
基于注意力和字嵌入的中文医疗问答匹配方法
2019-08-27 02:26陈志豪余翔刘子辰邱大伟顾本刚
计算机应用 2019年6期
陈志豪 余翔 刘子辰 邱大伟 顾本刚


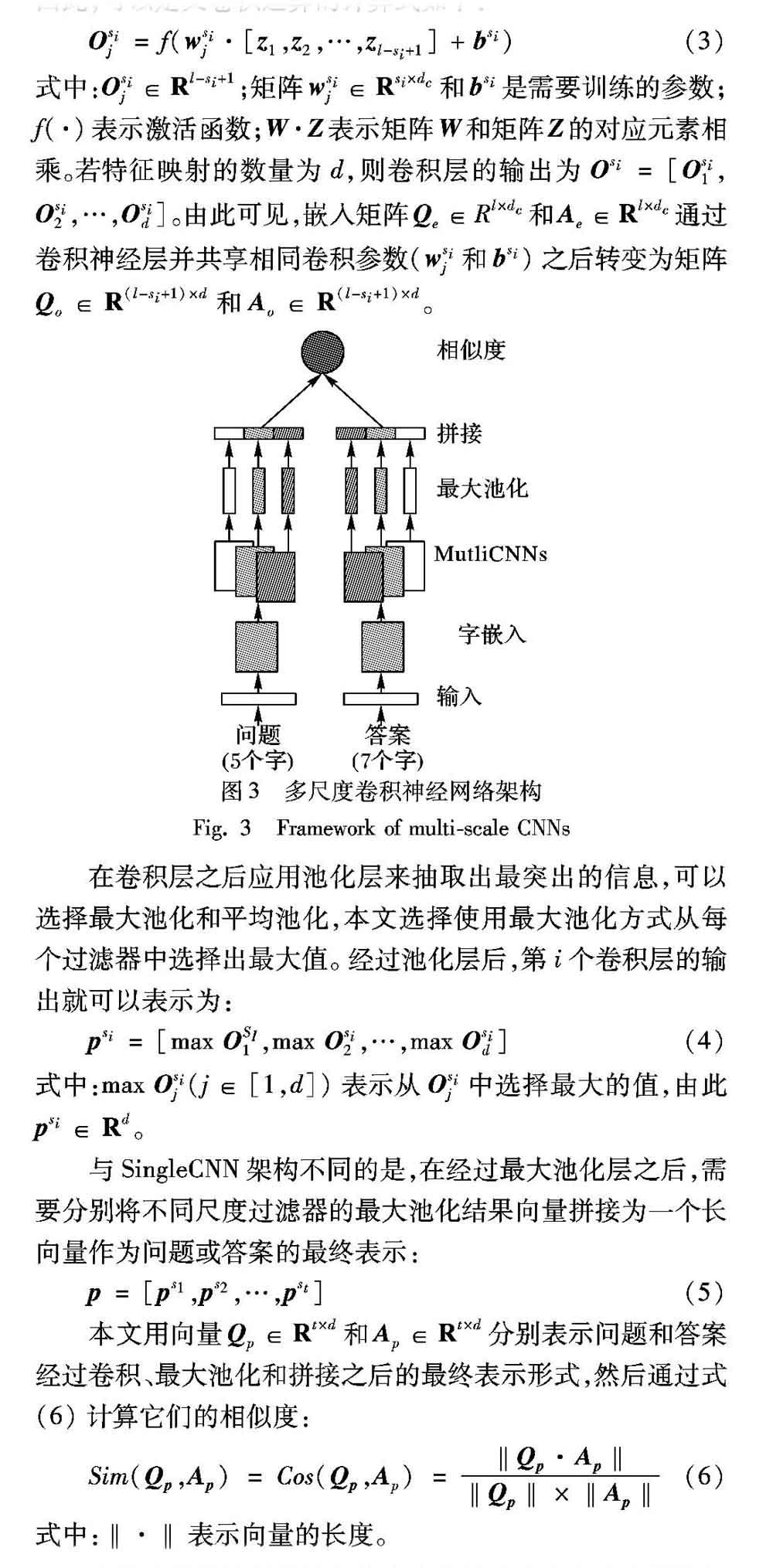
摘 要:针对当前的分词工具在中文医疗领域无法有效切分出所有医学术语,且特征工程需消耗大量人力成本的问题,提出了一种基于注意力机制和字嵌入的多尺度卷积神经网络建模方法。该方法使用字嵌入结合多尺度卷积神经网络用以提取问题句子和答案句子不同尺度的上下文信息,并引入注意力机制来强调问题和答案句子之间的相互影响,该方法能有效学习问题句子和正确答案句子之间的语义关系。由于中文医疗领域问答匹配任务没有标准的评测数据集,因此使用公开可用的中文医疗问答数据集(cMedQA)进行评测,实验结果表明该方法优于词匹配、字匹配和双向长短时记忆神经网络(BiLSTM)建模方法,并且Top-1准确率为65.43%。
关键词:自然语言处理;问答对匹配;卷积神经网络;字嵌入;注意力机制
中图分类号: TP183人工神经网络与计算
文献标志码:A
Abstract: Aiming at the problems that the current word segmentation tool can not effectively distinguish all medical terms in Chinese medical field, and feature engineering has high labor cost, a multi-scale Convolutional Neural Network (CNN) modeling method based on attention mechanism and character embedding was proposed. In the proposed method, character embedding was combined with multi-scale CNN to extract context information at different scales of question and answer sentences, and attention mechanism was introduced to emphasize the interaction between question sentences and answer sentences, meanwhile the semantic relationship between the question sentence and the correct answer sentence was able to be effectively learned. Since the question and answer matching task in Chinese medical field does not have a standard evaluation dataset, the proposed method was evaluated using the publicly available Chinese Medical Question and Answer dataset (cMedQA). The experimental results show that the proposed method is superior to word matching, character matching and Bi-directional Long Short-Term Memory network (BiLSTM) modeling method, and the Top-1 accuracy is 65.43 %.
Key words: natural language processing; question answer matching; Convolutional Neural Network (CNN); character embedding; attention mechanism
0 引言
随着互联网的快速发展,愈来愈多的人倾向于在健康医疗网站上提问来寻求健康帮助,例如中國的寻医问药网、39健康网和丁香园等。此类网站为患者和医生提供了一个在线交流的平台,便于用户随时随地获取高质量的医疗健康推荐。患者只需描述其自身的症状并发布问题,就能得到指定的医生或任意医生的回复和建议。然而,大多数情况下,许多用户提出的问题都相似,这一方面给医生专家带来了巨大的回复负担,另一方面延长了患者等待回复的时间。因此,为了提高用户体验,有必要设计一种方法来有效地处理医疗问答匹配的问题,即从已有的医疗答复记录中自动选择与用户问题匹配最佳的答复推荐给用户。
本文重点关注的是中文医疗问答匹配和答案选择的问题,其中所考虑的问答语言均限于中文。相比于Feng等[1]和Tan等[2]在英语语言环境下的开放领域问答匹配的研究,本文所讨论的问题更具挑战性,原因有两点:1)领域受限性质;2)中文语言具有一些特殊的特征。
进一步的讨论如下:
首先,由于汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此分词是大多数中文自然语言处理(Natural Language Processing, NLP)任务中不可或缺的数据预处理步骤,如词性标注(Part-of-Speech tagging, POS)和语义分析。由此可见,分词的准确与否大大影响了下游任务的准确性。尽管已有的分词工具(如:ICTCLAS、jieba和HanLP)的性能已经达到了满足大多数实际应用的水平,但它们一旦发生偏差,将通过管道不可避免的影响整个系统框架,导致整体性能下降[3]。此外,当直接应用于医学文本时,包含的各种医学术语会导致这些通用分词工具的性能进一步下降。例如,药物名称“活血止痛片”和“维生素C黄连上清片”被jieba分词工具错误的划分为了“活血 止痛 片”和“维生素 C 黄连 上 清 片”。尽管引入特定领域的词典可以减轻专业术语对分词的负面影响,但构建此类词典似乎总是令人望而却步,因为它涉及大量的手工劳动并需要大量特定领域的专业知识。更糟糕的是,在处理在线社区发布的未经编辑的问题和答案时,预定义的词典往往不合适。因为它们通常是以非正式的表达形式编写的,往往包含许多简写词和非标准的缩略词,甚至是错误的拼写和不合适的语法结构的句子。例如,问句“嘴骑魔拖车摔肿了怎么消下去现在还疼不能吃饭感觉越来越大也不能喝水”将“摩托车”误写成了“魔拖车”,另外全句没有任何标点符号,逻辑表达混乱。虽然,通用分词工具都能够加载定制的领域词典,但是定制词典需要耗费大量的人工时间,且定制的词典也不可能覆盖所有的领域词。
为了避免上述问题,提出采用字嵌入的端到端的神经网络框架。该框架采用的是字级的表示,即用字嵌入方式替代传统的词嵌入方式。此种方式既可以避免数据预处理时的分词步骤,也可以避免由分词错误引起的其他组件的性能下降。问题和答案的表示向量分别使用中文字进行预训练得到,并且类似于词嵌入,将每个字描述为固定长度的向量。
由于在中文语言中字所含的语义信息比词语的语义信息少,若采用统计方法则可能需要使用语言模型或词性标注等方式来抽取相关的语义信息。然而,卷积神经网络(Convolutional Neural Network, CNN)强调N-Gram内的本地交互,能够自动捕获字和词语的局部语义信息,无需其他方法辅助,因此本文引入CNN来构建模型。又因为中文词语或短语通常由2至5个字构成,所以采用多尺度卷积神经网络(Multi-scale CNNs, MultiCNNs)来提取不同尺度的上下文信息,由此可以更好地编码问题和答案。因此,本文提到的MultiCNNs模型由一组不同尺度的卷积核组成。
大多数之前的工作都是将问题和答案两个句子分别表示,很少考虑一个句子对另一个句子的影响。这忽略了两个句子在同一任务背景下的相互影响,也与人类在比较两个句子时的行为相矛盾。人们通常从另一个句子中提取与身份、同义词、反义词和其他关系相关的部分来找到一句话中的关键部分。受Yin等[4]提出的基于注意力(Attention)机制对句子对联合建模的方法的启发,本文引入Attention机制将问题和答案两个句子一起建模,用一个句子的内容来指导另一个句子的表示。因此,本文提出了基于注意力和字嵌入的卷积神经网络(CNNs based on Attention Mechanism and character embedding, AMCNNs)框架。
答案推荐是问答系统的目标。对于每个问题描述,答案候选池都包含100个候选答案,其中有一个或多个相关答案和多个不相关答案。问答匹配任务的目标就是从候选答案中找出精确度分数最高(Top-1)的一个答案,并将其推荐给用户。
1 国内外研究现状
本节简要介绍了与本文工作相关的两大类相关研究。首先,本文回顾以前关于传统问答的研究。接下来将概述深度学习应用于问答对匹配任务的情况。
1.1 传统问答方法
Jain等[5]提出了基于规则的医学领域问答系统架构,并详细讨论了基于规则的问题处理和答案检索的复杂性。然而,由于用户问题总是以大量不同的方式呈现,因此基于规则的方法可能无法涵盖所有表达方式。
Wang等[6]提出了另一种方法,首先将句子划分成单词以训练每个句子的词向量,然后通过计算每个单词之间的相似性来评估每个问答对的相似性。而Abacha等 [7]则是将问题翻译成机器可读的表示形式。 因此,该方法能够将各种自然语言表达问题转换为标准的表示形式。 后来,Abacha等 [8]通过在表示和查询层应用语义技术来扩展他们以前的工作,以便创建结构化查询以匹配知识库中的条目。这些方法取决于手工设计的模式和特征,需要巨大的人力和专业知识。
现有研究提出了一些关于中文问答的模型。 Li等[9]构建了一个用于音乐领域的语义匹配模型,能够自动将问题翻译成SPARQL查询语句来获得最终答案。Yin等[10]针对在线健康专家问答服务效率低下的问题,开发了用于对相似的问题和答案进行分组的分层聚类方法和用于检索相关答案的扩展相似性评估算法,用于从已有的专家答案中进一步提取出答案。然而,这些方法都将分词作为中文文本处理的必要步骤,虽然在一般领域中分词工具能达到研究者们的期望,但它们并未考虑误差所带来的影响。 Wang等[11] 提出了一种集成基于计数和基于嵌入的特征的方法;他们还在研究中指出,基于字的模型优于基于词的模型,从中得到启示:处理汉字可以避免分词错误带来的不利影响。
1.2 深度学习在问答匹配任务中的应用
近年来,由于深度学习技术无需任何语言工具、特征工程或其他资源,因此,愈来愈多的自然语言处理(NLP)任务都采用了该技术。
Feng等[1]设计了6个深度学习模型,并在保险领域进行了问答匹配的实验,该实验结果为其他问答匹配任务研究者提供了有价值的指导(例如,卷积层后不需要全连接层)。Hu等[12]提出了两种不同的卷积模型来学习句子的表示,这是使用神经网络解决一般句子匹配问题的先驱工作。之后,Feng等[1]和Zhou等[13]采用CNNs来学习问答对的表示,进一步用于计算不同问题与候选答案之间的相似性。后来,为了从句子中提取序列信息,Tan等[2,14]利用递归神经网络(Recurrent Neural Network, RNN)及其變体长短期记忆网络(Long Short-Term Memory network, LSTM)来学习句子级表示;值得注意的是,他们还利用注意力机制来增强问题和答案之间的语义关联。Yin等[4]设计了3种基于注意力机制的卷积神经网络(Attention-Based CNN, ABCNN)来建模问答对,并分别在答案选择(Answer Selection, AS)、释义识别(Paraphrase Identification, PI)和文本蕴含(Textual Entailment, TE)3个任务上进行了模型验证。Zhang等[15]提出端到端的字嵌入多尺度卷积神经网络模型,用于医疗领域的问答匹配任务。
但是,上述所有研究都与英文文本相关。当直接用于处理中文文档时,所提出方法的性能会出现相当大的下降,是由于中文与英文的结构有很大不同。
2 AMCNNs
本文将详细介绍用于中文医疗问答对匹配的多尺度卷积神经网络模型,其基于注意力机制和字嵌入。首先,本文讨论编码中文医疗文本的正确嵌入方式;其次,详细描述字嵌入多尺度卷积神经网络架构和本文提出的基于注意力机制的字嵌入多尺度神经网络架构。
2.1 字符的分布式表示
在许多自然语言处理任务中,一个基本的步骤就是将文本序列转换成机器可读的特征,该特征通常是固定长度的向量。
近年来,基于嵌入的方式在文本特征提取中得到了广泛应用,证明了它在语义表示上的效用。而用得最多的一种嵌入方式就是词嵌入(word-embedding)方式,也即分布式词表示。Bengio等[16]提出了一个神经网络语言模型(Neural Network Language Model, NNLM),它将神经网络与自然语言处理相结合以训练词嵌入。之后,Mikolov等[17]受NNLM的启发提出了一个非常高效的语言模型:Word2Vec。而且,近年来Word2Vec受到越来越多的关注并成功应用于许多NLP任务,例如句子匹配[18]、文档分类[19]和知识图谱抽取[20]。
2.2 多尺度卷积神经网络架构
目前,卷积神经网络因其能够捕获本地上下文信息的能力而在许多NLP任务中得到了应用。该网络不依赖于其他如词性标注或解析树之类的外部信息。通常,一个卷积神经网络架构由两部分组成:卷积和池化。卷积步骤利用固定大小的滑动窗口提取本地上下文特征,而池化步骤选择从前一层提取的特征的最大值或平均值以降低输出维度,但保留了最突出的信息。然而,单尺度卷积神经网络(Single-scale CNN, SingleCNN)架构只有一个固定卷积窗口的特征映射,也即它能捕获的信息很少。考虑到汉语短语的表达结构,SingleCNN架构可能不足以提取字信息。而多尺度的卷积神经网络(MultiCNNs)架构的工作方式与SingleCNN架构的工作方式相似,唯一不同之处在于采用了多个不同尺度的特征映射来提取信息。该架构如图3所示,问题和答案句子分别由固定长度的字符嵌入序列表示:[c1,c2,…,cl]。字向量的维度由dc表示,且向量中的每个元素都是实数,则cl∈Rdc。每个句子需要归一化为一个固定长度的序列,即若句子长度小于某个阈值就添加0补齐,相反若大于某个阈值就裁剪掉多余部分。经过字嵌入层后,每个问题和答案分别由矩阵Qe∈Rl×dc和Ae∈Rl×dc表示。
假设存在一个卷积核尺寸集合S={s1,s2,…,st},其中第i个卷积神经网络卷积核的尺寸表示为si。当给定序列Z=[z1,z2,…,zl-si+1],其中zi=[c1,c2,…,ci+si-1]表示句子中连续si个字向量拼接的结果,也即每个特征映射提取出的信息。因此,可以定义卷积运算的计算式如下:
2.3 基于注意力机制的多尺度卷积神经网络架构
基于注意力机制的多尺度卷积神经网络(AMCNNs)架构的工作方式与MultiCNNs相似,唯一不同之处在于两个句子经过嵌入层后会分别与注意力特征矩阵A相乘,得到一个注意力特征映射矩阵,并与经过嵌入层后得到的矩阵一起作为卷积层的输入。该架构如图5所示。由于考虑到两个句子在同一任务背景下的相互影响,因此用一个句子的内容来指导另一个句子的表示。
AMCNNs利用一个注意力特征矩阵A来影响卷积运算。注意力特征旨在对卷积中与问题(或答案)单位相关的答案(或问题)单位赋予更高的权重。如图5所示,矩阵A是通过左侧的字嵌入表示单元和右侧的字嵌入表示单元相匹配产生的。A中第i行的注意值表示sq的第i个单位相对于sa的注意力分布,A中第j列的注意值表示sa的第j个单位相对于sq的注意力分布。A可以视为sq(或sa)在行(或列)方向的新的嵌入表示,因为A的每一行(或列)是sq(或sa)上的一个字的新的特征向量。因此,将这个新的特征向量与字嵌入表示组合并将它们用作卷积运算的输入就有理可依了。通过将注意力特征矩阵A转换为图5中的两个与字嵌入表示相同格式的灰色矩阵来实现这一点。因此,卷积层的新输入具有每个句子的两个特征映射。
2.4 目标函数
给定一个问题qi,它的真实答案是a+i,而a-i是从候选答案池中随机选择的错误答案。一个有效的网络模型应该能够最大化Sim(qi,a+i),且最小化Sim(qi,a-i)。为了训练以上神经网络,本文采用文献[1,4,13,16-17]中的方法定义训练损失函数为:
3 数据集和实验设置
3.1 cMedQA数据集
当前在中文医疗领域问答匹配任务上没有标准的评测数据集,因此选择从专业的医疗健康网站上收集中文医疗问答数据集(Chinese Medical Question and Answer dataset, cMedQA)[15]。该数据集是一个基于中文医疗问答的公开可用的数据集,其中的問答数据收集于寻医问药网。问题通常是由用户提出,而答案来自于专业医生的可靠回复。通常一个问题会得到多个医生的回复,即一个问题有多个正确答案。
3.2 评价方法
3.3 基线模型
目前优秀的问答匹配模型都是基于英文语境,且面向开放领域问答,因此本文所描述模型不与它们进行比较,而是设计了一些基线模型用于实验效果对比,如下所示:
1)字匹配(Character Matching)。字匹配方式统计问题与答案中相同字的数量。
2)词匹配(Word Matching)。与字匹配相似,统计问题与答案中相同词语的数量。但是需要使用分词工具进行分词,因此本文选择了两种分词工具(Jieba和ICTCLAS)用以展示不同分词工具对模型性能的影响。
3)BM25。BM25(最佳匹配)是信息检索中的一种排序函数,该函数定义如下:
4)BiLSTM。Tan等[2]使用双向长短时记忆神经网络(Bi-directional LSTM, BiLSTM)来学习问题和答案的语义表示。BiLSTM是循环神经网络(RNN)的变体,能够捕获长文本序列的语义信息。
猜你喜欢
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
计算机应用(2016年12期)2017-01-13
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
电脑知识与技术(2016年10期)2016-06-16
