
基于支持向量机的网络评论情感分析方法
2019-09-17 08:27程正双王亮
电子技术与软件工程 2019年16期
文/程正双 王亮
随着互联网及信息技术的快速发展,网络成为人们现在获取信息的主要途径,并且由以前纸质版的单方面获取信息变成可以对获取的信息进行在线讨论和评价。这种转变虽然能够看到及时的反馈但也形成了大量虚假信息,使不知来龙去脉的网民误信谣言及导向,因此网络舆情监控变得越发重要。通过对网络上信息监控和分析,可以对网络上的情感走向进行信息排查。但对于如此庞大的信息,仅依靠人为挖掘监控是远远不够的,因此利用当前的信息技术如数据挖掘、大数据分析、机器学习和人工智能等对网络上信息进行情感分析、给出定性的情感类别成为当前研究的热点之一。
从相关文献看,网络信息情感向分析可归类为主要的两类方法:第一种是基于情感词典的方法,第二种是基于机器学习的方法。第一种方法的基本思想是计算句子中表示情感的词语与词典中词语的相似度,然后得到词语的情感极性从而判断判断句子情感倾向,此方法的不足时对上下文及句子整体的语义理解不足。基于机器学习的方法一般将词语词向量表示,然后使用卷积神经网络或者递归神经网络等深度学习方法对其情感极性进行分类。由于神经网络的参数较多,在实际应用中还需要参数优化和防止过拟合。
本文利用支持向量机能够分类的特点,提出了一种基于支持向量机的网络信息情感分析方法。首先给出了利用python对网页信息进行获取的方式,然后对支持向量机的基本原理进行了概述,接下来给出了基于支持向量机的情感分析方法的流程,最后通过实验验证了此方法的有效性。
1 信息获取及表示
1.1 信息获取
分析网站的结构,利用python对网页信息进行爬虫,获取我们想要的评论作为数据。获取的数据中因含有大量冗余和无意义的数据,如繁体字、间隔、符号等利用规则有效剔除脏数据,清洗数据不仅为训练提供有效的数据而且减少无效参数提高准确率。对于清除后的数据利用分词工具进行分词操作,精确的分词模式不仅可以根据词性分词而且可以提取关键字、自定义字典和去除停用词等,为下一步模型训练进行准备。流程如图1所示。
1.2 信息表示
在自然语言处理中,词向量就是将自然语言数值化。以one-hot词向量为例,one-hot词向量在所有状态中计算出概率最高的状态为1,其余为0。因此在one-hot词向量中,只会有其中一个分量只是1,其余全为设置为0。one-hot词向量易造成数据稀疏的缺点, Word2ver是机器学习中训练分布式词向量的一种方法。在特征提取时利用Word2vec可以将一个句子中的每个词组映射到一个空间中,从而使每条语句都对应一个同等维度的词向量矩阵,这个矩阵类似于图像的矩阵形式。在本文中用word2ver训练语料,得到词向量后进行切词和去停用词处理,获取词向量集合。在遍历词向量集合会有一些使用率很低的词汇,在训练词向量时词频低于5的词汇都不会被训练,从而移除没有词向量的词汇。
2 基于支持向量机的的情感分析
支持向量机SVM是一种有监督的机器学习模型。SVM分类器既是分类模型,也可以看作线性回归模型。支持向量从训练数据中创建一个函数,训练数据通常由双输入对象和期望输出组成,从而学习出的函数可以用以预测新对象的输出。SVM通常用于分类,其中函数输出有限类中的一个。支持向量机还用于回归和偏向学习,它们分别被称为支持向量回归(SVR)和排序支持向量机(SVM)。支持向量机(SVM)最初分为两类,常用于两种情况:线性可分和线性不可分。在实际应用中,所获得的训练样本往往会受到噪声和离群点样本的污染。支持向量机得到的分类超平面由支持向量确定。噪声的存在增加了标准SVM训练的低效性,使得决策边界不可能从最优超平面上得到。在机器学习中,有许多改进分类的技术。因此,为了改进分类问题,人们提出了许多方法,通过识别样本的不确定性,如噪声样本和离群点样本,来丢弃或删除这些样本。同时,针对支持向量机分类方法中存在的噪声和离群样本,给出了改进分类方法的一些解决方案。另一方面,对于SVM分类器的样本约简,提出了许多识别决策边界的方法。在数据集存在噪声的情况下,已有的分类方法不能有效地识别边界样本,从而降低了SVM分类器的计算量。
机器学习的框架是要从训练集中提取特征,结合一定的算法(如:SVM)得到分类结果。其SVM中涉及的超平面是到一侧最近点的距离等于到另一侧最近点的距离,同样超平面分为线性可区分和线性不可区分。训练SVM对仿真参数空间中两个不同点的自旋构型数据集的元素进行分类。如果训练数据位于一个相变的不同侧面,那么训练后的SVM将自旋构型标记为中间到训练集的能力可能用于研究相变,例如确定模型参数空间中的相变点。为了说明SVM的概念,考虑一个最简单的例子:n维空间Rn中的点x,其中有一组这样的点,它们可以被超平面分成两组(通常用y=±1标记)。在垂直距离上与超平面最接近的点是支撑向量。
w • x - b = 0.
支持向量机的训练包括找到使|K|最小的w和b训练集中所有点i服yi(w • xi- b)≥1。利用该最小化问题的解,定义任意点x的决策函数为:d(x) = w • x - b.然后d(x)的符号为这两组中的任意一组指定一个点。
在我们实际应用中,完全线性的数据分离是几乎不可能达到的。可以对所谓的对偶公式进行推广,这也允许加入非线性特性。这里省略了细节,我们只引用将在后续分析中使用的决策函数的最终形式:

图1:信息获取流程
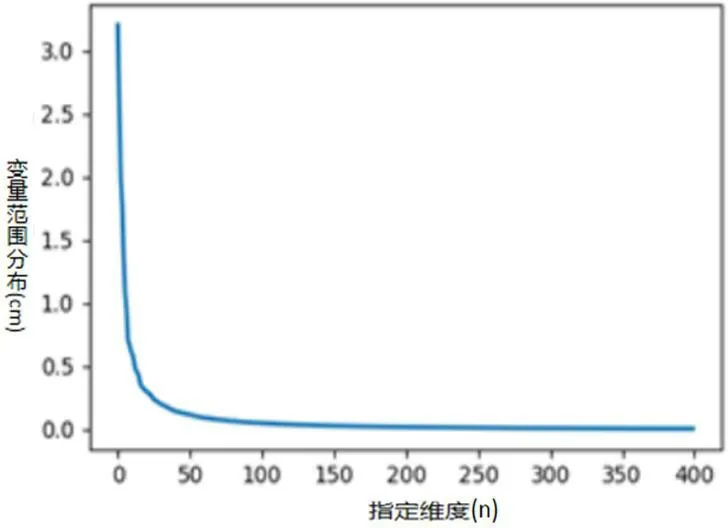
图2:降维维数曲线
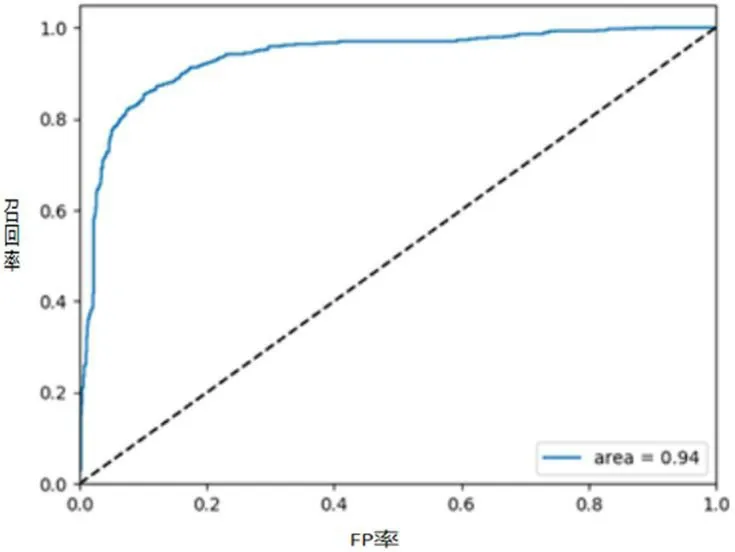
图3:ROC曲线
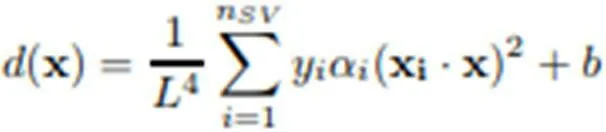
将训练中得到的支持向量标记出来。本文主要分为正面、负面和中性三类,利用SVM分类作为情感分类器的算法。对带有标签的训练集和验证集进行分类训练。SVM主要针对样本数据进行训练学习、分类和分析预测,由于SVM要求被计算机识别的因而数据都被处理为实数,因此对于属性值为类别的属性要进行转换。例如:{赞,差,一般},可以转换成3个属性,赞(1, 0, 0)、差(0, 1, 0)和一般(0, 0, 1)等。SVM有较为严格的统计学习理论,具有很好的推广能力。这可以抓住关键样本和删除大量冗余样本。
3 实验及结果分析
在本次实验中首先对评测进行数据处理,将从网页中爬虫下来是数据提取到文本中,然后将文本通过结巴工具进行分词和词性标注,最后将结果保存到另外一个文本中。在这里为了能够简化,采用中文分词的精确模式,试图将句子最精确地切开,比较适合文本分析。最后全部以行读入数据,相当于每行就是一个独立的句子。为了降低对内存的消耗,这里我们使用iter迭代,告诉Word2Vec输入的数据是可迭代的对象,使用生成器会大大降低内存消耗,所以这里我们返回的是生成器而不是列表(近似将生成器等同于列表)。处理后将数据样本分为训练集、验证集和测试集,训练集用来训练模型。验证集用来验证通过模型得到的情感是否正确,及时反馈给模型,并优化模型。测试集便用来测试模型。将词向量所得到的高维数据再用word2vec中的方法将相近的词进行汇聚,再对情感字典降维和扩充等操作,最终作为输入数据用于SVM分类。
3.1 部分实现代码
代码如下:

3.2 实验结果分析
实验结果中,首先对数据预处理时对数据分布式向量化Word2vec。在高维向量空间中对稀疏数据集的探索也变得更加困难。是因为得出高维度词向量,随着维数的增加,数据的稀疏性会越来越高。主成分分析PCA (PCA),也称为Karl-Hunin-Lough变换,是一种研究高维数据结构的技术。PCA可以将潜在相关的高维变量合成为线性变量所以要进行降维。本文采用PCA算法对结果进行降维,Word2vec模型设定了400的维度进行训练,得到的词向量为400维。运行代码,根据结果图发现,包含原始数据的绝大部分内容是在前100维,因此模型的输入选择前100维。维数曲线如图2。
当数据都准备好后用机器学习SVM训练,训练之后模型用于预测句子是正面评论、负面评论或者是中性评论,对于模型是否有效及效果的好坏,可以通过验证模型计算测试集的预测精度,并用ROC曲线来验证分类器的有效性。运行代码,得到Test Accuracy: 0.886,即本次实验测试集的预测准确率为88.6%,ROC曲线如图3所示。
4 结语
本文提出基于机器学习的情感分类方法,利用网络爬虫作为舆情分析数据获取的通道,获取数据后利用Word2vec工具和情感词性标签建立,并在此基础上结合否定词和副词等来确定情感倾向值。在训练时,选出其中部分表达积极情感的文本和其中小部分表达消极情感的文本,或者还包括一部分表达中性情感的文本,用SVM方法进行训练,获得一个情感分类器。在未来,我们不仅要努力提高数据在情感分类的有效性,而且还要研究不确定性的其他方面,并将该方法扩展到多类分类问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学物理学报(2019年1期)2019-03-21
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
