
基于长短期记忆网络的载荷谱外推方法研究
2019-09-19 07:41:16向华荣郑国峰秦致远
重庆理工大学学报(自然科学) 2019年8期
向华荣,曾 敬,郑国峰,秦致远
(1.重庆西部汽车试验场管理有限公司, 重庆 408300;2.中国汽车工程研究院股份有限公司, 重庆 401122)
在汽车或零部件的开发过程中,可靠性均需要通过道路试验进行检验。根据疲劳理论的损伤等效原理,在已知用户使用环境及汽车载荷输入的情况下,理论上可通过在试验场里按照一定比例混合各种强化路面,复现出用户工况下的载荷输入。通过试验场的强化路面,可以在较短的时间内完成可靠性验证试验,达到减少试验时间、缩短研发周期的目的。出于降低研发成本和时间的考虑,一般用户使用环境的汽车载荷输入不会以目标里程为基准进行载荷谱采集,而是根据用户道路比例分布情况,按类型进行采集,在样本量足够的前提下进行载荷谱外推,实现目标里程下的载荷谱获取。
目前较为典型的外推方法包含参数外推法、按里程分位点外推法、峰值(peak over threshold,POT)外推法、雨流矩阵外推法[1-3]等。其中参数外推法的原理是获取载荷谱均值、幅值的二维概率分布函数,基于概率密度分布函数以及外推目标里程,将相应的累积频次进行外推。POT外推法认为载荷谱时间序列中超过阈值的峰值服从一定的分布,通过对超过阈值的峰值的概率密度函数的拟合,基于概率密度函数对峰值进行外推。雨流矩阵外推法先将载荷谱通过雨流计数得到雨流矩阵,从雨流矩阵中选择外推的阈值计算穿越等级密度,然后通过累积雨流矩阵获取极限进行雨流矩阵估计外推。也有学者[4]对通过雨流计数后的分布进行核密度统计,得到非参数雨流外推模型后运用蒙特卡洛方法随机放置载荷循环进行外推。上述方法可根据载荷谱的特点或应用目的来进行选择,但往往在用分布函数进行拟合或设置阈值时引入了人为因素,外推结果需要再转化为时域程序谱作为下一步的输入。
本文基于长短期记忆网络(long-short term memory,LSTM)算法,对采集到的载荷谱进行外推[5-6]。该方法基于已有的采集样本,对目标里程下的剩余样本进行预测,直接得到目标里程下时域谱结果,在主要步骤上可减少外推中主观因素的影响。对不同外推方法进行对比,结果表明:所提出的方法能够实现对载荷谱的外推,且基于LSTM的外推方法能很好地复现原始雨流图分布特征。
1 基于长短期记忆网络算法的载荷谱外推理论
长短期记忆网络是一种基于循环神经网络的改进机器学习神经网络,LSTM可以识别并记忆时间序列中长期信息的特征,并对当前的输出产生影响。LSTM直接利用计算机“学习”原数据的特征,故该方法能在主要步骤上减少人的主观因素。目前该方法已成功运用在语音识别、机器翻译、交通流量预测、经济模型的拟合及预测上。黄婷婷等[7]通过LSTM神经网络的长期依赖特性来提高金融时间序列的预测精度,杨甲甲等[8]成功将其运用到工业负荷短期预测上,杨国田等[9]将其运用到火电厂NOx排放预测上,取得较好效果。本文使用LSTM对载荷谱时间序列进行学习后,通过得到的模型对原载荷谱进行长期预测,以达到“外推”的目的。基于长短期记忆网络算法的载荷谱外推基本流程见图1。

图1 LSTM外推基本流程
根据图1,基于长短期记忆网络算法的载荷谱外推方法的主要步骤如下:
步骤1 将载荷谱输入到基于长短期记忆网络算法中。
步骤2 将输入的载荷谱数据进行正则化,并划分训练集和测试集。划分训练集的目的在于获取适应输入样本的数学模型;划分测试集的目的在于通过训练得到数学模型,之后对样本进行载荷谱外推。
步骤3 基于LSTM算法,对输入载荷谱进行训练,获取适应输入样本的数学模型。LSTM算法由输入层xt、输出层ht、遗忘层ft、状态更新层Ct组成。对于标准循环神经网络,每个时刻的隐层状态由当前时刻的输入与之前的隐层状态相结合组成,即LSTM 具有“记忆”功能。
LSTM的一个单位的基本结构如图2所示,其中xt序列为输入时间序列,ht为输出时间序列。LSTM的最大特点就是输入xt不仅会影响到输出ht,还会将Ct-1改变为Ct,Ct和ht将输入到下一个基本单元甚至传递到更远的基本单元并影响其状态。
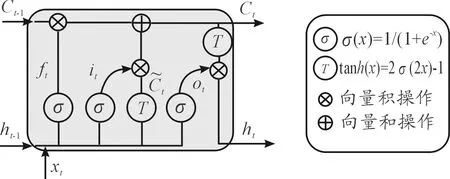
图2 LSTM单元结构

(1)
遗忘层ft由式(2)给出,它决定了过去记忆单元对当前记忆单元的重要程度,其由一个sigmoid函数控制输出。
ft=σ(Wf·[ht-1,xt]+bf)
(2)
输入层由式(3)给出,其与遗忘层类似,也是通过一个sigmoid函数来控制输出,得到一个在[0,1]范围的值,控制被加入的新信息。
it=σ(Wi·[ht-1,xt]+bi)
(3)
综合以上各层,最新记忆由式(4)给出,在整个学习过程中,其状态会不断更新。
(4)
输出层由式(5)(6)给出,输出门的作用是筛选出记忆单元和隐层单元中存在的冗余信息,输出时如果已达到阈值,就将输出与当前层的计算结果相乘,并把得到的结果作为下一层的输入;如果未达到阈值,则“遗忘”输出结果。
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot*tanh(Ct)
(6)
采用交叉熵损失作为代价函数能更好地解决参数更新效率下降问题,其损失C可通过式(7)进行计算,其中n表示样本总数,zl表示实际值。
(1-z)ln(1-f(∑lwlxl+bl))
(7)
将训练的输出数据与测试数据进行对比,计算两组数据的交叉熵代价函数。每一次训练中,经过前向计算得到当前训练阶段的代价函数,通过误差反向传播进行网络参数的更新,直至n次训练后代价函数收敛为止。
4) 对输入载荷谱进行外推计算。通过得到的模型对原载荷谱进行长期预测,以达到“外推”的目的。
2 基于LSTM的载荷谱外推算法应用
2.1 载荷谱采集
本次试验在样车各轮轮心处及减震器上安装加速度传感器,弹簧及部分连杆部位安装应变片,在某汽车试验场的几条主要特征强化路上进行采集,见图3。需要多次采集强化路面的载荷谱,最后取有效的载荷谱进行剔除奇异点、消除趋势项、滤波等预处理。各种试验路况信息见表1。
2.2 基于LSTM的载荷谱外推
基于谷歌发布的人工智能开源工具TensorFlow[10]建立LSTM外推模型。TensorFlow的特点是使用图来表示计算任务,图中的一个操作节点获得0个或多个张量来执行计算,生成 0个或多个张量,每个张量是一个类型化的多维数组。TensorFlow在会话的上下文中执行图,使用张量表示数据,通过变量维护状态。

图3 传感器安装及道路情况
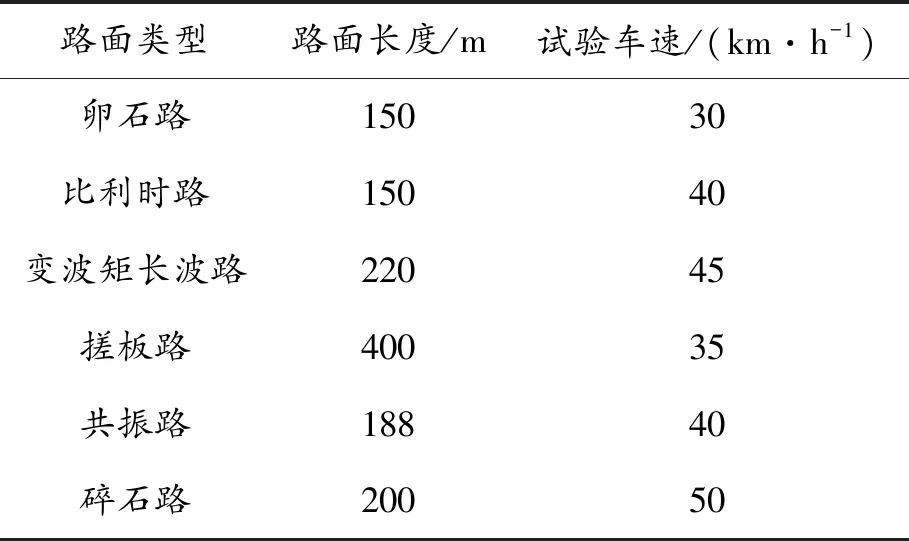
路面类型路面长度/m试验车速/(km·h-1)卵石路15030比利时路15040变波矩长波路22045搓板路40035共振路18840碎石路20050
本文首先通过python环境导入TensorFlow、pandas、numpy模块,将利用csv格式进行保存的时域谱数据通过pandas.read_csv函数读入程序,用data-numpy.mean(data))/numpy.std(data)函数进行标准化处理。在TensorFlow中已将LSTM模型封装为LSTMCell模块。本文定义神经元数量为100个,时间步长为20 ms,批处理大小为60,学习步长为0.000 1,在初始化输入与输出接口直接调用该模块,利用图1的流程进行训练。本文通过NVIDIA提供的CUDA作为硬件支撑,在整个机器学习过程中,通过tensorboard可以看到整个学习过程中loss的变化,见图4。当学习准确率达到98%时,继续学习的收益变小,可停止训练。
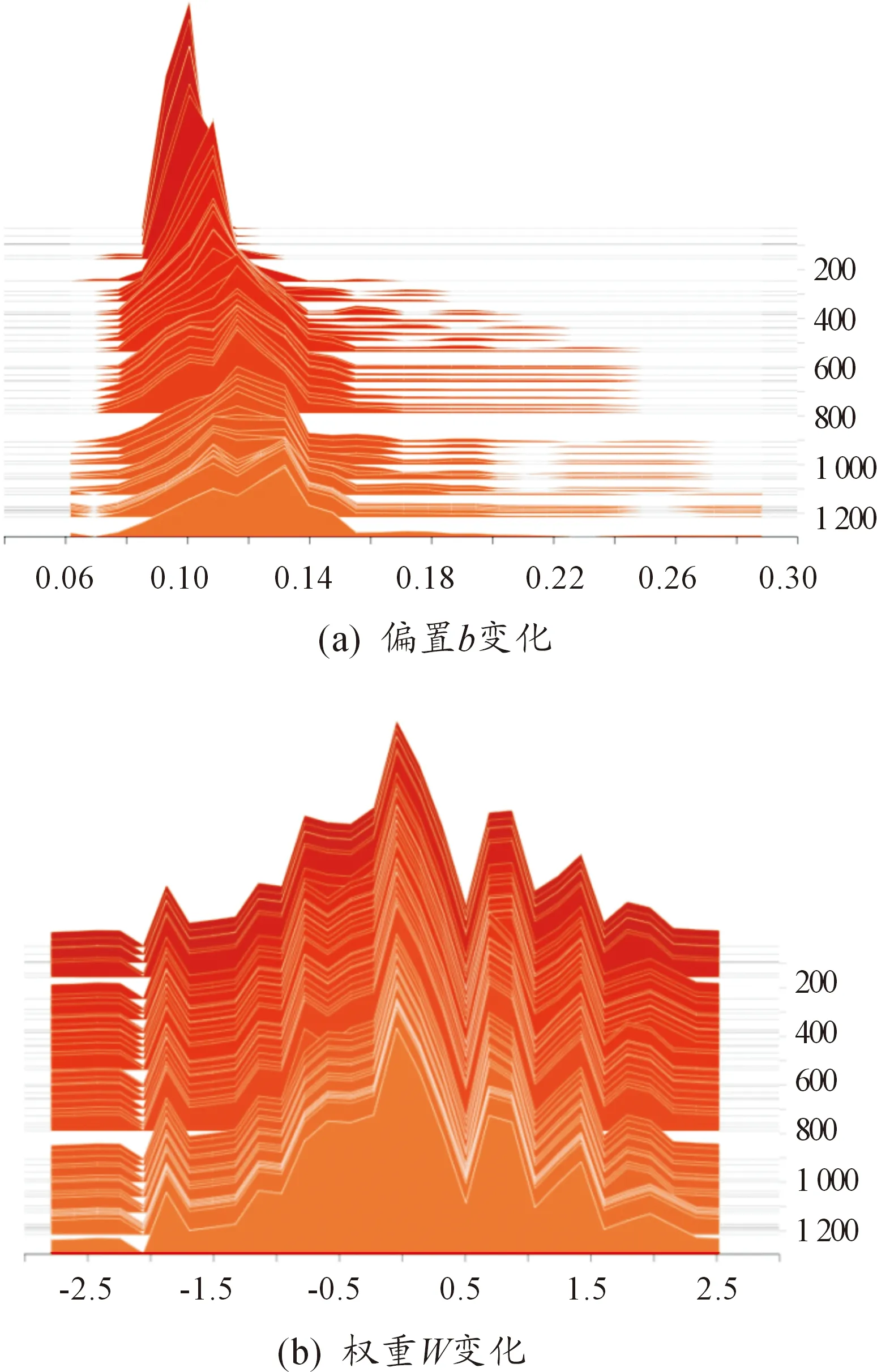
图4 训练过程中输入层偏置b、权重W的变化
利用训练得到的超参数模型即可进行外推,部分道路垂向加速度10倍外推结果如图5所示。
2.3 基于LSTM的外推前后载荷谱对比
将LSTM方法外推数据与原始数据频谱曲线进行对比,部分道路频谱曲线如图6所示。
在频谱图上,外推前后数据频谱在总的形态上有很好的一致性,利用Pearson相关系数法对一致性进行检验。Pearson相关系数ρX,Y衡量数组X和Y线性关联性的程度,系数的取值总是在-1.0~1.0范围,接近0的变量被成为无相关性,接近1或者-1被称为具有强相关性。外推前后的频谱曲线,经Pearson相关系数法检验后的结果如表2所示。经LSTM方法外推前后数据的频谱曲线有强相关性,说明该方法能对原始数据的频谱特征有很高的学习率。

图5 部分道路垂向加速度10倍外推结果
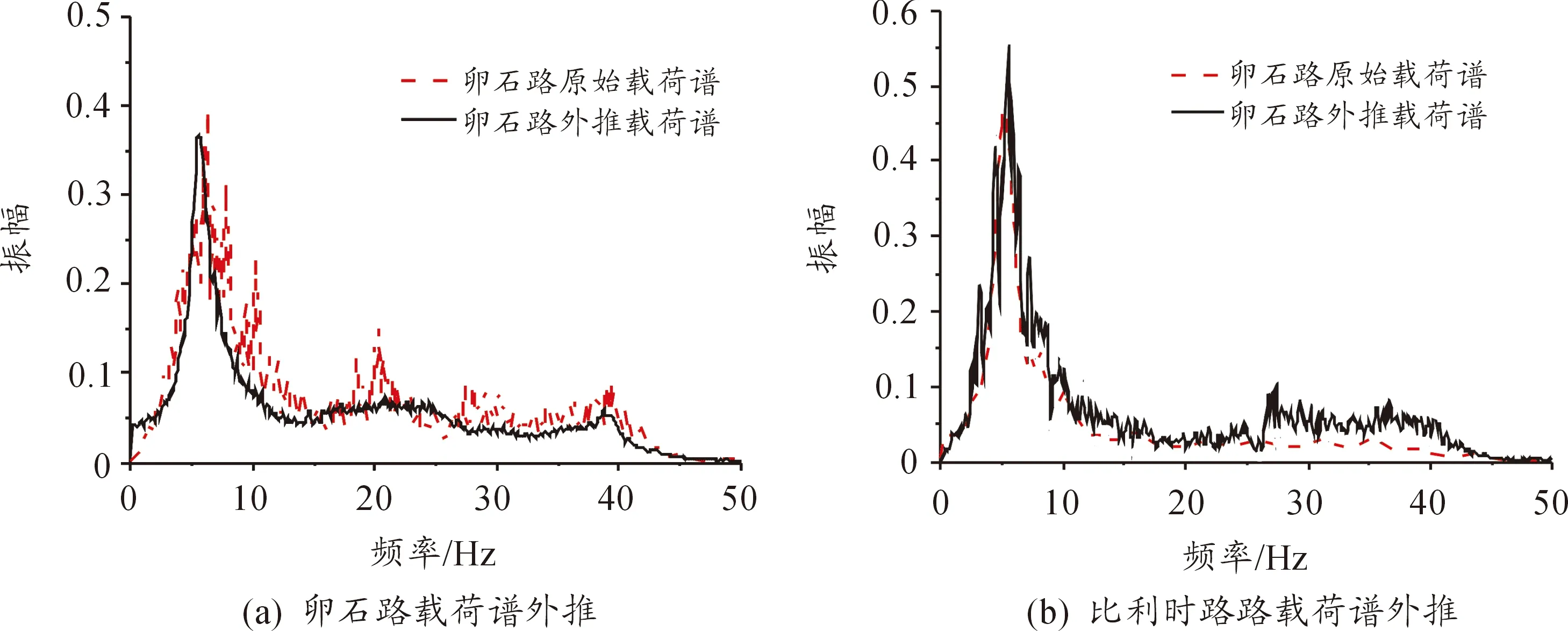
图6 LSTM方法外推后与原始数据频谱图对比
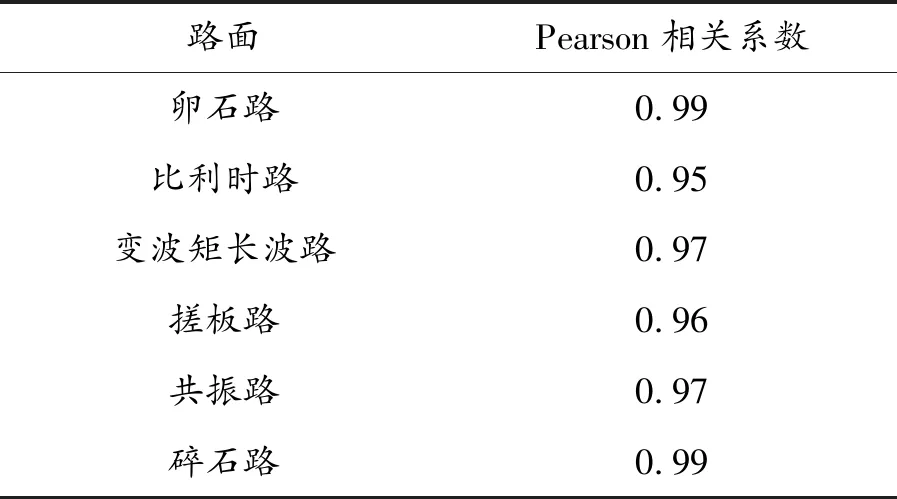
表2 外推前后数据频谱曲线的相关性
3 几种外推方法的对比
对载荷谱的外推,普遍采用的几种外推方法的特点见表3。
本文基于LSTM外推方法以及非参数核密度外推方法中分别采用expanechekov核函数、Circle核函数、均值核函数、幅值核函数对在卵石路上采集到的载荷谱进行外推,几种方法的雨流图对比见图7。

表3 几种外推方法对比

图7 卵石路载荷谱雨流图对比
从雨流图可以看出,非参数核密度外推法的分布趋于“单核”特征,LSTM方法外推分布具有“多核”特征,后者的分布情况及对各向的疏远点的复现效果更好,在实际工程运用中可选择LSTM方法进行外推。
4 结束语
本文尝试利用LSTM方法对汽车载荷谱进行外推。LSTM外推方法引入人为因素较少,外推数据平稳,且可直接表示为时域数据,便于转化为台架试验或加速寿命试验的输入。对一段载荷谱采用LSTM方法进行外推,并对外推前后的雨流图进行对比,结果表明:通过LSTM外推后的载荷谱能较好地复现原始雨流图分布特征,该方法有很大的工程应用潜力,同时也展现了机器学习在工程研发领域的应用前景。
LSTM外推方法虽比较“智能”,但机器学习生成的模型不直观,对原数据特征依赖度较大,所以对原数据的选择与处理要求更高。未来有如下研究方向:① 进一步探讨更多种特征的原始载荷谱数据在外推前后的差异,建立载荷谱数据集;② 尝试在台架试验中进行外推时域谱测试,并安排实车道路耐久测试,将真实部件损伤情况与仿真情况进行对比。
猜你喜欢
中国新通信(2023年3期)2023-06-24 03:00:06
空间科学学报(2021年6期)2021-03-09 06:20:14
测控技术(2018年7期)2018-12-09 08:58:22
人民黄河(2018年8期)2018-09-10 16:05:55
数字通信世界(2018年7期)2018-08-03 02:06:02
大学物理实验(2016年2期)2016-06-20 06:17:30
无线电通信技术(2015年3期)2015-12-23 11:37:00
科技视界(2015年16期)2015-02-27 10:18:12
化学教学(2014年4期)2014-06-17 23:45:55
电子设计工程(2014年19期)2014-02-27 12:00:41
