
利用核函数法中的自适应带宽同时对一维空间两个储集层属性参数进行粗化
2019-09-06 09:30MOHAMMADRezaAzadABOLGHASEMKamkarRouhaniBEHZADTokhmechiMOHAMMADArashiEHSANBaratnezhad
石油勘探与开发 2019年4期
MOHAMMAD Reza Azad,ABOLGHASEM Kamkar Rouhani,BE HZAD Tokhmechi,MOHAMMAD Arashi,EHSAN Baratnezhad
(1.Shahrood University of Technology,Shahrood 3619995161,Iran; 2.Tarbiat Modarres,Tehran 114-14115,Iran)
0 引言
多孔介质中流体流动性研究对于解决环境和能源问题非常重要[1-2]。但是从计算工作量的角度,无法求解精细尺度地质模型的流动方程。为了保留储集层属性等重要信息并建立流动方程,需要将精细尺度模型转化为大尺度模型,该过程称为网格粗化[3-4]。网格粗化可以减少计算工作量并缩短计算时间[5-10]。
许多学者对网格粗化方法进行了改进并取得了非常好的效果,但都具有一定的局限性,并且在属性粗化过程中存在一些问题[11-18]。基于平均值法是传统的粗化方法[19-21],该方法不适用于非均质性强的情况。拉普拉斯算子-表皮因子法对三维导流系数粗化结果进行随机分析,并利用多重边界法对三维裂隙多孔介质的渗透率进行粗化[17-18]。基于小波的网格粗化法对阈值的选取要求很高[22-24],在传统的阈值函数(分为硬阈值函数和软阈值函数)概念的基础上[25],Ge等[26-27]在2015年提出了混合阈值函数的概念,避免了单一使用硬阈值函数或软阈值函数的缺点。目前,大多数网格粗化方法只能对一维或多维空间1个储集层属性进行粗化,无法同时对2个或多个储集层属性进行粗化。本文利用核函数法中的自适应带宽技术,在一维空间同时对2种储集层属性进行粗化。在初始模型中,粗化与网格单元的可变性有关,因此需要采用可变带宽方法,并将核函数法中的带宽视为系统的变化程度。用于计算可变带宽的方法主要有:①在动态或自适应带宽中,通过设置门槛值,将每个网格单元的粗化表示为网格单元的可变性;②通过误差值将门槛值限定在所需频带或网格单元的数量上。在前述小波变换的网格粗化法中,以二进制格式进行网格粗化,但在此过程中不知道粗化网格单元的数量。前人研究均无法做到从粗化过程的初始状态就确定网格单元的数量。本文提出的基于核函数的粗化方法可以从粗化开始就确定模型的粗化网格单元的数量。
本文首先从理论角度介绍核函数法中基于自适应带宽的网格粗化算法,然后分别给出每个属性参数的粗化结果。最后,采用两种方法(两种方法具有相同的粗化网格单元数量)建立储集层两个属性参数同时粗化的最终粗化模型。
1 网格粗化算法及数据
核函数方法的主要思路是利用邻域观测来估计某一点(x点)的分布函数。核函数法是一种灵活估算特定数据分布密度的方法。核函数在结构上与柱状图相似,但与柱状图的主要区别在于核函数的密度计算基于x点周围及具有不同的权重的指定范围,而在柱状图中,密度计算范围包括x点及具有相同权重的x中心位置,且取决于每个领域。假设X1,X2,…,Xn是种群n的随机样本,这个样本的结果用x1,x2,…,xn表示,则核函数计算的分布函数可用以下方程表示[28]:

核函数通常是概率密度函数,即积分为1,且K域中的x满足的一个直接结果是核函数密度估算量也是一个概率密度函数。核函数的类型和带宽是两个主要参数。在利用核函数方法进行密度函数估计时,核函数本身的作用很小,但是正确选择带宽h至关重要[29]。考虑到系统粗化与网格单元的可变性有关,可以将核函数密度估计法中的带宽视为系统可变程度的函数。在含有大量信息且具很强可变性的区域,考虑到任何一种粗化方法,无论其精度和操作方式如何,都应尽量保持系统的主要特性属性参数,短程带宽可以达到这个粗化的目的,且该区域的粗化程度最小。因此,这些区域将保持小尺度。反之,在较小可变性或平滑变化的区域,带宽选择足够大的情况下,被合并的原始网格单元最多,这时则由小尺度变为大尺度。
可变带宽可以直接指示系统的可变程度。用动态方法来确定最佳带宽,假设随机样本为x1,x2,…,xn,使用可变带宽的核函数方法估算密度的函数公式如下:
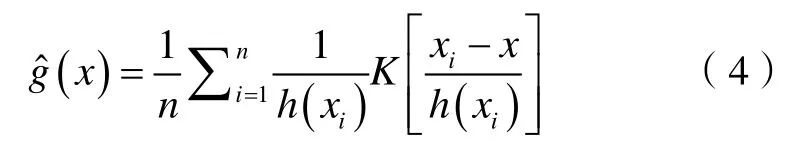
此时定义的门槛值或带宽是可控的,可以从数据中获得变化量及其最大变化量。基于核函数法的自适应带宽对两个属性参数的粗化步骤如图1所示。与传统的粗化方法相比,该方法的网格粗化是严格基于属性的固有可变性。通过确定可变带宽,在可变性较大的区域,选择较小带宽,网格单元应尽可能小;相反,在储集层特征变化较小的地区,选择较大带宽,粗化的网格单元较多。这与核函数带宽方法的多分辨率特性有很大关系。
本文方法适用于任何类型的测井数据,放射性测井、电测井、声波测井或机械式测井等数据类型均可。本文以孔隙压力和电阻率这两种测井资料为例进行粗化,这两个属性参数均为井内测量的两套不同的数据集。沿450 m井段测量了2 413个点的两类测井数据(见图2),根据最大值和最小值之差得到最大门槛值和门槛值的变化。
2 网格粗化结果
2.1 一维空间单一属性参数的网格粗化
在基于核函数法的自适应带宽进行网格粗化时,如果两个相邻网格单元的差异性小于门槛值或带宽,则可将这两个小网格单元合并为一个大网格单元。网格粗化与门槛值关系密切,如果选择较低的门槛值,则被粗化的网格单元较少;如果选择较高的门槛值,被粗化的网格单元的数量将会增加,最终网格单元的数量将会大大减少。

图1 利用核函数法中的自适应带宽对一维空间两个属性参数同时粗化流程图

图2 孔隙压力测井数据(a)及电阻率测井数据(b)
在基于核函数带宽的网格粗化中,通过定义门槛值可控制计算效率。在本文方法中,门槛值可以用所需网格单元数量的函数进行计算,而网格单元的数量由时间函数表示。通过更改门槛值,误差值和网格单元的数量将发生变化。网格单元越多,计算时间越长,计算精度越高。随着网格单元的变大,计算时间会减少,但计算精度也会降低。使用核函数带宽的主要思路是在合理的时间以最高的精度进行模拟。提高精度需要增加网格单元的数量,因此在保持网格单元较小的情况下,网格单元过多会大大增大计算量和降低计算效率。计算效率完全取决于网格单元的数量。如果网格单元的数量是固定,例如,如果需要n个网格单元,并且计算时间为t,那么在模拟过程中,当基于可变性进行多分辨率粗化时,就变成n个网格单元,然后运行该模型,以便用网格单元的数量控制原始模型的最大方差并保证最终模型的精度在可接受范围内。为此,通过考虑核函数评价标准,如均方误差(MSE)、累积或平方误差之和(SSE)及定义的门槛值,可以控制粗化网格单元的数量。在核函数粗化方法中,储集层的可变性可认为是门槛值的函数,通过控制该门槛值,确定模型的最终网格单元数量。这是核变换函数粗化方法和小波变换粗化方法的主要区别。
在本文算法中,可变带宽值从0到最大值不等,可等于数据的最小值和最大值之差。对于每个任意带宽,假设数据x1,x2,…,xn位于带宽范围内。如果这些数据的平均值等于则SSE可由以下方程式得出:
因此,对于每个带宽或门槛值,设一个SSE值和有限粗化带数量。在对数据的第1个属性参数进行网格粗化时,门槛值变化范围为0~1 400,步长为2.5。第2个属性参数网格粗化的门槛值变化范围为0~1 000,步长为3。如果选择较小的门槛值,模型会保留更多的储集层信息,粗化过程将从更多的非均质区域开始。零门槛值将使整个网格单元保持细粒度且不会进行粗粒化。最大门槛值可将网格单元整体收缩到一个均匀区域,整个模型被转换成一个网格单元。网格粗化过程中的另一个关键点是设置最优门槛值或适当的带宽,对于提高计算效率是非常有效的。为此,提出了3种不同的方法:SSE变化-带宽关系法、连续SSE变化法、SSE可变性与带宽关系曲线和网格单元数量-变化性与带宽关系曲线相交法。利用SSE差分法确定最优门槛值或最优带宽。图3显示了第1个属性参数(孔隙压力)的粗化结果,当门槛值为50时,SSE值为86,网格单元数量为940;当门槛值为80时,SSE值为176,网格单元数量为682;当门槛值为100时,SSE值为331,网格单元数量为554。结果表明,最优门槛值为80。图4显示了第2个属性参数(电阻率)的粗化结果,当门槛值为15时,SSE值为14,网格单元数量为800;当门槛值为30时,SSE值为48,网格单元数量为590;当门槛值为80时,SSE值为192,网格单元数量为391。结果表明,最优门槛值为30。
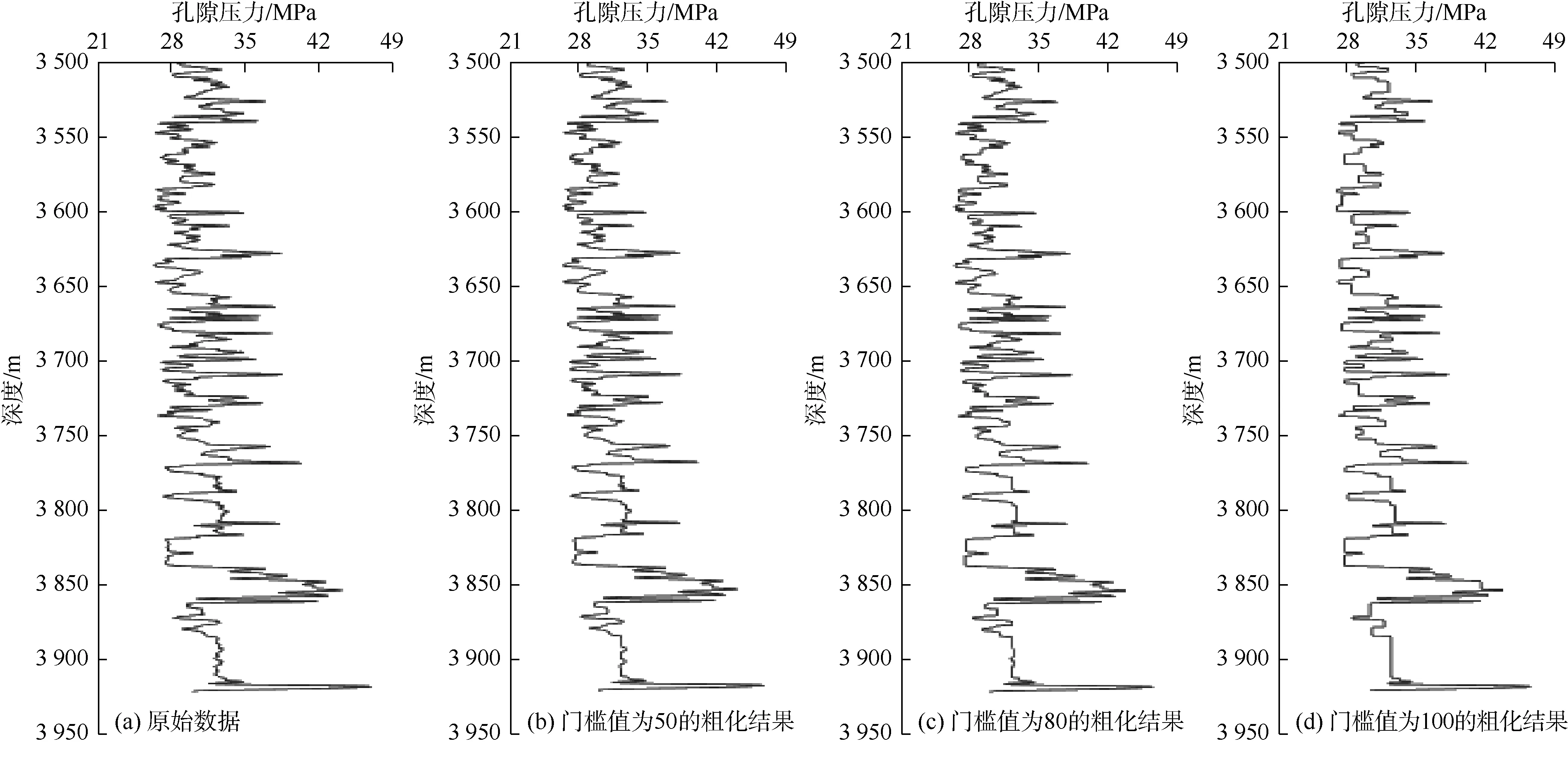
图3 第1个属性参数(孔隙压力)在不同门槛值下的粗化结果
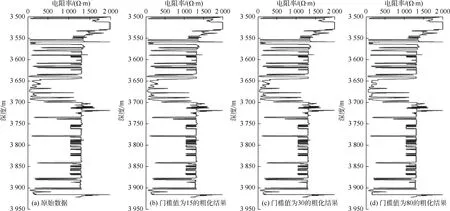
图4 第2个属性参数(电阻率)在不同门槛值下的粗化结果
基于核函数法中的自适应带宽进行网格粗化取决于计算时间和模型精度。例如,如果粗化的目的仅仅是降低计算成本,可以选择较大的带宽;反之,如果粗化的目的是提高模型的精度,则应选择较小的带宽。
2.2 两个属性参数的同时粗化
同时对两个或多个储集层属性参数进行网格粗化的结果更加可靠,这种方法的目的是采用两种不同方法获得两个相同数量的网格单元,然后根据这两个属性参数建立流体流动方程。本文首先计算储集层两个属性参数的最优带宽并得到粗化结果,根据最小带宽法和最大带宽法对两个属性参数同时粗化获得最终的粗化模型,同时保证这两种方法的网格单元数和网格位置都相同。
如前所述,第1个属性参数的最优门槛值是80,粗化网格单元的数量为682;第2个属性参数的最优门槛值是30,粗化网格单元的数量为590。在同时对这两个属性参数进行粗化时,需要保证按比例粗化的网格单元数量相等且网格单元的位置也相同。在最小带宽法中,以两个属性参数中带宽较小的一个作为粗化标准。通过比较两个属性参数的粗化网格单元,将其中较小的一个作为最优网格进行计算。显然,两个属性参数最终粗化模型的网格单元数大于单一属性参数的数量。图5为采用最小带宽法对两个属性参数同时粗化的结果,最终的粗化网格单元数为848,原始模型的网格单元有2 413个。应用最小带宽法时,第1个属性参数的粗化误差为390,第2个属性参数的粗化误差为187。在两个属性参数的粗化模型具有相同的网格单元数量和相同的网格位置。

图5 最小带宽法第1个属性参数(a)和第2个属性参数(b)粗化结果
采用最大带宽法时,使用两种属性参数中带宽较大的一个作为粗化标准。通过比较两种属性的粗化网格单元,将较大的一个作为两个属性参数同时粗化的最优网格进行计算。显然,两个属性参数的最终粗化模型的网格单元数量小于单一属性参数的数量。图6为采用最大带宽法对两个属性参数同时粗化的结果,最终的粗化网格单元数量为144。应用最大带宽法时,第1个属性参数的粗化误差为1 000,第2个属性参数的粗化误差为1 532。

图6 最大带宽法第1个属性参数(a)和第2个属性参数(b)粗化结果
综上所述,采用最小带宽法和最大带宽法对两个储集层属性参数同时粗化得到的模型粗化网格单元数分别为848和144个。基于核函数的带宽,应用这两种不同方法建立1个具有相同网格单元数量和相同网格单元位置的粗化模型。其中,最大带宽法中的网格单元尺寸远远大于最小带宽法。
为了验证方法的可靠性,将粗化结果与测井和试井解释结果进行对比(见表1),在某些点上,估算压力和粗化压力相等。此外,实际压力值与基于粗化模型得到的压力值之间的差异不大,可以接受。
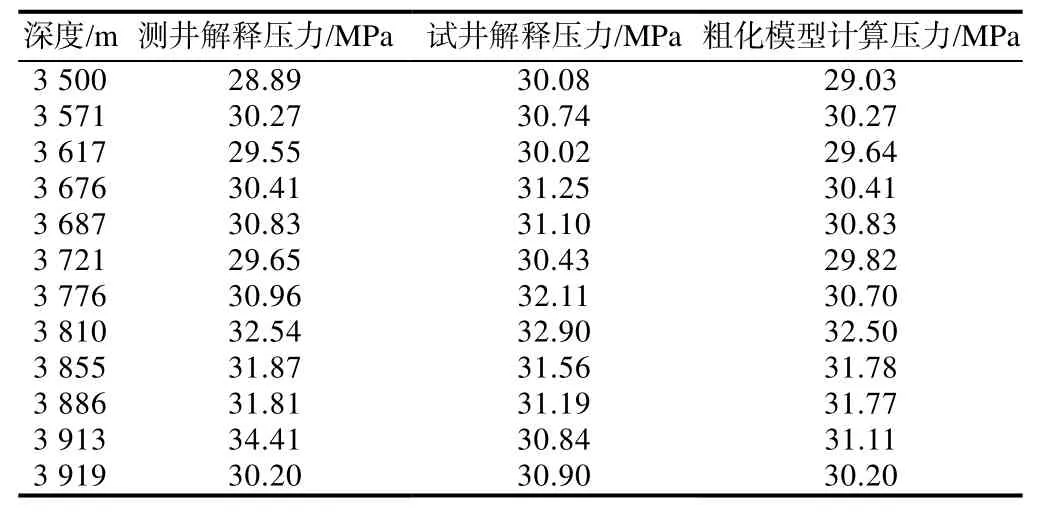
表1 不同方法得到的孔隙压力值对比
3 结论
本文介绍了一种利用核函数法中的自适应带宽同时对一维空间两个储集层属性参数进行粗化的方法。该方法既减少了网格数量,同时也保留了原始精细模型的主要非均质性特征。本文方法采用最小带宽法和最大带宽法对两个属性参数同时进行粗化,保留了属性参数高可变性的精细尺度,并对低可变性区域进行粗化,由此建立两种属性参数的最终粗化模型。最小带宽法和最大带宽法的粗化误差率由最终的网格单元数决定。从计算的角度来看,带宽粗化法得到了具有多个表示对数网格单元的非均匀对数,且最小带宽法的粗化误差小于最大带宽法。
符号注释:
猜你喜欢
电镀与涂饰(2022年8期)2022-05-25
声学与电子工程(2021年4期)2022-01-11
石油化工高等学校学报(2021年1期)2021-04-06
当代陕西(2019年8期)2019-05-09
小学生学习指导(低年级)(2019年3期)2019-04-22
小猕猴智力画刊(2016年6期)2016-05-14
黄河之声(2016年24期)2016-04-22
汽车文摘(2015年4期)2015-12-13
中国火炬(2015年3期)2015-07-31
现代企业(2015年5期)2015-02-28
