
基于刑事案例的知识图谱构建技术
2019-09-23 07:07陈彦光刘海顺李春楠孙媛媛
郑州大学学报(理学版) 2019年3期
陈彦光, 刘海顺, 李春楠, 刘 静, 孙媛媛
(1. 大连理工大学 计算机科学与技术学院 辽宁 大连 116024;2. 大连市人民检察院 技术处 辽宁 大连 116011)
0 引言
近年来,我国不断深入推进“智慧司法”建设.随着中国裁判文书网、中国庭审公开网等平台的相继建成运行,我国司法公开达到前所未有的广度和深度.若能以网络上海量的案例信息为基础构建知识图谱,将产生巨大价值.知识图谱是用于描述海量实体、实体属性及实体间关系的有效工具[1].随着语义网络的快速发展,互联网上出现了大量的知识图谱,如国外的YAGO、国内的开放中文知识图谱OpenKG.CN等.但以上知识图谱都是面向通用领域的,面向专业领域尤其是司法领域的知识图谱尚寥寥无几. 国内外在司法领域进行自然语言处理和数据挖掘研究均已有报道.国外方面,文献[2]发明了一种基于荷兰案例法的法律推荐系统;文献[3]结合司法领域的信息检索技术,设计了一个司法问答系统;文献[4]基于Okapi检索模型,提出了一种改进的法律判决信息提取方法;文献[5]提出了奥地利法律的表示方法,并构建了司法知识图谱.国内方面,文献[6]介绍了法律知识库的设计思路及框架;文献[7]运用语义标注技术构建刑事审判本体实例库;文献[8]将文本挖掘技术应用于法律事务,可以让不熟悉专业用语的群众更有效地获得相关查询;文献[9-10]实现了对法律文书的罪名预测;文献[11]将定罪过程建模为多标签分类问题,解决了定罪过程中出现的动态标签问题和标签分布不平衡问题.近年来,在垂直领域的中文知识图谱构建技术方面,针对医疗和化学等领域的数据处理、知识获取和命名实体识别技术等方法也有一些研究[12-14].
本文以涉毒类案件为例,提出了一种面向刑事案例的知识图谱构建系统,系统主要包含案例信息提取算法、复杂案例的案情抽取模型和案件要素抽取算法.刑事判决书文档以内容划分,可以分为单人、单情节的简单案例文档,以及涉及多个犯罪嫌疑人或多个犯罪情节的复杂案例文档,二者区别在于复杂案例文档中案情描述部分占据很大篇幅,难以通过规则对其案情描述进行提取.现有的对刑事判决书的文本挖掘研究以简单案例为主,直接对复杂案例进行挖掘存在困难.本文在知识图谱构建系统中运用了一种迭代方法,利用简单案例的信息抽取结果训练适用于复杂案例的信息抽取模型,从而为在缺少人工标注数据集的情况下进行复杂案例信息抽取提供了一种思路.
1 基于司法案例的知识图谱构建方法
依照裁判文书的结构特征,基于司法案例的知识图谱构建流程如图1所示.由图1可以看出,本文的主要方法包含3个部分:案例信息提取算法的设计、复杂案例案情抽取模型的设计以及案件要素抽取算法的设计.

图1 基于司法案例的知识图谱构建流程Fig.1 Flow chart of the knowledge graph construction based on judicial cases
1.1 案例信息提取算法的设计
1.1.1案例本体结构定义 本体是对一个特定领域的重要概念的形式化描述.在本文定义的案例本体结构中,根元素为案例的刑事判决书,涵盖全部案例信息.案例本体和实例对照如表1所示.其中针对本体结构中的犯罪情节,定义其实例为该案例的案情描述,本文中出现的犯罪情节是指本体结构中的犯罪情节部分.

表1 案例本体和实例对照Tab.1 Comparison of case ontology and instance
1.1.2信息提取规则设计 通过分析大量的刑事判决书内容,可以发现刑事判决书的内容组织形式相对规范,且在每个部分有标志性词语可作为信息提取的关键点.依照定义的案例本体结构,分别为需要抽取的信息构造语法规则,同时注意对现有的规则进行补充完善,尽量覆盖每份刑事判决书的全部信息.
1.1.3案例信息提取流程 案例信息提取流程如图2所示.由于刑事判决书的内容格式相对规范,直接使用正则表达式和信息提取规则对各部分信息进行提取.

图2 案例信息提取流程Fig.2 Flow chart of case information extraction
1.2 复杂案例案情抽取模型的设计
案例信息提取算法在简单案例上效果良好,但在复杂案例上难以将全部犯罪情节提取出来.针对此问题,将复杂案例的判决书文本划分为句子集合,利用文本分类方法将这些句子分为案情描述句和非案情描述句两类.实验结果表明,句子分类模型对复杂案例案情描述提取的准确率,与案例信息提取算法对简单案例案情描述提取的准确率相当.对复杂案例犯罪情节以外的其他案例信息依然使用案例信息提取算法进行提取.
1.2.1基于卷积神经网络的文本分类方法 卷积神经网络(CNN)是一类深度前馈人工神经网络,在计算机视觉和语音识别方面取得了显著成果.2014年,文献[15]提出用CNN进行文本分类的方法.CNN句子分类模型结构简单,输入层既可以使用初始化的词向量,也可以使用预训练的词向量;隐藏层使用一维卷积操作提取文本特征;输出层使用Softmax分类器基于文本特征预测分类结果.
1.2.2基于CNN的案情描述句子分类模型 对复杂案例的案情描述和非案情描述进行分类,但是缺少基于复杂案例的案情描述句和非案情描述句标注数据集,直接构造可用于训练句子分类模型的数据集需要一定的时间和人力成本.考虑到复杂案例的案情描述句和简单案例的案情描述句在语法和语义上具有一致性,一个简单案例通常只有一个案情描述句,可通过案例信息提取算法直接提取出来.一个复杂案例有几个到几十个案情描述句,单个句子均与上述实例类似.对非案情描述部分而言,简单案例和复杂案例在句子级上也具有一致性.因此,由简单案例的案例信息提取结果构造训练集,训练句子分类模型,以对复杂案例的案情描述进行提取,模型的测试集是基于复杂案例构造的.在句子分类模型的选择上,选择了CNN句子分类模型[15].该模型是轻量级的,不会占用过多的时间成本,并且具有较好的鲁棒性,在一定程度上能满足知识图谱构建的需要.
以训练好的CNN句子分类模型为中心,前置判决书文本预处理模块,后置案情描述输出模块,将该模型包装为复杂案例的案情抽取模型,嵌入知识图谱构建系统.模型的输入为判决书文档,输出为犯罪情节.该模型为复杂案例犯罪情节的提取提供了一个解决方案.实验结果表明,将判决书分为简单案例判决书和复杂案例判决书,以简单案例为基础迭代处理复杂案例的方法是完全可行的.
“三个一”精准化钻井实现了技术措施监控由事后处理向事前控制的转变。以往井队做出技术决策后对公司技术部门存在不报或瞒报问题,只有技术措施执行不下去或出现复杂故障的时候才向技术部门汇报。对此公司技术部门采取以下措施:
1.3 案件要素抽取算法的设计
将刑事判决书的内容分为案情描述和非案情描述两个部分.针对刑事判决书中的案情描述,通过自然语言处理技术进行深入分析,在实体识别的基础上提取构成刑事案件的基本要素即案件要素,结合关系类型构建“实体-关系-实体”三元组.
1.3.1案件要素识别过程 在进行案例信息提取之后,针对案情描述部分,依照自然语言处理的通用流程,使用语言技术平台LTP[16]进行分词、词性标注及命名实体识别处理.
由于面向司法领域,因此需要构造词典对案情描述中涉及的名词如罪名、犯罪动作、毒品类案件中的非法毒品名称等进行定义.在对通用的命名实体进行识别之后,结合实际办案情况,对命名实体识别的结果进行二次处理,添加非法毒品名称等类型的实体,使用BIEOS标注方案进行表示,最终得到犯罪情节中的犯案时间、犯案地点、涉案人、涉案毒品等案件要素信息.
1.3.2关系定义 本文旨在构建对提供量刑建议有参考价值的知识图谱,因此重点考虑与量刑有关的关系类型,对其他信息暂不考虑.
以涉毒类案件为例,常见的罪名有三类:贩卖毒品罪、非法持有毒品罪、容留他人吸毒罪.上述三类罪名中与量刑相关的犯罪动作可划分为五类,分别为“卖”“买”“持有”“容留”“吸食”;针对被告人的判决结果,可将刑罚也划分为五类,分别为“罚金”“拘役”“有期徒刑”“无期徒刑”“死刑”.
1.3.3三元组构建 针对非结构化的案情描述,按照定义的关系类型,结合语句的语法结构设定规则,将识别案件要素以三元组形式存储.
在确定三元组中两个实体的关系时,需要通过分析语法结构中的主谓关系等进行判别.对文本进行依存句法分析,确定语句中各要素之间的句法关系.依存句法分析是将句子由一个文本序列转化为一棵结构化的依存分析树,通过依存树上的关系标记来表示案件要素之间的关系.
为将每个案件的犯罪情节和案例的基本信息联系起来,将案例信息同样存储为数据表的格式,刑事判决书的文书编号作为外键和犯罪情节的数据表进行关联.针对每个情节的犯案时间和地点,同样存储在数据表中,通过指代该情节三元组的ID值与犯罪情节的数据表相关联.
2 实验结果
2.1 数据集
使用的数据集为中国裁判文书网公布的涉毒类案件的刑事判决书,涉毒类案件主要以三类罪名为主,分别为贩卖毒品罪、非法持有毒品罪和容留他人吸毒罪.其中贩卖毒品案件209 055份,非法持有毒品案件30 927份,容留他人吸毒案件88 600份.根据简单案例和复杂案例的刑事判决书案情描述部分的书写结构不同,首先筛选出简单案例共247 865份,其余都归为复杂案例.
2.2 案例信息提取
根据所定义的案例本体结构和提取规则,设计了案例信息提取算法,实现了案例信息的提取和存储.实验采用328 582份案例的刑事判决书文本文档为数据集,依据信息抽取过程中出现的问题,不断对规则进行修正和补充,得到最终的案例信息提取算法.
由于数据无标注,需要人工对算法进行评估.对三类案件的简单案例分别随机抽取130份进行统计,每组进行三次实验,采用准确率和召回率两个指标作为模型的评价标准.本文中的准确率和召回率都是以每篇刑事判决书文档为单位进行定义,准确率和召回率的计算公式如下:


针对三类案件分别进行案例信息提取实验,其中贩卖毒品罪、非法持有毒品罪和容留他人吸毒罪在文档级别的准确率分别为80.15%、82.34%和81.04%,召回率分别为93.47%、97.26%和94.94%.
由于提取的案例信息中的犯罪情节部分规定必须准确涵盖该案例的案情描述内容,不可以缺少信息,也不能够包括多余的信息,如证据、证人证言、公诉机关的指控意见等,所以对准确率的定义比较严格.而在真实的刑事判决书中,由于办案人员写作风格的不同,部分文书中案情描述会夹杂着证据、证人证言等内容,因此整体而言,案例信息提取算法的总体准确率主要受犯罪情节提取准确率的影响,但三类案件准确率的平均值都达到了80%以上.由实验结果可以看出,本文的案例信息提取算法可以将刑事判决书中的案例信息有效地抽取出来.
2.3 复杂案例的案情描述提取
首先针对贩卖毒品类案件训练了CNN句子分类模型.随机选取简单案例的案情描述句子1 000句作为正例,字长度大于20的非案情描述句子1 000句作为负例,以此构成训练集,另外在复杂案例中按上述要求各取300句构成测试集.分别使用初始化词向量和预训练词向量进行两组实验,准确率分别为65.38%和75.26%,其中预训练词向量由30余万份判决书文档使用Gensim训练得到.
通过实验可知,使用预训练词向量的效果更好,所以使用预训练词向量进行后续实验.由于训练集样本过少,得到的模型不足以被系统使用,故将训练集扩大到5 000句正例和5 000句负例,将测试集扩大到1 000句正、负例.当训练集规模达到10 000句时,准确率可达到91.51%,与案例信息提取算法对简单案例的案情描述提取结果相当,因此该分类模型可以被系统采用.在10 000句训练集的基础上,还分别基于SVM分类模型、逻辑回归模型和随机森林方法进行了对比实验,准确率分别为85.34%、84.15%和84.40%,结果均弱于本文采用的CNN句子分类模型.
验证了CNN句子分类模型的效果之后,又分别针对非法持有毒品类案件和容留他人吸毒类案件训练了CNN句子分类模型.以准确率作为参考指标衡量模型的提取效果,贩卖毒品罪、非法持有毒品罪和容留他人吸毒罪的实验结果分别为91.51%、93.24%和89.77%.
2.4 司法案例知识图谱构建
构建的知识图谱中包含非犯罪情节和犯罪情节两部分内容.非犯罪情节部分是指通过案例信息提取算法提取的案例基本信息表;犯罪情节部分是围绕定义的五类犯罪关系和五类判决结果关系,将与量刑相关的文字描述处理为多个结构化的三元组形式,然后进行存储,形成犯罪情节信息表,同时将犯罪情节的时间和地点也存储为数据表的形式,构成基于司法案例的知识图谱.
以“陈某容留他人吸毒案(2017)川1 681刑初63号”文件为例,其中针对犯罪情节的描述为:“1. 2017年4月初的一天,被告人陈某在华蓥市XX路XX号其家中容留王某某吸食毒品甲基苯丙胺(冰毒).2. 2017年4月21日晚,被告人陈某在华蓥市XX路XX号容留柏某、王某吸食毒品甲基苯丙胺……”;针对判决结果的描述为:“判处有期徒刑九个月,并处罚金人民币6 000元”.
以此为基础构建的三元组形式示例如表2所示.可以看出,用本文的方法准确地将犯罪情节中的各个案件要素抽取出来,并与关系对应,形成“实体-关系-实体”三元组形式,同时将被告人的判决结果处理为数字化形式,刑期以[年, 月, 日]的形式存储,可以进行对案件情节和判决结果的统计.
以三类涉毒类案件为数据基础进行了知识图谱的构建,建成的知识图谱中“实体-关系-实体”三元组共274万余个,包含涉及量刑的犯罪情节和判决结果的信息.基于本文构建的知识图谱,可以方便地进行查询、统计等应用.表3给出了三类案件简单案例中的罚金分布统计情况.
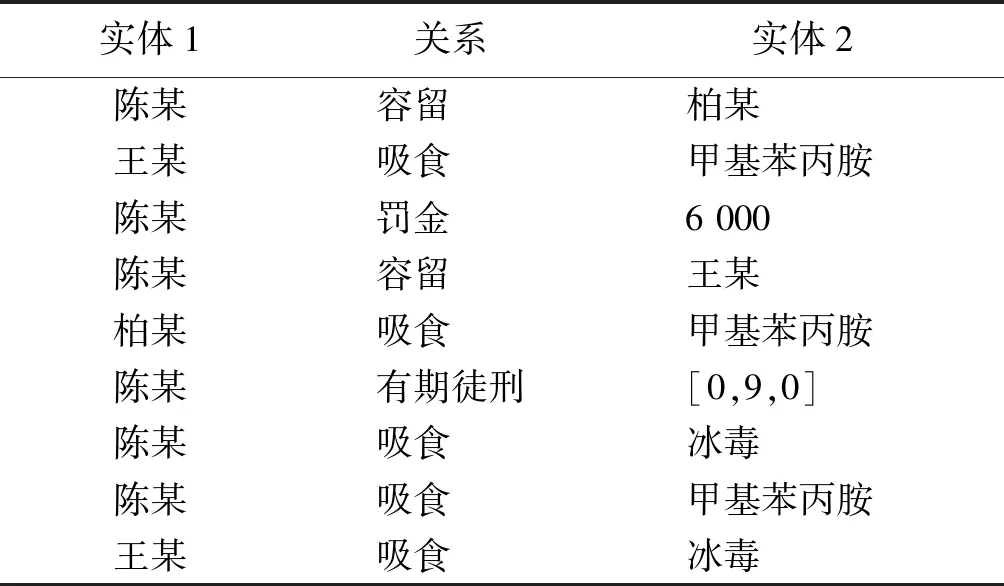
表2 量刑相关的三元组形式示例Tab.2 Form of the triples related to measurement of penalty

表3 三类案件简单案例中的罚金分布统计情况Tab.3 Statistics of fines in simple cases of the three crimes
3 结论
针对2004—2017年公开的30余万份涉毒类案件刑事判决书,构建了面向涉毒类刑事案件的知识图谱.基于所构建的知识图谱,可实现对相关案件关键情节和判决结果的统计分析,为司法文书的智能化处理提供数据基础.下一步的工作将对已构建的知识图谱进行完善,对指代同一事物的实体进行实体消歧,同时继续挖掘判决书的文本特征,改进案件要素提取算法,训练针对多类案件的多分类模型,以及评估多分类模型的优良性.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
少先队活动(2020年12期)2021-01-14
健康体检与管理(2021年10期)2021-01-03
南方周末(2020-01-30)2020-01-30
青少年科技博览(中学版)(2019年12期)2019-04-10
新城乡(2018年6期)2018-07-09
领导科学论坛(2016年9期)2016-06-05
