
基于关键句提取的中文微博情感计算
2019-09-04 06:21:18胡召亚张顺香
阜阳师范大学学报(自然科学版) 2019年3期
胡召亚,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
微博通常既包含着一些热点事件和新闻话题的描述,也包含着广大用户对这些事件或新闻的态度和看法,通过分析用户在线发表的内容来了解事件的舆论走向,对政府和社会把握社情民意有着重要意义。基于此,本文对微博进行情感倾向的研究与分析。
目前,中文情感倾向分析的研究方法主要分为两大类。一类是基于情感词典与规则的方法。文献[1-5]都是以情感词典为基础,考虑语义规则的影响对文本进行情感分析与研究。文献[6]将语义规则与胶囊网络融合,增强综合句子的表示学习,提高跨域情绪分类的性能。文献[7]通过构建多级词库,制定成词规则,开展串频统计给出一种新词识别方法。另一类是基于机器学习的方法。文献[8-10]采用特征融合的方法,构建不同模型进行情感判别。文献[11]采用基于层次结构的多策略方法,分类效果比单纯使用表情符号和情感词典有一定提高。文献[12-13]利用依存句法与关联规则进行特征提取与构建,从而进行情感分析。文献[14-17]利用卷积神经网络进行训练,建立情感分类模型进行情感分析。文献[18]提出了利用卷积神经网络与k-means聚类算法结合的短文本聚类模型。文献[19]以用户信息为基础,分析用户的偏好话题,并推荐给其他信息相似的用户作为核心人物,提出基于用户聚类的微博推荐算法。
根据目前已有的中文微博情感分析方法以及现阶段的文本情感分析领域的研究成果,考虑以下几点:①如何对存在误导语句的长微博进行情感分析,并减少计算量,提高工作效率;②对于存在复杂句型的句子,如何提高文本情感值的准确度。针对上述问题,本文提出一种基于关键句的中文微博情感分析的方法。该方法首先对微博语句进行关键句提取,再利用多规则方法,即句型规则与句间关系规则计算关键句的情感值。情感分析工作主要分为两个部分,具体实现框架如图1所示:
1)关键句提取。首先引入大连理工大学的情感词汇本体作为情感词典,计算语句的情感属性值与位置属性值,然后通过构建的关键特征词词典计算语句的情感特征词属性值。最后筛选得分较高的语句作为关键句。
2)情感倾向性计算。首先提取情感词利用句间关系规则计算子句的情感值,再利用句型规则对整个关键句情感值进行计算。最后,与表情加权求和得到整体情感倾向值。
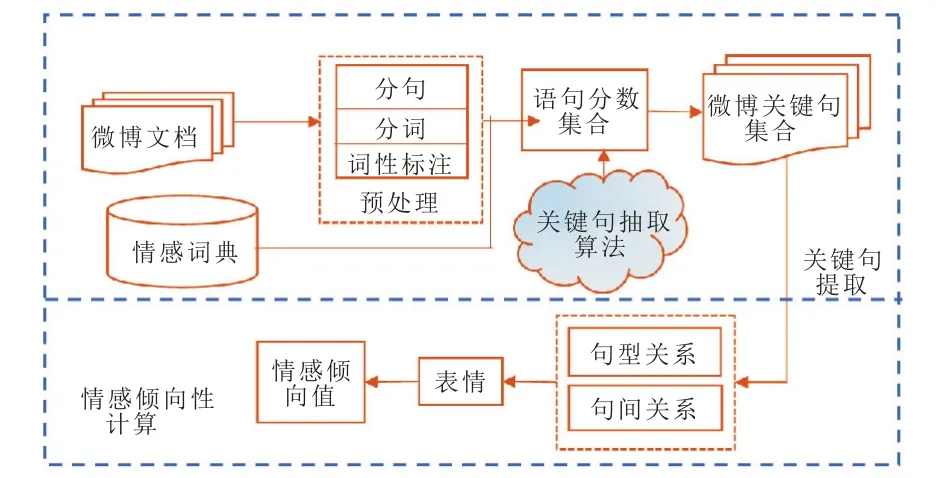
图1 情感分析框架图
1 关键句抽取算法
关键句抽取算法主要考虑句子的3个属性:情感属性、位置属性与关键特征词属性。在一篇微博中,对每个句子计算上述3个属性,并进行加权求和,获得每个句子的得分,设定阈值,选择得分大于阈值的句子作为关键句。句子si分值函数
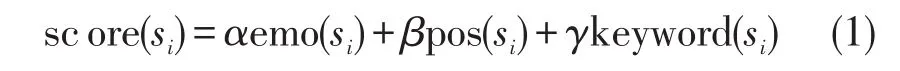
其中,α、β与γ为调节参数,为使结果更加准确,它们的值通过机器学习的方法训练得到。
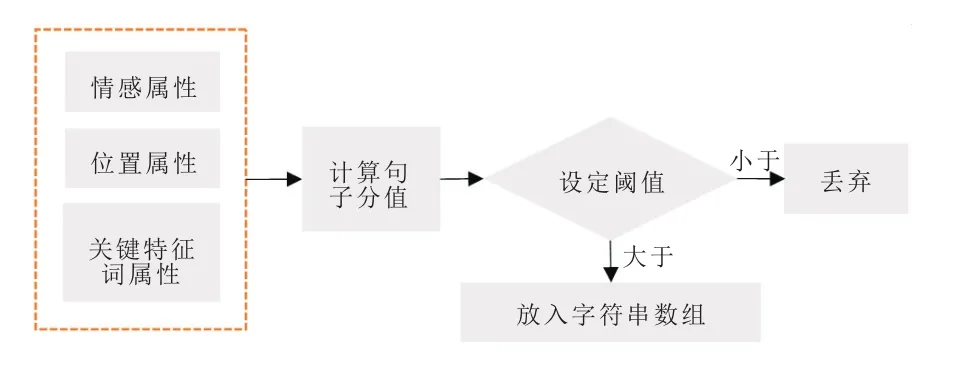
图2 关键句抽取流程图
1.1 情感属性
由于微博文本语句的发散情况,情感属性用来识别句子是否具有情感倾向性。本文采用大连理工大学的情感词汇本体作为情感词典[20]。定义情感属性emo(si)

其中:wordi,k表示si中第k个词语;m表示si中词语的个数。当 wordi,k为情感词时,estimate(wordi,k)=1,否则为 0。
1.2 位置属性
通常情况下,一段文字的起始句子为点题,结尾为总结。对于一篇长微博而言,开头和结尾一般表达了作者的观点和情感倾向,应该赋予较高的权重。位置属性pos(si)表示了句子在整篇微博中的位置信息。
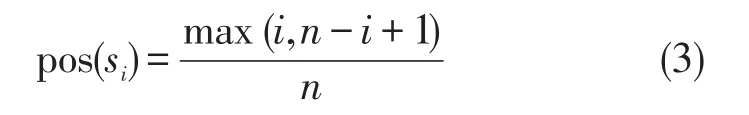
其中:n为该篇微博中的句子个数;si代表该微博的第i个句子。该公式保证了在整篇微博中,开头和结尾的句子具有较高的权重。
1.3 关键特征词属性
影响情感倾向的关键句中一般含有总结性词语,可以作为关键特征词,例如“总之”等。同时,含有第一人称表述词的语句通常明确表达了发布者的观点或者情感倾向,例如“我”等。因此,第一人称表述词也可作为关键特征词。本文根据语料通过经验进行整理建立了两类关键词集合:总结性词语集C1={总之、因此、所以、总而言之、总的来说、综上所述、喜欢、其实、觉得、最好、建议、支持、反对、赞成、应该、但是、但、理解};第一人称表述词语集C2={我、本人、俺、人家、咱、咱们}。
若上述词语存在于某个句子中,则该语句为微博关键句的可能性比较大,所以定义
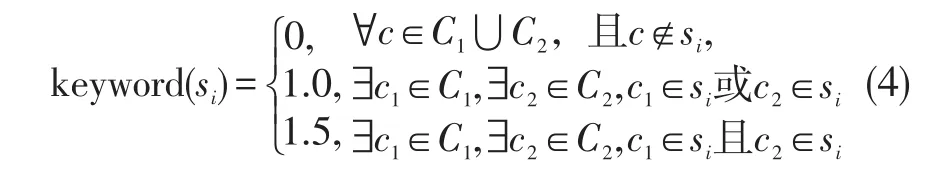
关键句抽取算法如算法1所示。

images/BZ_98_276_953_1185_1014.png输入:待识别的微博文档输出:保存关键句的数组1.输入关键句阈值λ以及微博文档,定义字符串数组t,数组zscore;2.对微博文档进行预处理,即按标点符号进行分句。按顺序放进t中,t中下标表示句子对应位置;3.for each句子s in t 4.{for(k=1,2,…,m)5. { if(wordi,k∈情感词集)6. estimate(wordi,k)=estimate(wordi,k)+1;7. 由(2)式计算情感属性得分; }8. 句子的位置i=t的下标;9. 由(3)式计算位置属性得分;10.由(4)式计算关键特征词属性得分;11.由(1)式计算句子关键句得分;12.if(score>λ)13.{将s放入字符串数组z中;14.将score放入数组zscore中;}15.}
算法1中,第4~7行计算句子的情感属性得分,第8~9行和第10行分别计算句子的位置属性得分和关键特征词属性得分,第12~14行判断是否作为关键句并将其存入数组中。
2 规则多方法计算
中文语法句型丰富多变,在含有情感词的关键句中,任何修饰词都能够影响情感词所在语句的倾向值,故利用句型规则和句间规则计算句子级的情感倾向值。
2.1 句型规则
每个关键句都是一个完整的句子,即以句号、问号、感叹号结尾的句子,Si表示第i个关键句。本文只考虑4种常见的句型,即感叹句、疑问句、反问句以及陈述句。分别对应4条句型规则,由Ci表示相应规则下的权值:
感叹句一般表达作者的强烈意图。若Si为感叹句,则情感倾向极性加强,令Ci=2。反问句的表达一般会改变句子的情感极性。若Si为反问句,则改变情感倾向的程度值,令Ci=-1.5。若Si为疑问句,并不改变句子的情感极性,只是提出疑问,令Ci=1。若Si为陈述句,对情感倾向值没有影响,令Ci=1。
2.2 句间关系规则
在一个复句中,存在以逗号分隔的多个子句,这些子句之间的关系也影响着整个文本的情感倾向值。本文考虑常见的四种句间关系,即转折关系、假设关系、递进关系与否定关系。定义pi表示句间关系规则下的权值:
2.2.1 转折关系规则
在含有转折关系的关键句中,说话者所表达的意图往往在后面的子句中。故对应规则如下:
若Si中只存在前接转折词且出现在子句sj中,则p1,p2,…,pj=0,pj+1,…,pn=1;若Si中存在后接转折词(或同时存在前接转折词)且后接转折词出现在子句sj中,则p1,p2,…,pj-1=0,pj,pj+1,…,pn=1。
2.2.2 假设关系规则
含有假设关系的关键句中,往往说话者的主要意图在前半部分的前提条件,由此便弱化了后半部分。对应规则如下:
若假设关系后连接词出现在子句sj中且存在前连接词出现在子句sj之前,则p1,p2,…,pj-1=1,pj,…,pn=0.5。
2.2.3 递进关系规则
通常情况下,在递进关系的关键句中,后半部分的子句要比前半部分的子句意义更深、更大。故对应规则如下:
若关键句中存在递进关系连接词且出现在子句sj中,则p1,p2,…,pj-1=1,pj,…,pn=1.5。
2.2.4 否定关系规则
若关键句中存在否定词出现在子句sj中,则pj=-1。
2.3 表情符号
微博表情在微博文本的情感分析中起着重要的作用。在新浪微博中,表情符号是文本形式的表达,一个表情符对应的文字包含在一对中括号之间,所以利用正则匹配的方法获取表情符号。本文通过人工的方式对常用的表情符号进行情感强度标注,分为三个类别:积极、消极和中性。将采用表情情感值与文本情感值进行加权处理来获得最终的情感倾向值。
3 微博综合情感计算
前述工作结束后,将得到关键句组成的文本中表情、复句、分句、短语四个层面上的参数,由此计算最终的情感倾向值,用S来表示。
1)分句情感值Score(si)
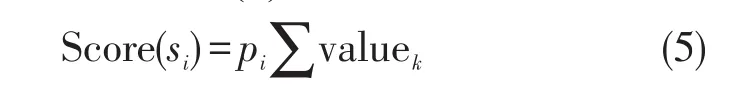
2)复句情感值Score(Si)

3)关键句组成的文本情感值Score(total)

4)表情情感值Score(E)
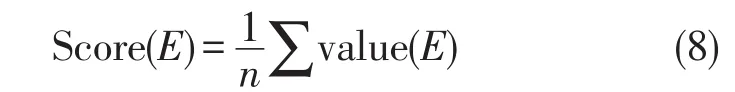
value(E)表示微博表情情感值,由微博文本中所有出现的表情情感值求和后取平均确定。
5)微博情感值S
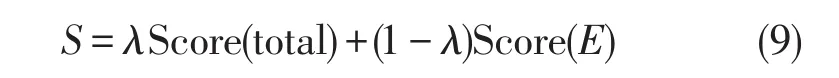
λ值取0.64,由多次试验取得。
4 实验
4.1 实验数据
实验数据集采用公开的微博情感分析数据集,在该数据集中,包含200万条微博数据,均已完成情感倾向的标注。本文在标注情感极性为褒义、贬义、中立的数据集中各分别随机选取1 000条微博作为实验数据。
4.2 实验性能评估指标
通过采用本文的算法对微博进行情感分析,将分析的结果与人工标注的结果进行对比,以准确率Precision、召回率Recall及F1作为评估指标。其计算公式如下:

4.3 实验设计与结果分析
为验证本文提出的基于关键句分析的中文微博情感分析方法,设计实验如下:
实验1:对实验数据进行预处理之后,考虑句型规则和句间规则,引入表情符号,计算微博文本的情感倾向,即规则+表情+情感词典的方法,进行实验。
实验2:采用本文提出的基于关键句提取的中文微博情感计算方法,在实验1的基础上引入关键句抽取算法,对抽取到的关键句进行情感计算分析。对收集到的数据集进行如上实验,实验结果如表1。
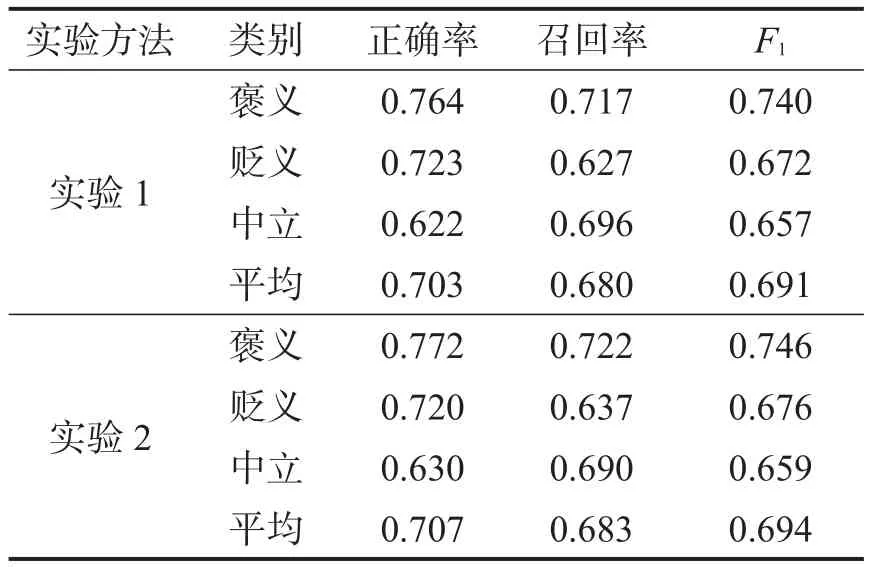
表1 微博数据情感分析实验结果
从表1可以看到实验结果的变化,与实验1中简单考虑语义规则的方法相比,在加入关键句提取之后,正确率、召回率、F1的平均值都有所上升,因为在长微博中,有部分不相关的语句影响文本的情感倾向,故在进行关键句提取之后,结果更加准确。
5 小结
针对中文语言的特点和微博中部分长微博的情况,本文提出一种基于关键句的中文微博情感分析算法。首先提取影响微博情感倾向的句子作为关键句,再对关键句采用句型规则与句间规则的方法进行情感分析,实现了从词语级到句子级再到文档级的情感计算。
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12 07:23:28
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
计算机集成制造系统(2020年8期)2020-09-11 02:49:36
西夏学(2018年2期)2018-05-15 11:24:42
高中生学习·高二版(2016年7期)2016-05-14 03:22:35
智能系统学报(2015年5期)2015-12-03 05:18:10
NBA特刊(2014年7期)2014-04-29 00:44:03
中国商人(2013年1期)2013-12-04 08:52:52
阅读与作文(英语高中版)(2013年5期)2013-05-28 06:43:48
中学生英语·外语教学与研究(2008年7期)2008-12-19 05:28:46
