
基于店铺特征和用户需求的广告转化率预测
2019-09-10 07:22:44孙玥杨国为何鎏
青岛大学学报(工程技术版) 2019年3期
孙玥 杨国为 何鎏



摘要: 针对现有搜索广告转化率预测模型和分类模型未考虑店铺特征和用户需求,为了更好的预测广告的转化率,本文基于店铺特征和用户需求对广告转化率进行预测。以阿里搜索广告为研究对象,提出基于店铺特征和用户需求的数据预分析的特征处理方式,对特征进行预分析,即对用户和店铺的相关特征进行初次预测处理,分别求出转化率,以此作为新特征。XGBoost算法泛化性能高,损失函数同时用到一阶导和二阶导,可以加快优化速度,所以运用该算法构建基于店铺特征和用户需求的阿里搜索广告转化率预测模型和转化率分类模型。通过对比预测结果在对数似然损失(Logarith mic loss, Logless)的指标,该预测模型的正确预测率和正确分类率显著提升。本文使用的特征处理方式能够充分挖掘商品信息,能够更好的实现广告转化率的预测,有利于提高广告的竞争力。
关键词: 搜索广告; 预分析; XGBoost; 转化率; 店铺特征; 用户需求
中图分类号: TP181 文献标识码: A
1 相关理论与证明
1.1 特征工程概念
特征工程是机器学习领域至关重要的概念,一般认为是为机器学习应用而设计特征集的相关工作。对于基于特征的机器学习方法,特征集的选择决定了算法迭代到最优情况的极值,特征体系设计的优劣决定了整个模型的性能[6]。因此,如何利用已有的历史数据抽取有效的、与预估任务高度关联的特征是接下来要考虑的首要问题。特征设计的好坏直接影响预测模型预测效果的极限,对模型的时空复杂度及收敛速度都有较大影响。特征工程通过一系列必要的工程活动,将所有信息使用更加高效的编码方式表示,获取更好的训练数据。在对信息进行特征处理时,要保证信息损失较少,原始数据中包含的规律依然保留。此外,新的编码方式应尽量减少原始数据中不确定性因素的影响[78]。
1.2 特征工程常用方法
对特征工程的数据处理一般包括3种方式。在进行特征构建时,分别对不同类型的数据进行处理,获得预测模型需要的特征。
1.2.1 数值型数据
1) 标准化处理:对于数值型的特征,特征取值范围较大,数据分布也很分散,导致方差很大,因此在进行处理时,需要将其标准化为正态函数,均值为0,方差为1,但处理前需要提前考虑是否需要进行这项处理[9]。
2) 归一化处理:将数据大小调整到0~1之间,进行归一化处理后,不仅能够提高收敛速度,减少运算时间,而且能够提升模型精度。所以本文对广告商品的销量等级、价格等级、被收藏次数等级、被展示次数等级这些特征进行归一化处理。
3) 离散化处理:将连续值转化成非线性数据。广告商品的品牌编号是一个long类型,将其按照1 000以上,10到1 000和10以下进行离散化处理。
1.2.2 类别型数据
类别型一般是文本信息,使用数据时采用OneHot编码处理。OneHot编码方法是使用N位状态寄存器对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候只有一位有效[1011]。在对页面展示编号广告商品的类目进行处理时,采用OneHot编码处理。
1.2.3 时间型数据
时间型数据特征可被看作两部分,当为连续值时,用来统计持续时间和时间间隔等[1213];当为离散值时,可以提取小时和星期,w和h就是提取出来的小时和星期。
2 基于XGBoost算法的转化率预测模型和分类模型的构建过程XGBoost是大规模并行Boosted tree工具,比常见的工具包快10倍以上,Boosted tree最基本的组成部分叫做回归树(Regression tree),也叫CART,它会把输入根据输入的属性分配到每个叶子节点,且每个叶子节点上面都会对应一个实数分数[1415]。该算法可通过分布方式建立模型,在不断更新迭代中选择梯度下降的方向来保证预测结果最优,其算法流程如下[16]
本文使用XGBoost算法在CPU计算机上并行Boosted tree,提升Boosted tree的预测精度[17],调用train_test_split函数,随机将实验数据划分为训练集和测试集,其中实验数据都是242维,用来训练模型。
3 系统实现
3.1 实验数据
为保证实验结果的准确性,实验使用的数据来自阿里妈妈国际广告算法大赛,本次使用的数据包括基础数据、广告商品信息、用户信息、上下文信息和店铺信息5类。基础数据表如表1所示,提供了搜索广告最基本的信息以及“是否交易”的标记;广告商品信息、用户信息、上下文信息和店铺信息等4类数据如表2~表4所示,提供了
3.2 实验数据特征处理
采集到的广告数据由于相关性程度低等因素导致包含不实用数据,为了使数据分析或数据预测工作具有科学性和可靠性,不能直接使用这些“脏数据”。因此,首先需要对采集到的原始数据进行特征提取[18]。
3.2.1 用户信息处理
用户自然属性特征来源与用户的注册信息,主要根据所给的数据进行转化率求解,即在所有给定的数据及标签的情况下,分别求出不同性别及不同年龄等级产生购买行为的转化率,从而产生新的使用特征。
3.2.2 广告商品的信息处理
对于广告商品的属性列表,由于其属性有分类,所以需要计算其各属性的数量及权重和。商品類目列表经过计算,其第1列完全相同,所以只选后两个,并把其分为两个特征分别计入,为后面编码做准备。广告商品编号、广告商品的品牌编号、广告商品的城市编号分别计数,求其转化率。
3.2.3 上下文信息处理
用户是否购买商品与时间存在一定联系,如双十一购物节、春节、圣诞节、情人节等都会使用户产生购买行为,因此商品的展示时间也是一个重要属性。根据所给的原始数据,先将时间转化为正常格式,同时增加周属性来增加新的特征。对于商品的预测类目属性,由于其存在缺失值,可以统计类目属性的个数、最大值及其总和。
3.2.4 OneHot Encoding处理
在很多机器学习任务中,特征有的是连续值,有的是分类值。如果将特征用数字表示,效率会很高。但是在转化为数字表示后,数据不能直接用在分类器中。为了解决上述问题,可行的方法是采用独热编码(OneHot Encoding),又称1位有效编码。其方法是使用N位狀态寄存器对N个状态进行编码,每个状态都有其独立的寄存器位,并且在任意时候,其中只有一位有效[19
20]。所以对'item_sales_level','item_price_level','item_collected_level','item_pv_level','context_page_id','w','h','item_category1','item_category2'进行编码处理。
3.2.5 基于店铺特征和用户需求的预分析特征处理
为解决传统特征处理的弊端,本研究加入创新点,为对shop和user的相关数据进行预分析的特征处理,分别通过XGBoost后产生两列新的特征,即不同店铺和不同用户的转化率,其分别为predicted_shop_score和predicted_user_score。
用户数据的转化与否与用户的意愿密切相关,所以对用户相关的特征处理非常重要。首先对每个用户的相关特征进行组合,然后通过XGBoost对组合后的数据求转化率,进而重新生成一维特征,即每个用户的转化率predicted_user_score。
店铺优劣对广告商品转化率有重大影响,对于同一商品,不同店铺的转化率不同,店铺的评价数量、好评率、星级、服务态度、物流服务、描述相符等特征都会影响转化率,而店铺转化率又与广告商品的转化率密切相关,所以研究店铺的相关特征对搜索广告转化率有重大影响。首先对每个店铺的相关特征进行组合,然后通过XGBoost对组合后的数据求出转化率,进而重新生成一维特征,即每个店铺的转化率predicted_shop_score。对于得到的两维新特征predicted_shop_score和predicted_user_score,与其他特征一样,作为最终需要的特征进行训练。
4 实验评价与讨论
4.1 分类预测评估指标
本文采用对数似然损失(logarithmic loss, Logloss)对模型进行评价。对数损失通过惩罚错误的分类,实现对分类器准确率的量化。最小化对数损失基本等价于最大化分类器的准确度,为了计算对数损失,分类器必须提供对输入所属类别的概率值,不只是最可能的类别。对数损失的计算公式为
4.2 实验评价
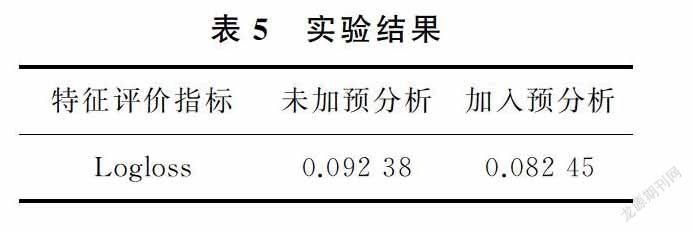
运行Python程序,通过模型将测试集的样本进行分类,求解其转化率,用于求Logloss的pi,进而求解Logloss值。实验结果如表5所示。由表5可以看出,在没有加入初次预测项数据时,logloss较高;在加入初次预测后,logloss明显下降。因此,基于店铺特征和用户需求预分析的特征处理方式是可用的。
5 结束语
本文提出基于店铺特征和用户需求预分析的特征处理方式,对转化率进行正确分类及预测。通过实验研究广告转化率的预测问题,训练数据特征的选择对于模型的预测性能影响重大。广告转化率预测中,数据特征包含基础数据、广告商品信息、用户信息、上下文信息和店铺信息。这些特征组合得越好,模型性能就越好,模型的准确率就越高。本文提出的模型更好地降低了Logloss值,预测广告的转化率更准确,实现了广告商的最大利益。如何从特征学习的角度预估稀疏广告的转化率,同时进行不同模型融合方面的机理性研究是下一步的研究重点。
参考文献:
[1] Graepel T, Candela J Q, Borchert T, et al. Webscale Bayesian clickthrough rate prediction for sponsored search advertising in Microsoft's bing search engine[C]∥International Conference on International Conference on Machine Learning. Haifa, Israel: DBLP, 2010: 1320.
[2] 宋益多. 基于用户特征的搜索广告点击率预测研究[D]. 哈尔滨: 哈尔滨工程大学, 2015.
[3] Stankevich M, Isakov V, Devyatkin D, et al. Feature engineering for depression detection in social media[C]∥International Conference on Pattern Recognition Applications and Methods. Angers, France: IEEE, 2018: 426431.
[4] 余仕敏. 基于递归神经网络的广告点击率预估[D]. 杭州: 浙江理工大学, 2016.
[5] 曹璨. 基于特征抽取和分步回归算法的资金流入流出预测模型[D]. 合肥: 中国科学技术大学, 2017.
[6] Thenmozhi D, Mirunalini P, Aravindan C. Feature engineering and characterization of classifiers for consumer health information search[M]. Springer, Germany: Text Processing, 2018.
[7] 张凯姣. 基于Python机器学习的可视化麻纱质量预测系统[D]. 长宁: 东华大学, 2017.
[8] 司向辉. 个性化广告点击率预测的研究和实现[D]. 北京: 北京邮电大学, 2013.
[9] Chen J H, Li X Y, Zhao Z Q, et al. A CTR prediction method based on feature engineering and online learning[C]∥International Symposium on Communications and Information Technologies. Cairns, QLD,Australia: IEEE, 2017.
[10] 劉怀军, 车万翔, 刘挺. 中文语义角色标注的特征工程[J]. 中文信息学报, 2007, 21(1): 7984.
[11] 王兵. 一种基于逻辑回归模型的搜索广告点击率预估方法的研究[D]. 杭州: 浙江大学, 2013.
[12] 周永. 基于特征学习的广告点击率预估技术研究[D]. 哈尔滨: 哈尔滨工程大学, 2014.
[13] 胡平伍. 移动广告点击率预测方法的研究与实现[D]. 南京: 东南大学, 2017.
[14] 叶倩怡. 基于Xgboost方法的实体零售业销售额预测研究[D]. 南昌: 南昌大学, 2016.
[15] 兰晓然, 张灏, 李明, 等. 基于数据挖掘的手机用户换机行为预测研究[J]. 数学的实践与认识, 2017, 47(16): 7180.
[16] 贾文慧, 孙林子, 景英川. 基于XGBoost模型的股骨颈骨折手术预后质量评分预测[J]. 太原理工大学学报, 2018, 49(1): 174178.
[17] 樊鹏. 基于优化的xgboosTLMT模型的供应商信用评价研究[D]. 广州: 广东工业大学, 2016.
[18] 刘怀军, 车万翔, 刘挺. 中文语义角色标注的特征工程[J]. 中文信息学报, 2007, 21(1): 7984.
[19] 匡俊, 唐卫红, 陈雷慧, 等. 基于特征工程的视频点击率预测算法[J]. 华东师范大学学报: 自然科学版, 2018(3): 7787.
[20] 严岭. 展示广告中点击率预估问题研究[D]. 上海: 上海交通大学, 2015.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:48
中国调味品(2017年2期)2017-03-20 16:18:13
中国新通信(2016年21期)2017-01-06 11:51:42
青年时代(2016年20期)2016-12-08 17:50:05
新闻爱好者(2016年10期)2016-11-18 15:20:33
今传媒(2016年5期)2016-06-01 23:47:05
今传媒(2016年5期)2016-06-01 00:17:22
商(2016年9期)2016-04-15 09:47:56
中学化学(2015年2期)2015-06-05 07:18:13
中国校外教育(上旬)(2015年9期)2015-05-30 06:39:49
