
深度学习在输电通道危物辨识技术中的应用
2019-10-10 06:55杨可林许永盛李鹏
广东电力 2019年9期
杨可林, 许永盛, 李鹏
(国网山东省电力公司菏泽供电公司,山东 菏泽 274000)
高压输电线路是输送电能的重要设备,其正常运行是评价电网安全的重要基础指标。我国复杂的地形地貌导致了输电线路运行环境的恶劣,极易发生各种故障影响系统的安全稳定运行[1]。为了保证复杂状况和环境下巡检工作的效率和可靠性,电网公司对巡检系统进行改造,通过使用监控设备代替人工现场巡检的方式,大大提高了运行检修工作的效率。电网大力发展智能监控的同时,也面对着新的难题。以山东省菏泽市为例,据统计菏泽市35 kV以上电压等级输电线路124条,总长度2 215 km,共计8 401座杆塔,监控设备的安装使用大大减少了传统巡检方式的人力和工作时间的投入,但同时监控设备产生的视频或图像数据的总量也极其庞大。菏泽电网现阶段已知安装监控设备约1 200台,以每天工作12 h、每0.5 h拍摄1张图像计算,一天整个监控系统能够获得约28 800张图像,一个月接近860 000张。而根据统计,菏泽电网平均每年发生故障跳闸70~80次,平均每月发生故障不超过10次。在海量的监控数据中可挖掘的有效故障原因数据寥寥无几,而且受硬件设备和拍摄条件的影响,肉眼无法快速准确辨识拍摄图像,增加了人工识别工作的难度。由于有效图像数据比例较小且有效性无法保证,大大增加了后期人工识别图像的工作量和时间,降低了故障排除的效率。
目前相关研究多采用监控视频作为主要的识别样本,利用运动目标检测技术实现对输电线路附近异物的识别。例如:通过分析拍摄视频图像,采用帧差法在关键帧中标注出异物,再利用特征点跟踪异物,从而实现输电线路异物识别[2];在改进的最大类间方差分割算法分割背景的基础上,根据输电线路特征有目的性地进一步滤除背景,采用梯度法寻找输电线路,选取Hough变换累加器极大值个数和检测到的输电线路数量作为依据,识别输电线路异物[3];分析巡检过程拍摄到的图片,根据人眼感知特性在事先检测到的输电线路有明显差异的兴趣区域内计算出视觉显著图,然后利用颜色、形状或空间分布等特性对异物区域实现统一定位[4]。
上述方法虽然对于异物识别的准确性极高,但主要采用视频数据,数据量比起图像数据更加庞大,相应地对系统传输通道和储存设备的要求也更高,单位时间内服务器设备处理数据量巨大。但电网监控系统处于发展初期,相关硬件设备尚不完善,这些方法的推广受到了限制。并且上述方法只能做到识别异物的出现,不能真正判断异物的种类,想要得到更加精确的异物信息,依然需要人工识别的参与。
为了解决电网智能监控存在的问题,结合当下发展迅速的基于深度学习的目标检测技术,针对输电线路周边常发生的工程机械外力入侵检测问题,提出了基于深度学习的输电通道危物辨别技术,对监控图像中可能引发线路故障的工程机械进行自动识别,并在图像中使用边界框标注其位置和种类[5-6]。使用深度学习对图像进行故障目标的判别,可提高故障判断效率和可靠性,同时为故障定位和预警提供有效数据。
1 基于深度学习的目标检测
深度学习是机器学习最新的研究领域,其在图像识别、语音识别、人脸识别和目标检测等方面均有重要应用。深度学习来源于人工神经网络,通过模拟人脑神经结构,形成一种多层神经网络,从图像、语音和文字等数据中提取低层特征,组合形成更加抽象的高层特征,以发现数据的分布式特征表示[7]。目前涌现出了许多深度学习模型框架,如深度置信网络[8]、自编码器[9]、卷积神经网络(convolutional neural network,CNN)[10]和循环神经网络[11]及演变的多种模型等。其中,CNN采用了卷积层和下采样层间局部连接、同层间权值共享以及池化处理的思想,其网络结构具有复杂度低、训练难度低、计算速度快、容错能力和鲁棒性强等特点,使其成为当下使用最为广泛的神经网络结构。
现阶段深度学习已经在其他领域得到了应用,例如:使用多层网络结构搭建的深度CNN能够检测到复杂环境中的行人,识别率高达99.7%[12];使用CNN识别多种手势,精度较高且复杂度较小,具有很好的鲁棒性,对各个手势的识别率为90.75%~100%,误识率也小于10%[13]。因为CNN在各领域的出色表现,本文也选择采用CNN作为主要研究方向,研究CNN在输电通道智能监控中的应用。
1.1 CNN
CNN属于前馈深度网络,由加拿大多伦多大学LeCun教授提出,最早作为分类器使用[14]。CNN作为一种分层结构网络,根据各层功能和作用,可分为输入层、卷积层、下采样层(也称为池化层)、全连接层和输出层。CNN基本结构如图1所示。
CNN识别图像的基本原理为:图像从输入层进入CNN,通过多层卷积层和下采样层交替作用,提取输入图像低层特征并转变为高层特征,再由全连接层和输出层对提取的高层特征进行分类,最终输出一个一维向量,代表输入图像的类别。下面针对CNN各层进行详细介绍。
输入层负责接收读取输入信号,例如图像、语音及文字等。卷积层由多个特征面组成,每个特征面由多个神经元组成,主要功能是通过卷积核进行卷积计算提取特征。卷积层数学模型描述为
Xi=f(Xi-1⊗Wi+bi).
(1)
式中:Xi为第i层的特征图;Wi为第i层卷积层的权值向量;bi为第i层卷积层偏移向量;f(*)为激励函数,通常采用tanh函数或是sigmoid函数。
卷积层应用了局部连接和权值共享的概念,使用小于图片尺寸的卷积核(一般采用3×3或5×5的卷积核)对整个图进行滑动卷积计算处理,提取出卷积核所要突出的特征(例如线条、边缘等),起到了滤波的作用。每层卷积层会使用多个不同的卷积核以提取出多个特征,并形成特征图向下输入到下采样层中进行池化,对特征进行进一步筛选。
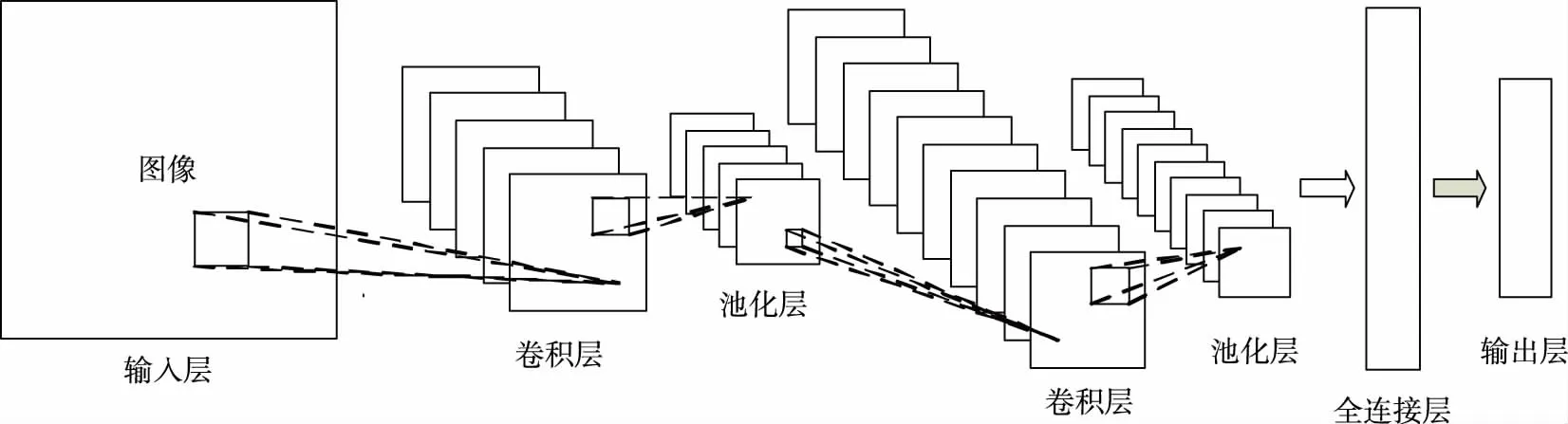
图1 CNN基本结构Fig.1 Basic structure of CNN
下采样层设置在卷积层之后,同样由多个特征面组成,会将卷积层传输过来的特征图按照一定规则(一般分为均值池化和最大值池化),在保证特征图空间性不变的前提下,减低特征维度。下采样层数学模型描述为
Xj=p(Xj-1).
(2)
式中p(*)为所选择的的池化规则。
全连接层与局部连接的卷积层和下采样层不同,全连接层的神经元会与上一层全部神经元相连,将经过多层卷积层和下采样层所提取的特征进行最终分类。全连接层数学模型为
Xi=f(WiXi-1+bi).
(3)
输出层采用Softmax逻辑回归的方法对全连接层输出特征进行分类。
1.2 模型选取
作为计算机视觉领域中的重要课题,目标检测的主要功能是定位图像中的目标,识别目标类型并在图像中画出边界框作为标识。该功能十分适合运用在如今监控设备不断完善的电网巡检系统中,用于检测输电线路周边可能影响到电网系统稳定运行的危险物体,做出及时正确的预警与判断。
目前基于深度学习的目标检测算法根据工作原理可分为2类:
a)两步检测算法,首先在未识别图像中产生候选区域,然后对候选区域分类,其典型代表是基于候选区域的R-CNN系算法,如R-CNN[15]、Fast R-CNN[16]、Faster R-CNN[17]等;
b)一步检测算法,直接在未识别图像中产生类别概率和位置坐标值,典型的算法如YOLO(you only look once)[18]和SSD(single shot multibox detector)[19]。
目标检测模型的主要性能指标是检测准确度和速度,其中准确度包括定位准确度和分类准确度。本文分别采用Faster R-CNN和Mobilenet_SSD[20]网络模型,使用同一组训练样本训练模型参数,并使用另外一组与训练样本互斥的测试样本作为验证比较。
2 实例验证
2.1 框架选取
深度学习框架主要包括TensorFlow、Caffe、Keras和CNTK等,本文选择最主流的TensorFlow和Caffe框架进行比较,分析各自的优缺点,决定所采用的框架。
TensorFlow是由Google在DistBelief的基础上进行改进的第二代人工智能学习系统,具有较好的灵活性、可移植性和可延展性;支持Python、C/C++、Java以及Go多种语言编写,程序编译兼容性更高;支持在图形处理器(graphics processing unit,GPU)上运行,能极大提高CNN模型的训练速度和运行速度,节省时间成本;支持分布式计算,可以在单个CPU/GPU或GPU组成的分布式平台上自动运行。
Caffe由贾扬清提出创建,具有开放性和社区性,而且框架运行速度快,模块化程度高,也是第一个工业级深度学习框架。但是Caffe由于架构设计问题造成框架不够灵活,且扩展性不好。
考虑到实际应用运行中的硬件和软件环境因素,为提高CNN模型的泛用性,选择兼容性和可移植性更好的TensorFlow作为本文CNN框架。
2.2 样本选取
经过调研比较,本文选取威胁输电通道概率最大的大型工程机械作为主要识别对象。
因实际现场图片数量较少,无法单独作为CNN训练样本,而且目前尚无危险物体相关图像数据集,本文选择从互联网上获取和人工拍摄图片的方法,经过人工筛选和查重之后,挑选出合适的1 330张图片作为训练样本。
经过初步的测试发现,1 330张图片作为样本训练出的CNN模型精度依旧较低,为了提高样本数量,并减小样本获取和筛选的工作量,在保证样本有效性的前提下,采用数据增广,对原有的1 330张图片样本进行旋转不同角度和对比度变换处理,将训练样本扩充到了13 300张,以提升CNN模型的训练精度。数据增广效果如图2所示。

图2 数据增广效果Fig.2 Data augmentation effect
2.3 样本标注
样本选取之后,因为Faster R-CNN和Mobilenet_SSD网络模型是有监督学习,需要对样本进行标注,以便网络模型训练过程中能够定位到需检测的目标位置。
使用labelImg软件,打开样本图片,人工判断需要标注的目标位置与种类,并手动画出矩形标注框,将目标整体包围,保存形成关于目标在图片中的位置文件,即与图片名相同的xml文件。完成13 300张图片手动标注以后,即可对CNN进行训练,标注效果如图3所示。

图3 标注效果Fig.3 Label effect
2.4 模型训练
CNN的训练过程即是对网络模型内部参数的求解过程。其中,Faster R-CNN提供了交替训练和近似联合训练2种训练方式,本文选择使用近似联合训练,在保证准确率的同时,训练速度更快。
根据样本集调整预训练的学习参数:①样本数据分块设置为133;②模型初始化,采用标准偏差0.01的零均值高斯分布来初始化权重;③设定每一层卷积层学习率一致,初始学习率0.001,系数动量0.9,权值衰减系数0.000 5。
2.5 图像检测结果及分析
本文的实验环境为Intel(R) Core(TM) i7-5500U CPU @ 2.40 GHz,8 GB RAM以及Windows7(64位)操作系统,图像检测与分类基于OpenCV和Tensorflow进行。
实例验证的指标包括准确率和召回率,准确率为正确检测的目标数量与标记目标总数量之比,召回率为正确检测的目标数量与实际目标总数量之比。
图片选取了非训练样本的378张测试样本,其中危险物体选定为大型挖掘机,共计420台挖掘机,将其放入训练模型中进行目标检测。图像检测部分结果如图4所示,其中左列为Faster R-CNN网络模型结果,右列为Mobilenet_SSD网络模型结果。

图4 图像检测结果Fig.4 Image detection results
Faster R-CNN与Mobilenet_SSD网络模型图像检测数据见表1。

表1 检测数据Tab.1 Detection results
Faster R-CNN网络模型检测运行时间远大于Mobilenet_SSD网络模型检测时间,但其准确率高于Mobilenet_SSD网络模型。这主要是因为Faster R-CNN网络模型比Mobilenet_SSD网络模型规模大,拥有更多的卷积层和下采样层,需要更长的运算时间;与此同时,Faster R-CNN网络模型需要生成候选框,在多个候选框中进行回归与分类,这会消耗更多的计算时间;也因如此,Faster R-CNN网络模型对于图像中目标的特征提取更加详细准确,在识别多目标图像时精确性更高。
在比较召回率时,Faster R-CNN网络模型却小于Mobilenet_SSD网络模型。通过仔细分析图像标注结果发现,在Faster R-CNN网络模型的结果中出现了大量仅标注了挖掘机局部区域的现象。根据分析,Faster R-CNN网络模型在对目标局部特征识别后,将其作为目标本身,减小了召回率;另外,当多个挖掘机重叠时,因为其特征发生重叠,网络模型会将其作为同一个目标标记,这也是召回率降低的一个重要原因。
实例验证的初步结论是:Faster R-CNN网络模型更适用于对目标检测精度要求较高的场合,而Mobilenet_SSD网络模型更适用于对目标检测效率要求较高的场合。
2.6 现场图像检测结果及分析
现场图像选取了从电网监控系统中挑选出包含危险物体的图像,其中危险目标选定为大型挖掘机,将其放入训练模型中进行目标检测。现场部分图像检测结果如图5所示,其中左列为Faster R-CNN网络模型结果,右列为Mobilenet_SSD网络模型结果。

图5 现场图像检测结果Fig.5 Detection results of on-site image
经过实际图像验证,在不考虑检测运行时间的情况下,Faster R-CNN网络模型的准确率远大于Mobilenet_SSD网络模型,且边界框位置和大小更加精确。
与图4结果相比,现场图像检测效果明显降低,主要原因在于现场图像中危险物体图像的占比太小,不到整个图像大小的1%,目标特征并不明显,提取和识别的难度较大,相应的目标分类准确率和边界框回归的准确性明显降低。
3 结束语
经过图像检测实验,初步验证了基于深度学习的输电通道危物辨识技术具有较高的识别效率和准确率,具备实际应用的基础。相比于早期电网使用的异物辨识技术,基于深度学习的输电通道危物辨识技术能够准确判断出危及输电通道安全运行的危险物体,并标记出物体位置,为电网运检和维护提供更加详细准确的信息,提高巡线效率,减少工作时间和人工的投入,也可避免人工识别中因疲劳可能造成的错误判断。
结合现场图像的检测结果,在实际应用中还需要考虑图像的拍摄条件等因素对识别正确率的影响,主要问题是识别目标在图像中所占比例较小,目标特征不够明显。在今后的工作中,需要着重解决较小目标的识别问题,研究方向主要有以下几点:①增加小目标样本在训练样本中的比例,提高小目标样本对训练模型参数的调节作用;②加强小目标特征表达,从图像预处理入手,减小大量背景图像对小目标的干扰;③调整训练模型的边界框长宽比和像素尺寸,提高模型对特定小目标的识别效率和精度[21-24]。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
知识经济·中国直销(2018年8期)2018-08-23
北京航空航天大学学报(2018年1期)2018-04-20
