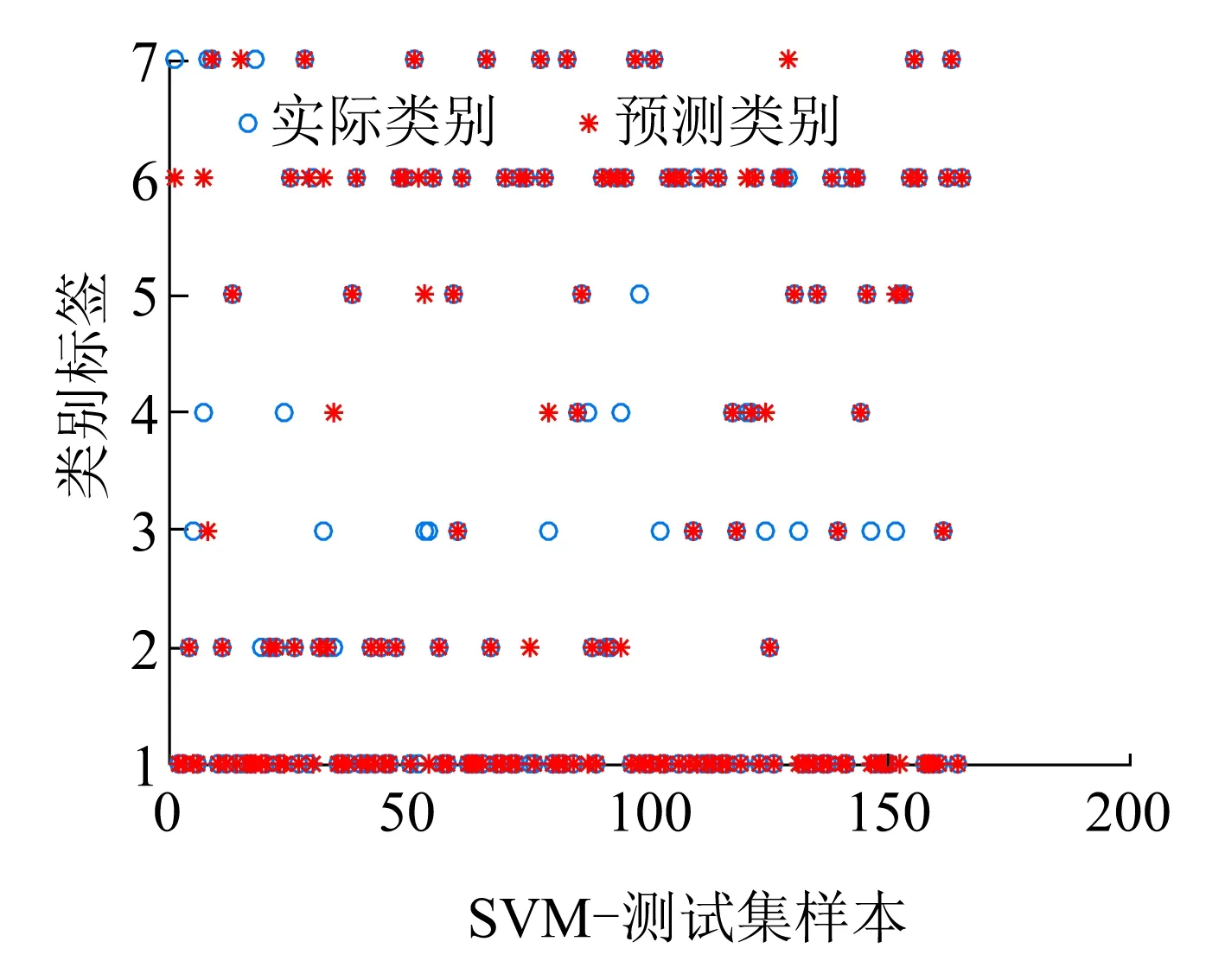
(a)测试集的实际分类和预测分类
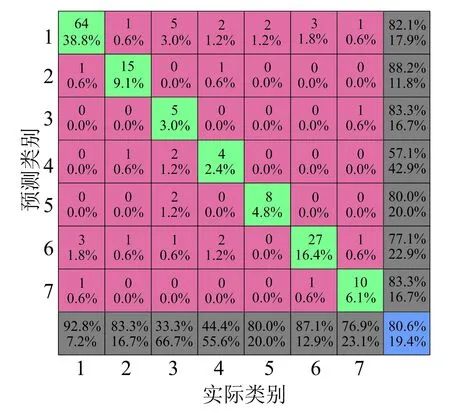
(b)混淆矩阵
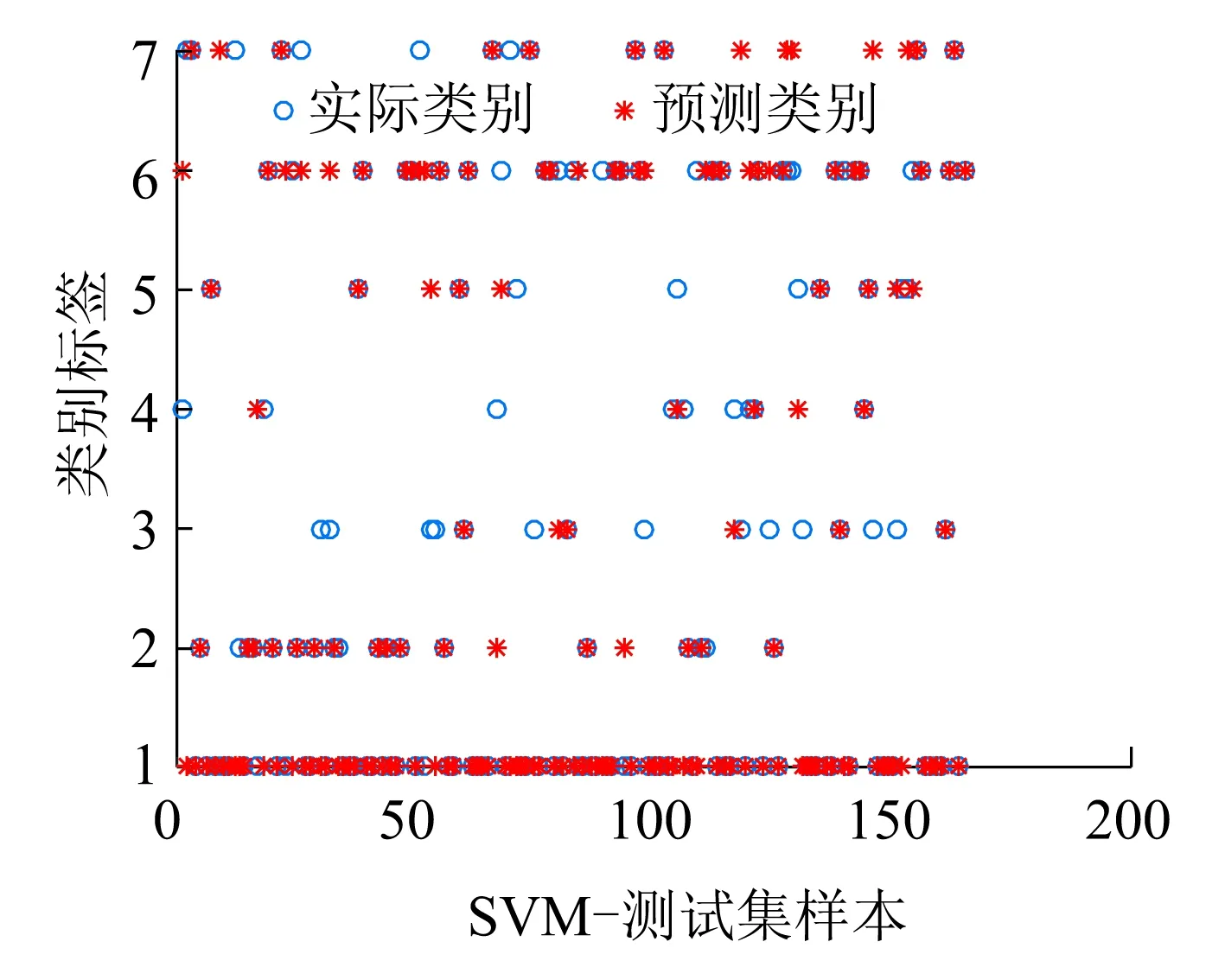
(a)测试集的实际分类和预测分类
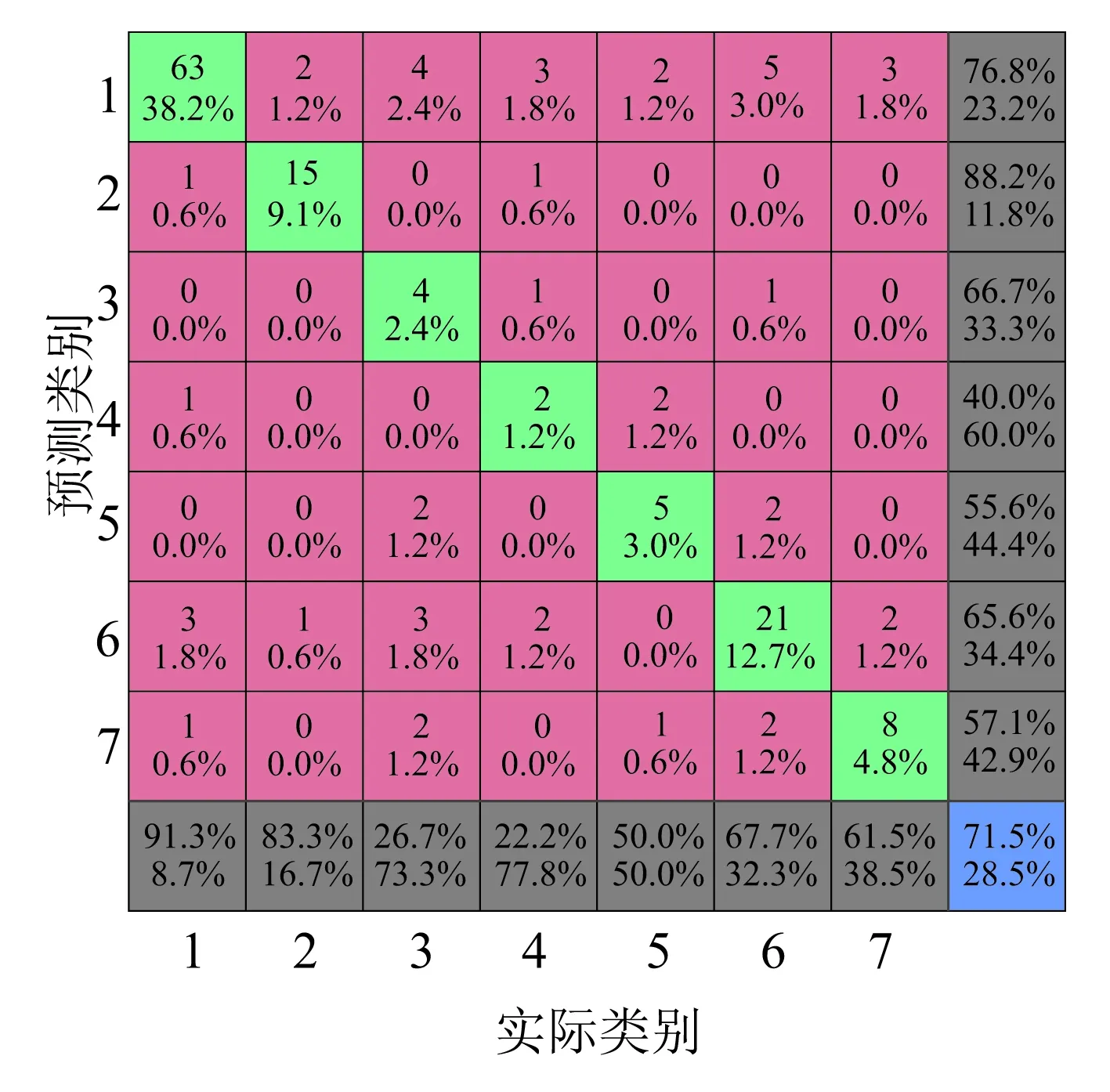
(b)混淆矩阵
(a)测试集的实际分类和预测分类
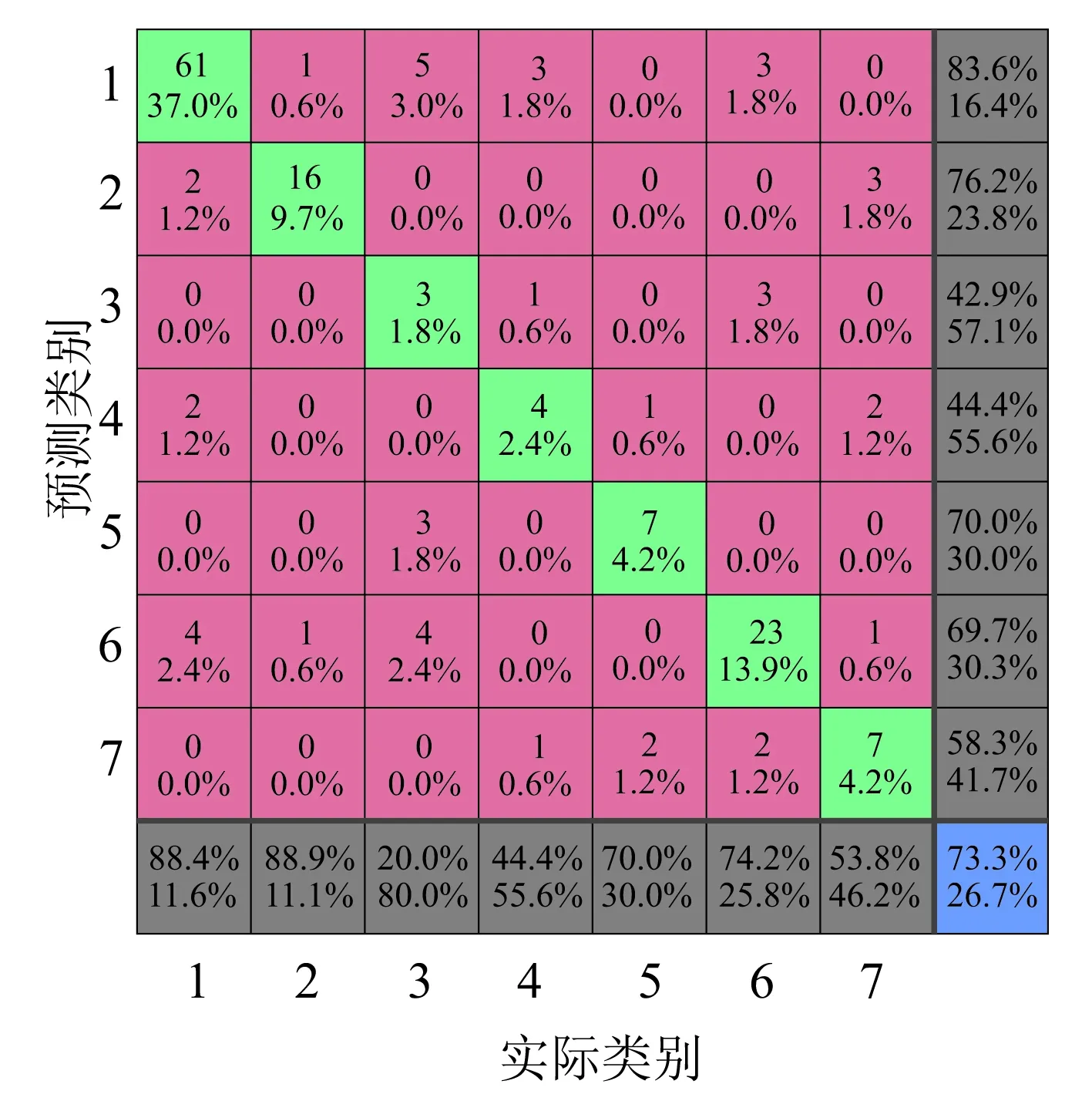
(b)混淆矩阵
为了更加准确且全面地评价三种特征空间的诊断结果,采用Precision和F-measure作为评估指标,图10直观地表示出了三种特征空间之间的差异。
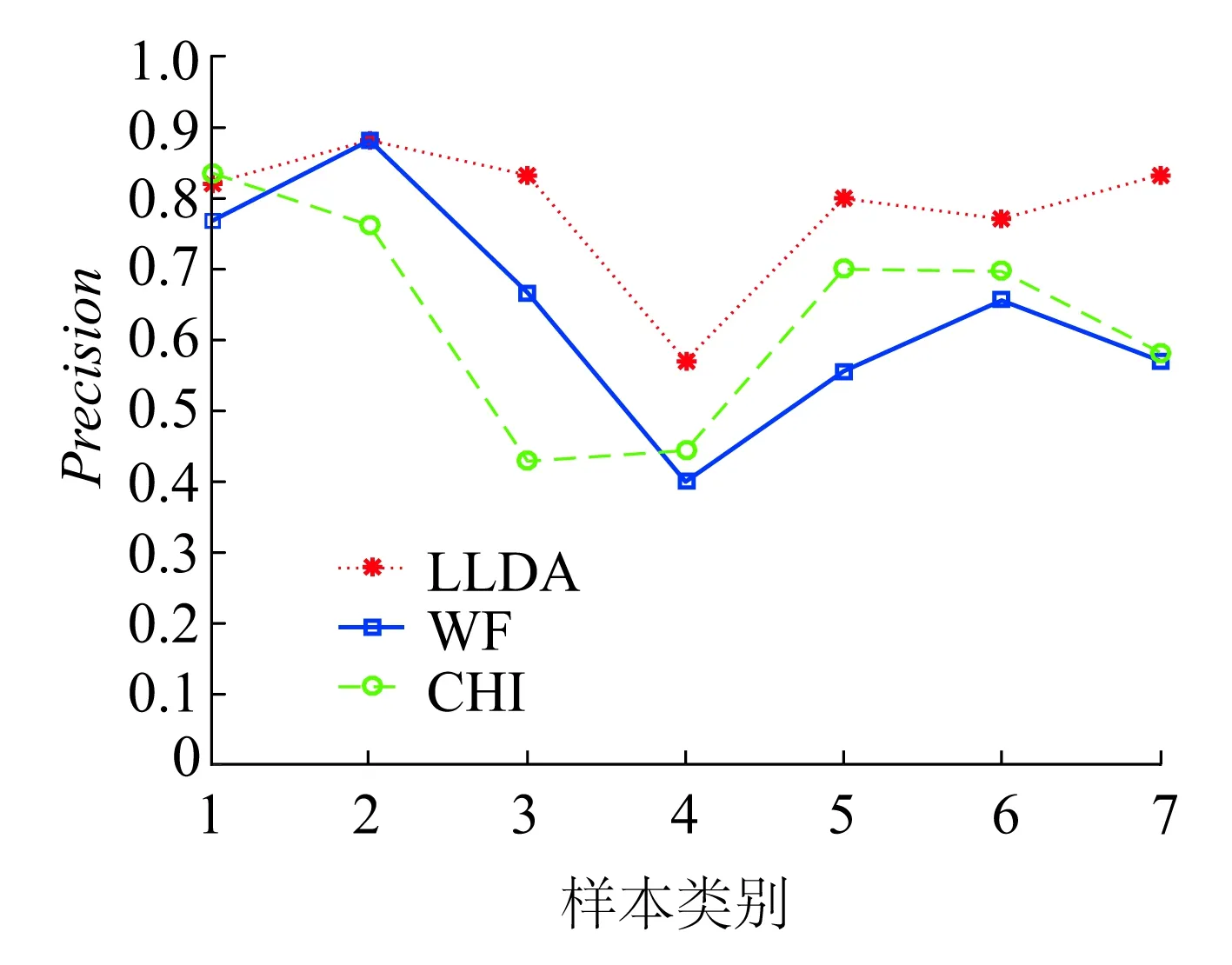
(a)Precision对比
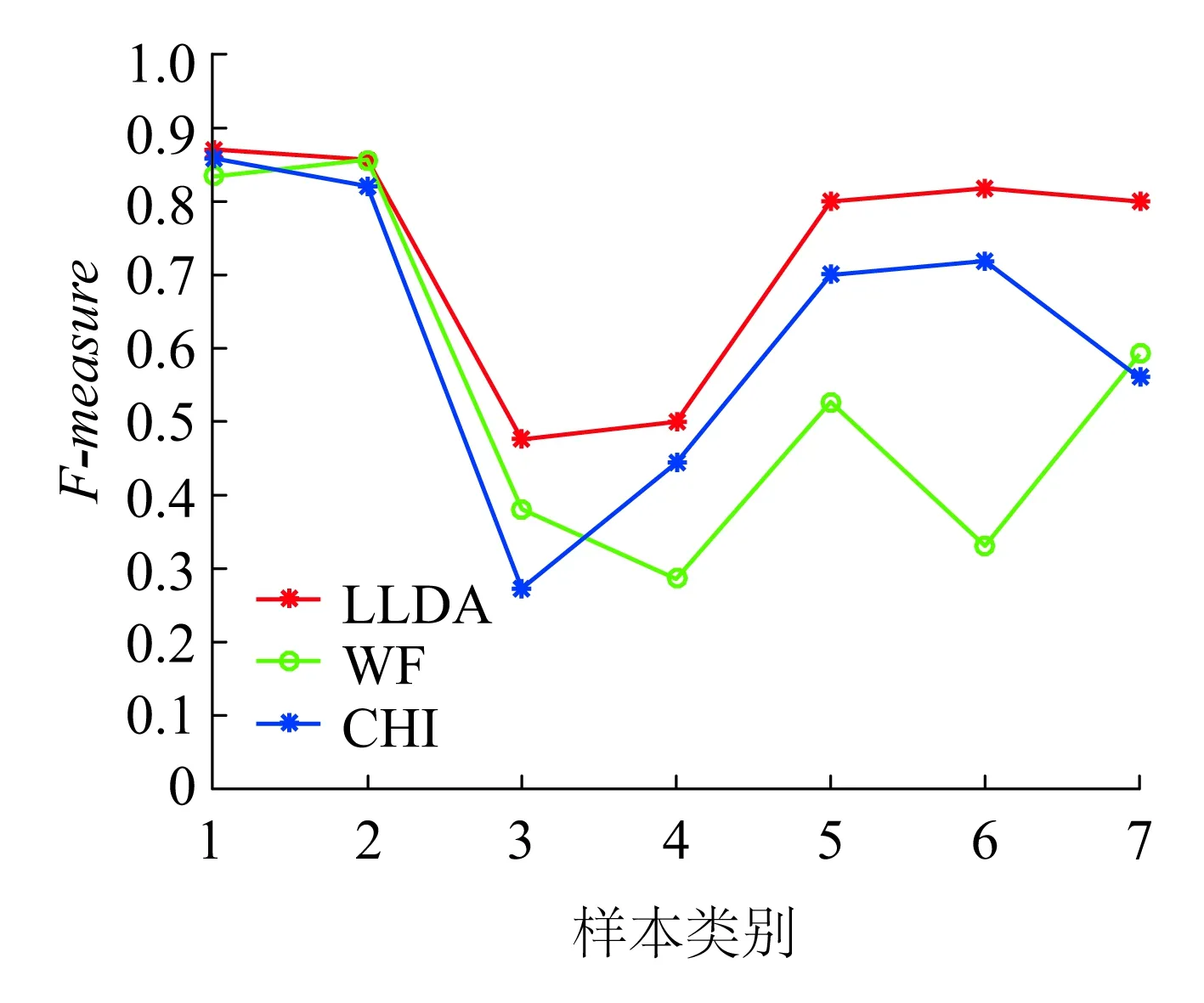
(b)F-measure对比
通过两种评估指标的对比,可以发现,相比于WF和CHI两种特征空间,改进的LLDA模型的诊断效果最优,并且对于小类别样本的诊断精度也具有一定的改善效果。
4 SVM算法优化
通过表2和表3可以发现,样本数据的分布具有明显的不均衡性。为了使样本数据的这一特点尽可能小地影响分类器的精度,一般可以从数据处理层面和算法改进层面解决这一问题。数据层面一般采用过采样、欠采样的方式进行处理;算法层面则采用引入代价敏感矩阵,构建集成分类器等方式进行处理。文献[17]对不平衡文本数据采用SMOTE过采样技术实现故障少数类别样本的自动生成,提高了分类效果。文献[18]提出的数据流滑动窗口方式下的自适应集成分类算法,有效解决了传统算法中数据块大小影响分类效果的问题。
本文以SVM为基分类器,采用粒子群算法优化分类参数的方式完成对不均衡数据的诊断分类。
4.1 基于粒子群优化的参数选取
粒子群优化算法是Eberhart和Kennedy受鸟群捕食行为的启发,对这一行为深入研究后结合群体智能提出的一种优化算法。该算法利用群体中个体之间的信息交互与合作,使得群体能够以更快收敛速度移动到最优区域。
PSO将每个个体视为一个“粒子”,该粒子无体积且认为所有的粒子均在同一个D维搜索空间中进行搜索。在每一次的迭代过程中,粒子通过追踪两个最优解来更新自身。其中一个是粒子本身寻得的最优解pbest,另一个就是这个群体中目前搜索到的最优gbest。这些粒子以一定的速度飞行,此速度决定了粒子飞行的距离和方向。粒子速度的值不但取决于自身的飞行经验,还受同伴飞行经验的影响,粒子在飞行过程中的速度根据实际情况实时更新。粒子i的速度用Vi=[vi1vi2…vin]表示。1998年,Shi和Eberhart[19]在论文中首次引入惯性权重的概念用于改善算法的收敛性能。最初的粒子群优化算法的迭代公式如下。
速度向量中第i个分量的迭代公式为
vk+1,i=qvk,i+c1r1(pbestk,i-xk,i)+
c2r2(gbestk-xk,i)
(22)
位置向量中第i个分量的迭代公式为
xk+1,i=xk,i+vk,i
(23)
式中:q为惯性权重;c1和c2是加速常数;r1和r2在[0,1]区间内随机取值。
4.2 SVM分类参数优化实现
SVM的参数优化具体实现流程如图11所示。
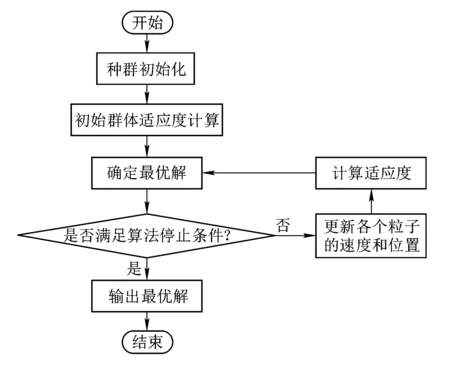
图11 SVM优化算法流程
4.3 基于PSOSVM算法的故障诊断仿真
本文利用动车段2015年全年和2016年上半年总计552条故障数据进行故障诊断仿真。故障数据被划分为训练集和测试集,其中训练集占70%,测试集占30%。日志数据的诊断分类是通过逐级诊断的方式完成的。日志文本进行一级故障诊断后,将诊断结果以向量的形式与日志表征向量进行串联融合,得到表示日志数据的融合特征空间向量,其中日志表征向量是数字化表示的文本向量,表征不同主题的词项在该文本中的分布情况,若该词项出现,则向量对应位置置1,否则为0,其维数等于不同主题所包含的相关词项数量。采用粒子群优化后的SVM分类器对融合的特征空间向量进行诊断分类,在进行多分类仿真时,采用台湾大学林智仁等开发的LIBSVM工具箱[20],采用一对一的分类策略。将分类器的分类结果与测试集中已知的故障类别进行对比,得到诊断样本的诊断精度。
4.3.1 一级故障诊断仿真分析
为了说明PSO-SVM算法的有效性,以SVM和KNN算法作为对比算法,仿真结果如图12~图14所示。
对比图12~图14可以看出,在诊断结果中,采用相同的特征表示向量时,PSO-SVM算法的效果优于其他两种算法。分别采用PSO-SVM、SVM和KNN三种算法进行故障分类的结果见表4。
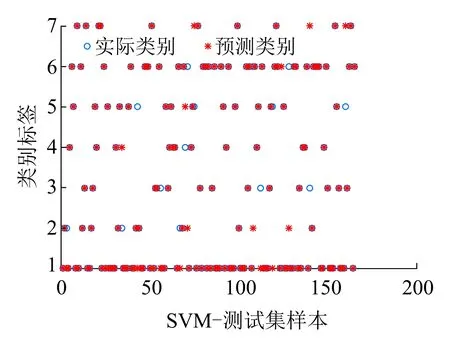
(a)测试集的实际分类和预测分类
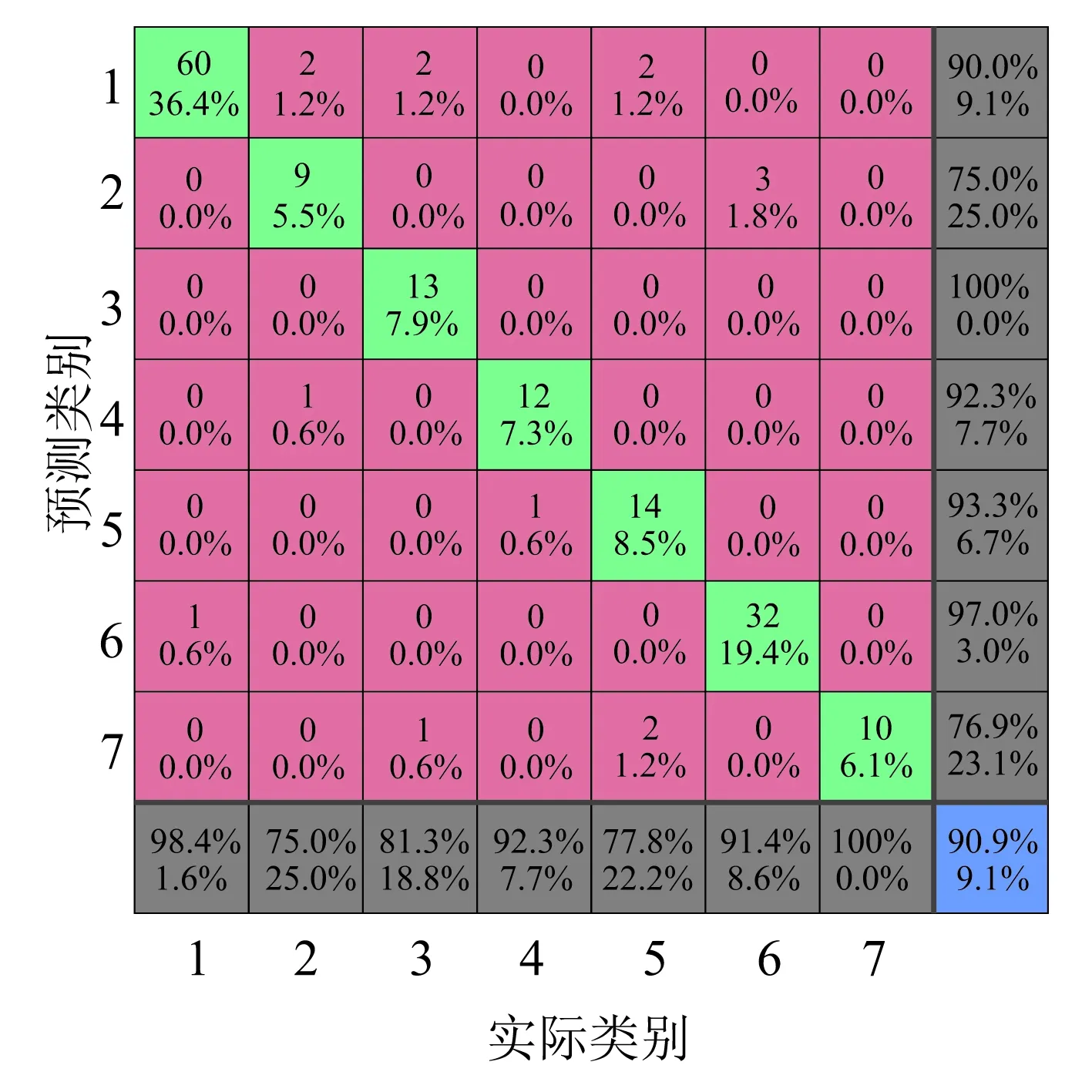
(b)混淆矩阵
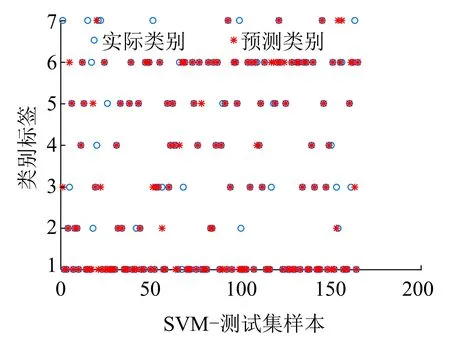
(a)测试集的实际分类和预测分类
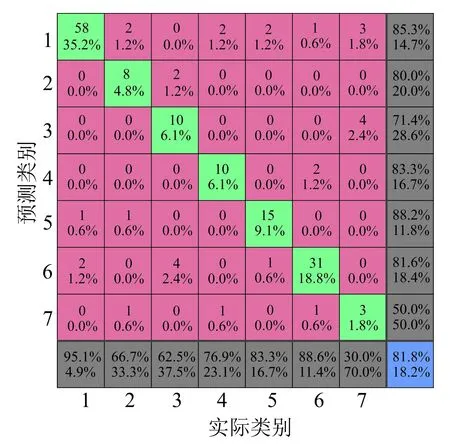
(b)混淆矩阵
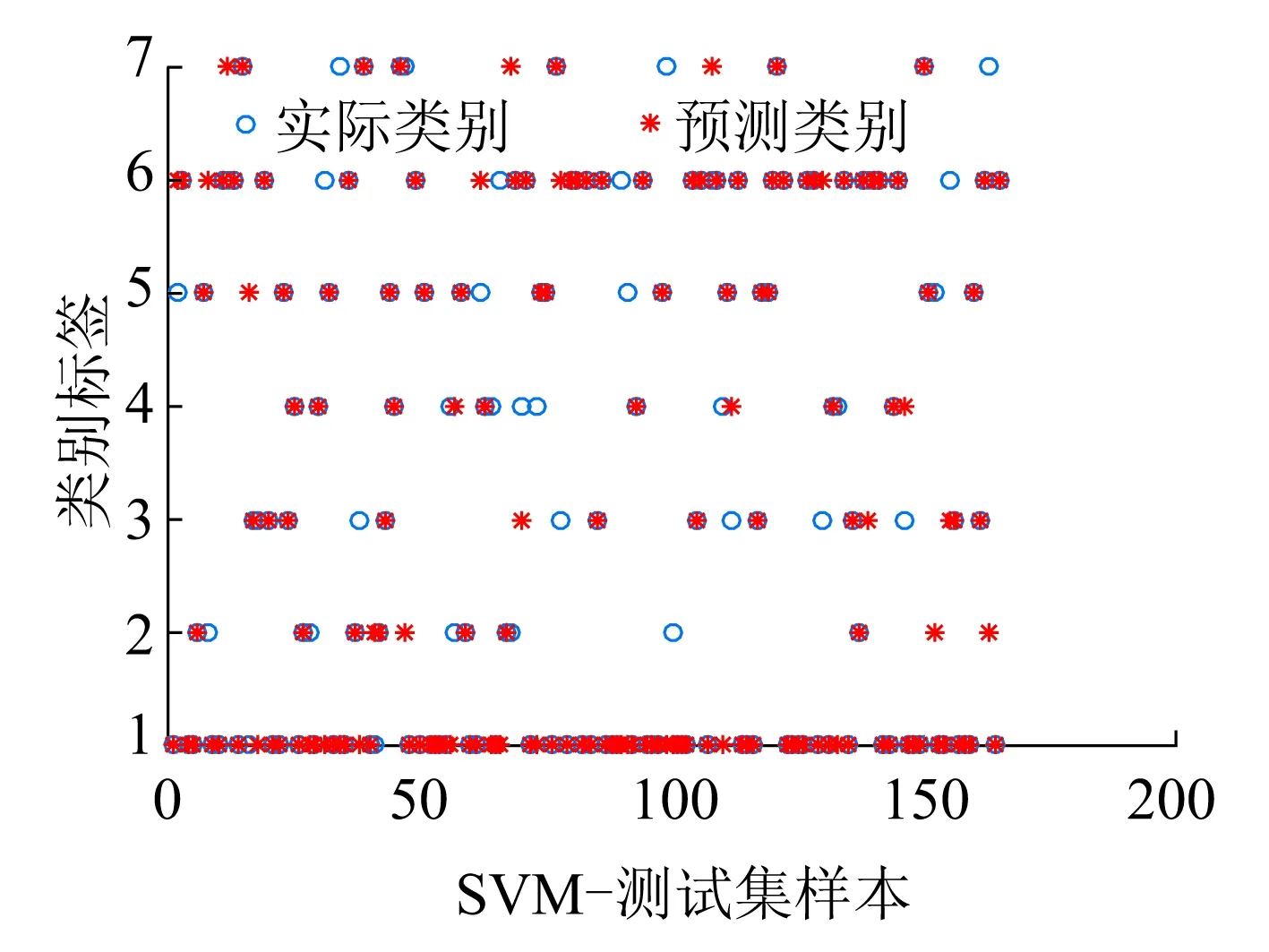
(a)测试集的实际分类和预测分类
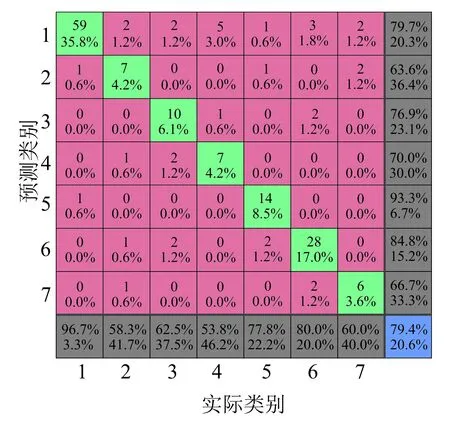
(b)混淆矩阵

表4 一级故障诊断准确率 %
为了进一步说明,对于不均衡数据的改善效果,对比三种算法的混淆矩阵可以明显看出,分类器在提高整体准确率的同时可以较好地提高小类别样本的诊断精度。同样采用Precision和F-measure两个指标对三种算法的诊断效果进行评估。
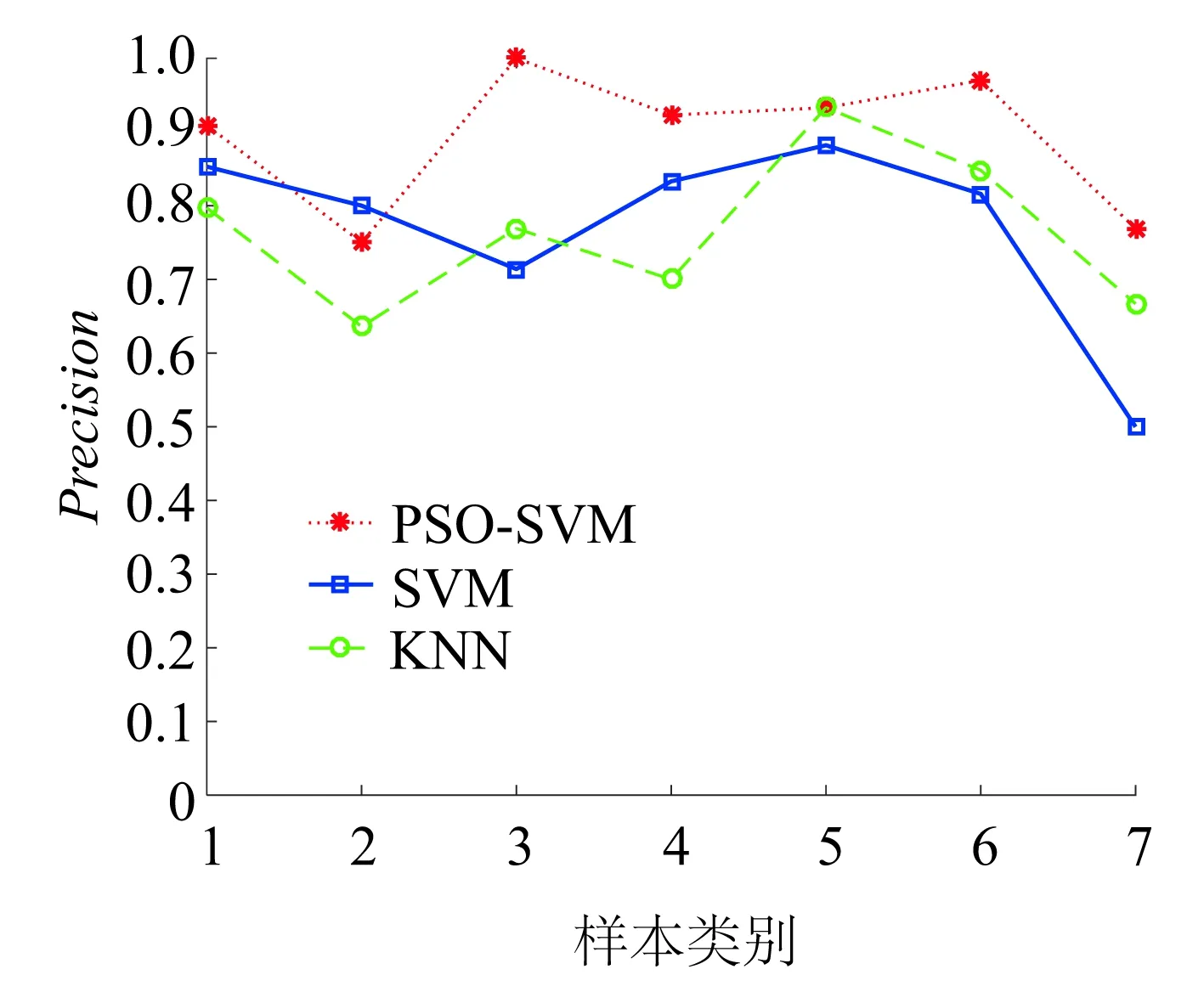
(a)Precision对比
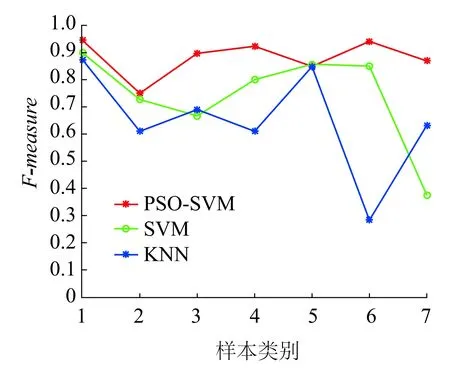
(b)F-measure对比
通过图15可以发现PSO-SVM算法的两种指标在每一种一级故障诊断结果中都具有最优效果。通过上述仿真结果可以得出:PSO-SVM对样本分布不均衡数据的诊断分类具有较好的提升效果。
4.3.2 二级故障诊断仿真分析
为了完成车载数据的二级故障诊断,同时提高故障诊断的准确率,本文将一级故障诊断结果转化为一种特征向量,采用数据融合技术与主题模型从文本中提取的主题特征向量进行融合。一级故障诊断结果的特征向量代表具体的故障类型编号,一级故障共有7种,为了降低向量的维数,采用二进制的表现形式给故障类型编码,如故障类型编号为7的特征向量表示为[1 1 1]。在进行二级故障诊断时将此向量添加到对应文本直接提取的特征向量的末尾,即采用串行融合方法对特征向量进行融合。
为了说明特征向量融合的有效性,分别采用PSO-SVM、SVM和KNN三种算法比较基于LLDA和FLLDA提取的特征向量进行故障分类的准确率。结果见表5。
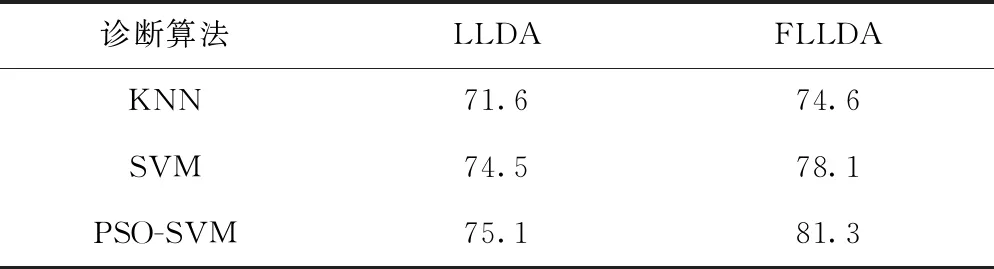
表5 基于LLDA与FLLDA的二级故障诊断准确率 %
从表5中可以看出不同诊断算法均是采用融合后的特征向量进行故障诊断的准确率较高,说明特征融合可以有效提高故障诊断精度。针对同一种特征向量,PSO-SVM算法在三种算法中的诊断准确率依然是最好的。采用PSO-SVM对融合后的特征向量进行二级诊断的准确率低于一级故障诊断的准确率,一方面是由于二级故障诊断划分类别更加详细,数据的不均衡性对诊断精度的影响增大,另一方面是受到一级故障诊断错误分类的影响。
5 结束语
本文根据300T车载设备故障文本数据特点,构建故障特征词库,采用改进的LLDA模型提取日志数据的语义特征,并与传统的词频方法,卡方统计进行了对比分析。实验结果表明SVM基于LLDA提取出的特征向量进行故障分类的准确率明显优于采用WF和CHI提取特征进行故障分类的准确率,验证了LLDA模型提取日志数据语义特征的有效性。
故障样本中不同故障类型所占比例差异较大,传统分类器容易把小比例故障类型错误地归类为大比例故障类型,具有一定的局限性,无法满足实际要求。为了解决这一问题,本文将粒子群优化算法引入支持向量机内,优化了支持向量机的部分参数,通过与传统的支持向量机算法SVM,K最近邻算法KNN进行对比分析,验证了所提模型的有效性。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
华人时刊(2021年13期)2021-11-27
计算机系统应用(2021年2期)2021-02-23
心声歌刊(2020年4期)2020-09-07
铁道通信信号(2020年8期)2020-02-06
电子技术与软件工程(2019年18期)2019-11-18
汽车维修与保养(2019年3期)2019-06-19
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电子技术与软件工程(2017年14期)2017-09-08
