
基于双语信息和神经网络模型的情绪分类方法
2019-09-23 07:07李寿山
郑州大学学报(理学版) 2019年3期
张 璐, 殷 昊, 李寿山
(苏州大学 自然语言处理实验室 江苏 苏州 215006)
0 引言
随着社交网络的迅速发展,越来越多的用户倾向于在以微博为代表的社交媒体中表达自己的观点或情感,每天数以亿计的微博文本涉及时事政治、社会热点、科技、娱乐等生活的方方面面.为了挖掘与分析这些海量的具有潜在价值的信息,情感分析正渐渐发展成为自然语言处理中的热点研究[1].
情感分析又称意见挖掘、观点分析等,是通过计算机帮助用户快速获取、整理互联网上的海量主观评价信息,对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[2].文本情绪分类是情感分析的一项基本任务,该任务旨在根据文本表达的个人情绪(高兴、伤心、愤怒等)对文本进行自动分类[3].由于用户之间本身存在着喜好、立场、出发点等诸多方面的差异,因此对生活中的各种事件和现象所表现出的情绪和态度也会有很显著的差异.迄今为止,文本情绪分析已经被应用在多个领域,比如股票市场[4]、在线聊天[5]以及新闻分类[6]等.
传统的情绪分类方法通常需要充足的人工标注语料,但是到目前为止,与情绪相关的公共语料库相对匮乏,获得这样的标注数据费时费力.社交文本还存在文本较短、信息量较少等问题.考虑到已有的文本情绪分类方法都是基于单语语料,我们尝试利用翻译语料对语料库进行扩充,并为情绪分类提供更多的信息量.
例1源文本: 今天大甩卖!我们去逛街吧~
翻译文本:There′s a big sale on today! Let′s go shopping.
例2源文本:To show off! This Gundam model looks nice.
翻译文本:来炫耀!这个高达模型看起来不错.
由于中文微博情绪语料库的匮乏,例1中的“大甩卖”没有在训练集中出现,那么它很难被正确分类,但是如果我们把它翻译成英文“big sale”,这样我们就可以利用英文Twitter情绪语料中的信息来弥补这一点.类似地,例2中的“show off”没有在训练集中出现,但是如果我们把它翻译成中文“炫耀”,那么就可以利用中文微博情绪语料中的信息增加信息量.
我们提出了一种基于双语信息和神经网络模型的情绪分类方法,同时利用中文微博语料和英文Twitter语料对模型进行训练.首先,利用机器翻译工具分别对两种源语言语料进行翻译,得到相应的翻译语料;其次,将相应语言的语料进行合并扩充,得到两组不同语言类型的语料;最后,将文本分别使用源语言和翻译语言进行特征表示,建立双通道LSTM模型融合两组特征,构建情绪分类器.
1 相关工作
目前,针对社交媒体的文本情感分析方法研究大都面向情感极性(正面、负面)[7],而细粒度的情绪分类方法研究还比较缺乏.
早期的一些研究利用规则来判别情绪类别,Kozareva等[8]基于统计方法,利用上下文词语与情绪关键词的共现关系对文本进行情绪分类.一般而言,情绪分类会被定义为一个机器学习问题.Tokuhisa等[9]提出了一种面向数据的方法,推断对话系统中说话者表达的情绪.Beck等[10]提出了一个基于多任务高斯过程的方法对情绪进行分类.Bhowmick等[11]利用多标签K近邻分类技术对新闻句子进行分类.Das等[12]利用弱势语言(孟加拉语)博客语料进行情绪分类,首先对句子的词汇进行6类情绪分类,再通过词汇的情绪类别来判断句子的情绪.Li等[13]提出利用句子的标签因子图和上下文标签因子图进行句子级的情绪分类,很好地解决了数据稀疏和情绪多标签问题.Xu等[14]提出了一种由粗粒度到细粒度的分析策略,通过整合相邻句子的转移概率来重新定义情绪的类别.Yang等[15]介绍了一种基于情绪的主题模型为预先定义的情绪构建了一个特定领域的词典.
以上这些情绪分类方法都需要利用充足的标注数据来训练模型,但是在很多情况下,获得这样的标注数据费时费力.有些研究通过半监督方法来解决这个问题,Liu等[6]提出了一种协同学习算法,利用未标注数据中的信息提升情绪分类的性能.Li等[16]提出了一个双视图标签传播算法,将源文本和回复文本分别看作两个视图.
2 基于双语信息和神经网络模型的情绪分类方法
传统的情绪分类方法都是基于单语语料进行,虽然情绪分类研究已开展多年,但是情绪语料库的构建工作相对较少,可用于研究的情绪语料库也比较缺乏[17].对于情绪分类任务来说,标注语料将会耗费大量的人力物力,并且各个情绪类别的样本分布很不平衡,影响情绪分类的性能.
2.1 机器翻译
为了同时利用中文微博语料和英文Twitter语料,我们用机器翻译工具(http:∥fanyi.baidu.com/translate)对源语料进行翻译得到翻译语料,即将中文微博语料翻译得到英文微博语料;英文Twitter语料翻译得到中文Twitter语料.图1的机器翻译模块展示了训练过程中机器翻译的流程.
2.2 基于双语信息和神经网络模型的情绪分类方法
为了能够充分利用双语信息,我们提出了一种基于多通道LSTM神经网络的情绪分类方法.我们将源语料和翻译语料进行合并,得到两组不同语言类型的语料,即将中文微博语料与中文Twitter语料合并得到中文混合语料,英文Twitter语料与英文微博语料合并得到英文混合语料.我们将分类文本分别使用中文、英文进行特征表示,使用LSTM[18]神经网络提取隐层特征,所用公式为
hChinese=LSTM(TChinese),
(1)
hEnglish=LSTM(TEnglish).
(2)
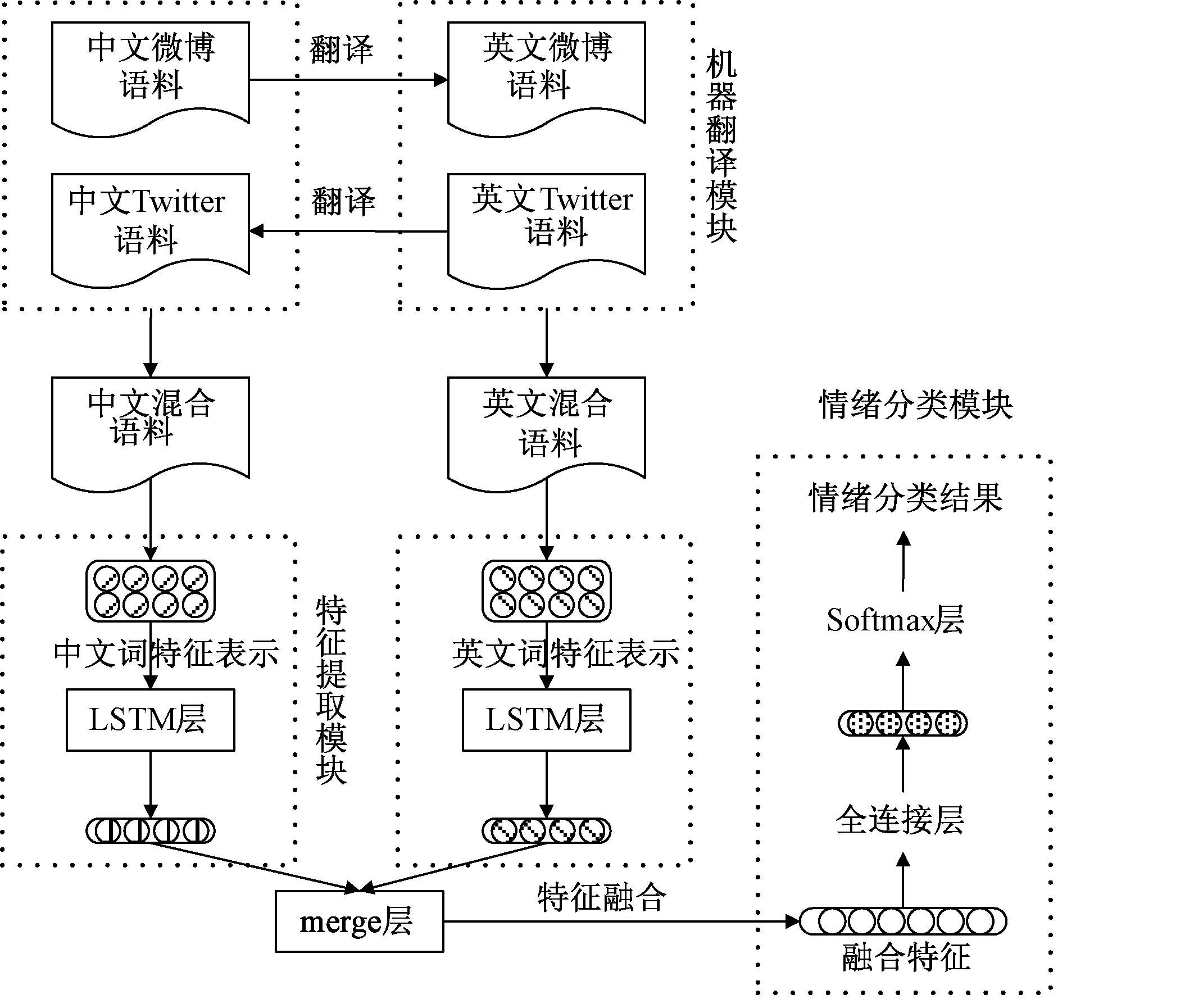
图1 基于双语信息和神经网络模型的情绪分类方法Fig.1 The approach to emotion classification based on bilingual information and neural model
其中:TChinese和TEnglish分别代表中文和英文特征表示.
在模型的merge层中,我们将上述两组隐层特征进行特征融合,具体融合公式为
hmerge=hChinese⊕hEnglish,
(3)
其中:⊕表示向量逐元素相加或者向量拼接.本文对两种融合方式都进行了探索.
在情绪分类模块中,我们将融合特征hmerge作为全连接层的输入,为了缓解过拟合,全连接层使用了Relu激活函数,具体公式为
hdense=Relu(Wdense·hmerge+bdense),
(4)
其中:Wdense和bdense分别是全连接层的权重和偏置.Relu激活函数能够将小于0的值全部置0,具有引导适度稀疏,缓解过拟合的作用.模型的最后是Softmax层,用来输出分类概率,所用公式为
p(y|TChinese,TEnglish)=Softmax(Wo·hdense+bo),
(5)
其中:Wo和bo是输出层的权重和偏置;p(y|TChinese,TEnglish)是当前样本的分类概率.
我们选用交叉熵损失函数作为模型的损失函数,其公式为
(6)
其中:N是训练样本的数目;C是目标类别的数目;yj表示属于第j个类别的概率;l是正则化系数;θ代表所有参数.我们采用Adam优化算法[19]对参数进行更新.
3 实验
3.1 实验设置
本实验使用的中文语料来自新浪微博,由NLP&CC-2013中文微博情绪分析评测提供,英文语料来自Twitter,由SemEval-2018 Task 1: Affect in Tweets 提供.中文语料对应7个情绪类别,分别是高兴、喜好、愤怒、悲伤、恐惧、厌恶和惊讶,样本数量分别为1 460、2 203、669、1 173、148、1 392、362.英文语料对应4个情绪类别,分别是愤怒、恐惧、高兴和悲伤,样本数量分别为1 901、2 452、1 816、1 733.对于中文语料,由于恐惧情绪的样本数量太少,根据其样本数生成测试集得到的实验结果具有较大的偶然性,因此我们选取第二少类别(惊讶情绪)样本数的20%(即362*20%≈72)作为各情绪类别的测试样本数.训练样本则从各类别的剩余样本中抽取.对于英文语料,我们分别从各个类别中选取200个样本作为测试集,剩余样本都作为训练集.由于中英文语料类别不一致,所以我们仅对类别相同的部分进行扩充.
我们首先使用复旦大学发布的分词工具FudanNLP对中文语料进行分词,英文语料则按空格进行切分,然后使用word2vec训练词的分布式表示,词向量维度设置为100.实验中使用的分类算法包括最大熵和LSTM神经网络,其中最大熵使用Mallet机器学习工具包,LSTM神经网络使用深度学习框架Keras,LSTM层的输出维度为256,全连接层的输出维度为128,迭代次数为20.我们采用正确率和F1值作为衡量分类性能的评价指标.
3.2 实验结果
为了验证基于双语信息的情绪分类方法的有效性,我们实现了以下几种情绪分类方法.
1) 基准方法+最大熵(Baseline_maxent).直接使用源语言的训练集训练最大熵分类器,对相应语言类型的测试集进行测试.
2) 基准方法+LSTM(Baseline_lstm).直接使用源语言的训练集训练LSTM分类器,对相应语言类型的测试集进行测试.
3) 语料库扩充+最大熵(CorpusExp_maxent).通过机器翻译对中英文语料进行翻译,从而实现训练语料的扩充.使用扩充后的训练集训练最大熵分类器,对相应语言的测试集进行测试.
4) 语料库扩充+LSTM(CorpusExp_lstm).通过机器翻译对中英文语料进行翻译,从而实现训练语料的扩充.使用扩充后的训练集训练LSTM分类器,对相应语言的测试集进行测试.
5) 基于双语信息的情绪分类方法:隐层拼接(Bilingual-concat).使用本文提出的基于双语信息的情绪分类方法,其中隐层向量通过拼接方式融合.
6) 基于双语信息的情绪分类方法:隐层相加(Bilingual-sum).使用本文提出的基于双语信息的情绪分类方法,其中隐层向量通过按位相加方式融合.
图2比较了几种情绪分类方法在中文测试集和英文测试集上的情绪分类性能.通过比较Baseline-maxent和Baseline-lstm以及CorpusExp_maxent和CorpusExp_lstm,我们发现LSTM分类器的性能整体上略优于最大熵分类器.

图2 中文和英文测试集上不同情绪分类方法的性能比较Fig.2 The results of different classification methods on weibo and Twitter
为了验证通过机器翻译实现语料扩充对分类性能的影响,我们比较了语料库扩充方法与基准方法(Baseline_maxent和CorpusExp_maxent以及Baseline_lstm和CorpusExp_lstm).在中文测试集上,正确率分别提高了0.6%和1%;在英文语料上,正确率分别提高了1.5%和2.4%.上述数据表明,通过翻译语料扩充训练样本能够一定程度上提高情绪分类的性能.
为了验证使用双语信息对情绪分类性能的影响,我们比较了基于双语信息的情绪分类方法和语料库扩充+LSTM方法(CorpusExp_lstm)的实验性能.在中文测试集上,当隐层向量拼接融合(Bilingual-concat)时,正确率提高了2.8%;当隐层向量按位相加融合(Bilingual-sum)时,正确率提高了3%.在英文测试集上,当隐层向量拼接融合(Bilingual-concat)时,正确率提高了1.2%;当隐层向量按位相加融合(Bilingual-sum)时,正确率提高了1.4%.以上数据表明,融合文本的双语信息能够增加文本的信息量,提高情绪分类性能.
最后,我们比较了基于双语信息的情绪分类方法与基准方法+LSTM方法(Baseline_lstm)的实验性能.在中文测试集上,当隐层向量拼接融合(Bilingual-concat)时,正确率提高了3.8%;当隐层向量按位相加融合(Bilingual-sum)时, 正确率提高了4%.在英文测试集上,当隐层向量拼接融合(Bilingual-concat)时,正确率提高了3.6%;当隐层向量按位相加融合(Bilingual-sum)时, 正确率提高了3.8%.实验结果表明,我们提出的基于双语信息的情绪分类方法既能够通过机器翻译扩充训练样本,又能够增加单个文本的分类信息,不管在中文测试集还是英文测试集上都能够显著提高情绪分类的性能,充分验证了该方法的有效性.
此外,为了更细致地比较各情绪分类方法的性能,我们分析了以上几种情绪分类方法在各情绪类别上的F1值,如表1和表2所示.从表1和表2中可以看出,基于双语信息的情绪分类方法在各情绪类别的F1值上总体是有提升的.从F1值的宏平均也可以看出,基于双语信息的情绪分类方法在使用隐层拼接融合和按位相加融合时,分类性能都明显优于其他方法.

表1 中文语料上各情绪类别的F1值Tab.1 The F1 scores of different classification methods on weibo
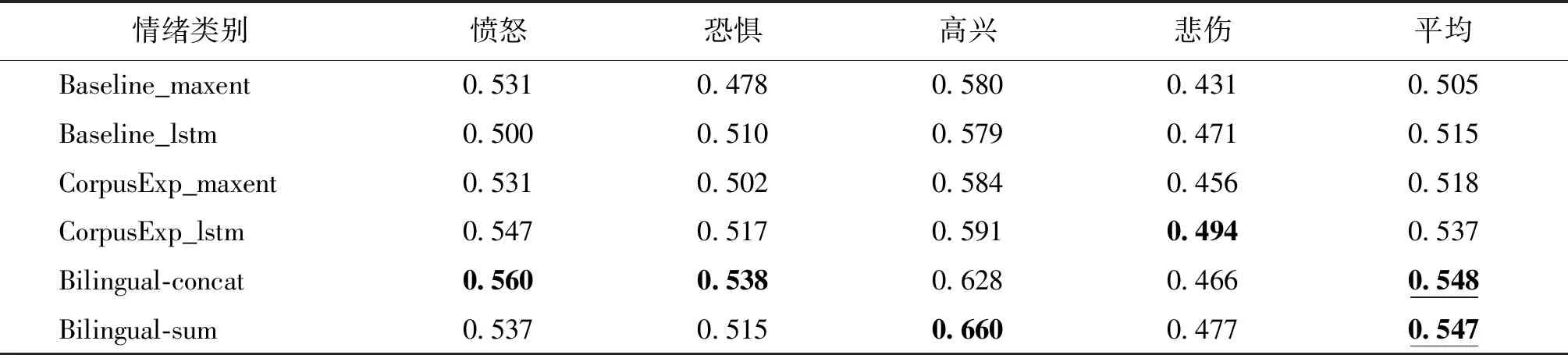
表2 英文语料上各情绪类别的F1值Tab.2 The F1 scores of different classification methods on Twitter
4 结论
本文针对文本情绪分类任务中已标注样本不足和分类文本较短、信息量少的问题,提出了一种基于双语信息的情绪分类方法.该方法既能够通过机器翻译扩充语料,又能够融合分类文本的中英文特征表示,增加分类文本的信息.实验结果表明,该方法能够充分利用训练样本,不管在微博语料还是Twitter语料上的性能都明显优于传统方法.
在下一步工作中,我们将探索中文与其他语言(德语、日语等)的融合,以此来验证我们方法的有效性.此外,我们可以实现基于多语信息的情绪分类方法,将多组不同语言领域的语料融合,同时提升各语言领域的情绪分类性能.
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
厦门大学学报(自然科学版)(2021年4期)2021-06-22
计算机应用与软件(2020年9期)2020-09-09
人民珠江(2019年4期)2019-04-20
计算机应用与软件(2018年9期)2018-09-26
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
外语教学理论与实践(2014年2期)2014-06-21
