
基于在线比较评论情感分析的方法探索
2019-09-29 13:42杨帆
中国市场 2019年25期
杨帆
[摘要]比较评论是一种比较普遍的评论形式,借用比较可以得到产品之间的差异性。文章在研究现有情感分析方法的基础上,对比较评论情感分析方法进行了探讨。其一般过程为:采用简单的比较句识别方式,使用监督学习构建特征词典,在词典中增加非特征词的特征判断,然后采用情感极性判断或使用情感词权重、程度副词以及否定词加权计分的方法判断语句的情感得分,获取到比较产品之间在特征属性上的差异。
[关键词]中文比较评论;情感分析;中文分词;评价模型
[DOI]10.13939/j.cnki.zgsc.2019.25.185
1引言
随着网上购物的蓬勃发展,网络评论越来越多,中文文本的情感分析研究也随之增加。这些评论对于产品的评价有较高的现实意义,比起早期的商品购物评分机制,评论更加具体,更加多元化,对于评论的挖掘是对评分机制的重要补充,甚至有超越和代替评分的趋势。在这些商品购买评论中,比较评论是指用户购物后发表的评论中有关这一产品与另一产品的对比信息,这类还有比较句的评论比起一般评论,能反映出更多产品之间的差异和优劣,有助于分析产品在市场上的竞争力,故比较评论挖掘近来也受到研究者的重视,有不少学者对其进行情感分析并得到关于多个产品在不同属性上的比较数据,为决策者提供参考。
2相关研究
比较评论挖掘的研究是从文本挖掘中的关系抽取技术演化而来的,关系抽取是信息抽取的一个重要分支,是将有关系的实体从文本中获取出来的方法。其具体的手段包括监督学习、半监督学习、无监督学习以及远程监督学习。监督学习人工参与多,而无监督学习则无人工行为,远程监督是借用远程数据进行人工标注的方式。
借助关系抽取的研究方法,比较评论情感分析主要从以下几个方面开展,包括比较句识别技术、比较要素抽取以及比较观点的情感分析。
2.1比较句识别技术
比较句的识别最开始是英文的识别研究,Jindal等提出将分类器和CSR相结合的比较句识别方法获得了不错的F值。[1]国内较早的研究是黄小江讨论了汉语比较句的范畴、外延和特征,定义了汉语比较句识别的任务,并提出用SVM分类器将汉语句子分为“比较”和“非比较”两类。[2]黄高辉以SVM为分类器,以特征词和 CSR序列规则为特征, 同时利用 CRF算法抽取实体对象 , 并增加以实体对象的信息作为特征,显著提高了比较句识别的准确率 、召回率和 F 度量。[3]
比较句的识别主要是通过识别算法发掘文本中的比较语句,由于中文语句的灵活性,其算法比英文的比较句复杂,也有学者提出比较简单的发现方式,特别是针对差比语句的情感分析研究,其识别方式为只要语句中包含两个比较产品以及“比”就识别为差比语句。文章的研究就是采用这种简单有效的方式进行识别。
2.2比较要素的抽取
比较要素是比较句中的特征识别,即比较点的识别和抽取,简单地说就是这个比较句是在比较这两个对象的什么特征。对于细粒度的属性级别的情感研究,特征发现和抽取也是非常重要的一个环节。
比较要素的抽取目前主要有两种方法,一种是人工总结特征词典,包括收集产品说明书中的产品特征,相关专家给出的产品特征以及总结部分测试文本中的特征,然后根据特征词典使用字符串匹配的方法抽取比较句中的比较点信息;另一种是使用特征发掘,在没有特征词典的情况下,使用发掘算法在测试数据集中发现总结特征词,动态形成特征词典,然后在使用字符串匹配等方式抽取比较点。[4-5]
2.3比较观点的情感分析
比较观点的情感分析是比较评论挖掘的第三个研究方向,这个主要是借用一般语句的情感分析方法对比较语句做情感分析。常用的情感分析主要是使用情感词典,并结合考虑程度副词以及否定词,然后判断出该句的情感倾向。目前有两种情感计分方法,一种是只判断情感极性,正面情感为+1,负面情感为-1;另一种是在判断极性的基础上,还要根据程度副词判断好坏程度,有的还会根据情感词本身的情感强烈程度给出权重后再结合程度副词进行判断。[6]
3模型实现方式
3.1实现工具
(1)Python语言与爬虫技术。Python语言是一种简单而又强大的高级编程语言,有非常丰富的数据结构,灵活的程序处理方式,以及大量的支持该语言的第三方函数库,在爬虫和大数据处理方面有非常明显的编程优势。[7]
(2)分词。现存的几大分词工具有:结巴中文分词、中科院分词、Smallseg以及Yaha分词等,其效果存在细微的差异,大致上的分词结果相仿。文章采用基于python的结巴中文分词技术,对抽取出的比较评语进行分词。
分词的好坏主要影响情感分值的计算,对于特征抽取的影响较少。为了减少由于分词不当而导致的词语计分错误,多采用人工的方式对情感词典进行修正。
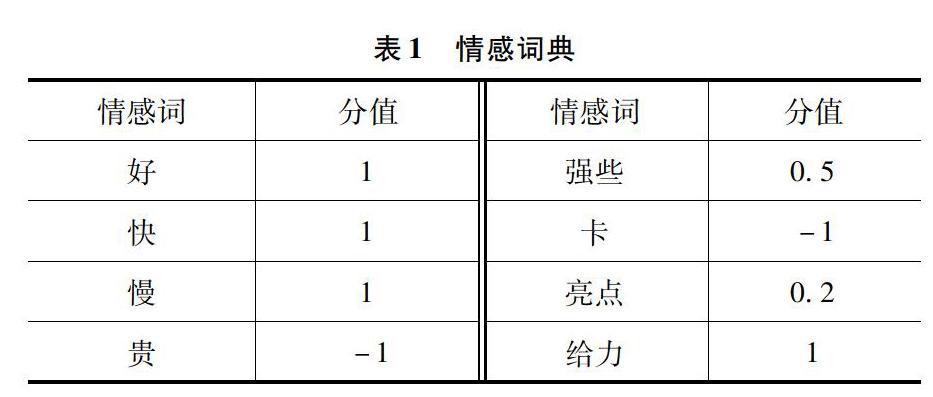
(3)词典。词典的优劣直接决定了模型的有效性,一般在现存的一些词典(知网情感词典、台湾大学NTUSD、清华大学李军的褒贬义词典等)基础上,结合所训练的文本材料自身的行业特点,设计特定语境的情感词典。另外,为了抽取特征,获得比较对以及计算情感权重,还需要设计产品名称词典、特征词典、特征分类词典、否定词典、程度副词词典以及同义词典。其中程度副词词典分为前缀词典和后缀词典。
部分词典情况如表1所示。
3.2实现步骤
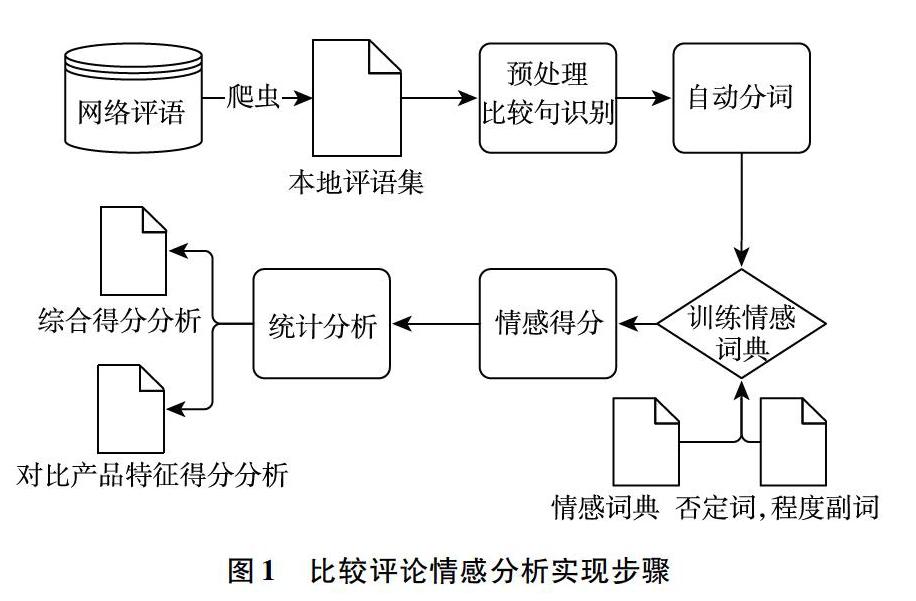
按照比较评论情感分析的具体需要,文章设计了一种基于在线比较评论情感分析步骤,如图1所示。从网络评语到统计分析,共包括了5大处理过程:网络评语的爬取、数据的预处理与比较句的识别、自动分词、训练情感词典、计算情感得分、统计分析。
4结论
文章在现有研究的基础上,提出了一种在线比较评论情感分析方法的解决思路,能很好地对产品做成评价,进行数据试验后,其评价的结果与官方给出的排名结果基本一致。而此方法不仅能对产品的综合情况进行分析,还可以针对产品某一具体特征的情况给出评价值,为决策提供更加精细的分析数据。主要的研究不足为模型的智能化程度还不够,分值计算为线性方式也会损失精度,后续研究可进一步完善。
参考文献:
[1] NITIN JINDAL,BING LIU. Identifying comparative sentences in text documents[C].Washington:In Proceedings of SIGIR,2006:244-251.
[2]黄小江,萬小军,杨建武.汉语比较句识别研究[J].中文信息学报,2008, 22 (5):30-37.
[3]黄高辉,姚天防,刘全升.CRF算法的汉语比较句识别和关系抽取[J].计算机应用研究,2010, 27(6): 61-64.
[4]王凤霞.比较句识别及观点要素抽取方法研究[D].太原:山西大学,2013.
[5]周红照,侯明午,侯敏,等.基于语义分类的比较句识别与比较要素抽取研究[J].中文信息学报,2014,28(3):136-141,149.
[6] 吴晨,韦向峰 . 用户评价中比较句的识别和倾向性分析[J].计算机科学,2016,43(6A):435-439.
[7]黄红梅,张良均. Python数据分析与应用[M].北京:人民邮电出版社,2017.
