
基于L2-VAE的局部放电未知信号识别方法
2019-10-10 07:04邓冉朱永利刘雪纯翟羽佳
广东电力 2019年9期
邓冉,朱永利,刘雪纯,翟羽佳
(新能源电力系统国家重点实验室(华北电力大学),河北 保定 071003)
局部放电(partial discharge, PD)是电力设备绝缘性能降低的重要征兆[1]。不同的放电类型有着不同的放电环境及发展趋势,及时识别放电类型对放电信号的定位及检修预防工作具有重要意义[2]。放电信号识别的一般步骤是:特征提取、特征降维和模式识别。常用的特征提取方法有:基于图谱的统计参数法[3]、基于信号分析的时频量法[4]及熵[5]和混沌特征法[6]。这些特征具有较高维度,能充分表征样本信号。常用的模式识别方法有:支持向量机[7](support vector machine, SVM)、神经网络[8]和聚类方法[9]。这些方法一般都是使用所有类型样本训练一个分类器,分类器的输出即为放电类型。高维特征可充分表征杂质样本,使杂质更容易影响监督学习的分类决策面。故在样本容量有限的情况下,直接使用高维特征易使分类器过拟合[10-11],需将所有样本放在一起降维以保持不同类样本间的差异性,但降维也会使样本产生形变,缩小样本差异度[12]。
上述方法都只能识别典型油纸绝缘结构下的各已知类型。然而电力设备结构多样且组件复杂,各种新材料也逐渐被用于设备制造业中,很难保证现有的放电库中包含所有放电类型。若有新的放电类型出现,则会被误判为已知类型,污染放电库[13]。此外实际收集的样本中也可能包含别的非放电样本,故对典型油纸绝缘结构放电信号的识别应多出一个不属于已知类型的识别分支,称为“未知类别样本”。
有关未知样本的识别研究较少。文献[13]集合了所有样本的权值指标,并对权值求取阈值以隔开其中的已知和未知类。文献[14-15]对支持向量描述 (support vector data description, SVDD)的球体半径进一步划分以确定阈值。这些方法中的未知类型仅为新类型的放电样本,但实际中的未知信号有无数种可能,不能保证所有未知信号降维后都能维持原有差异。
目前未知类的识别领域存在的困难有:①未知类型样本有众多可能,具有多变性,其对数据集整体降维的形变程度的影响无法预知,甚至可能影响识别结果。②未知类型样本多样,没有统一的特征属性,难以识别。
深度学习方法自从提出就颇受学者青睐,促进了众多领域的发展。变分自编码器(variational auto-encoders,VAE)是一种结合了深度学习的数据生成模型,其内部的损失函数常采用平均方差(mean square error,MSE)距离。该法较少用于PD信号的识别,仅有文献[16]利用其隐含层提取PD信号特征,仍未用于PD相关的数据生成。最大类间方差法Otsu是一种经典阈值二分算法,具有较好的分割效果和很强的自适应性[15],在图像分离领域得到了广泛应用。
本文针对未知类型样本的识别问题提出了L2 -VAE方法。为避免降维的影响,特征提取方面使用信号原始未降维特征。针对高维特征下杂质样本对监督学习的过拟合问题,分别对每类放电建立VAE无监督生成模型;对于高维特征的冗余问题,使用L2正则化方法对VAE神经网络的各层权值加以约束,以此避免高维特征的过拟合。此外,本文使用各已知类型放电的VAE模型分别对未知类数据进行数据生成,再选用模型中的MSE损失函数来度量生成样本和原未知样本的差距,并选出最匹配的MSE距离。这样未知类便会得到较大的MSE距离,实现了未知类在MSE距离属性上的统一性。同理,已知类会得到较小距离,之后再使用Ostu算法对未知类样本进行判定和分离。为验证本文所提方法的有效性,分别使用降维后的特征及常规的SVM方法对典型油纸绝缘结构缺陷放电信号分类,并与本文方法使用结果进行对比。
1 L2-VAE基本原理
1.1 VAE原理
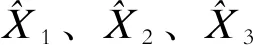
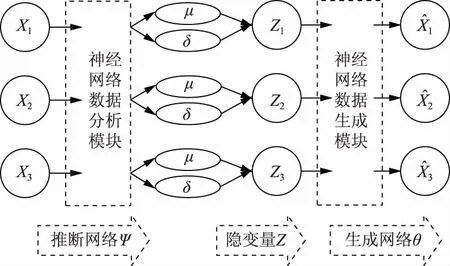
图1 VAE模型Fig.1 VAE model
在图1的推断网络中,产生估计后验分布函数qΨ(z|x)。使用Kullback-Leibler散度度量它和生成网络中的真实后验分布Pθ(z|x)间的距离[17-18],该距离即为网络的损失函数,通过最小化损失函数来优化网络参数,即
DKL(Pθ(z|x)‖qΨ(z|x))=

(1)
式中:DKL为Kullback-Leibler散度度量函数;x、z分别为VAE模型的原始量和隐变量。
经变分贝叶斯推理得到简化的变分下界,即为最终的损失函数
L(θ,Ψ)=DKL(qΨ(z|x)‖P(z))+
E[-ln(Pθ(x|z))].
(2)
式中:E为z服从分布qΨ(z|x)时函数的期望值。若qΨ(z|x)最终服从标准正态分布,则先验分布P(z)也为标准正态分布,即

(3)
式中N(0,1)为标准正态分布。
损失函数L(x)的第1项为qΨ(z|x)和P(z)的Kullback-Leibler散度,结合式(3)将其简化。其中的均值、方差可由推断网络中的神经网络部分得出,即
(4)
对于损失函数第2项中的Pθ(x|z),可以由某种概率密度函数公式直接计算得到[19]。若Pθ(z|x)为二值函数伯努利分布,则可化简为交叉熵形式,即
(5)

若Pθ(z|x)为正态分布,则可化为MSE损失函数
(6)
可见,损失函数的第2项度量的是原始量与生成量的距离。由于放电特征不是二值伯努利分布,本文的VAE模型采用MSE损失函数。
1.2 L2正则化
正则化是通过最小化特征前的系数来避免机器学习过拟合的一种方法,它能够弱化非必要特征的影响。L2函数是可导凸函数,广泛用于模型的正则化约束[20]。正则化可作为损失函数的附加部分,含L2项损失函数的一般表达式为
L=L′+L2=(kx-y)2+λ‖k‖2.
(7)
式中:k为x的系数,kx是对样本属性的估计;y是样本的真实属性;λ为正则化项的权重;L2为正则化函数;L′为损失函数。
1.3 改进VAE
为防止维数灾难,引入L2正则化,从而达到近似自适应降维的效果。然而VAE模型由神经网络构成,特征前的系数k是由众多激活函数权值w经某种复杂关系映射得来,不能直接得到特征前的系数。模拟正则化原理可直接对激活函数权值w最小化。改进的损失函数为
(8)
式中:LVAE为VAE模型的损失函数;Lw为神经网络权值的正则化函数。
1.4 L2-VAE识别已知放电类型
不同类型的放电信号具有不同的特征关系,分别使用L2-VAE生成模型并提取特征函数关系,在对样本匹配时选用MSE距离作为度量方法。设共有g类放电样本,样本的特征向量可表示为F=[f1f2…fp]。对已知类型(不含未知类)的具体识别步骤如下:
a)用各类放电的训练集样本训练L2-VAE模型,共得到g个VAE样本集合{tVAE1,tVAE2,…,tVAEk,…,tVAEg}。

d) 在矩阵D中找到最小距离dmin并记录其下标,假设dMSEk为dmin,则k为样本类别。
本文有关高维的适应性处理方法如图2所示,使用g个无监督生成模型避免了直接在高维空间对样本分类,预防高维的过拟合现象;通过正则化方法改进VAE,可达到自适应降维的效果。

图2 高维特征处理图Fig.2 High dimensional feature processing diagram
为了验证本文的高维处理方法对已知类的识别影响,用监督学习决策树分类作为对比,分别采用原始图谱44维统计特征和主成分分析 (principal component analysis,PCA)降到5维的特征对电晕、板对板、悬浮和多尖对板放电进行识别。识别结果如附录A表A1,决策树的最大叶子节点数取10。由表A1可知,高维特征下本文方法对放电信号的识别效果远优于决策树。这是因为本文方法是针对高维问题而设计的,决策树对高维数据没有适应能力,直接在高维空间分类会过拟合;降维后2种方法都能够有效识别各放电类型,这是因为测试集中不含未知类型,对已知类降维不会造成严重的形变。
2 L2-VAE识别未知类型
2.1 Otsu原理
Otsu算法又称最大类间方差法,由学者Nobuyuki Otsu于1979年提出,是一种自适应阈值分割方法,分割后的2类样本差别最大。其基本原理是先对样本所在区域进行等级细分,共分为L个等级,每个等级的长度为h,再从这些等级中选择使类间方差最大的等级。设Pi为在第i等级区间内出现样本的概率;PA(k)、PB(k)分别为[0,k]、[k+1,L]等级区间出现样本的概率;μA(k)、μB(k)分别为[0,k]、[k+1,L]区间出现样本的等级均值;δ(k)为以k作为分界等级的类间方差;δ*(k)为最大类间方差;k*为最大类间方差对应的分界等级。类间方差的定义如式(9)—(13)[13, 21],且可得到最优的划分阈值T。
(9)
(10)
μ=PA(k)μA(k)+PB(k)μB(k).
(11)
(12)
(13)
2.2 基于L2-VAE的未知类别样本的识别方法
本文通过对识别样本的最小MSE距离集dmin进行Otsu阈值划分来识别样本类型。MSE损失函数是优化VAE模型的依据,若样本属于某一已知类型,则必定能找到与之匹配的VAE模型,与该模型对应的MSE损失函数的值也较小,从而能够保证获得较小的dmin;若样本属于未知类型,则会与所有VAE模型匹配失败,那么即使是dmin也会有较大的值。这使得所有未知类型样本在MSE距离属性上得到了统一,且已知类的dmin和未知类的dmin值差距较大。
计算训练样本和待识别样本(测试样本)的dmin集,分别记为dXLmin,dCSmin。设dXLmin集中的最大值为XLmax;使用Otsu算法对dCSmin划分,可得划分阈值T。若dCSmin含有未知类,并假设dCSmin集中已知类的最小值为d1,最大值为d2,未知类的最小值为d3,理想状态下的阈值T在区间[d2,d3]内;若dCSmin不含未知类,则T属于区间[d1,d2]。基于此,可由XLmax和T间的关系实现对有无未知类的判定,并由阈值T分离出未知类型。设已知类型共有g类,对未知类的识别流程如图3所示。此方法使用了全部的高维特征,避免了降维的影响。分类工作在一维空间MSE属性上进行以防止分类器高维过拟合,更有利于未知信号的识别。
图3 识别流程Fig.3 Identification flowchart
3 实例分析
3.1 实验数据
实验室构造典型油纸绝缘结构下的板对板、电晕、悬浮和多尖对板放电模型如附录A图A1。其中悬浮放电为油中悬浮,多尖对板采用的是绝缘纸板。试验标准为IEC 60270-2000,试验采用的并联测试电路如附录A图A2,实际的接线照片如附录A图A3,用脉冲电流法标定放电量。采用TWPD-2F 局部放电综合分析仪[13],每个工频周期记录一个放电数据,采样点数为 400~1 600万。4种放电类型各生成50组,一共有200组放电数据。
3.2 未知样本识别实例分析
在4种放电类型中各选择50组。并对放电谱图提取能够反映谱图形状的11个统计特征[22]。每组放电信号有44维特征。
未知类型样本可以为任意信号,本文测试集中的未知类型选为新放电类型信号和噪声信号。在4种放电类型中轮流选取2种作为已知类。以已知类中板对板和电晕为例,在板对板、电晕放电数据中各抽取40组作为训练集。另取4种放电各10组,噪声数据30组作为测试集。测试集中的悬浮、多尖对板、噪声共50组数据是未知类型。使用训练集的2种数据分别训练出板对板、电晕2个L2-VAE模型,λ取200。分别使用2个模型生成2组新的测试集数据和2组新的训练集数据。计算生成数据和原真实数据的MSE距离,并得到dmin集。获取dXLmin集中的最大值XLmax,用Otsu自适应法对测试集dCSmin划分阈值,依据本文方法判断样本类别。同理得到另外5种模式下的识别结果,见表1。
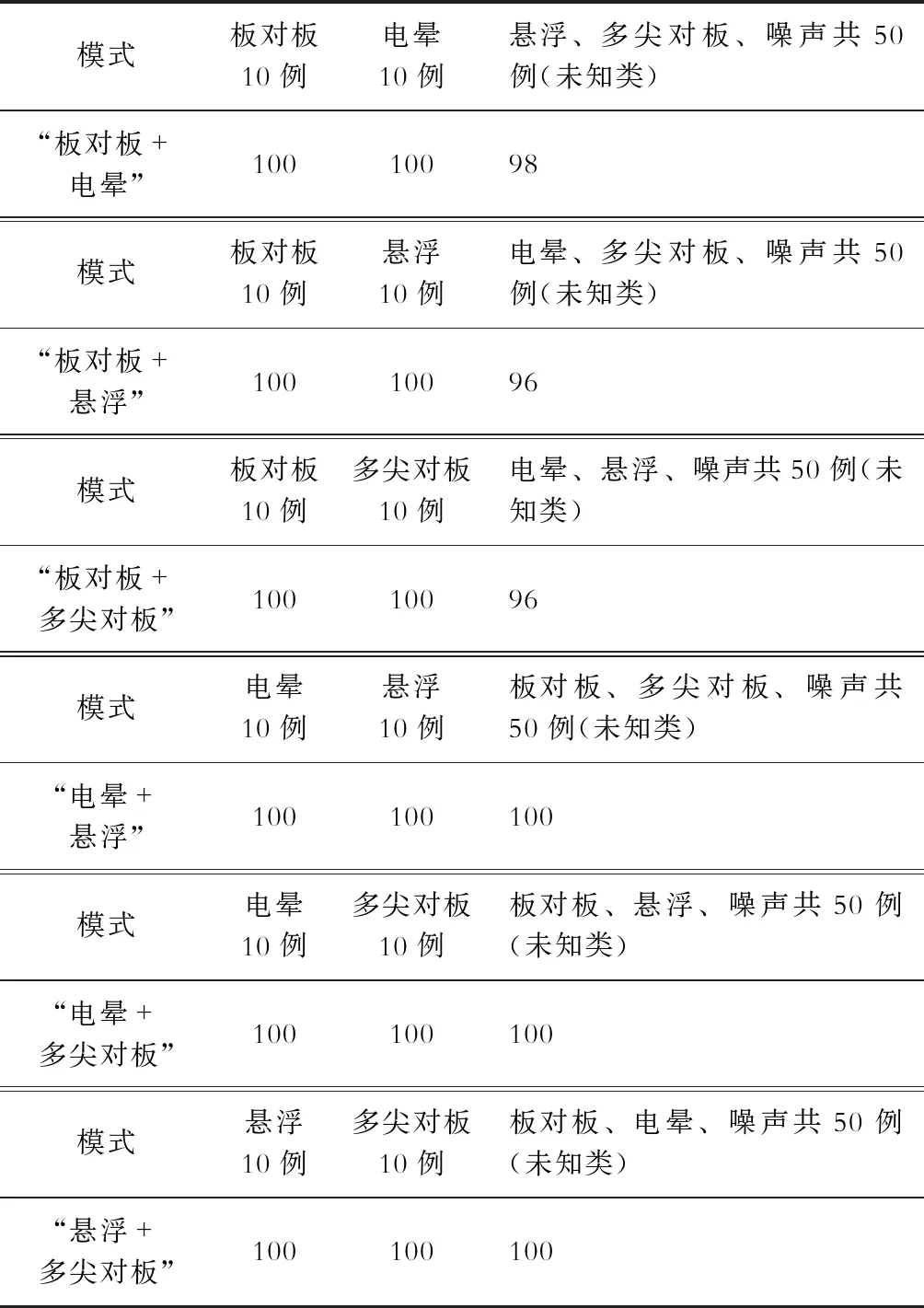
表1 测试集识别结果Tab.1 Identification results of test set %
由表1可知,本文方法能有效地分离未知类型,同时也实现了各已知类型的识别,保证了已知类的识别效率。
为验证MSE的度量效果,分别选择MSE、Tanimoto系数和Person系数度量高维特征向量的距离。对比“板对板+电晕”模式的识别结果见表2。

表2 各度量方式识别结果Tab.2 Identification results of each metric method %
由表2可知,各度量方法对已知类都有较好的识别率,MSE对未知类的识别效果最好。这是因为训练VAE模型时采用的损失函数是MSE形式, 故后续的匹配方式选用MSE能够充分结合模型优势,利用到模型的训练成果。
为了展现直接使用高维特征对未知类的识别优势,使用PCA算法分别将4种放电数据降到二维并以X1、X2表示,如图4所示。
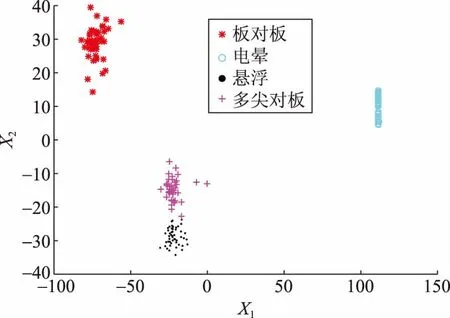
图4 局放信号二维特征图Fig.4 Two-dimensional feature diagram of partial discharge
由图4可知,若未知类型为放电信号,则降维造成的影响不大。另将30组噪声数据和放电数据降到二维,如图5所示。
由图5可知,噪声和板对板放电的分布规律不同,但二维视角有部分重叠,含有噪声样本的降维会使样本特征集变形,噪声和板对板放电间的差异度产生严重形变,同时削弱了悬浮和多尖对板放电的差异度。为了展现低维特征对含噪声的未知类型的识别效果,先将44维特征降到5维,再使用本文方法对5维的样本集合进行识别,对“板对板+电晕”模式的识别结果见表3。

图5 局放信号和噪声二维特征图Fig.5 Two-dimensional feature diagram of partial discharge and noise

Tab.3 Identification results of post-dimension test sets (including unknown classes)%
由表3可知,由于未知类型中噪声样本的影响,降维后的未知类识别率下降,同时严重影响了已知类板对板放电的识别。此外实际中新放电类型不可预测,降维后不一定能维持各类信号的差异度,有必要使用高维特征实现对信号的充分表达,低维特征不适合未知类的识别。
为方便展示本文的正则化效果,对板对板放电的40组数据另加1个无用特征,该特征在前20组数据和后20组数据上差异较大,会对板对板放电产生干扰。分别采用VAE和L2-VAE进行特征生成,该特征的生成结果见附录A表A2。由表A2可知原始VAE生成的特征有较大差异,仍为无用的干扰特征,而L2-VAE生成的特征趋于一致,削弱了该特征的干扰。
SVM分类的“最大间隔”原理使其也具有处理高维特征的能力。为综合验证本文方法的识别效果,分别采用文献[13]中的模糊C均值(fuzzy C-means, FCM)加权聚类的未知类识别方法和SVM分类算法作为对比,分别对只含已知类和含有未知类的测试集样本进行识别。对“板对板+电晕”模式44维特征的识别结果见表4,SVM参数C取1,高斯参数取0.05。

表4 本文方法和SVM对比Tab.4 Comparison of this method and SVM %
由表4可知:测试集中不含未知类时,SVM和L2-VAE都能准确识别放电类型,而FCM只能识别板对板放电,它将已知类电晕放电误判为了未知类,不能对是否含有未知类进行判定;测试集中含有未知类时,SVM不能识别未知类,这是因为SVM算法误将未知类型分为了已知类型。本文所提方法对已知、未知类都有较高的识别率。FCM也能识别各类信号,但效果略逊于本文方法,这是因为FCM在对样本降维的过程中产生了图5的噪声和板对板放电信号重叠的现象。
4 结论
本文提出了基于L2-VAE的未知类型局部放电识别方法,并得出以下结论:
a)对各已知类样本的高维特征建立多个改进的L2-VAE生成模型,能够削弱降维的形变影响,并能在一定程度上抑制维数灾难。
b)获取每例样本的MSE距离值,利用Otsu自适应算法对待识别样本的最小MSE距离集划分阈值,以实现未知类的判定。
c)实验结果表明,本文方法能够充分利用样本特征信息,对典型油纸绝缘结构缺陷下的未知类信号识别效果优于SVM和FCM。
猜你喜欢
数学杂志(2022年4期)2022-09-27
车主之友(2022年4期)2022-08-27
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
海峡姐妹(2019年12期)2020-01-14
数学年刊A辑(中文版)(2019年1期)2019-01-31
自动化学报(2017年11期)2017-04-04
火控雷达技术(2016年1期)2016-02-06
应用数学与计算数学学报(2014年3期)2014-09-26
