
基于CART的高校教师亚健康决策模型构建
2019-09-03 11:34张一川殷慧文
实验室研究与探索 2019年8期
易 俗, 张一川, 殷慧文
(1.辽宁大学 创新创业学院,沈阳 110036; 2.东北大学 软件学院,沈阳 110819)
0 引 言
亚健康是介于健康与疾病之间的边缘状态[1]。高校教师在教学、科研繁重任务下,工作没有时间界限和空间界限[2]。传统研究方法采用自评量表和调查表[3]的方式对高校教师亚健康状况及影响因素进行统计和评估。该方法往往只能从宏观角度出发,阶段性的开展调查。因此,从个体亚健康的预测预警角度,缺乏统计评估的时效性与客观性,且调查评估过程需要投入的代价较高,效率较低。
大数据因其强大的预测能力,在疾病诊疗、模型建立、健康管理、基因分析等方面逐渐显示出巨大优势[4-5]。基于机器学习的高校教师亚健康检测方法能够根据已有大数据分析建立评估模型,并在此基础上根据影响因素基本数据满足高校教师个体亚健康状态的检测、评估。相比与传统方法,亚健康大数据的分析更加高效、客观,能够即时反映教师的亚健康状况,并且能够进一步支持高校教师亚健康的预测与预警。
决策树分类是数据挖掘中的一种分类方法[6]。通过对已有教师数据的学习和分析提取规则,对识别指标中的属性进行量化计算。从而,为高校教师亚健康状态的检测提供科学、准确的评估方法体系。目前,国内外大量研究针对分类回归树(Classification and Regression Tree,CART)技术在健康、医疗领域进行了深入研究[7-10]。既涵盖了健康疾病检测、风险评估与干预的理论方法体系研究,也包括利用CART对疾病和健康的检测、预警研究。还有方法通过改进CART算法降低数据的冗余度,提高诊断及预测的精度。但尚未存在研究利用CART的方法针对高校教师亚健康状态的检测给出完整全面的分析和建模。
本文首先综合分析高校教师职业本身的社会压力与生活行为,充分考虑职业特性,构建一种多维度的高校教师多维影响因素概念模型。并进一步进行影响因素样本数据集的特征分析,确定条件特征及决策特征,给出了数据预处理的方法及过程。在此基础上,利用CART算法给出了高校教师亚健康决策模型的构建、优化方法和过程。最后,设计了模型的构建架构,并利用Spark计算框架给出了该方法的并行实现。
1 样本数据分析及处理
1.1 多维影响因素
高校教师具有脑力劳动特征的职业特性,其个人健康状况变化具有内在规律性,而不同的健康数据之间存在着内在的关联性。在教学任务、科研成果等方面承受着巨大的精神压力,在事业成就、职称、生活习惯、人际关系等高压环境下也存在着各种心理矛盾。为此,在性别、年龄、职称等流行病学特征的理论依据下,针对高校教师的职业特点,将导致高校教师出现亚健康状态的因素划分为多维度高校教师健康影响因素[11-12]。多维度高校教师健康影响因素从社会特性、健康特性、环境特性、职业特性和行为特性5个维度展开,见图1。
1.2 样本数据集特征分析
采用决策树技术解决高校教师亚健康状态评估首先需要对样本数据集展开分析。

图1 高校教师健康多维影响概念模型图
根据上述分析得到的多维影响因素,归纳样本数据集中包含的条件属性特征有48个,各维度参考的特征因素见表1。
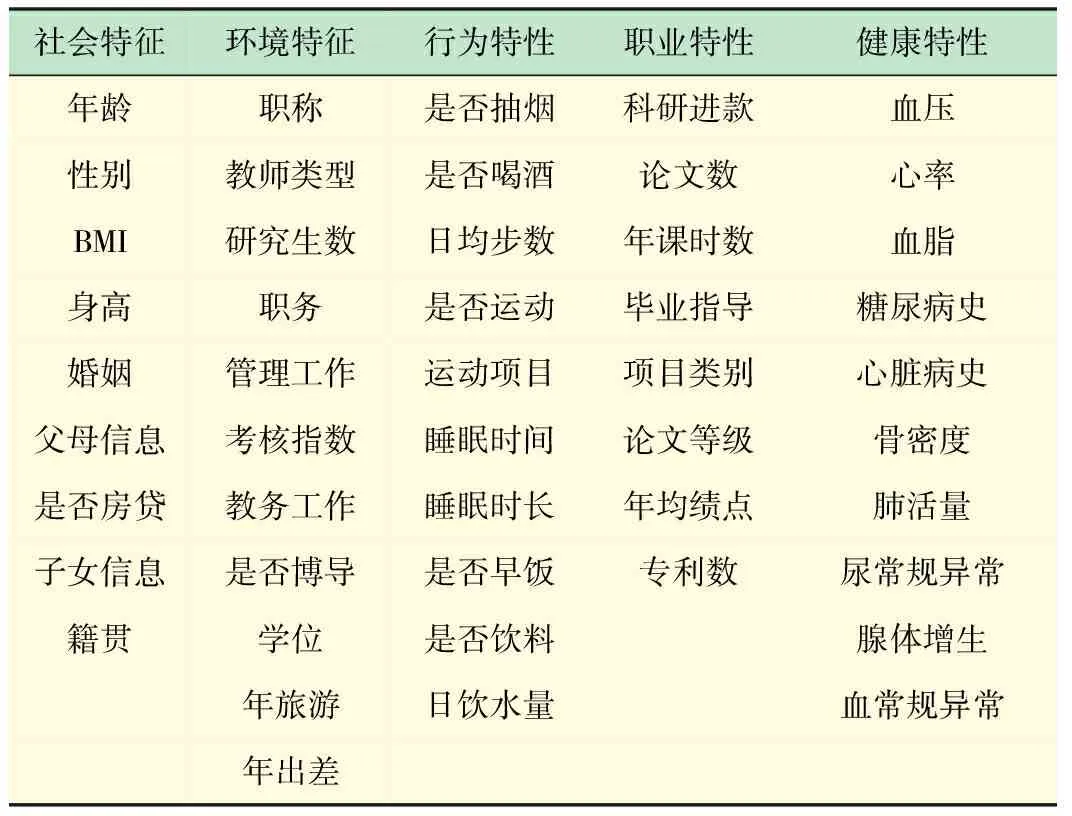
表1 多维亚健康影响因素属性表
决策属性采用健康特性与标准亚健康评估指数相结合的方式,制定亚健康评价准则。利用向量空间模型对亚健康影响因素进行数学抽象。设样本数据集中条件属性特征为向量L(l1,l2,…,ln),其中l1至ln为影响高校教师健康的n维属性,主要来自于多维影响因素的社会特性、环境特性、职业特性及行为特性。决策属性特征为向量R(r),其中r是根据上述亚健康评价准则得到的亚健康评价值,即
r=w1·PHI+w2·CMI,(w1+w2=1)
其中,PHI值是根据教师个人健康特性属性中相关指数未在正常范围内的数量确定的体检健康值。CMI值根据康奈尔医学指数问卷结果,综合考虑身体因素和心理因素两方面得到的亚健康状态值。w1与w2为健康评价权重系数,通过调整该系数能够综合考察不同指标比例对认定是否亚健康及亚健康程度的影响。
1.3 样本数据预处理
亚健康决策树的构建包括构建与优化两个阶段。首先,利用决策树算法通过训练数据集构造初始决策树;然后,利用树优化算法通过测试数据集修正决策树。因此,样本数据的预处理除了考虑对数据如何采集,还需要考虑对数据如何进行整合及标注。亚健康评估样本数据的预处理过程见图2。
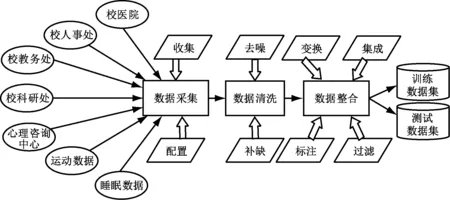
图2 数据预处理过程图
(1) 数据采集阶段通过与校医院、人事处、教务处、科研处、心理咨询中心等多部门协同合作。针对健康特性、职业特性、环境特性等不同属性的数据来源,通过各种管理系统接口进行数据的收集。利用Flume分布式架构,将大量的数据从数据资源装载到目标服务器。针对行为特性数据如日常运动、健康等日志的采集,通过Apache的Flume数据采集工具实现。同时,利用ZooKeeper保存配置数据,保证配置数据的一致性和高可用。采集来的多样化数据经过值域对照、数据抽取、转换,最后上传到健康数据库。
(2) 数据清洗阶段为了降低决策树构造过程数据质量对模型效果的负面影响,针对采集得到的数据进行数据补缺、去噪初步处理。
(3) 数据整合阶段针对上述分析数据库中的数据进行数据的进一步处理。重点考虑数据对分析过程的影响,通过变化、集成、标注及过滤过程对数据进行整合处理。围绕构建决策树的目标结果进行分析和处理,整合成支持数据分析阶段的输入数据。数据变化及集成过程将来自不同源的数据转换成统一的数据类型,以及将部分连续型数据转化为离散型数据,从而简化相应的计算量;数据标注过程对条件属性值即决策属性值进行阈值范围的考察和确定;数据过滤过程对需求数据属性展开分析,对原数据中的数据进行合理范围内的约束和选择。最终结果数据集即可划分为训练样本和测试样本,提供给决策树建模算法进行树的构建。
2 CART算法亚健康决策树建模
2.1 CART算法适用分析
高校教师亚健康的多维度影响因素具有条件属性繁多的特点。多维影响因素中具有复杂数据类型的指标属性,如既包括婚姻状况、职称、是否吸烟等离散型数据,也包括年论文数、年龄、日均步数等连续型数据。条件属性值的区间划分情况较为复杂,需要算法提供动态处理能力。CART算法模型可以运用于多指标海量数据的复杂分类处理特性,使得应用于高校教师亚健康评估决策树的建模更加适用,具有较大的优势。
CART算法利用分类树适用于离散型目标数据的分析,利用回归树适用于连续型目标数据的分析[13]。因此,当亚健康评估目标为亚健康评价值r时,可考虑利用回归树构建对高校教师的健康值评估;当亚健康评估目标按照评价值被离散化处理为诊断时,如离散化为疾病、亚健康和健康,可考虑利用分类树构建高教教师的健康状态评估[14]。本文采用分类树模型根据健康状态对决策树进行模型构建。其中,CART样本数据抽象为:
DC={DL,DR}
(1)
DL={L1,L2,…,Ln}
(2)
DR={R1,R2,…,Rn}
(3)
d1=(l11,l12,…,l1n,r1), (d1∈DC)
(4)
式中,DC为样本数据集,其中包括特征属性集DL及结果属性集DR。L称为属性向量(Attribute Vectors),其属性来自于多维度亚健康影响因素分析过程中得到的条件属性特征向量L(l1,l2,…,ln),其中既包括连续型属性也包括离散型属性;R称为标签向量 (Label Vectors),其属性来自于影响因素分析过程得到的决策属性特征向量r,该特征向量值是根据亚健康评价值r的阈值范围评定给出的,包括{疾病,亚健康,健康}。dn为样本数据集中的单条数据。本文研究的样本集中每个样本有48个条件属性和一个决策属性。
高校教师亚健康评估CART算法的决策树构建实现过程首先定义了3种数据结构:存储样本属性名称及取值的KVNode属性,存储具体某个样本的TeacherSet属性,树的节点属性TreeNode;并存放于SHDataStructure.h中。样本通过划分不同文件分别存储样本的属性及样本集。设计ReadFile类读取文件分别存储在两个向量中。
2.2 决策树构造算法
利用CART算法构建亚健康决策树的基本原理是检查每个健康条件属性所有可能的划分值来发现最好的划分。首先,需要针对条件属性从多样本集的输入变量中选择最佳分组变量;其次需要针对分组变量进行纯度计算,找到一个纯度最高的最佳分割值。因此,对于离散型考虑除空集和全集之外的所有划分情况;对于连续型,则针对n个连续值产生n-1个分裂点,相邻两个连续值的均值(li+li-1)/2即为分裂点的分割值。将每个属性的所有划分按照Gini分割指数进行划分,Gini分割指数主要用于考察节点内n(n≥2)种样本的差异。针对整个样本训练数据集DT,DL部分一共包含n个条件属性,那么Gini指数可以定义为:
(5)
式中:Pm为决策属性值m在训练样本DT中的相对概率,如果集合DT中共有t条训练数据,在l1的条件下分成DT1和DT2两部分,数据条数分别为t1和t2,那么这个Gini分割指数就是:
(6)
以递归的方式针对每个属性值尝试划分,意图找到使得Gini分割指数变量最大的一个划分,该属性值划分到的子树即为决策树构造阶段的最优分支。
高校教师亚健康评估CART算法的决策树构建过程采用递归函数的方式,将全部样本数据集的80%作为训练数据集进行决策树构建。建模具体实现过程首先找到一个划分值,若不存在,返回-1,然后判断当一个树不是叶子节点时则按照划分值进行划分。设计并实现SHTreeCons类,如图3所示,该类图展示用于构造决策树模型的基本方法。其中,SHTreeBuild方法通过调用划分方法对非叶子节点进行划分;TreeDivid方法是节点划分方法,划分左右节点;AttriCho方法针对输入的考察节点进行属性值的选择;GiniSeg方法用于计算Gini分割指数对构造树进行最优划分;TraverTree方法用于构造决策树的模型。

图3 亚健康决策树构建类图
构造决策树模型的核心算法SHTreeBuild函数的伪代码描述如下:
输入TreeNode
输出无
步骤1遍历所有节点,当节点不为空时,循环执行步骤2~5,否则跳出结束程序;
步骤2变量nodeCount增1,且将其赋值给当前节点的nodeCount,树遍历排序;
步骤3调用AttriCho方法进行属性值划分确定并将该划分添加到节点属性中;
步骤4如果该节点属性划分值为-1则无法再次划分,将其定为叶子节点,返回步骤1;
步骤5若节点属性划分值不为-1,则执行步骤6~8;
步骤6将该节点定为非叶子节点;
步骤7调用TreeDivid方法,将父节点按照划分属性进行划分;
步骤8通过递归方式调用函数SHTreeBuild分别建立左子树及右子树,返回步骤1。
TreeDivid函数针对对输入的样本变量进行基于Gini分割指数的最优划分,若划分成功返回属性下标,否则返回-1。nodeCount在该函数中能够支持树的遍历,对每一个节点赋予唯一值,树模型的构建过程是采用前序遍历。当建树结束后,树的前序输出结果即为nodeCount从小到大的排序,然后通过TraverTree函数输出树的中序序列以确定树的结构。其中,nodeCount和leavenode同时还将支持后续的树模型优化剪枝过程。
2.3 决策树优化剪枝算法
采用CART算法的后剪枝方法在已构建的决策树模型基础上,通过删除节点分支来剪去树节点。
CART利用成本复杂度标准是在已有分类树的加权错分率基础上,加上对树的惩罚因子。其中,惩罚因子包含一个复杂度参数a来表示每个节点的惩罚代价。成本复杂度的数学表达为:
Ca(T)=C(T)+a×|Tnum|
(7)
式中:C(T)是测试数据被已生成的树模型T错误划分的部分;Tnum是已生成树T的叶子节点个数;a是每个决策点惩罚代价,a=2(n-1),其中n为分类数。若a=0则表示对该树绝大多数的节点没有惩罚,其成本复杂度是未剪枝的树。通过剪枝算法,从剪枝得到的优化树模型中选取测试数据集上具有最小误分的树作为最终优化的决策树模型。
高校教师亚健康评估CART算法的决策树优化过程将全部样本数据集剩余的20%作为测试数据集进行决策树剪枝。设计并实现SHTreePrun类,如图4所示,该类图展示用于对决策树模型进行剪枝的基本函数。其中,SHPrun函数为剪枝函数,利用测试数据集对已生成的树模型进行剪枝;TraverLevel方法通过层次遍历对决策点进行序号分配,以便用于剪枝函数处理;ErrTest方法通过考察不同决策点下建树样本产生的错误样本个数,其中参数t为决策点的数目;DesTest函数根据具体的某个决策点对测试样本集进行测试,其中参数k为单个样本,t为决策点数目。

图4 亚健康决策树剪枝类图
对于剪枝算法来说,首先要考虑获取已生成树的决策点,才能根据决策点数目进行剪枝。利用二叉树具有非叶节点与叶节点之间差1的特性,可计算得到非叶结点数量。利用层次遍历对决策点逐层赋值,其中根节点nodeCount赋值为1,左节点nodeCount赋值2,叶子节点nodeCount为0。
层次遍历后根据决策点数量,改进决策树前序遍历,确定叶子节点,从而确定模型树的结构。然后,根据树的决策点数对训练样本和测试样本的误差进行统计。不同决策点对应不同子树,通过前序遍历可以将叶子节点中的错误样本统计出来计算该树模型错误样本的个数。接着,利用测试样本对树模型进行遍历,统计修正后测试样本错误样本个数。最后,得出最小误分树结果集。
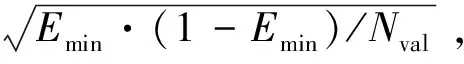
3 模型实现与验证
基于上述高校教师亚健康决策树模型构建思路,在学院实验室机房进行主机运行环境的搭建,采用开源的操作系统和相关开源开发资源进行运行环境的部署,利用Spark计算框架进行亚健康评估决策树构建的分布式并行实现。
样本数据方面基于多维亚健康影响因素,抽取2016年3月至2017年3月的258例教师基本数据。决策树CART算法的参数设置为:树结构最大深度为5,父节点最小个案数为5,子节点最小个案数为1,Gini系数的最小变化值为0.000 1,在树的构建过程中排除缺失值[15]。对48个影响因素进行决策分析,归纳出模型的评估规则。根据该算法得到的输出结果数据部分内容展示如图5所示。其中node表示节点序号,根据算法可知序号越小越接近根节点,序号越大越接近叶子节点;split表示分割点属性及其划分阈值;n表示该分割点属性下一共具有的数据量;loss表示该属性下未得到目标决策值的数据量;SHval表示该条件属性特征值下得到的决策属性值;最后,SHprob为该分割点特征值下各决策值的占比。

图5 CART算法决策树建模结果
该决策树模型通过CART算法的构建和剪枝优化处理,最终确定了14个属性作为亚健康评估的条件属性,见表2。

表2 决策树模型亚健康评估条件属性
该决策树模型共产生了32个叶子节点,其中10个叶子节点利用J表示评估结果为健康状态;6个叶子节点,利用B表示评估结果为疾病状态;16个叶子节点,利用Y表示评估结果为亚健康状态。该决策树基于大数据,既能够归纳出影响亚健康的主要因素,也能够总结出评估亚健康状态的规则,为未来的智能亚健康检测评估系统与智能亚健康监视预测系统的应用开发提供基础。
为了验证基于CART算法的高校教师亚健康决策模型的有效性和准确率,其中选择43名教师作为实验对象,利用高校教师亚健康模型对该实验对象进行教师健康状况的评估及预测实验。评估实验结果健康人数4人,亚健康人数33人,疾病人数6人。
根据WHO(世界卫生组织)权威发布,全球人类亚健康状态比例为75%。利用本文方法预测得到的高校教师亚健康比例为76.7%,见图6。这一结果与全球亚健康比例组成非常接近,说明该方法具有一定的准确率。且通过观察该数据略高于全球普通人群,进一步阐明高校教师工作性质将带来一定的身心压力,高校教师群体相对普通人群更加具有亚健康风险。
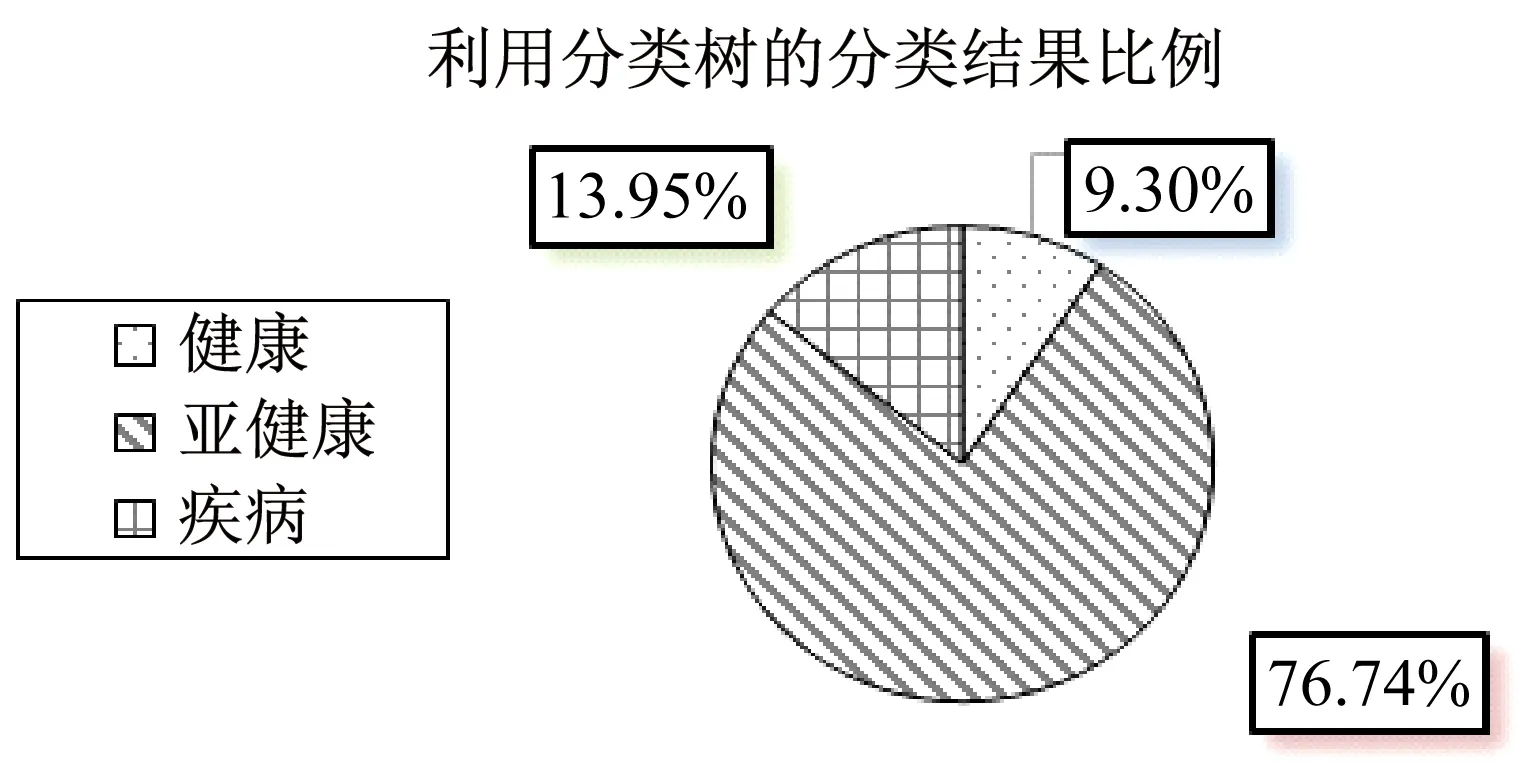
图6 分类树结果比例
除此之外,利用文献3中提出的基于流行病学调查问卷传统方式针对这43名教师进行亚健康状态评估的对比实验。如图7所示,经统计利用传统方法得到的健康状态分类结果与本文提出的方法得到的分类结果数据仅在亚健康与疾病状态的分类部分差异极小。进一步证明该方法能够有效指导高校教师亚健康状态的预测。与传统方法相比,具有更加良好的即时性和操作简易性。
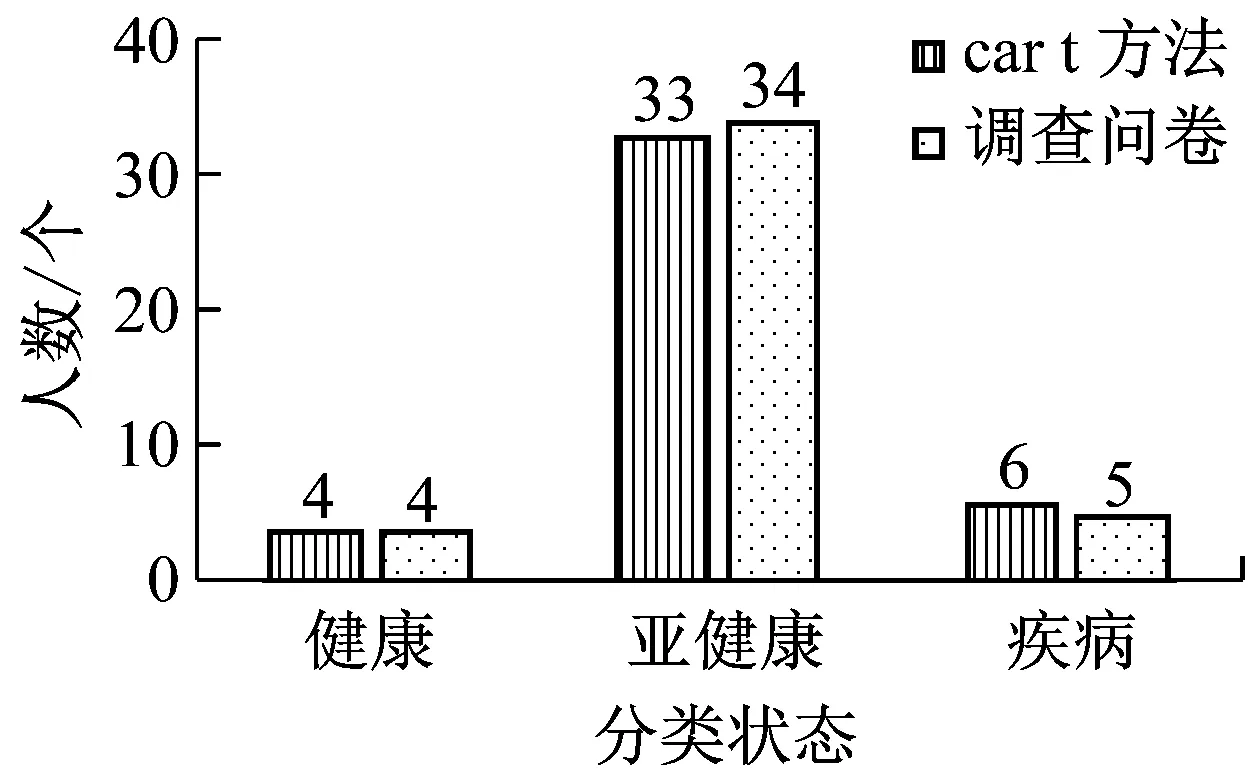
图7 决策树模型与传统方法比较
4 结 语
利用CART算法针对高校教师亚健康状态决策模型的建立进行了研究。设计了多维高校教师亚健康影响因素概念模型,以及分析了相应样本数据的特征,实现了数据预处理的具体过程;利用CART算法给出了多维影响因素样本数据下进行了决策树的建模和优化方法。并且,设计了亚健康评估的系统架构,利用Spark进行了并行化的算法实现,并通过实验对模型的有效性进行了验证,为高校教师亚健康检测评估、监视预测提供了良好的决策模型基础。
猜你喜欢
河北画报(2020年10期)2020-11-26
成都信息工程大学学报(2019年3期)2019-09-25
少先队活动(2018年5期)2018-12-29
时代英语·高一(2018年5期)2018-11-19
电子制作(2018年16期)2018-09-26
中国劳动关系学院学报(2016年5期)2016-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
人间(2015年19期)2016-01-04
亚太教育(2015年18期)2015-02-28
郑州大学学报(医学版)(2015年1期)2015-02-27
