
基于大数据的高校毕业生就业决策支持系统设计
2019-09-10 00:27段薇
现代信息科技 2019年15期


摘 要:大数据背景下,传统的决策支持系统很难适应海量数据的存储、处理以及实时决策的需求。利用大数据技术建立基于Hadoop的大数据决策支持系统体系结构,依据这个体系结构,结合高校毕业生就业决策支持系统的具体需求,建立基于大数据的高校毕业生就业决策支持系统,该系统对高校毕业生的就业以及高校专业的设置、招生计划的制定都有较好的指导作用。
关键词:大数据;Hadoop;决策支持系统
中图分类号:TP311.52 文献标识码:A 文章编号:2096-4706(2019)15-0082-03
Design of Decision Support System for College GraduatesEmployment
Based on Big Data
DUAN Wei
(School of Math and Computer Science,Jiangxi Science & Technology Normal University,Nanchang 330038,China)
Abstract:Under the background of big data,traditional decision support system(DSS) is hard to meet needs of massive data storage,processing and real-time decision-making. By using big data technology,a big data decision support system that system structure based on Hadoop is constructed. Then combining this structure with the needs of the decision support system of graduatesgraduate employment,the decision support system of college graduate employment based on big data can be constructed. It will benefit to help college graduatesemployment and instruct colleges majors setting and establishment of enrollment plan.
Keywords:big data;Hadoop;decision support system
0 引 言
大学生的就业一直都是社会各界普遍关注的社会问题。教育部颁布的《教育部关于做好2019届全国普通高等学校毕业生就业创业工作的通知》明确指出“促进高校毕业生就业创业,事关广大群众切身利益,事关社会和谐稳定,事关高等教育健康发展”[1]。
随着我国教育信息化步伐的不断加快,各高校基本上都建立了与毕业生就业相关的管理信息系统,通过信息化手段服务于毕业生就业工作,但就目前应用状况而言,这些系统的功能基本停留于简单的信息采集、查询等层面,对诸如毕业生的就业信息分析、就业趋势的预测以及个性化就业推荐服务等深层次的应用,更多流于形式。因此,這些系统对指导高校毕业生的就业及预测未来的就业趋势发挥的作用比较有限。目前高校就业管理部门对毕业生的就业指导主要依赖于个人的主观经验,导致就业指导的专业性不足。如何提高就业指导决策的科学性和专业性成为高校就业指导工作面临的首要问题。
随着“大数据”时代的来临,大数据技术在社会各领域中日益发挥着重要作用,决策者的决策基于数据和分析而做出,而并非基于经验和直觉。将大数据技术运用到高校毕业生就业领域,对于为高校毕业生的就业提供决策支持是十分有益的。
1 决策支持系统简介
决策支持系统(Decision Support System,DSS)是从管理信息系统发展而来的,利用数据和模型,通过人机交互的方式辅助决策者解决半结构化和非结构化决策问题的信息系统。传统的决策支持系统由数据库子系统、模型库子系统、人机交互子系统三个部分构成[2],如图1所示。
数据库子系统:由数据库和数据库管理系统构成,存储和管理了决策支持系统所需的各类数据。
模型库子系统:由模型库、模型库管理系统构成,存储和管理决策支持系统中的各类决策模型。
人机交互子系统:用户通过该子系统与决策支持系统中的数据库管理系统,模型库管理系统对话,以查询、操作数据库,或运行模型获得结果。
2 基于Hadoop的大数据决策支持系统
2.1 基于大数据的决策支持系统需要解决的问题
“大数据”时代的到来对决策支持系统的发展提出了许多新的要求,这些要求主要体现在大数据环境下决策支持系统中海量数据的存储、处理以及实时决策这三个方面。传统的决策支持系统所包含的数据多为结构化数据,这些数据一般都存储在单结点的关系数据库中,但关系数据库在非结构化数据的存储和数据库的扩展性方面存在不足,不适合在大数据环境下进行包含多种非结构化数据的海量数据的存储和处理。由于传统的决策支持系统处理的数据量小,数据的查询和模型库模型算法的运行的时间都很短,因此传统的决策支持系统仅能满足数据量较小的情况下用户实时决策的需求。在大数据环境下,由于涉及的数据量巨大,数据的查询和模型算法的运行都需要花费很多时间,因此传统关系数据库和模型库中的模型算法已无法满足决策者实时决策的需求,需要从数据的存储方式以及模型库模型的实现算法两方面解决基于大数据的决策支持系统的实时决策需求。
2.2 建立基于Hadoop的大数据决策支持系统体系结构
Hadoop是由Apache基金会所开发的分布式系统基础架构,其核心是能够实现海量数据存储的HDFS(分布式文件存储系统)以及能解决大数据的并行处理、计算的MapReduce(分布式并行计算框架)[3]。Hadoop发展至今,已成为构建大数据平台的主流技术,除了HDFS和MapReduce,还有许多基于Hadoop的软件,为其提供多方面的业务支撑。如:数据仓库Hive;NoSQL数据库HBase;机器学习算法库Mahout;数据迁移工具Sqoop以及大数据可视化工具(R语言,Python语言)等。
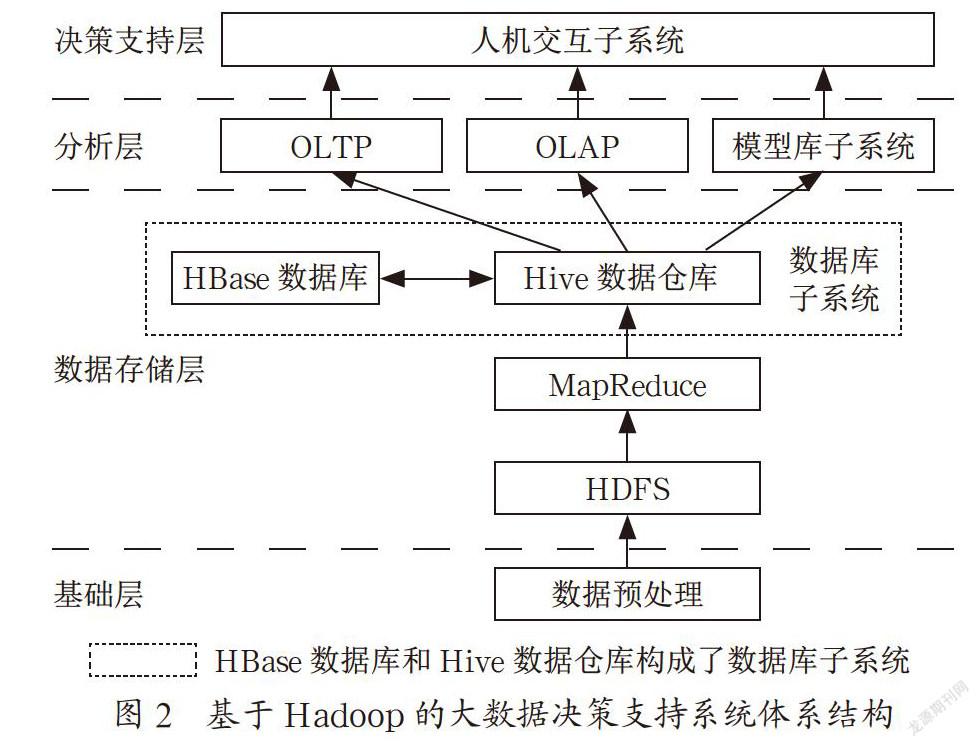
依据“基于大数据的决策支持系统”对海量数据的存储、处理以及实时决策要求,利用Hadoop框架和相关技术采用分层设计方法对“基于大数据的决策支持系统”的体系结构进行设计[4,5],整个系统体系结构包括四层:基础层、数据存储层、分析层、决策支持层,系统结构如图2所示。
基础层:实现决策支持系统所需的各类数据的抽取、清理、转换等预处理工作。
数据存储层:实现决策系统所需的各类数据的存取、管理功能。为解决海量数据的存储,数据存储层将基础层预处理后的数据存储到Hadoop的HDFS中。为提高数据库子系统的查询、处理速度,在数据存储层利用Hive数据仓库结合HBase宽表数据库,为基于大数据的决策支持系统构建一个低延迟的数据库子系统。Hive是基于Hadoop的数据仓库,它能使用类SQL的HiveQL(HQL)语言实现数据查询操作,能使不熟悉MapReduce的用户利用HQL处理和计算HDS上的结构化数据,因此十分适合针对数据仓库的OLAP(联机分析处理)操作。由于Hadoop通常都有较高的延迟,因此Hive不适合低延时的实时应用。HBase是面向列存储的NoSQL数据库,可以存储结构化和非结构化数据,可进行快速查询,但HBase数据库不支持类SQL语句,因此可以将Hive和HBase结合,将基于大数据决策支持中所需的隨机查询数据存入HBase数据库,通过Hive利用HQL语句对HBase数据库存储的数据进行OLTP(联机事务处理)操作,以满足基于大数据决策支持实时决策的需要。
分析层:提供决策模型,以及针对数据库和数据仓库的OLTP和OLAP操作,辅助决策者决策。Mahout中提供了许多可扩展的机器学习领域经典算法,它在最近版本中提供了对Hadoop的支持,利用Mahout中这些经典算法结合决策支持系统的决策需求,可构建模型库的决策模型,在Hadoop框架下运行,提高决策模型的运算速度,满足基于大数据决策支持实时决策的需要。
决策支持层:这是一个人机交互子系统,决策者可通过人机交互调用分析层中模型库的模型,对数据库子系统中的数据执行OLTP/OLAP操作,获取决策所需的信息,辅助决策者进行决策。
3 基于大数据的高校毕业生就业决策支持系统
3.1 可行性
大数据技术为提升高校就业指导决策的科学性提供了可能。目前各高校建立的与毕业生就业相关的管理信息系统中已存储了大量历届毕业生就业的相关信息,各高校的就业信息网上也发布了最新的招聘信息。这些信息数据量大,数据类型多样,既有结构化数据也包含了许多半结构化和非结构化数据,且每年都有大量的毕业生信息以及招聘信息产生,数据的增长速度非常快,但这些数据的价值密度低。因此,目前大多数高校所掌握的和高校毕业生就业有关的数据信息具备了大数据的“4V”特征,即数据体量巨大(Volume)、数据类型繁多(Variety)、产生速度快(Velocity)、价值密度低(Value)[6]。
当前大数据技术的飞速发展,为大数据的存储、处理提供了可能。以Hadoop为代表的大数据技术为基于大数据的高校毕业生就业决策支持系统的设计提供了技术支持。对基于大数据的高校毕业生就业决策支持系统可基于Hadoop的框架来实现。
3.2 基于大数据的高校毕业生就业决策支持系统的功能需求分析
(1)对高校毕业生就业情况进行分析,产生大学毕业生就业质量年度分析报告;
(2)对高校毕业生就业的热点和发展趋势分析;
(3)对就业整体趋势进行预测;
(4)智能化的推荐,为高校毕业生进行个性化就业推荐[7-9]。
3.3 基于大数据的高校毕业生就业决策支持系统的设计
高校毕业生就业决策支持系统按照“基于Hadoop的大数据决策支持系统”体系结构进行设计,其基础层、数据存储层、分析层和决策支持层的具体功能如下:
基础层:数据来源于毕业生生源信息数据库,毕业生就业信息数据库,就业信息网站的招聘信息,双选会,公务员、事业单位的招考信息等,这些信息数据既包含了关系数据库中存储的结构化数据,也包含了网站上的半结构化、非结构化信息。基础层需要对这些异构的数据进行采集、清理、预处理,再将其输出到数据存储层的HDFS中。
数据存储层:数据存储层不仅要能够存储海量的数据,更重要的是为其上层——分析层能够更好地对数据进行分析提供支持。数据仓库是为了决策需要而设计的,是面向主题的、集成的。数据仓库的设计是数据存储层设计的重点。在本系统中,依据其功能需求,设定数据仓库面向毕业生就业的职业流向和毕业生就业的地域流向两大主题。数据仓库的逻辑结构采用雪花模型进行设计,如图3所示,它包括两个基本的元素:事实表和维度表,事实表用来存放要分析的全部数据,维度表中的维度是分析问题的角度(例如:性别、专业、学历层次、地域、职位、行业、就业单位的性质等)。
分析层:针对数据库和数据仓库的OLTP和OLAP操作可生成决策所需的各类统计数据,但决策者使用决策支持系统不是直接依靠数据库子系统中的数据进行决策,而是在很大程度上利用模型库中的模型进行决策。因此,模型库是分析层设计的重点。根据本系统的需求,按照“选择模型/自定义模型—训练模型—评估模型—优化模型”的步骤,利用Mahout中的算法建立模型库中的模型,如:构建关系模型对大学生就业价值取向与就业流向(职业流向、地域流向)的关系进行研究,构建时间序列模型对就业整体趋势进行预测,构建聚类模型对掌握高校毕业生就业的热点进行分析,构建推荐模型对大学生进行个性化就业推荐。
决策支持层:利用Python实现该层的人机交互功能,通过人机交互调用模型库中的模型或进行数据查询,引导决策者进行决策。
4 结 论
大数据技术正在成为推动社会发展、进步的新力量,基于大数据的高校毕业生就业决策支持系统利用大数据技术分析就业形势和毕业生特点,不仅能帮助毕业生调整就业预期/找准就业定位,还可以为高校的专业设置和招生计划的决策提供指导。
参考文献:
[1] 中华人民共和国教育部.教育部关于做好2019届全国普通高等学校毕业生就业创业工作的通知[EB/OL].https://www.ncss.cn/tbch/2019jycytz/,2019-06-01.
[2] Sprague R H,Jr. A Framework for the Development of Decision Support Systems [J].MIS Quarterly,1980,4(4):1-26.
[3] 百度百科.Hadoop简介 [EB/OL].https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin,2019-06-01.
[4] 王振.基于Hadoop的大数据处理关键技术研究 [D].南京:南京邮电大学,2014.
[5] 任建新.基于Hadoop平台的大数据应用系统架构的研究与实现 [D].北京:北京邮电大学,2014.
[6] [奥地利]维克托·迈尔-舍恩伯格.大数据时代 [M].盛扬燕,周涛,译.杭州:浙江人民出版社,2013.
[7] 张亮.大数据时代下的大学生就业指导工作研究 [J].石家庄职业技术学院学报,2014,260(6):60-62.
[8] 李鹏,蔡治廷.大数据时代的大学生就业工作探析 [J].黑龙江高教研究,2015(5):86-88.
[9] 杨锐,夏红.大数据时代下大学生就业数据信息的应用研究 [J].中国电力教育,2014(20):119-120.
作者简介:段薇(1974.12-),女,汉族,湖南祁阳人,副教授,硕士,研究方向:数据挖掘。
猜你喜欢
中国现代医生(2022年21期)2022-08-22
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
电脑知识与技术(2016年23期)2016-11-02
科技视界(2016年20期)2016-09-29
无线互联科技(2015年22期)2016-03-07
