
基于Xgboost和LightGBM算法预测住房月租金的应用分析
2019-09-13 06:34季孟忠黄益槐
计算机应用与软件 2019年9期
谢 勇 项 薇 季孟忠 彭 俊 黄益槐
(宁波大学机械工程与力学学院 浙江 宁波 315211)
0 引 言
在我国,租房是居民获取住房的主要方式之一。据《中国流动人口发展报告2017》显示,全国流动人口总规模为2.45亿人,流动人口在流入地的家庭规模为2.67人。另外根据中国指数研究院重点城市租金水平估算2017年全国户均年租金为2.0万元,据此测算流动人口带来的住房租赁市场规模每年达1.2万亿元。住房租赁市场将在我国社会经济的发展中扮演重要角色,住房租金问题也一直是研究人员关注的焦点。现有研究文献主要集中关注住房租赁制度和租金影响因素。在住房租赁制度的相关研究中,刘洪玉[1]提出目前租房租赁行为不规范、市场化机构出租缺位影响了住房租赁市场的健康发展。施继元等[2]认为住房租赁市场应该致力于服务中低收入人群。黄燕芬[3]建议以“租购同权”作为突破口,推进“租售并举”,促进住房租赁市场健康发展。租金影响因素分为宏观因素和微观因素。宏观因素进一步细分为住房租赁市场供需、住房租赁市场制度、国家经济发展态势以及国民经济收入水平四个方面,微观因素研究则主要基于特征价格理论(Hedonic Price Model)[4]。该理论认为价格是由商品所有特征带给人们的效用决定的,具体对住房租金来说,影响租赁价格分为地段、房屋结构以及社区环境三大类。文献[5-8]从政策、住房价格、居民收入水平等经济发展指标对租金的影响进行研究并提出相应的政策建议。文献[9-12]基于特征价格理论得出住房配套设施、装修情况等建筑特征是影响租金的关键。
综上所述,现有研究大都集中在住房租赁制度和租金影响因素,尚未有租金预测方面的研究。互联网和大数据的发展给住房租赁市场带来了很大的冲击,如今越来越多的人利用互联网进行租赁房屋,从某种程度上来说,互联网已经成为租房者和房东之间的桥梁。房屋租金通常由住房租赁市场供需等宏观因素以及位置地段等房屋商品特征因素综合决定,但是对于租房这个相对传统的行业来说,信息严重不对称一直存在。一方面,房东不了解租房的市场真实价格,只能忍痛空置高租金的房屋;另一方面,租客也找不到满足自己需求高性价比房屋,造成了租房资源的极大浪费。本文着眼于租房租赁市场的痛点,利用真实的租房市场数据,通过3种机器学习算法模型,建立住房月租金预测模型,在一定程度上给予租房者以及房东参考价值,同时挖掘出背后影响租金的关键因素。
1 相关方法
1.1 GBDT算法
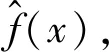
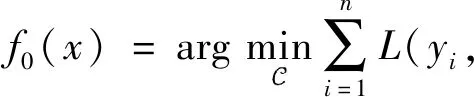
(1)

① 对i=1,2,…,n,计算残差rim,即在当前模型下的损失函数的负梯度值:
(2)
② 根据rim拟合一个回归树,得到第m颗数的叶结点区域mj,j=1,2,…,。j表示叶子节点个数。
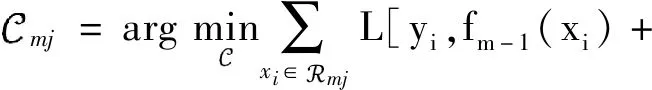
(3)
④ 更新回归树:其中I为指示函数,当回归树判定x∈mj时,其值为 1,否则为0。
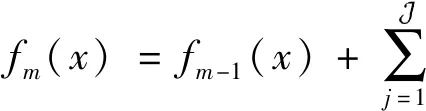
(4)
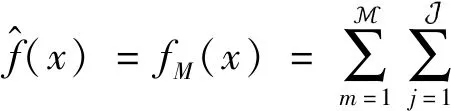
(5)
1.2 Xgboost算法
Xgboost是华盛顿大学陈天奇于2016年开发的Boosting库,兼具线性规模求解器和树学习算法[14]。它是GBDT算法上的改进,更加高效。传统的GBDT方法只利用了一阶的导数信息,Xgboost则是对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项,整体求最优解,用于权衡目标函数的下降和模型的复杂程度,避免过拟合,提高模型的求解效率,其步骤如下:
(1) 给定数据集D={(xi,yi):i=1,2,…,n,xi∈Rp,yi∈R},其中n为样本个数,每个样本有P个特征。假设我们给定k(k=1,2,…,K)个回归树,xi表示第i个数据点的特征向量,fk是一个回归树,F是回归树的集合空间,模型可表示为:
(6)
(2) 目标函数定义如下:
(7)
⋮
(8)
(4) 将式(8)的结果代入式(7)中,可得:
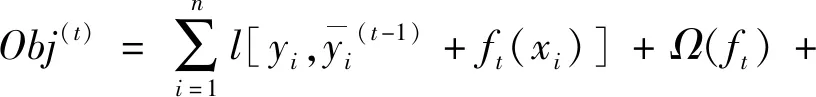
(9)
(5) 将目标函数做二阶泰勒展开,并且引入正则项:
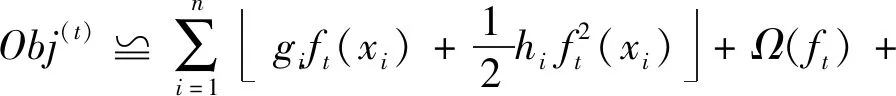
(10)
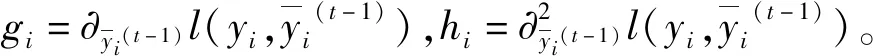
1.3 Lightgbm算法
LightGBM是微软2015年提出的新的boosting框架模型[15],该算法在传统的GBDT基础上引入了两个新技术:梯度单边采样技术和独立特征合并技术。梯度单边采样技术(Gradient-based One-Side Sampling,GOSS)可以剔除很大一部分梯度很小的数据,只使用剩余的数据来估计信息增益,从而避免低梯度长尾部分的影响。由于梯度大的数据对信息增益更加重要,所以GOSS技术在较传统GBDT少很多的数据前提下仍然可以取得相当准确的估计值。独立特征合并技术(Exclusive Feature Bundling,EFB)实现互斥特征的捆绑,以减少特征的数量。另外,传统GBDT算法中,最耗时的步骤是利用Pre-Sorted的方式在排好序的特征值上枚举所有可能的特征点,然后找到最优划分点,而LightGBM中使用histogram直方图算法替换了传统的Pre-Sorted以减少对内存的消耗。
1.4 住房租金预测建模分析流程
本文建模过程如图1所示,首先对住房租金数据进行预处理,包括异常数据的删除、缺失值数据的处理及数据集切分,然后使用python语言建立GBDT、Xgboost、LightGBM三种机器学习模型算法,采用网格搜索进行参数自动寻优。最后通过对比预测精度确定最优预测模型。
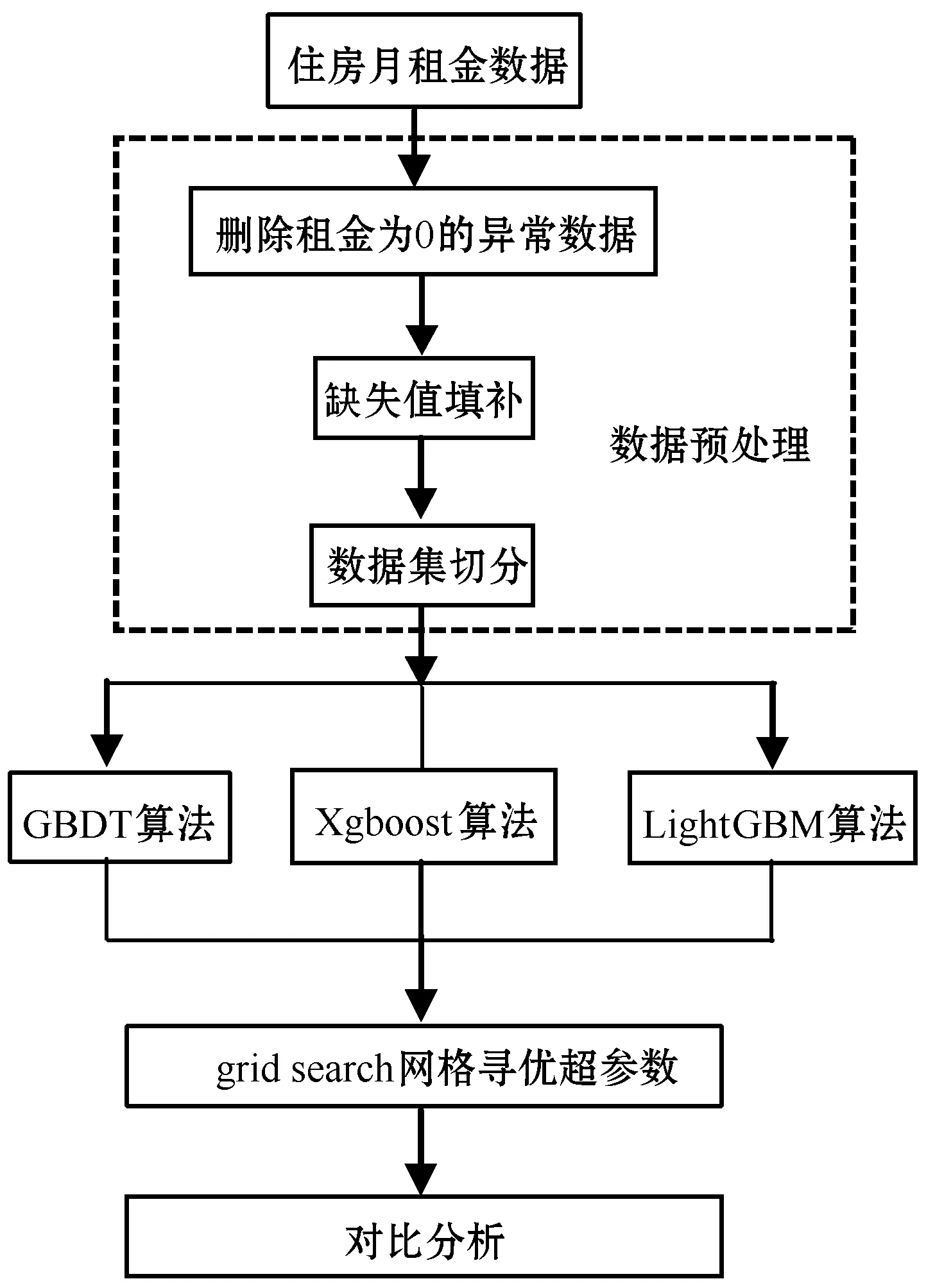
图1 建模过程
2 建模与实证分析
2.1 住房月租金数据描述及预处理
本文所采用的数据是由Data Castle住房月租金预测大数据竞赛数据集,总共196 539个样本。该数据集包括月租金以及房屋的基本信息,其中月租金为输出标签值,房屋基本信息提炼成M0特征(房屋信息采集的时间、房屋所在的区级行政单位、房屋所在楼层、房屋朝向方位、小区所在的商圈位置、房屋面积、房屋所在建筑的总楼层数、小区房屋出租数量、卧室数量、厅的数量、卫生间的数量)、M1特征(房屋装修档次、居住状态、出租方式)、M2特征(房屋附近的地铁线路、房屋附近的地铁站点、房屋距离地铁的距离)合计17个输入特征。为便于排版依次从A至Q给这些特征编号。统计分析得知,月租金分布如图2所示,租金变化范围主要集中在0至40之间,原数据集所含特征、特征编号和缺失值比例表1所示。

图2 月租金分布图
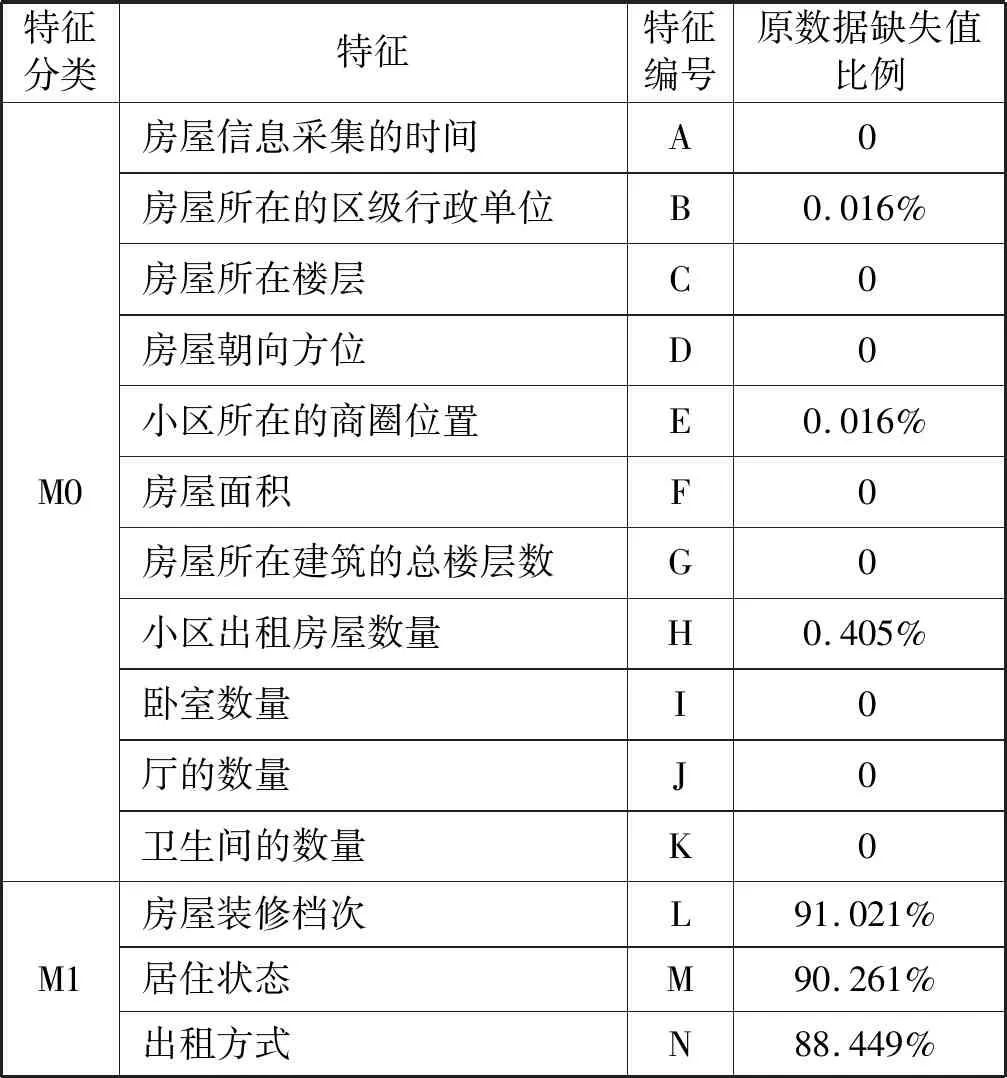
表1 数据集所含特征、特征编号及缺失值比例
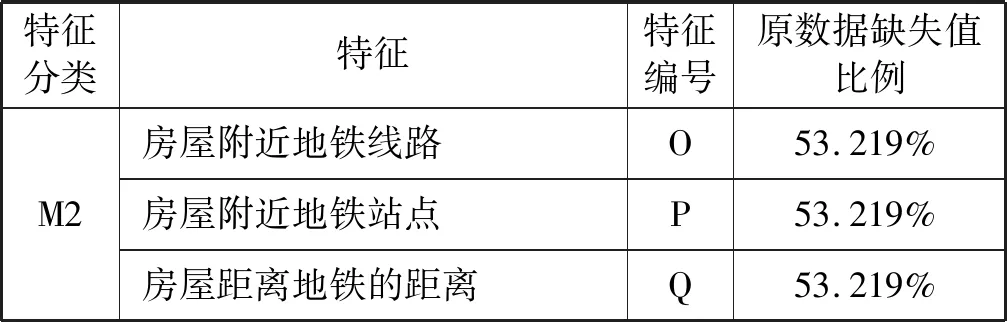
续表1
预测建模需要对数据进行异常数据剔除和缺失数据处理,在196 539个初始样本中,剔除月租金为0、距离为0及房屋面积为0的三个异常样本,剩余196 536个样本。缺失数据的处理按照缺失比例区别对待,对原数据缺失值较少的特征(区、位置、小区房屋出租数量)采用众数填充法,而原数据中M1特征(装修情况、居住状态、出租方式)缺失值达到90%左右,M2特征(距离、地铁线路、地铁站点)都是关于周边交通(地铁)的特征,缺失值均为53.219%,对于缺失超过50%的数据一般的方法是删除该特征。然而考虑到这些特征对于租金可能存在较大的影响,需要全面分析M1特征、M2特征对租金的影响。因此,把数据样本是否含有M1特征、M2特征作为切分依据,将原数据集切分成5个新的数据集:数据集①删除M1、M2特征;数据集②保留M1、M2特征都缺失的数据;数据集③保留M1特征缺失、M2特征不缺失的数据;数据集④保留M1不缺失、M2缺失的数据;数据集⑤保留M1、M2特征都不缺失的数据。这5个数据集纳入的特征分类如表2所示,√表示该数据集纳入该特征,×表示该数据集删除该特征和清洗后的各数据集的样本数。此外,为了评估模型的性能,对切分好的数据集分别随机选取90%的数据为训练集,10%的数据为验证集。
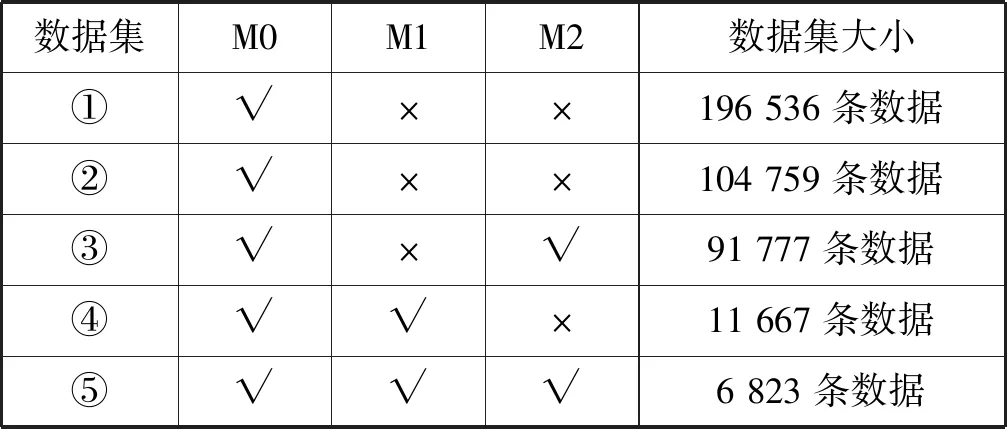
表2 数据集大小及所含特征
2.2 模型评价标准
实验采用均方根误差(Root Mean Square Error,RMSE)来度量预测模型的精确度,RMSE计算结果越小,预测越精准。其中N为样本个数,Xobs,i为第i个样本实际值,Xmodel,i为第i个样本预测值。
(11)
2.3 计算过程与结果分析
住房月租金预测计算采用PC配置3.10 GHz的Intel Pentium G2120处理器,4 GB内存64位Windows7操作系统,使用python3.5编程语言进行分析建模,建模过程中主要使用到的包和机器学习库有pandas、numpy、matplotlib、seaborn、sklearn、Xgboost和LightGBM。
使用GBDT、LightGBM 和Xgboost模型建模分析时,参数的选择对模型的预测结果有着较大的影响,故需要对若干参数进行调优。对于GBDT模型,本文主要对学习率、迭代次数、最大树的深度以及最大叶子节点数这4个主要参数进行调优;对于LightGBM模型,本文主要对学习率、迭代次数、叶节点数以及最大直方图树这4个主要参数进行调优; 对于Xgboost模型,本文主要对学习率、迭代次数、最大树的深度以及每个叶子节点样本权重和这4个主要参数进行调优。使用网格搜索对上述模型参数进行自动寻优,具体步骤如下:(1) 先确定学习率,把learning_rate设置成0.1,其他参数使用默认参数,使用GridSearchCV函数进行网格搜索确定合适的迭代次数;(2) 找到合适的迭代次数后使用GridSearchCV函数对模型的其他两个主要参数进行网格搜索自动寻优;(3) 减小(增大)学习率,同时增大(减小)迭代次数,找到合适的学习率是使得在误差最小时迭代次数最少。使用5折交叉验证的方法来选择参数,即每次将训练数据集分成5份,轮流将4份用于训练集训练剩下1份用于测试集测试,每次试验都会得到相应的分数(RMSE),最后将5次测试分数的均值当做最后的分数(RMSE)。在确定参数后,即可对验证集进行预测,预测结果见表3、表4、表5所示。对于LightGBM 和Xgboost使用模型plot_importance内置函数提取特征对于模型的重要度,GBDT使用模型内置函数feature_importances提取特征对于模型的重要度,每个模型的特征重要度百分比如表6、表7、表8所示。通过特征重要度可以识别影响租金的关键特征。
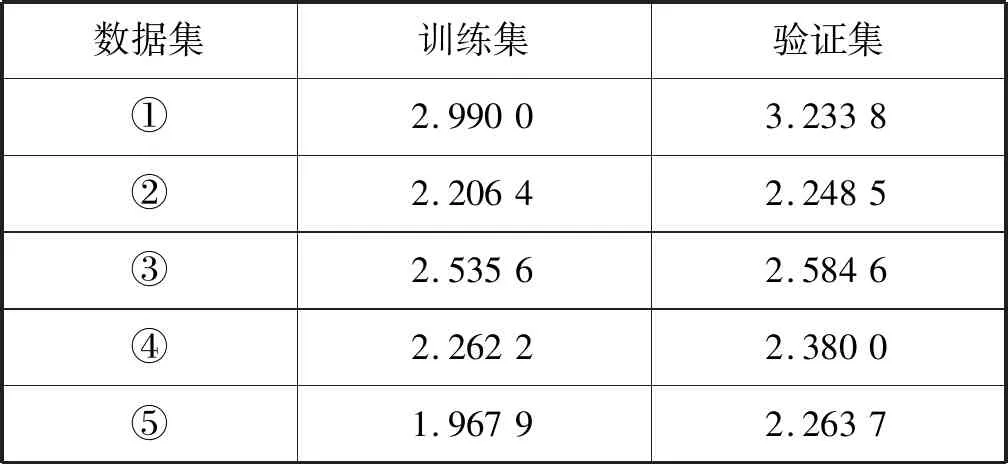
表3 GBDT模型预测精度(RMSE)
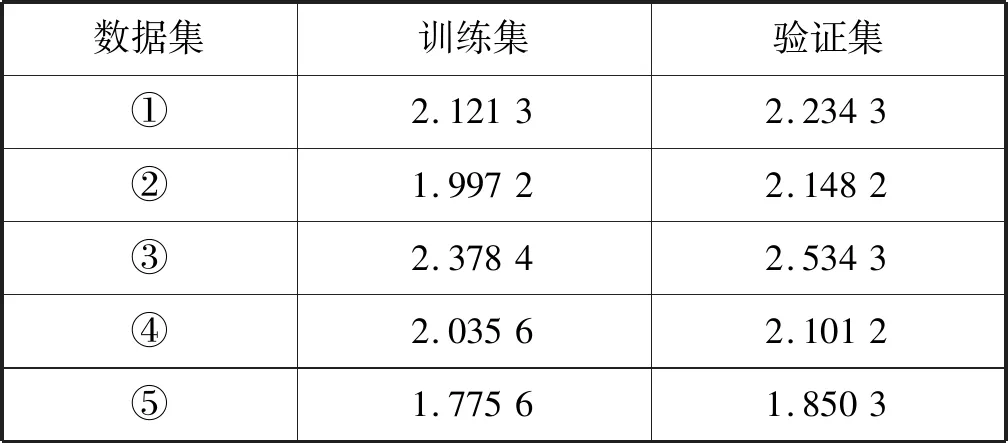
表4 Xgboost模型预测精度(RMSE)
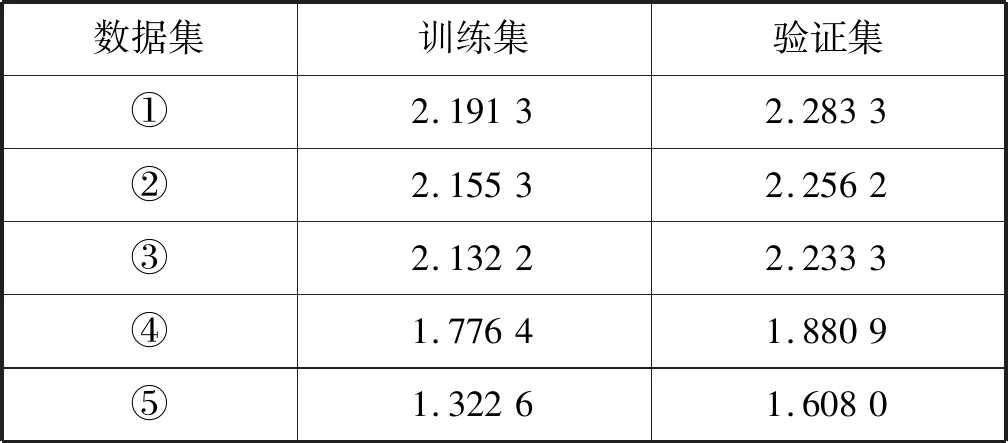
表5 LightGBM模型预测精度(RMSE)
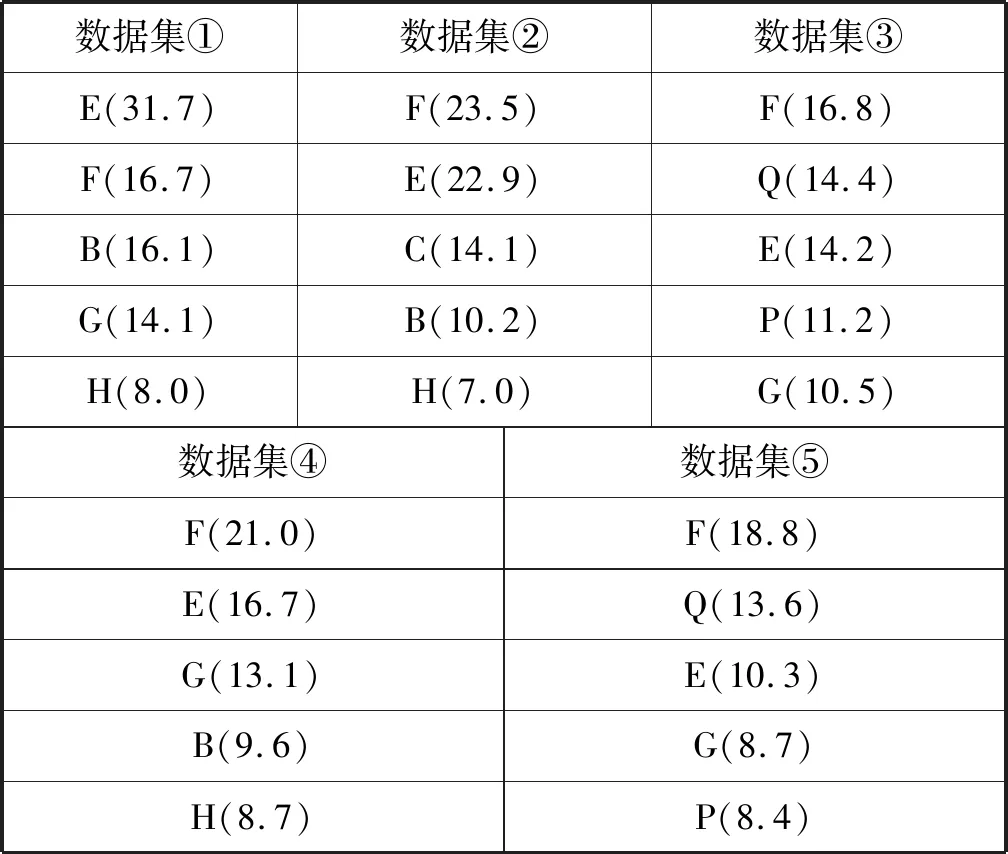
表6 GBDT模型特征排序 %
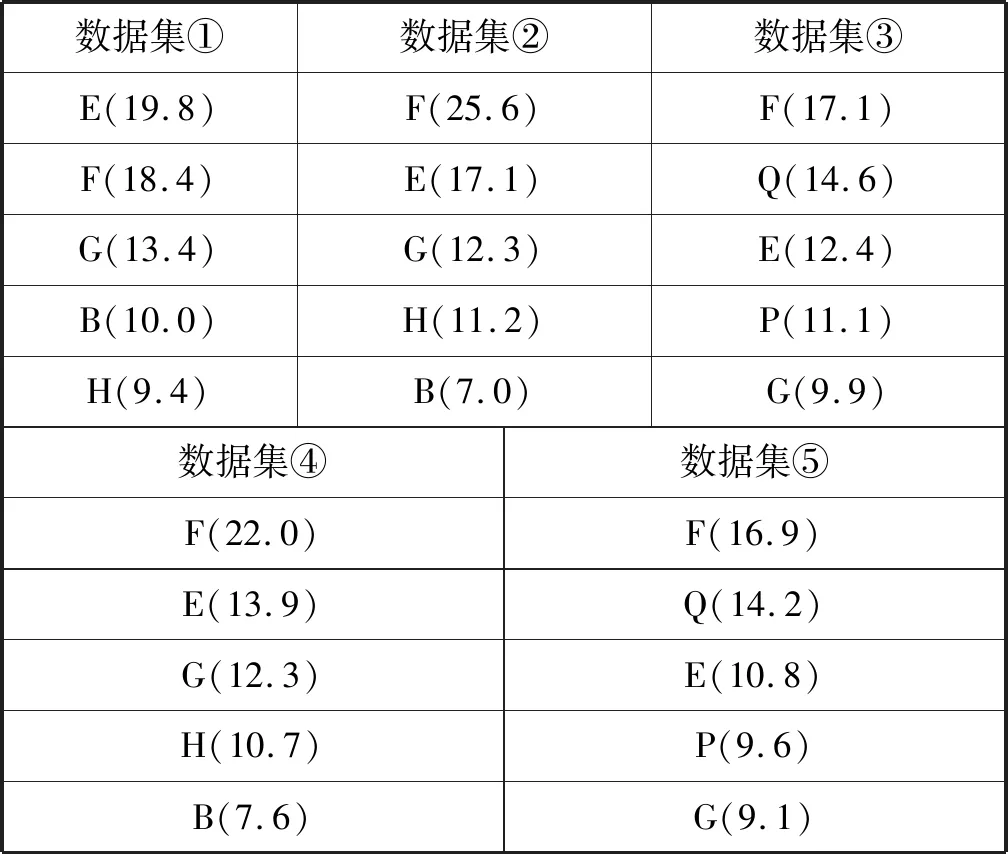
表7 Xgboost模型特征排序 %
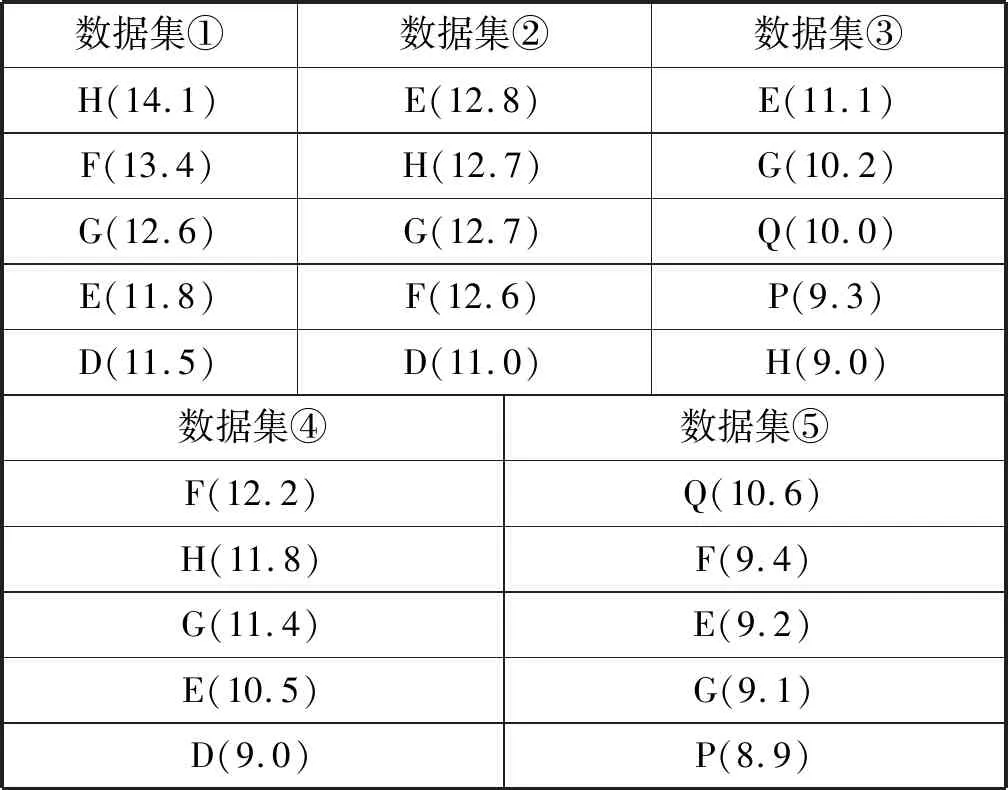
表8 LightGBM模型特征排序 %
根据表3、表4、表5综合考虑各数据集的预测结果可得出以下结论:LightGBM和Xgboost优于GBDT,而LightGBM和Xgboost互有优劣。LightGBM在数据集③、数据集④、数据集⑤上优于Xgboost。Xgboost在数据集①、数据集②上优于LightGBM。LightGBM精度最优可达1.608,Xgboost最优精度为1.850 3,GBDT最优精度仅为2.248 5。
从表6、表7、表8可以得出以下结论:
结合所有数据集的特征重要度排序,可以得出影响租金的关键因素是房屋面积(F)、小区所在商圈位置(E)、房屋距离地铁的距离(Q)、房屋所在建筑的总楼层数(G)、小区房屋出租数量(H)。房屋面积越大,租金越高是肯定的,小区所在商圈位置、房屋距离地铁的距离都代表了房屋附近的基础设施情况,这些本质上都属于地段因素。这反映了租房就是租地段的现象。而房屋所在建筑的总楼层数、小区房屋出租数量则需要进一步研究,可能是出租总量越多的小区通常居民成分复杂,会影响小区的舒适安全性。高层住宅通常配置电梯,年代较新,住宅状况较好,自然影响租金。
M1特征不是影响租金的关键因素,M2特征是影响租金关键因素;在含有M1特征(房屋装修档次、居住状态、出租方式)的数据集④和数据集⑤中,前5名都没出现该特征,说明M1特征不是关键因素。在含有M2特征(距离、地铁线路、地铁站点)的数据集③和数据集⑤中,房屋距离地铁的距离(Q)和房屋附近的地铁站点(P)均位于前列,说明关于地铁的M2特征是影响租金关键因素。
3 结 语
本文使用3种机器学习模型对住房月租金进行预测, Xgboost和LightGBM作为机器学习近年提出的新
方法,和传统GBDT相比较能达到较优的预测精度,Xgboost最低均方根误差可达到1.850 3,LightGBM最低均方根误差可达到1.608。同时,经过三个预测模型中特征重要度的排序,识别出影响租金最关键的特征是面积因素和地段因素。本文的不足之处在于Xgboost和LightGBM虽然能够得到较好的预测精度,但是由于Xgboost和LightGBM都是基于启发式算法,寻找的解为局部最优并非全局最优。另外,后续研究中也可以引入Filter、Wrapper等特征选择方法,以进一步提升预测精度。
猜你喜欢
社会科学战线(2022年7期)2022-08-26
消费电子(2022年4期)2022-07-18
汽车实用技术(2022年10期)2022-06-09
房地产导刊(2022年4期)2022-04-19
现代装饰(2020年12期)2021-01-18
作文周刊·小学一年级版(2021年40期)2021-01-04
文苑(2020年10期)2020-11-22
理财周刊(2020年8期)2020-08-09
金桥(2018年2期)2018-12-06
中国房地产·学术版(2018年2期)2018-03-14
