
基于语料库的语篇回溯范畴实证研究
2019-08-28 01:21:46陈虹
天津外国语大学学报 2019年4期
陈 虹
(安徽财经大学 文学院英语系)
一、引言
广义来讲,每个语篇都建立在回溯的基础上,因为阅读是不断积累信息的过程,没有前面的信息很难理解当前的内容。俄罗斯学者И.Р.Гальперин(1981:106)语篇范畴理论中的回溯(ретроспекция)是一种特别的现象,它属于语法范畴,故意把读者的注意力引导至上文,使读者关注先前叙述的事实内容信息,并同时能够把先前的内容和当前的内容统摄为一体。因此,回溯范畴是作者构建语篇结构、表现主题思想的重要手段和方法,对它的研究有助于更好的理解语篇形式和内容上的关联,具有重要的语言学意义。
二、回溯范畴的先行研究情况
目前,国内外学者对语言学中回溯范畴的研究主要集中在两个方面。一是对其理论的探讨,包括回溯的判定、基本特征、表现形式、作用和功能等;另一个是在对文学作品的时间范畴进行研究时,把它作为一种文学时间的延展方式。
回溯范畴在理论方面的研究至今没有超出И.Р.Гальперин的思想框架,众多学者都是以Гальперин回溯范畴理论为中心来进行研究。Гальперин(1981:105)认为,回溯由事实内容信息引起,其基本特征是时间发生前移,引导读者回顾过去。А.Ф.Папина(2002:169)在此基础上进一步认为,只要时间往回推就构成回溯。但Е.Е.Анисимова(2003:36)认为,Папина的观点把回溯泛化了,只有在时间回推的过程中出现跳跃才出现回溯。我国学者史铁强和安利(2008:45-46)比较倾向于Анисимова的观点,他们认为,在语篇叙事中通常会有一个主线推动情节发展,但语篇并不总是呈现为线性,叙事中作者会插入议论或描写,正叙中有时也会加入倒叙,因此语篇中存在着很多方法能让主线推进出现暂停,让叙事放缓,这种连续时空背景下的时间跳跃才是回溯产生的前提。关于回溯在语篇中的基本形式,学者们几乎都赞同Гальперин(1981:106)基于语用目的不同而进行的三类型划分方法:第一,恢复读者或受话人头脑中对此前已存信息的记忆,或传达对理解语篇后续发展所必需的部分新信息;第二,使读者或受话人能够在新条件下或新的上下文中重新审视已存信息,并把回溯前后的信息加以对照;第三,体现那些与观念内容信息间接有关的语篇个别部分。郭明(2012:265)在论著中曾提出过自己的三类型划分:第一,“恢复读者头脑中已知信息或者表述针对过去的、新的、但对于理解下文必需的信息”;第二,“在新的条件下、在其他语境中,结合已知内容对这些信息进行想象、推理”;第三,“对概念内容信息间接相关的语篇片段进行整合”。把这个三类型划分和Гальперин的三类型划分相互对比,基本一脉相承,没有很大区别。
回溯范畴由于与时间概念密切相关,因此也被置于文学时间的领域内进行研究。在文学作品的客观时间模式下,说话人可以自由地对已知事实进行思考或回忆,即,存在着回溯式的时间延伸。回溯式的时间延伸在文学作品中可以表现为作者运用倒叙或插叙的手法把叙述时间置换回过去,这是现实主义文学常用的推进情节的表现方式(车琳,2013:81-82)。它也可以表现为在机械时间坐标轴上的某一个准确位置,即依靠文学作品中人物的理智和主观控制来回忆往事,这时的回溯往往表现为一个意识清晰、思维明确的作品人物有意识和目的的在记忆深处搜索一个确定事件,因此这种回溯具有时间上的客观性和精确性,但却不能体现心理时间的渗透和绵延(郭明,2012:107-113)。回溯式的时间延伸还可以构建文学作品的另一层时间,即意识流动时间。虽然它同样主要依靠人物的思想和回忆来完成,但它是人物内心心灵时间的延展,是作品中的人物受到外界人或物的刺激后,在不经意间慢慢激活的、沉睡于无意识之中的记忆。这种回溯的时间形式可能是破碎、断裂的,甚至是幻觉、超理性的,它常常被后现代主义的作家用在意识流小说中(卢婧,2005:45-49)。
在回溯范畴的研究中,几乎全部的学者都把文学语体语篇作为研究对象,即使是对回溯理论的探讨,所举证的语例也几乎都是文学作品中的,这不能不说是一个缺憾。在各种语体语篇中进行研究,才能保证对回溯范畴的研究具有普遍意义。
三、回溯范畴的描述性分析
现在世界范围内已建成的绝大部分语料库遵循的都是词汇主义思想,这些语料库对能转化为词层面的研究十分合适(陈虹,2012:39-40)。但当研究上升到更高层次,如语篇层面时,这些已有的语料库就可能不再适用,这时可以创建面向自己研究题目的语料库(谢家成,2003:27)。大量的理论研究和实践探索表明,依照常规的建库原则,采用科学的建库方法和程序,可以使自建的小型语料库也同样具有代表性(Meyer,2002;Biber,1994)。
遵照创建语料库的一般原则、方法和步骤,我们建设了一个总词次超过17.5 万、拥有70 篇文本(30 篇文艺语体文本,20 篇政论语体文本和20 篇科技语体文本)、用于研究语篇范畴的小型俄语语料库。库中语料大部分来源于20 多个常用俄文网站随机下载的公用语篇,少数语料是从国内著名出版社出版的俄语教材和教辅材料中随机选用的语篇。小型自建俄语语料库的全部语料通过手工操作方式进行了文本标注和面向研究问题的标注。
根据小型自建俄语语料库的语料,可以对文学、科技和政论语体各语篇中回溯出现的类型和次数做出统计。表1是对自建库中三种语体语篇中各类型回溯出现次数的汇总。虽然由于语料库中不同语体语篇的数量不尽相同而使这个数据统计的比较意义不大,但它能让我们粗略认识从语料库中得到的回溯范畴数据的整体情况,并可以感觉到,有些类型的回溯只发生在特定语体的语篇中,有些类型的回溯在政论和科技语篇中出现的次数可能会比较少,事实是否如此,还有待于进一步验证。
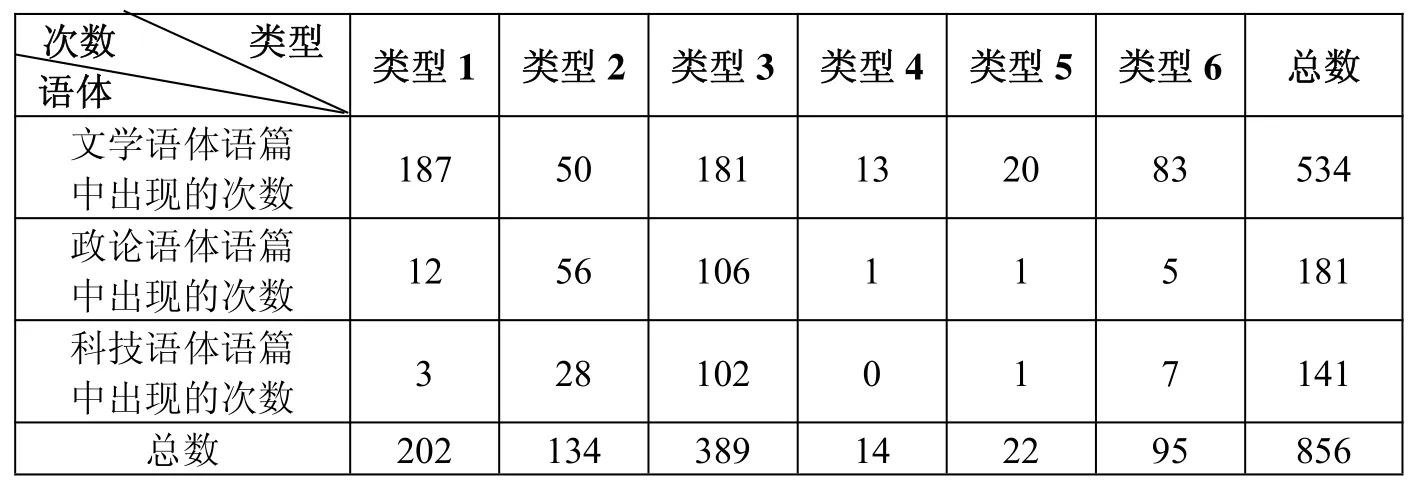
表1 回溯次数分布汇总表
为了对整个回溯范畴数据的主要特征和全貌进行比较全面的了解,可以利用均值和标准差对数据进行集中趋势和离中趋势的分析,利用公式计算出来的均值和标准差的统计结果详见表2。
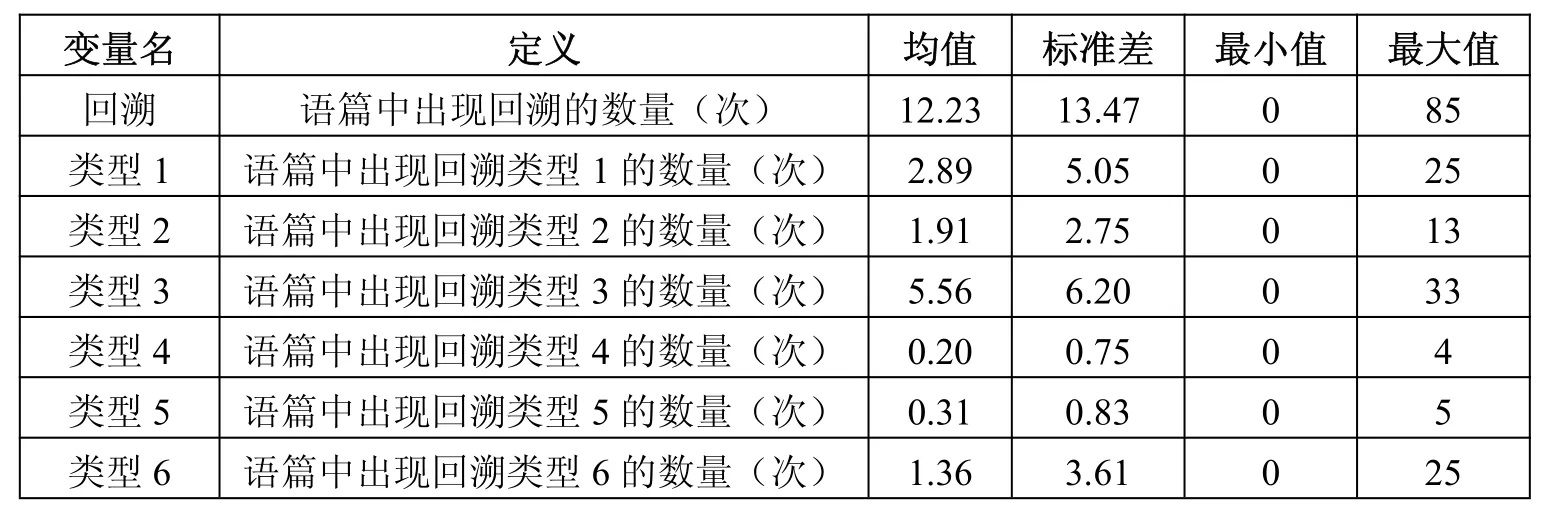
表2 回溯次数分布的统计分析表
从表2中的统计数据可以知道回溯在三个语体语篇中出现的总体平均次数为12次,次数分布标准差为13.47,这说明回溯在语料库里语篇的次数分布是离散的。这一结论从回溯出现的次数最小值为0,最大为85 也能反映出来。观察回溯具体表现类型的集中量数和离中量数可以发现,类型4 回溯是一个在自建语料库所有语体语篇中平均出现次数最低、分布最集中的回溯类型。与类型4 正好相反的是类型3,它是自建语料库中平均出现次数最多、最分散的一个。类型5 的平均值和标准差均比类型4 稍高一点,这说明它在自建语料库语篇中的次数分布比类型4 多,但也相对更分散。
对表1和表2的数据观察,不仅能够对回溯整体情况和各类型情况有比较深入的了解,也能够为进行统计分析时变量的选取和假设的建立提供参考依据。可以说对主要变量的统计数据进行描述性分析是进行假设检验的基础和必要步骤。
四、回溯范畴的统计分析
要想对回溯在语篇中总体次数分布的影响因素进行分析,或者试图找到导致类型4 和类型5 次数分布的原因,就要把回溯作为因变量,选取可能影响它的因素作为自变量,使用计量模型进行假设检验。
1 假设和变量的选取
与其他语篇范畴一样,至今学界都极少有对回溯进行实证分析的研究,也就无法找到相关经验用来借鉴,究竟有哪些因素会对回溯的次数分布产生影响,是个值得探索的问题。语篇元标注是语篇外部特征的体现,我们可以尝试把自建语料库元标注系统中能够使用的标注项都设定为回溯次数分布的影响因素。回溯范畴经常会被研究者与前瞻范畴联系在一起,这两个范畴之间大约存在着一定的影响关系。我们在以往的研究中发现语义独立片段范畴与回溯有非常显著的正相关关系,也就是说,语义独立片段也可能是影响回溯在语篇中次数分布的因素之一。有鉴于此,我们对回溯在语篇中总体次数分布影响因素的研究,可以通过验证如下三个假设来完成:假设一,回溯在语篇中的次数分布与语篇的功能范围有关,即语篇的语体特征会影响回溯的次数分布;假设二,回溯在语篇中的次数分布与前瞻及语义独立片段的次数分布相关,即回溯范畴与前瞻范畴、语义独立片段范畴具有相关性;假设三,在任意语体语篇中,语篇字数越多,出现回溯的次数也会越多,即在回溯出现次数的影响因素中,篇幅长短因素比功能语体的因素作用更大。
还可以尝试针对特定类型的回溯在语篇中分布次数的影响因素进行分析。在观察表2中各类型回溯的数据时我们发现,在回溯的所有具体类型中类型3 离中趋势最大,集中趋势也最大,即这种类型的回溯很集中的分散在某些个别语篇中,因此很值得详细研究一下它分布特征的影响因素。这样可以选取回溯的类型3 和类型2与类型1 进行具体个案对照研究,探讨它们各自分布特征的影响因素,这将有助于了解回溯各类型间分布特征影响因素的异同。
根据三个假设可以把前面提到的七个因素设为自变量,即功能范围、语篇来源、语篇字数、作者性别、语篇发表时间、语义独立片段出现的次数以及前瞻出现的次数。本研究中所有变量的定义和初步统计情况可见表3。
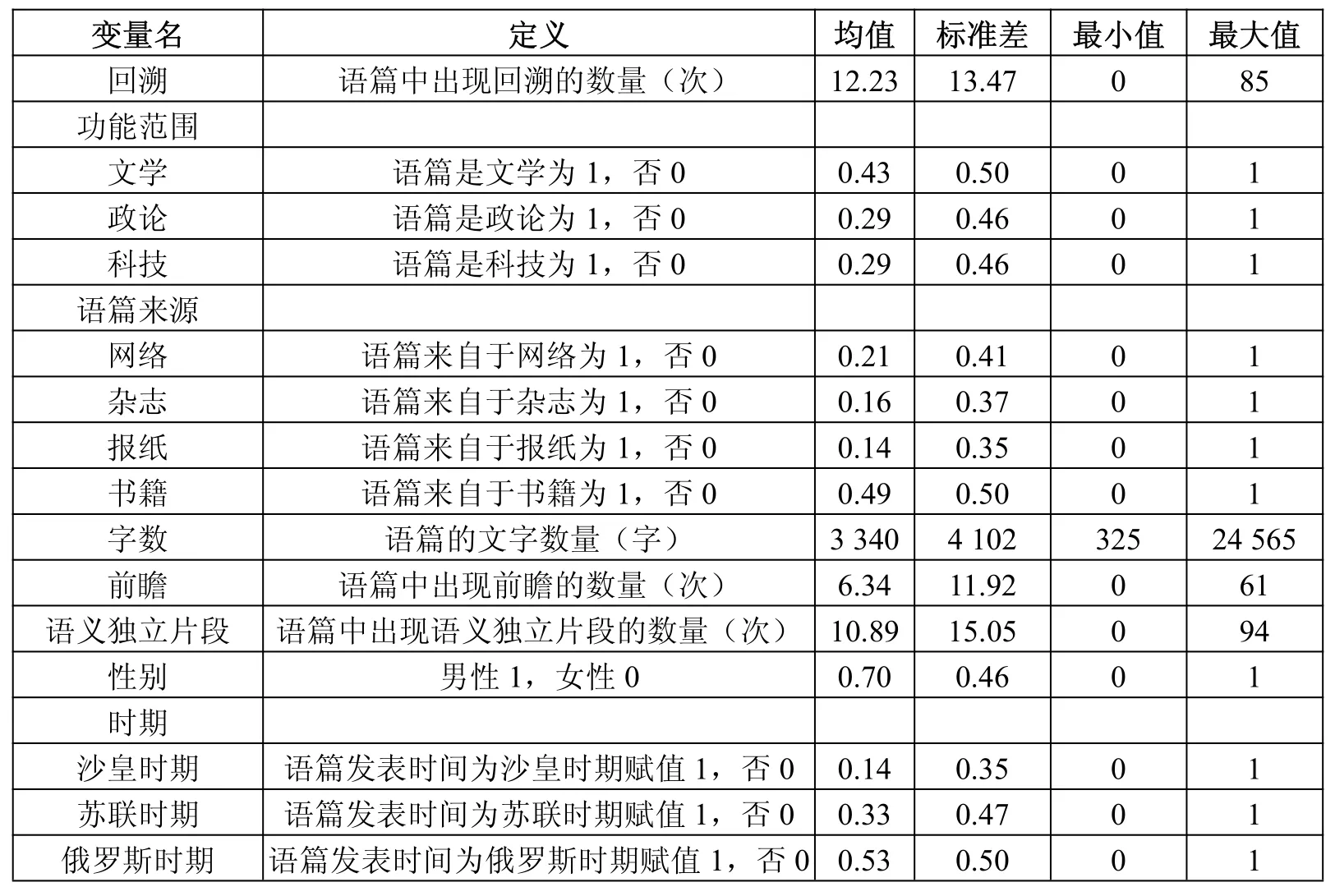
表3 回溯次数分布因素研究的变量描述
需要说明的是,在用STATA10.0 版本统计软件在计算机上进行计算之前,需要把每个称名型变量都转换为虚拟变量。我们把时期自变量进行了简单划分:1830-1922年为沙皇时期,1923-1991年为苏联时期,1992-2015年为俄罗斯时期②。
2 计量方法
回溯次数分布的影响因素分析可以使用广义的线性回归模型,并用普通最小二乘法进行参数估计。设符号HS 是模型中的因变量,表示回溯在语篇中出现的次数。把影响回溯在语篇中出现次数的因素设为X,作为模型中的自变量,根据广义的线性回归模型可以得到本项研究所需要的基本模型:
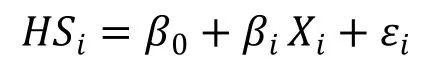
由于影响回溯次数分布的因素有七个,可以把它们分别代入基本模型,得到本研究所需要的拓展模型:
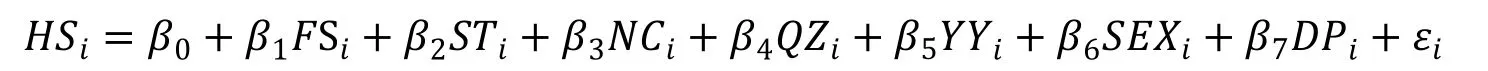
基本模型和拓展模型同时也可以作为回溯具体类型次数分布影响因素分析的基本模式和拓展模型。当基本模型作为回溯具体类型次数分布影响因素分析的基本模式时,模型左边的因变量HS 不再表示总回溯次数分布,而是表示类型1、类型2或类型3 在语篇中的次数分布,模型右边的因变量X,表示影响某类型回溯次数分布的影响因素。当拓展模型作为回溯具体类型次数分布影响因素分析的拓展模式时,模型右边各项中的,……仍然分别表示各影响因素的系数,只是这里的影响因素是指影响某类型回溯次数分布的因素。把拓展模型和所有原始数据输入10.0版本的STATA 软件后,利用计算机运算可以得到相应结果。
3 实证结果
总回溯次数分布影响因素的广义线性回归模型的计量结果如表2所示。样本观测值为70,说明自建语料库中全部三个语体的70 个语篇都参加了运算,样本是完全的。判定系数的值是0.686 0,说明建立的模型与样本数据之间的拟合程度比较好。
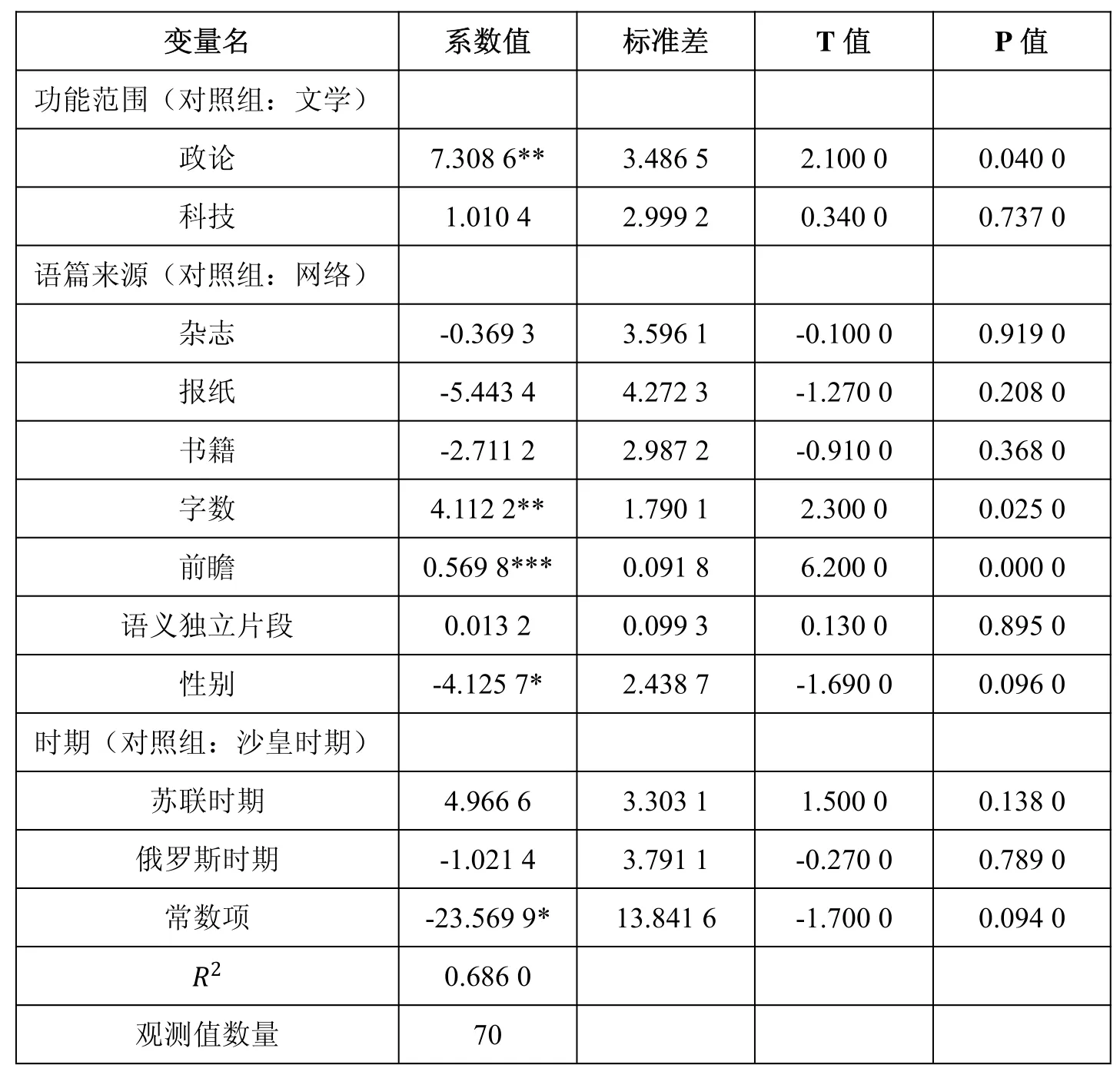
表4 总回溯次数分布影响因素的计量回归结果
根据前面设立的假设一,我们需要关注表4中的功能范围变量。在功能范围变量中,文学语体是对照组,政论语体与科技语体的系数值均为正,说明因变量与自变量之间正相关,即在总篇数固定、其他因素都不变的情况下,政论或/和科技语体的语篇越多,总的回溯次数也会越多,也就是说,在其他条件一致的情况下,文学语体语篇中的回溯次数比较少,政论和科技语体语篇中回溯出现的次数会比较多。观察它们对应的P 值可以发现,只有政论语体与因变量之间的正向相关系在10%、甚至是5%的显著水平上显著;而科技语体与总回溯次数的分布正向影响关系是不显著的。因此,我们可以得出结论,在其他条件不变、只有功能范围发生变化的情况下,总回溯的次数分布可能会因语篇三种语体配置的不同而不同,其中可以确定的是,在5%的显著水平上政论语体语篇的篇数越多,总回溯的次数也将越多。
为验证假设二,需要在表4中分别查看语义独立片段和前瞻两个自变量的情况。语义独立片段的系数值和P 值结果表明,它对总回溯次数分布的影响虽为正向但并不显著。前瞻变量的系数值和P 值结果说明,前瞻对总回溯次数的影响是正向的,而且是极度显著的。也就是说,在其他条件不变的情况下,语义独立片段出现次数的多少,对回溯出现次数没有多大影响;但前瞻出现次数的多少会极大影响回溯出现次数的多少,前瞻越多,回溯也会越多。
表4中的语篇字数变量结果表明,语篇字数与回溯次数分布呈正向影响关系,而且在5%的显著水平上显著。也就是说,在其他影响因素不变的条件下,在5%的显著水平上语篇的篇幅越长,回溯出现的次数也会越多。
回溯类型1(回忆性的回溯)次数分布影响因素的广义线性回归模型的计量结果如表5所示。样本观测值70,等于全部自建语料库的文本量;值为0.685 1,拟合度很好。
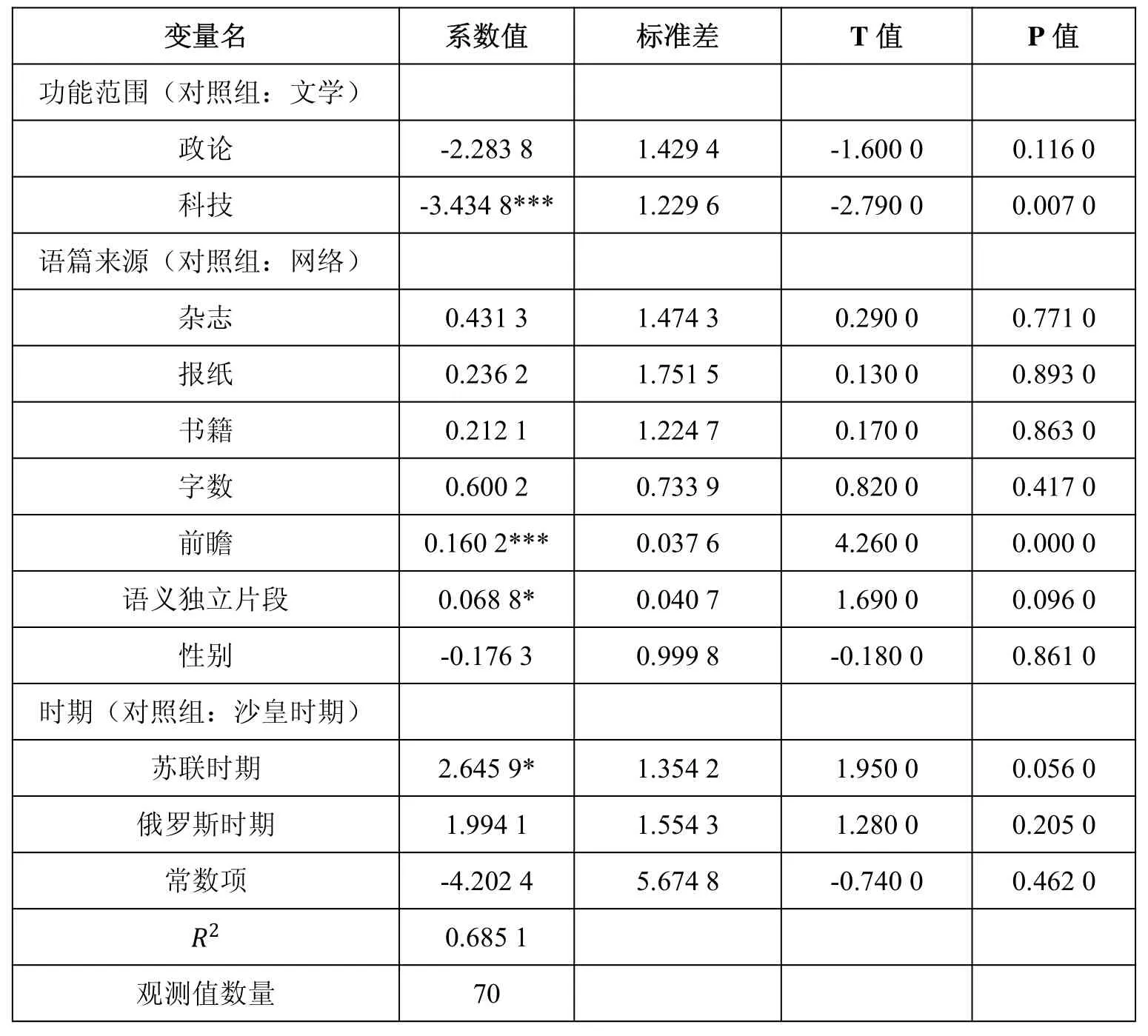
表5 回溯类型1(回忆性的回溯)的影响因素计量回归结果
首先需要观察表5中P 值小于0.1 的自变量,这样就可以先确定对类型1 次数分布有显著影响的因素。功能范围中P 值小于0.1 的是科技语体,且系数值为负,这说明在控制其他因素的条件下,科技语体的语篇越多,回忆性回溯出现的次数会越少,这一结论不仅在10%的显著水平上显著,甚至在1%的显著水平上显著。自变量前瞻的P 值是0.000 0,系数值为正,这说明在其他条件一定的情况下,前瞻出现的次数越多,回忆性回溯出现的次数也会越多,它也在1%的显著水平上显著。自变量语义独立片段的P 值表明,控制住其他变量时,语义独立片段出现的次数越多,回忆性回溯出现的次数也会越多。从表5中还可以观察到在时期变量中苏联时期的P 值也小于0.1,为0.056 0,系数值为正,这个结果说明在其他条件不变的情况下,发表时间属于苏联时期的语篇数量越多,回忆性回溯出现的次数也会越多。
回溯类型2(引述性的回溯)次数分布影响因素的广义线性回归模型的计量结果如表6所示。样本观测值数量70,值0.316 4,稍低,但“在社会科学中,回归方程中的过低是很正常的”,“一个看似很低的值并不意味着OLS 回归方程没有用”(伍德里奇,2010:38-39)。
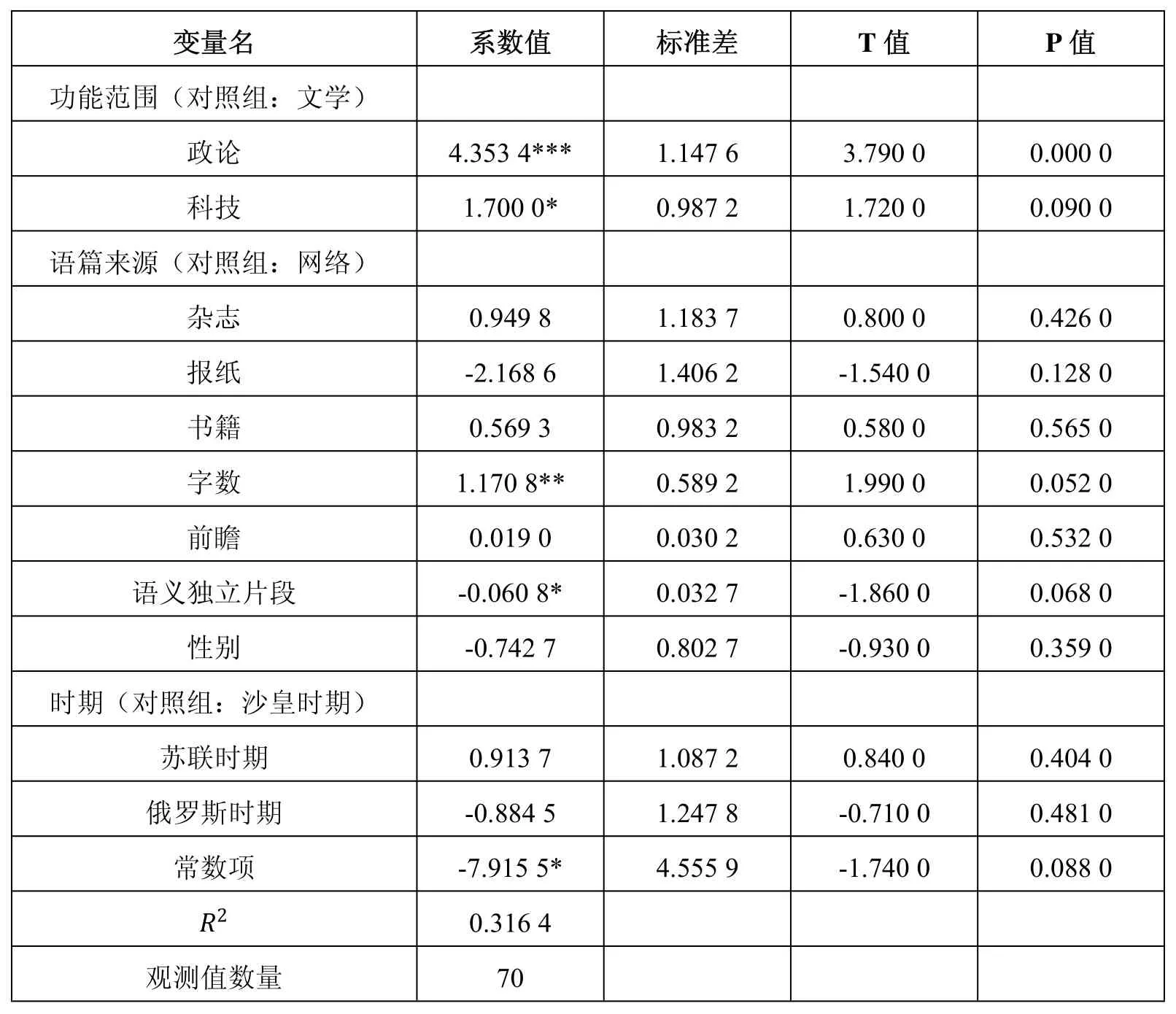
表6 回溯类型2(引述性的回溯)的影响因素计量回归结果
首先在表6中观察P 值小于0.1 的自变量,即先选定在10%的显著水平上对引述性回溯的次数分布有显著影响的因素。这样的自变量有四个:功能范围中的政论语体和科技语体、语篇字数以及语义独立片段。政论语体的P 值和系数值说明它甚至是在1%的显著水平上对类型2 回溯有正向的影响关系。科技语体的P 值为0.090 0,系数值为正,说明它在10%的显著水平上对类型2 回溯有正向影响关系。语篇字数的P 值和系数值结果表明,语篇字数与类型2 回溯在接近5%的显著水平上具有正相关关系,即在其他条件不变的情况下,语篇篇幅越长,引述性回溯出现的次数就会越多。语义独立片段变量的P 值为0.068 0,系数值为负,说明它与类型2 回溯在10%的显著水平上具有负相关关系,也就是说,在其他因素不变的条件下,语义独立片段越多,引述性回溯出现的次数反而会越少。我们还比较关注前瞻变量,它的系数值为正,但P 值为0.532 0,远大于0.1,即它虽然与引述性回溯有正向影响关系,但这种关系并不显著。回溯类型3(介绍性的回溯)次数分布影响因素的广义线性回归模型的计量结果如表4和5 所示。值为0.483 5,拟合优度一般,样本观测值数量为70。
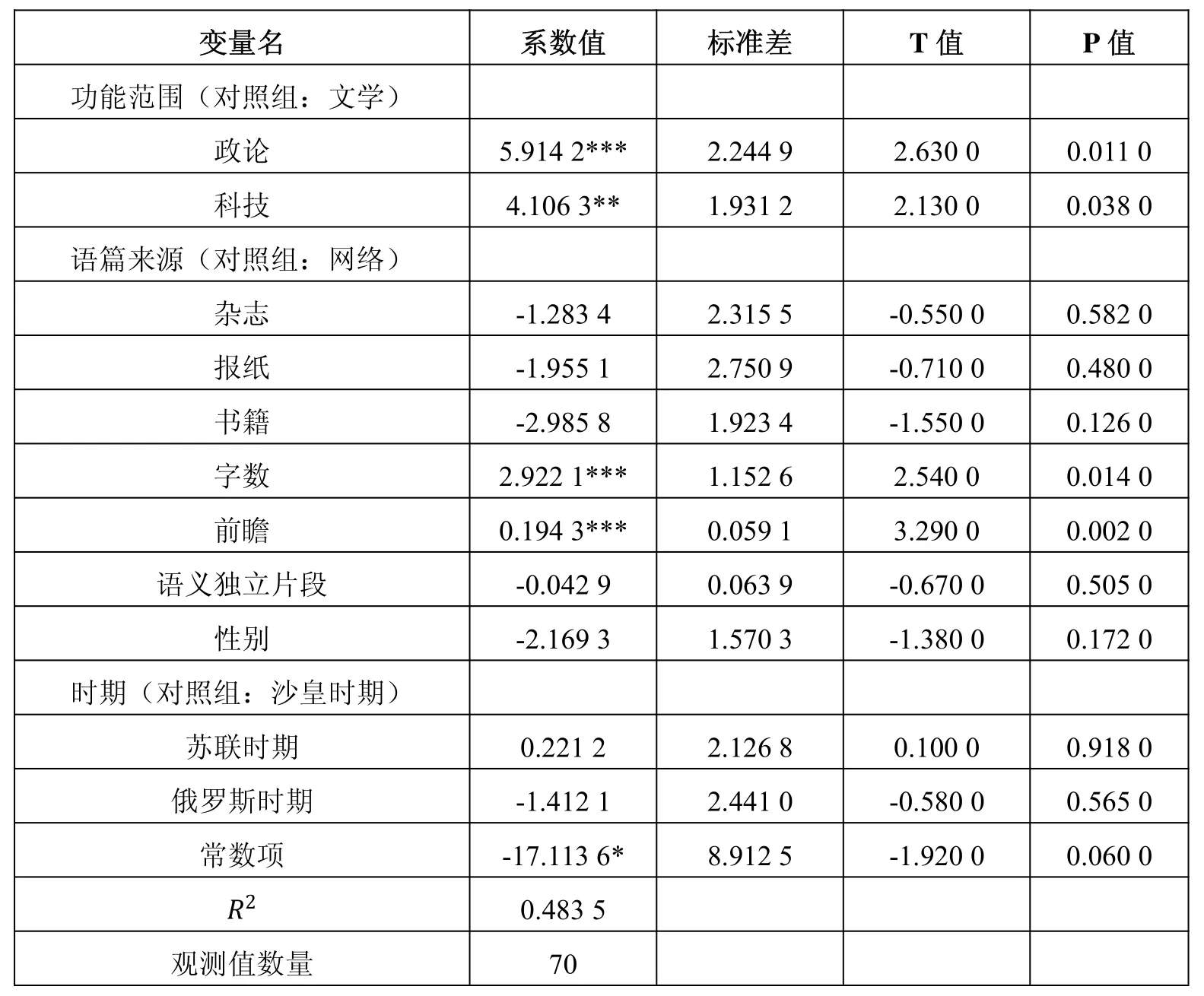
表7 回溯类型3(介绍性回溯)的影响因素计量回归结果
同样可以先在表7中观察P 值小于0.1 的自变量,即先选定在10%的显著水平上对介绍性回溯的次数分布有显著影响的因素。在表7中P 值小于0.1 的自变量有四个,分别为政论语体、科技语体、语篇字数以及前瞻。数据结果表明,政论语体在1%的显著水平对类型3 回溯有正向影响关系,科技语体与类型3 回溯的次数分布在5%的显著水平上存在正相关关系,语篇字数在1%的显著水平上对类型3 回溯有正向影响关系,前瞻与类型3 回溯的次数分布在1%的显著水平上具有正相关关系。
五、结论
通过对计量结果的解读和分析可以知道假设验证的结果。第一,在其他影响因素不变的条件下,政论语体的语篇数量越多,回溯出现的次数也将越多,也就是说,功能范围中的政论语体会影响回溯的次数分布,假设一成立;第二,在控制其他影响因素的条件下,前瞻出现的次数越多,回溯出现的次数也会越多,前瞻是影响回溯次数分布的重要因素之一,但语义独立片段却不是影响回溯次数出现的主要因素,它虽对回溯次数分布有正向的影响,但这种影响不显著,因此,假设二部分正确;第三,在其他条件一定的情况下,语篇的字数越多,回溯出现的次数也会越多,假设三成立。
通过表4可以分析出回溯范畴整体上在语篇中次数分布的显著影响因素情况,通过表5,6 和7 可以分别厘清回忆性回溯、引述性回溯以及介绍性回溯次数分布的显著影响因素。观察比较这些显著影响因素可以发现它们中有的是全部因变量的正向影响因素,如语篇字数;有的在各个自变量中不相同,如语义独立片段变量不是回溯总次数分布的显著影响因素,但它与回忆性回溯次数分布有显著的正向影响关系,与引述性回溯次数分布有显著的负向影响关系,与介绍性回溯的次数分布没有显著的影响关系。不同类型的回溯在次数分布特征上一定存在着与总体情况相一致的显著影响因素,但也会有自己独特的显著影响因素,即总体情况的显著影响因素与各类型的显著影响因素有同也有异。
利用语料库和计量软件对语篇层面上的特征范畴进行实证分析是一次有意义的尝试,它是语言学作为社会科学向理性的自然科学靠近的结果之一。语言是一个非常复杂的系统,语篇更是一个开放的体系。语言研究已经很好的与哲学、心理学、社会学、人类学、教育学甚至经济学等学科交叉融合,语篇的研究也可以从不同学科和角度切入,计量语篇研究也许有助于拓展人们对语篇研究的传统认知。
注释:
①结合Гальперин和我国学者史铁强和安利对回溯表现形式的类型划分,小型自建俄语语料库把回溯划分为六种类型,分别为类型1:回忆性的回溯;类型2:引述的话语或思想;类型3:介绍性的回溯;类型4:推断、揣测性的回溯;类型5:非现实性的回溯;类型6:关键性事物引起的回溯。
②时期划分的依据是苏联成立和解体的时间,苏联于1922年12月30日正式成立,1991年12月26日正式解体,以这两个时间点作为粗略划分俄罗斯历史分期的界限。
③FS,ST,NC,SEX 和DP 分别表示功能范围、语篇来源、语篇字数、语篇作者性别和语篇发表时间,是根据自建语料库的元标注系统确定的。QZ 和YY 分别表示前瞻和语义独立片段,是根据自建语料库的文本标注符号确定的。
猜你喜欢
话语研究论丛(2022年0期)2022-11-02 09:28:24
数学年刊A辑(中文版)(2021年1期)2021-06-09 09:32:00
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:42
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
中国修辞(2016年0期)2016-03-20 05:54:34
长江学术(2016年4期)2016-03-11 15:11:30
语言与翻译(2015年4期)2015-07-18 11:07:45
中国修辞(2015年0期)2015-02-01 07:07:26
西南学林(2013年2期)2013-11-12 12:59:14
