
“互联网+”环境下数据可信度量方法研究
2019-09-10 07:22李阿芳
河南科技 2019年26期
李阿芳







摘 要:大数据在生产活动中扮演着越来越重要的角色,不可信数据给大数据的应用带来了很大的麻烦,如何筛选出真实可信的数据成为大数据应用的重要课题。本文阐述了当前数据可信计算方法和模型,并分析其优缺点,提出了“互联网+”环境下的数据可信度量方法及其评价方法。该数据可信度量方法依据发布信息的主体、数据源以及数据自身的相关属性,计算数据的主观可信度、全局可信度以及本地可信度。试验结果表明,本方法在电子商务数据可信度计算方面有较好的效果。
关键词:互联网+;大数据;可信度计算
中图分类号:TP393.09 文献标识码:A 文章编号:1003-5168(2019)26-0017-04
Research on Data Credibility Measurement in "Internet +" Environment
LI Afang
(Shandong College of Information Technology,Weifang Shandong 261061)
Abstract: Big data plays an increasingly important role in production activities, and untrusted data has caused great trouble for big data applications. How to filter out authentic data becomes an important topic in big data applications. This paper expounded the current data trustworthy computing methods and models, and analyzed its advantages and disadvantages, and proposed a data credibility measurement method and its evaluation method under the "Internet +" environment. The data trusted metric method calculates the subjective credibility, global credibility and local credibility of the data according to the main body of the published information, the data source and the related attributes of the data itself. The test results show that the method has a good effect on the reliability calculation of e-commerce data.
Keywords: Internet +;big data;data credibility measurement
新时代,大数据呈现出规模大、流转快、类型多等特点,在数据生成和传播过程中不可避免地产生数据不一致、数据缺失等问题,导致大数据的可信度受到质疑[1],低可信度[2]的数据对大数据应用造成了很大的麻烦。
针对上述问题,本文提出了“互联网+”[3]环境下基于大数据处理技术的可信度量方法[4]。该方法依据发布信息的主体、数据源以及数据自身的相关属性,计算数据的主观可信度、全局可信度以及本地可信度,具体来说,通过用户与数据源之间的交互记录计算主观可信度,通过数据源发布或者产生数据的交互记录计算全局可信度,通过历史数据来计算本地可信度。试验结果表明,本方法在电子商务数据可信度计算方面有较好的效果。
1 数据可信度计算方法
1.1 数据可信度
在数据源可信度计算模型中,可信度包括直接和间接可信度两部分[5],根据实际情况,人们可以对两者分别进行加权,得到两实体之间的可信度。假设直接可信度为[DR],间接可信度为[IDR],则两实体之间的可信度为[wDR+1-wIDR],其中[w]表示权重,且满足[w∈[0,1]]。权重的大小取决于两实体之间交互记录的多少,如果交互记录多,则[w]值越大,否则[w]值越小。如果两实体之间没有直接交互记录,需要引入第三实体,且第三实体与前两个实体之间都需要有交互记录,如图1所示。
图1中,A和B之间、B和C之间都有交互记录,因此可以计算出两者的直接信任度,而A和C之间没有交互记录,因此只能通过B来计算A和C的间接信任度。
1.2 可信度计算模型
“互联网+”环境下,数据可信度主要包括动态和静态两种计算模型[6],基本可以划分为基于交易反馈的可信模型、基于关系的可信模型和基于兴趣的可信模型。
上述三种模型并非相互独立,每种模型各有优点和缺点,在计算可信度过程中,人们经常需要运用多个模型共同计算。从上面三种模型可以看出,影响数据可信度的因素主要有三个,即主体本身、数据源和数据,因此在“互联网+”环境下计算数据的可信度需要从上述三个方面入手。
2 大数据可信度量方法
2.1 大数据可信计算模型
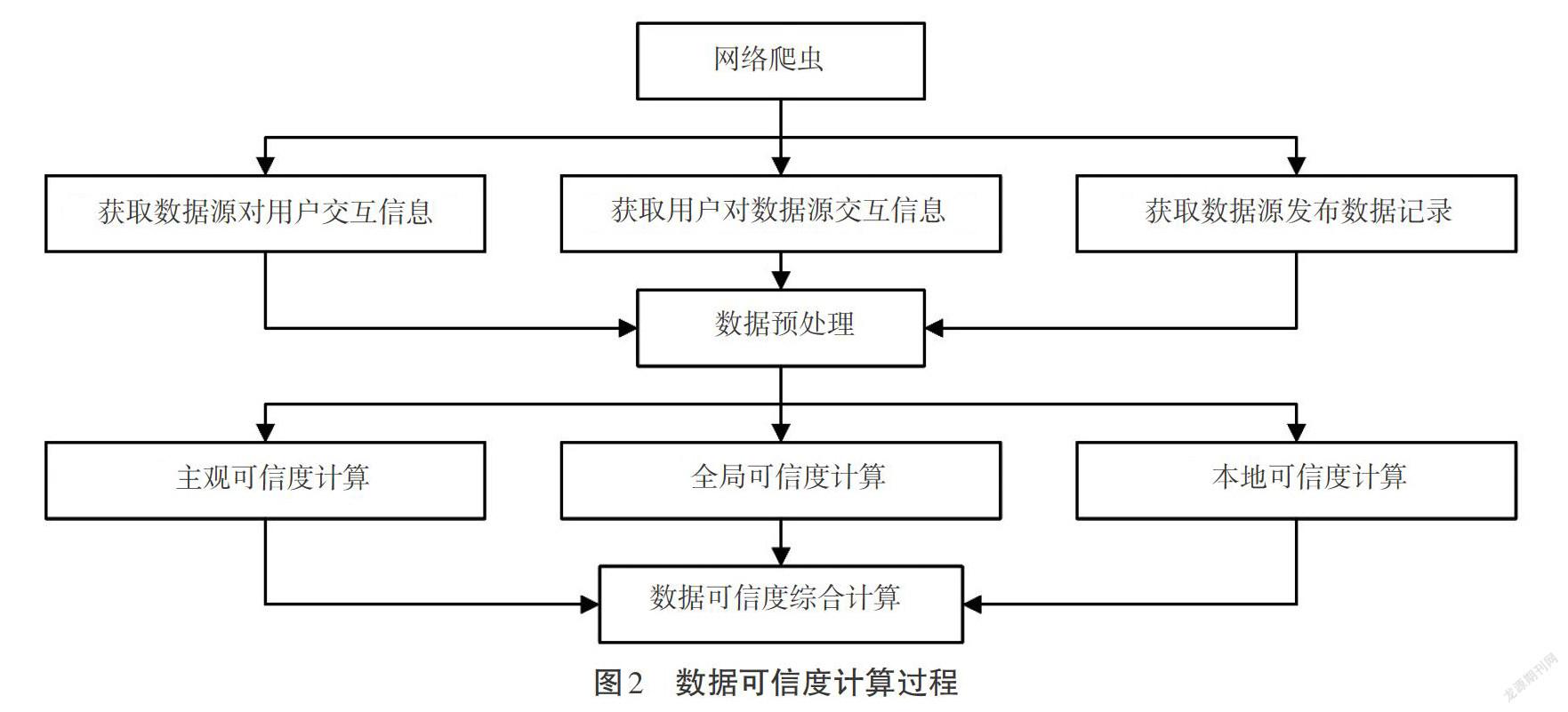
大数据环境下有各种数据源和用户,为了方便计算,人们需要将数据源和用户分别抽象为节点,数据源和用户之间的互动就可以抽象出5个交互数据,即用户、数据源、时间、结果以及数据内容,分别用符号User、DS、time、Res和Data表示,結果表示用户对该次交互的是否认可。在大数据可信计算模型中,首先通过网络爬虫获取用户和数据源的交互记录,并对这些交互记录进行预处理,删除重复和无效的数据,然后对每条记录提取交互五元组[T](User,DS,time,Res,Data),之后对五元组进行可信度的计算,具体计算流程如图2所示。
在数据可信度计算过程中,用户对数据源之间的交互记录主要包括用户对数据源发布的信息的评论,主要用于计算数据源的全局可信度,也就是说,通过分析全体用户对该数据源的评价,获得关于该数据源的客观评价。主观可信度表示单个用户对数据源发布消息的信任度,与全局信任度不同,主观可信度表示个人对数据源的信任程度。本地可信度是基于数据源本身特点计算的信任度,如数据源的所有者、数据源取得的认证信息、满足的标准等。
数据可信度综合计算就是针对主观可信度、全局可信度以及本地可信度,采用加法原则,根据数据可信度的侧重点加以权重。假设用户User在t时刻对数据源DS的主观可信度为[STUser,DS,t],数据源DS在t时刻的全局可信度为[GTDS,t],数据源DS的本地可信度为[LTDS],则此时数据源发布的数据D的可信度可用如式(1)计算:
[TUser,DS,D,t=αSTUser,DS,t+βGTDS,t+λLTDS] (1)
式中,[α],[β],[λ]分别为三种信任度的权重系数,且[α+β+λ=1]。在对待不同的数据类型时,可以动态调整系数的大小。
2.2 主观可信度计算
主观可信度从本质上来说是一种直接可信度,是通过用户和数据源之间的交互历史记录来计算的。假设用户与数据源的交互记录为[T],[T=T1,T2,…,Tn],其中[Ti=(Di,Si,ti)],三者分别表示交互信息的内容、交互信息是否成功、交互时间。一般来说,人们倾向于相信能够持续提供准确信息的数据源,因此交互记录中成功交互可以作为计算主观可信度的依据。在数据预处理过程中,依据是否可信,人们需要将交互记录划分为可信子序列[CTS=ts1,ts2,…,tsp]和不可信子序列[CFS=fs1,fs2,…,fsp]。
在主观可信度计算过程中,本文采用直接可信计算的PeerTrust算法,以记录开始时间t为准,距离t越长的交互,即最新的交互的可信程度越高,交互次数越多,交互的可信程度越高,因此可信交互计算公式为:
[CTrustUser,DS,t=i=1peti-t×count(tsi)/n] (2)
式中,[ti]为交互序列[tsi]发生的时间;[count(tsi)]为交互序列[tsi]中交互的次数。
不可信交互计算公式为:
[CNTrustUser,DS,t=i=1ll2×count(tsi)2eti-t/n2] (3)
为了避免在交互过程中“网络水军”对正常交互过程的干扰,在计算可信交互和不可信交互的过程中,需要对交互的用户主体进行评分,评分以用户主体的个人信息完成程度为标准,如是否提供年龄、职业、通信方式等,以用户个人信息为空和提供了完整信息为准,将用户主体的信息完整程度归一到[0,1]的区间,即0<[w(User)]<1,因此用户User对数据源DS的主观可信度[STUser,DS,t]为:
[STUser,DS,t=λUserw(User)CTrustw(User)CTrust+(1-w(User))CNTrust] (4)
式中,[λUser]为用户节点的独立参数。
2.3 全局可信度计算
全局信任来自数据源与所有用户的交互记录,假设当前数据源与用户和其他数据源的交互记录为[T],[T=T1,T2,…,Tn],其中[Ti=(Vi,Di,Si,ti)],[Vi]表示数据源在网络中的标识,其他符号与主观可信度计算中的意义相同。由于全局可信度是由所有用户对该数据源的信任度决定的,一般来说,对该数据源的信任度特别高或者特别低的用户的评价通常有较强的主观性,因此需要弱化该部分用户的信任度在全局可信度计算中的比例。在t时刻,全局可信值用[GTrust(DS,t)]表示,则有
[GTrust(DS,t)=mi=1m1STUser,DS,t] (5)
2.4 本地可信度计算
本地可信度是指数据源自身的可信度,该值的大小取决于其所有发布信息的可信度,且消息的发布时间越新,其可信度在本地可信度中占比越大。假设数据源DS发布的历史记录为[D=Dt1,Dt2,…,Dtn],该序列按时间顺序排列,每条记录的格式为[Dti=dti1,dti2,…,dtim],[dtim]表示记录[Dti]的第[m]个主题,每个主题包括两个Title和Value两部分内容,因此本地可信度的计算公式如下:
[LTrust(Dn)=j-1n-1sim(Dn,Dj)×LTrust(Dj)j=1nsim(Da,Db)] (6)
式中,[sim(Dn,Dj)]函数表示记录[Dn]与[Dj]的相似度。相似度的计算公式为:
[sim(Da,Db)=i=1mdai×dbi(i=1md2ai)×(i=1md2bi)] (7)
式中,[m]表示在两个记录[Da]、[Db]中相同主题的个数。
3 試验仿真
本仿真试验的目的是检验方法的正确性,试验的数据集采用社会化电子商务网站Epinions.数据集,包含用户对项目的评分信息和用户之间的信任信息。为了方便计算,其间对数据集进行归一化处理,将数据集的信任值使用[TTmax]转化到[0,1]区间内,数据集的统计特征如表1所示。
计算过程中,用户和数据源可抽象为节点Entity,实体之间的交互记录记为Data,Data的记录中有多个主题,涉及数据源之间的参数如表2所示。
在试验过程中,首先根据大数据可信度计算方法计算出数据的可信值,然后通过实际的数据可信值与数据集中预先计算好的信任值进行比较。在计算过程中,根据式(1)、式(4)、式(5)和式(6)分别计算其信任值,并对比迭代次数为500和1 000的计算结果。本文采用传统的EigenTrust算法、PeerTrust算法与本算法的计算结果进行对比,并使用平均绝对误差MAE和均方根误差RMSE两种指标来衡量三种算法的性能,计算结果如表3所示。
从表3可以看出,随着迭代次數的增加,基于大数据的数据可信度计算方法在计算准确度上明显高于其他两种算法,本文提出的算法在MAE和RMSE两个指标上分别提升了13.1%和9.5%,明显高于其他两种算法。
4 结语
本文研究了大数据、社会学中的信任理论和各种可信度分析模型,然后提出了“互联网+”环境下基于大数据处理技术的可信度量方法,根据实际情况,分别计算用户对数据源的主观可信度、数据源的全局可信度和本地可信度,然后通过权重加成的方式获取最终的可信度。在Epinions.数据集上与其他可信度计算算法对比,结果发现,本算法在准确度上明显高于其他算法。
参考文献:
[1]李刚,李天琦,程晓荣,等.大数据可信性度量方法[J].计算机工程与设计,2017(3):652-658.
[2]李淑慧.C2C电子商务信用评价体系研究:以淘宝网为例[J].山西农经,2019(3):11-12.
[3]赵阳,朱全银,胡荣林,等.基于自编码机和聚类的混合推荐算法[J].微电子学与计算机,2018(11):52-56.
[4]戚耀元,戴淑芬,葛泽慧.“互联网+”环境下企业创新系统耦合研究:技术创新与商业模式创新耦合案例分析[J].科技进步与对策,2016(23):76-80.
[5]林泓,辛海涛,谢嘉楠.基于直接和推荐可信度的P2P综合信任模型[J].武汉理工大学学报(信息与管理工程版),2011(6):887-891.
[6]中国科学院信息工程研究所.一种基于动态信任模型的IP定位数据库可信度评估方法:中国,CN201710092867.8[P].2017-08-01.
猜你喜欢
今传媒(2016年9期)2016-10-15
考试周刊(2016年79期)2016-10-13
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
