
机器学习模块在研究中国老年人摔倒因素中的应用
2019-09-17 08:28马若炎刘子桦
电子技术与软件工程 2019年16期
文/马若炎 刘子桦
1 数据搜集和来源
本数据来源于Özdemir, AhmetTuran, Billur Barsha三位瑞士研究人员所公布的针对于中国老年人所做的相关摔倒实验的具体数据。
2 数据集数据呈现
2.1 基本数据描述
本数据集包含16832条数据,七个变量值,分别为:ACTIVITY(摔倒次数)、TIME(测试者测试时间)、SL(血糖值)、EEG(EEG检测时间)、BP(血压值)、HR(心跳频率)、CIRCULATION(血液循环速率)。
2.2 原始数据处理和去噪
因变量处理:针对于数据集ACTIVITY和TIME列,在实验中不同的测试者检测时间是不同的,而为了保证因变量值数的统一性,我们运用如下的计算公式进行数据统一:
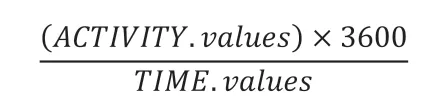
进而进一步得到不同用户在每一小时内摔倒的次数,同时生成新的因变量值列ADJUST_FALL并取代ACTIVITY和TIME值列。
数据去噪:由于python进行机器学习时是无法识别num值(空值),所以需要再通过fal_data=fal_data.dropna(axis=0)方法去噪。
3 因变量与自变量相关性分析
3.1 定性相关性分析
通过依次画出HR、SL、BP、CIRCULATION、EEG五个变量对于因变量ADJUST_FALL的残差图,我们发现HR、SL、BP、CIRULATION四个变量均与ADJUST_FALL呈现出反比例函数的趋势,同时从形态上初步可以看出他们之间的关系可能符合如下式:
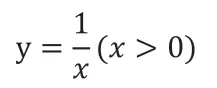
EEG变量从形态上来看可能与因变量ADJUST_FALL之间存在正比例函数关系,同时更有可能是值数函数关系,如下所示:
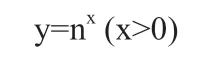
由于明显存在的正、反比例关系,可以进一步进行图形上的线性拟合尝试,实现方法是运用seaborn库的sns.pairplot(x=,y=,kind=re g,respect=0.8)命令行,生成相应的拟合直线,但是从图中来看单纯的线性回归很可能并不能做到较佳的拟合,相比而言取过对数后的变量可能更适合进行线性回归。
3.2 定量相关性分析
定性的分析之后,虽然数据可能存在强相关性,但仍需要通过相关性数值的计算才能够下定论,数值计算采用的是简单相关系数,在程序中,需调用的是cor_box = fall_data.corr()方法,生成简单相关系数表。
根据一般情况:简单相关系数0~0.3呈弱相关、0.3~0.6呈中等程度相关、0.6~1呈强相关,由以上数据可知,SL、HR、CIRCULATION与因变量ADJUST_FALL呈现强相关性,BP则与之呈现弱相关性,而EEG相关性极弱则可以考虑剔除。
不过从散点图来看,数据间可能存在反比例关系的可能性,所以可以尝试将取对数后再进行变量拟合。
经处理后,所有自变量调整过后于调整过后的因变量的简单相关系数都有了比较大的提高,除了BP之外其他所有的自变量已经达到了强相关水平,说明取对数后的自变量和取对数后的因变量有着极强的线性关系,后期的多元线性回归可以按照取对数后的数据进行。
4 运用sklearn训练模块进行的多元线性回归
4.1 sklearn机器学习模块简介
sklearn对一些常用的机器学习方法进行了封装,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。
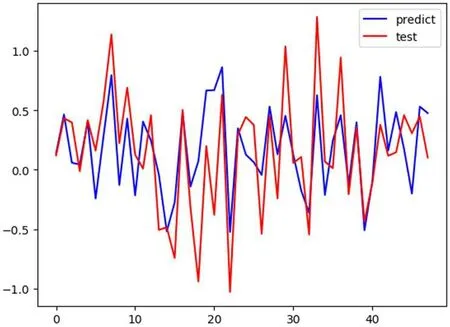
图1:预测集和测试集曲线图
机器学习任务通常包括分类(Classification)和回归(Regression),常用的分类器包括SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN。
4.2 运用sklearn机器学习方法进行线性回归的基本步骤
第一步:调用sklearn的LinearRegression()函数进行多元线性回归,同时运用fit函数进行训练,输出a(截距)、b(系数)。
第二步:输出测试集所针对的score值针对的测试集,并将score值赋值给y_predict。
第三步:不断调整训练集的参数设置,使得最终的参数达到一个合理的值数。最终调整过后的train_size为11000。
4.2.1 预测方程的推导
最终得出的预测方程是取对数后的方程,我们还需要将其进行还原得到的自变量和因变量真正意义上的拟合方程:推到公式如下:
(1)得到的原始方程为:y'=k1x1'+k2x2'+k3x3'+k4x4'+b(y'、x1'、x2'、x3'、x4'分别为取过对数的自变量和因变量)
(2)两边同时还原得到:
(3)带入线性拟合后的相关参数k1=-0.579, k2=0.0316, k3=-0.632, k4=0.679, b=4.270得到最终的回归方程为:
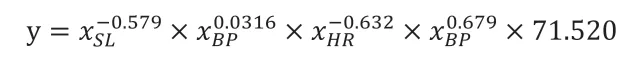
4.2.2 预测方程的检验
采用的是运用ROC二分类曲线检验的方式进行拟合函数诊断检验,终的预测模型已经能够达到较好的反应真实值的水平。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
中国药房(2022年7期)2022-04-14
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
语数外学习·初中版(2020年3期)2020-09-10
——与非适应性回归分析的比较
四川精神卫生(2019年2期)2019-06-18
文理导航(2017年20期)2017-07-10
遵义医科大学学报(2013年2期)2013-01-23
