
基于染色体分化遗传算法的工业生产线柔性加工
2019-08-30 01:56吴林彦李艳萍马义飞
制造业自动化 2019年8期
吴林彦,李艳萍,王 琪,朱 青,马义飞
(山东建筑大学,济南 250100)
0 引言
随着科学技术的进步和计算机技术的发展,原有的传统机械制造方式在计算机等辅助工具的帮助下得到了新的发展,增加了新的内涵。由于传统的机械制造方式受环境等不确定因素影响较大,操作人员疲劳、设备老旧、零部件损坏等问题会严重影响作业效果。因此计算机辅助设计(CAD)、计算机辅助制造(CAM)、柔性制造系统、计算机集成制造系统(CIMS)等新技术被广泛应用于机械制造领域。而在工业生产线的分配布局过程中,我们必须对之前所说的不确定因素进行评价并优化,以提高生产线的平衡性和鲁棒性,而这就是柔性制造系统(Flexible Manufacturing System,FMS)。
自从20世纪80年代FMS逐渐走向实用,国内外对FMS相关的研究就一直在进行。1977年Solberg采用CAN-Q模型评价FMS性能,首次将工业生产系统建立解析模型进行优化[1]。1983年Suri和Hildebrant对FMS的优化问题进行了讨论,采取了排队网络方法建立了整个制造系统的解析模型[2]。20世纪以来,闭排队网络(ClosedQue,CQN)模型作为求解速度更快效果更好的优化排队网络模型被广泛采用[3]。Rajagopalan提出了一个混合整数规划(MIP)解决方案,解决了零件分组和零件刀具分配问题[4]。随后Sawik提出了基于零件类型选择、机器装载、零件输入序列和操作调度的生产计划任务的层次结构以确定柔性制造系统[5]。阿蒙斯等人描述并讨论了机器装载问题的两个目标,即平衡工作负载和最小化工位用量[6]。文献[7]中也讨论了装载问题的双准则目标,包括平衡工作负载和满足零件类型流水线中的选择搭配。文献[6,7]指出,之前建立的一系列数学模型方法是不切实际的,因为即使对于中等大小的测试问题也需要大量的计算时间。尽管在过去的20年里在算法方面取得了进步,要解决这个问题仍然比较困难,同时在生产过程中实现所需的软件方面存在着一些障碍。后来Kumar和Shanker通过建立MIP模型来解决零件类型选择和机器装载问题,提出了基于遗传算法(GA)的求解方法,并且使得计算量更小[8]。Yang和Wu还应用了基于遗传算法的集成方法来解决FMS零件类型选择和机器装载问题,在实现算法的编码方案的同时,引入了虚拟作业和虚拟操作的概念[9]。
本文采用了基于染色体分化(GACD)原理的新型遗传算法,这是一种求解FMS中机型配置工序优化问题的新型算法。GACD具有优于传统遗传算法的以下 优点。
1)GACD在系统的应用和配置之间有更好的平衡性,因此与传统的遗传算法相比能得到更好的结果。
2)种群多样性的增加和限制交叉导致染色体之间更快的信息交换,从而比传统遗传算法收敛速度更快。
3)通过对GACD的分析,特别是对Bandhopadhyay和Pal提出的样例进行分析,GACD得到的优化值要优于传统遗传算法的优化值[10]。
1 染色体分化的遗传算法
遗传算法是一种“智能”概率进化搜索和优化算法,它通过采集一组称为种群的染色体并应用各种生物启发的遗传算子,如选择、交叉和变异来模拟染色体成熟过程。种群内的每一个染色体通过已经设定好的适应性函数进行评估,并通过选择、交叉、变异进行繁殖,产生新的子代并用适应性高的染色体组代替差的染色体组。以此类推不断选择和优化,直到找到令人满意且接近最优的解决方案[11]。
在本文所提出的染色体分化遗传算法中,我们应用性别分化使得染色体被分成两类,即男性(M)和女性(F),从而产生两个群体,即男性群体(MP)和女性群体(FP)。另外,在构造两类群体时我们人工地使这些种群不同,以最大化两个类之间的汉明距离(HammingDistance)的方式产生这两个种群。同时我们规定只有属于两个不同种群的个体之间才允许交叉,而选择则适用于所有种群[12]。因此,GACD在选择和优化之间更好的实现了平衡,这也是任何自适应系统的主要特征之一,从而使GACD优于简单的遗传算法(GA)。GA的基本步骤如图1所示,而GACD也基本遵循图1的步骤,2.1节~2.6节介绍了GACD与传统GA算法的参数不同之处。
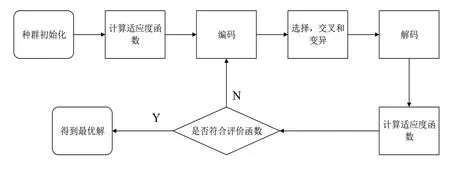
图1 遗传算法步骤流程图
1.1 种群初始化
图2描述了GACD染色体的构建过程。染色体的前两位称为数据类位,因为它们用来指示染色体的类是男性(M)还是女性(F)。这两个互相独立的类,一个由男性群体染色体(M)组成,另一个由女性群体染色体(F)组成。总种群(TP)等于男性群体(MP)+女性群体( F P ) 。 最开始各类染色体数量为MP=FP=TP/2,但是随着交叉和变异,这两类染色体(MP和FP)的大小在不同的世代中会逐渐出现差异。首先种群中的MP首先被初始化,每个M类染色体的数据位被随机初始化为01或10。然后对FP进行初始化,通过最大化男性群体和女性群体之间的汉明距离来生成每个F类染色体的数据位。而每个F染色体的所有数据类位都设置为0。因此对于两个染色体γ1和γ2:γ1,γ2,其中τ是染色体初始种群,HD(γ1,γ2)被定义为两个染色体不相同数据位的数量。两个群体MP和FP之间的HD表示为:

1.2 适应度函数
适应度函数定义也如式(1)、式(2)所示,通过计算男性群体和女性群体每个染色体前两个数据位的汉明距离确定新种群的适应度。
1.3 选择操作
通过确定种群的适应度函数,每次进化完毕后比较父代和子代的适应度,适应度高的被选择为新的男性群体和女性群体。
1.4 交叉操作
男性种群M和女性种群F之间的交叉操作概率xc。其中每个父代为子代提供一个类位,很明显女性种群F只能贡献类位0。因此,后代的类别只由能贡献1或0的男性种群M决定。如前文所示的交叉操作被应用于数据的类位上,直到满足以下条件则交叉停止。
1)原种群中没有染色体存在。
2)原种群中只有男性染色体M存在或只有女性染色体F存在。
在情况1中,交叉过程终止。在情况2中,剩余的M或F染色体与适应度最好的F或M染色体配对。如果在初始阶段,交配池只包含一个类的染色体,同样也中止杂交程序。
1.5 变异操作
变异操作概率为μp且应用在染色体的数据位中,并不应用在染色体的类位上。
2 GACD算法的具体应用
本节定义了GACD算法的相关术语,并讨论了GACD算法应用在生产线时出现的各种设计问题(例如编码、群体初始化、适应度函数评价、交叉、变异、选择和缩放)。GACD的主要优点是它的灵活性和适应不断变化的优化标准和约束的能力。对于单个个体的表示、编码方法、初始M和F种群、选择和缩放方法以及遗传算子的选择等因素对GACD算法的性能都会有很大的影响。因此在接下来的几小节中,本文对这些因素进行了详细的讨论。
2.1 编码
对染色体的编码方式是遗传算法实现中的一个关键问题。GACD编码包括对类位的编码和对数据位的编码。Holland等人采用了二进制字符串编码方案,但这样的方案后来被验证不适用于现实世界的问题[13]。在过去的十年中,各种非字符串编码技术已经被开发用于特定的问题,例如用于解决约束优化问题的实数编码和组合优化问题的整数编码。除了这些之外,邻接、置换和基于矩阵的编码也都被广泛应用。本研究采用的编码方式为,类位采用二进制编码,数据位采用面向数据序列的编码方案。例如,如果工业生产线生产一个机器需要8个步骤,那么它可以被编码为:

这里,类位01表示该染色体为男性(M)染色体,数据位依次表示生产步骤。
2.2 种群初始化
种群初始化的原则在2.2节已经讨论过,同样对于8个步骤的生产过程可以假设其表示为:

Male population 0 1 4 5 7 3 1 6 2 8 0 1 5 6 1 4 2 8 7 3 1 0 7 2 6 4 5 1 3 8 1 0 3 1 5 2 4 7 8 6
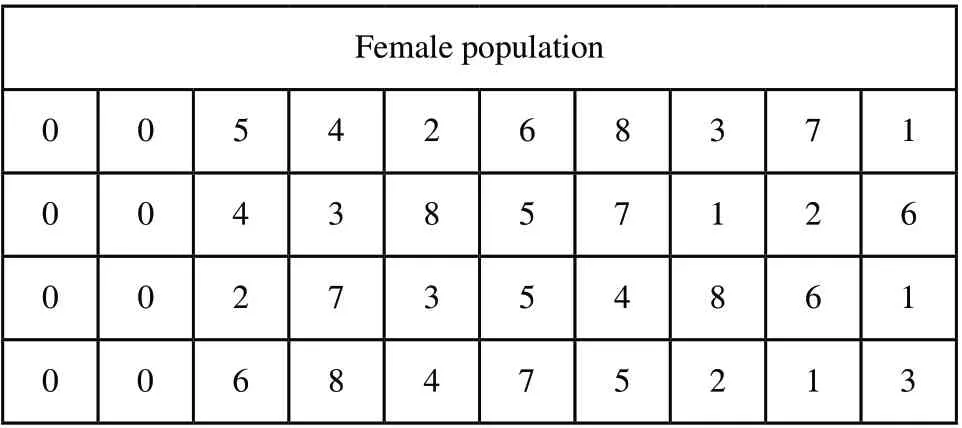
Female population 0 0 5 4 2 6 8 3 7 1 0 0 4 3 8 5 7 1 2 6 0 0 2 7 3 5 4 8 6 1 0 0 6 8 4 7 5 2 1 3
2.3 选择操作
选择操作是对所有染色体进行选择,同时不考虑染色体的类信息。选择操作中采用合适缩放方法有助于整个遗传算法保持合适的择优速率,并防止种群过早收敛到次优解。在本研究中,我们测试了各种缩放方法,包括动态线性缩放、幂律缩放、对数缩放、加窗、归一化和玻尔兹曼选择。计算实验表明,“玻尔兹曼选择”方案中的基于比例选择的“轮盘赌策略”比其他策略具有更高的效率。对于染色体K和适应度fk,尺度函数可以定义为:
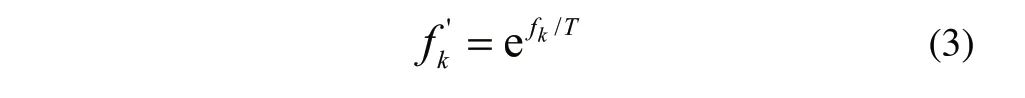
当控制参数T高时,选择压力较低。因此选择概率可以等价为:
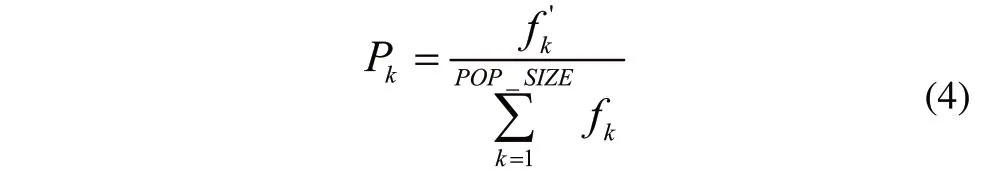
由式(4)可知,适应度最高的个体总是可以存活到下一代,以便使GACD能够更快地收敛。
2.4 交叉操作
在GACD算法中,交叉应用直到满足适应度函数的条件为止。交叉操作是一个M染色体和一个F染色体重组产生两个染色体的过程。目前解决排序和调度问题时常用的标准交叉算子为有启发式交叉、部分映射交叉(PMX)、增强边缘重组(EER)、顺序交叉(OX)、基于均匀顺序的交叉(UOX)和循环交叉(CX)。在本研究中采用了部分映射交叉的方法。部分映射交叉的操作流程为如下:
随机选取两个交叉点,按性别交换两个交叉点之间的片段。将男性染色体中的片段替换为女性染色体中同样交叉点间的片段。
将男性染色体交叉点外重复的工序按对应方式替换为交叉点内的工序步骤,同时将女性染色体按同样步骤处理,即可得到男性染色体的子代和女性染色体的子代,PMX流程如图2所示。
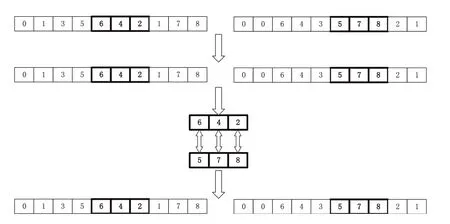
图2 部分交叉映射流程图
2.5 变异操作
染色体经过交叉操作后,染色体往往会受到突变,这些突变会为染色体增加额外的变异性,提供并维持了整个种群中的多样性,并能基本遍历所有的搜索空间。在本研究中,变异操作被作用于染色体的数据位。变异概率表示染色体中的基因将被改变的概率。在过去的研究中,人们提出了若干种用于遗传算法的变异算子,例如反转、插入、移位、互换变异等。而在本研究中,本文采用一种基于启发式的方法,使用邻域技术变异产生一个改进的后代。变异的基本原理如下,示意图如图3所示。
1)随机选择n个基因片段。
2)通过考虑所选基因的所有可能排列来产生邻域后代。
3)评价所有邻域后代的适应度并选出最优的 后代。
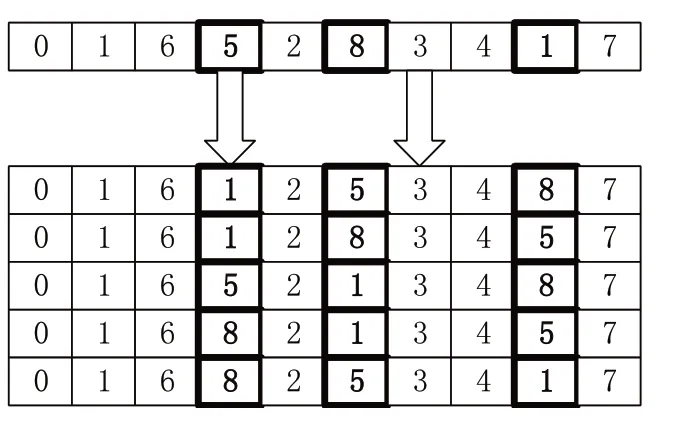
图3 变异操作示意图
2.6 参数设置
遗传算法的参数设置及优化是一个非常耗时的问题。主要可调的参数位种群大小POP_SIZE、进化次数MAX_ GEN、交叉概率xp、变异概率μp。其中:
种群大小通常根据染色体长度(CL)的倍数变化,如式(5)所示。其中PSF为种群大小因子。在本研究中,POP_SIZE=INIM_POP+INIF_POP,即种群大小为初始男性种群和初始女性种群的数量和。
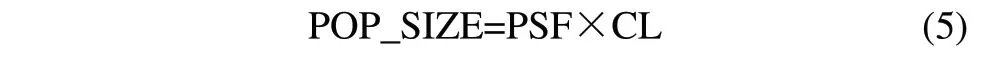
遗传算法通常采用较大的xp(0.4~0.9)和较小的μp(0.05~0.2),xp和μp的增加可以优化过程中的遍历程度,但同时也会增加算法的耗时。在本研究中,已经进行了大量的实验以实现优化和耗时之间的平衡,并且所得到的结果也在上述的范围内,这些参数的精确值将在下一章的示例中给出。
3 生产线示例
为了证明本文提出的GACD算法的有效性,将本方法应用到文献[14]至文献[16]中给出的一个随机机型的FMS示例中。表1为给定FMS类型的测试问题的详细描述下面的步骤描述了上述基于GACD方法在解决柔性制造问题上的应用。
1)设置初始变量INIM_POP=INIF_POP=5,xp=0.5,μp=0.1,MAX_GEN=30。
2)生产的总工序步骤pmax=8,同时工序的步骤顺序按照第三节中提到的种群初始化方式构造。
3)选择合适的适应度函数以最小化整体系统的不平衡性。
4)初始化进化次数GEN,并使GEN+1,对第2)步中初始化的种群进行操作,假设待操作的染色体为[0 1 5 4 3 7 1 6 8 2]。
5)对每个男性群体和每个女性群体计算适应度函数f1的值。其中只有染色体的数据位参与计算。
6)对于步骤4)给出的染色体,其代表的工作顺序为[5 4 3 7 1 6 8 2],性别为男性。按照第三章所述进行PMX交叉以及基于启发式的变异操作。交叉后的子代和变异后的子代共同构成进化后的子代。按照前文给出的适应度函数进行评价,并选择出最优染色体构成一次进化的结果。
7)终止条件如下:如果GEN=MAX_GEN,则终止进化,否则GEN=GEN+1,并回到第5)步。
经过以上给定步骤的GACD算法运算后,示例FMS的利用率可以达到76%。
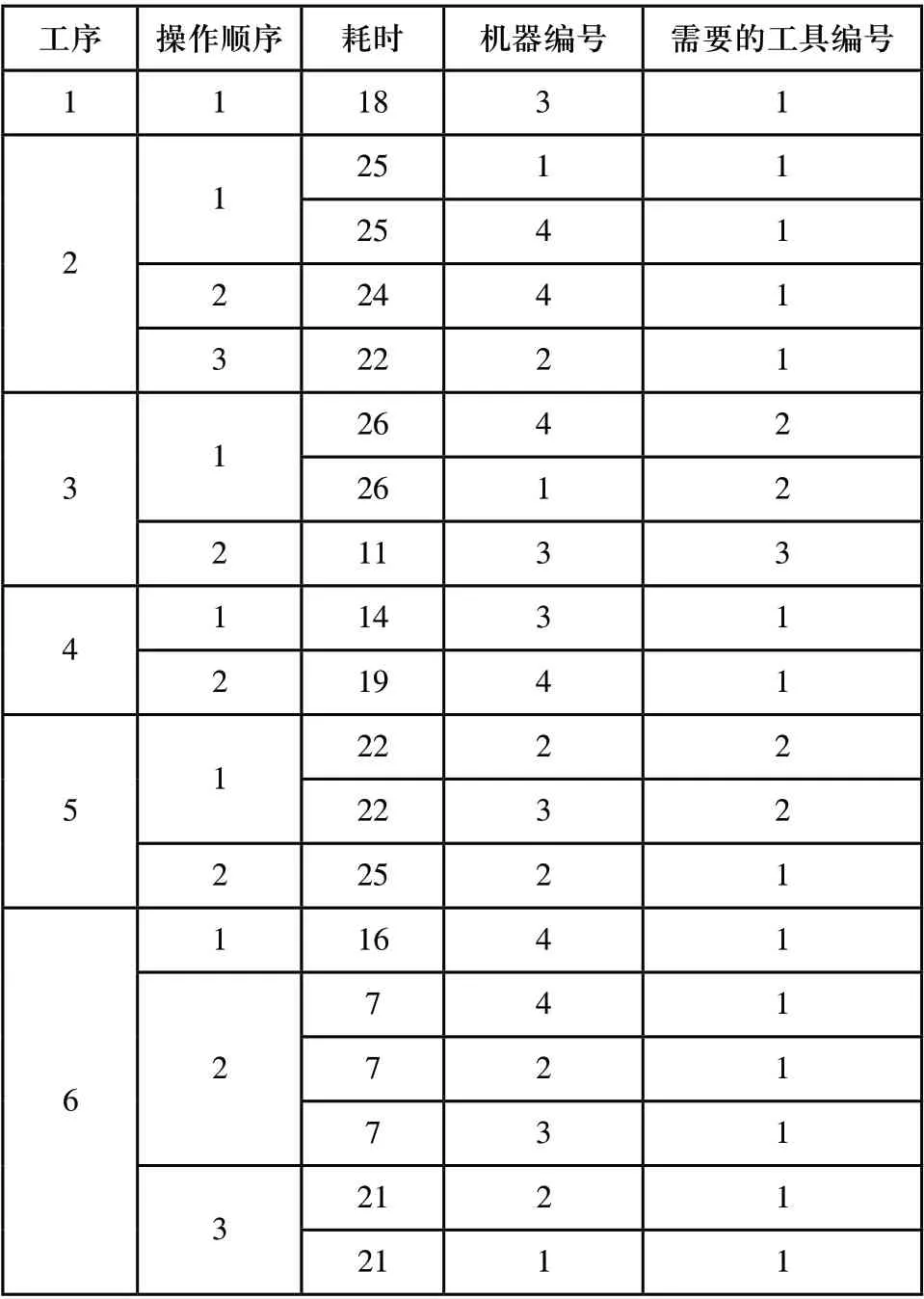
表1 FMS示例

表1(续)
4 结语
本文提出了一种基于启发式的GACD算法,并将其与普通遗传算法进行了比较。图4给出了GACD原理下几种交叉和变异算子组合的性能及其对示例给出的FMS加载问题结果的影响。同时,对于Tiwari和Vidyarthi在[17]提出的问题,我们将GACD算法与GA进行了比较,结果如图5所示。由比较可知,二者得到最优结果的进化次数是相同的,但对于结果的评价函数来说,GACD得到的结果使得系统的平衡性更高。
PMX-RE:部分映射交叉+相互交换
EER-INS:增强边缘重组交叉+插入交换
CX-DIS:循环交叉+替换
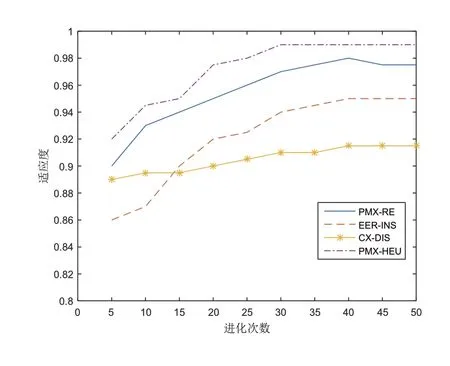
图4 不同算子的性能比较

图5 GA与GACD最佳适应度(a)和平均适应度(b)的比较
PMX-HEU:部分映射交叉+启发式变异本文对一个具有四个目标函数和两个技术约束的机器装载问题进行分析。本研究所要解决的关键问题是藉由满足工艺约束来决定机器上待加工零件类型的数目和顺序,以达到最小系统不平衡和最大产量。因此本文提出了一种基于染色体分化的遗传算法,利用染色体分化的概念来增强现有遗传算法的能力。其中在对算法进行编码时,将二进制编码应用于类位,并且使用实数编码对数据位进行编码,同时最大化染色体间的汉明距离,限制交叉,使得进化过程可以发生更快的信息交换。该方法在给出的示例测试问题中的应用表明,GACD在求解质量和求解耗时上都表现良好。同时本研究还可以进行进一步的研究,比如增加对资源的其他方面的分配,如增加工位,增加固定装置和自动引导车辆(AGV),都可以进一步的优化整个生产线系统。同时我们还可以增加一些惩罚概念和更多的目标函数,例如要求零件运输距离的最小化、加工器械在生产过程中的改变等等,而这也是我们下一步要考虑的主要问题。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
今日农业(2021年12期)2021-11-28
汽车工程(2021年12期)2021-03-08
初中生世界·八年级(2019年6期)2019-08-13
电子制作(2019年24期)2019-02-23
郑州大学学报(工学版)(2018年2期)2018-04-13
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
汽车科技(2015年1期)2015-02-28
