
基于可见/近红外高光谱成像技术的牛肉品种鉴别
2019-08-26 02:35王彩霞王松磊贺晓光
食品工业科技 2019年12期
王彩霞,王松磊,贺晓光,董 欢
(宁夏大学农学院,宁夏银川 750021)
牛肉味道鲜美,营养丰富,深受国内外市场的青睐。近年来,随着人们生活水平的不断提高以及膳食结构的日益科学化,消费者对牛肉品质和营养的要求越来越高。高品质牛肉鲜香细嫩,色泽红润,肌肉纹理清晰,蛋白质含量高,售价相对较高[1]。目前仍有不法商贩将低质量的牛肉假冒为高品质牛肉,以次充好,损害消费者利益。因此对不同品质的牛肉进行定性鉴别成为当前牛肉产业发展亟需解决的问题。不同品种的牛肉在品质和口感上存在很大的差异,但肉品性状和颜色极为相似,肉眼难以区分。传统的肉类鉴别方法有酶联免疫吸附[2]、蛋白质谱技术[3-5]、PCR[6]等,鉴别成本较高,操作繁琐,耗时耗力。因此,需研发一种高效快速、无损环保、操作简单的检测方法对牛肉的种类和品质进行鉴别。
高光谱成像技术作为一种新型无损检测技术,具有超多波段、高光谱分辨率和谱图合一等优势[7],在肉品分析领域得到了广泛的应用。Jiang等[8]利用Vis/NIR高光谱对鸡胸肉的嫩度进行分类研究,结果表明基于全光谱波段所建的偏最小二乘判别模型(Partial least squares discrimination analysis,PLS-DA)模型的校正集与预测集准确率分别为0.92、0.94;Xiong等[9]利用可见近红外高光谱对散养鸡和普通饲养方式下的及进行识别分析,并结合多元散射校正(Multiplicative scatter correction,MSC)进行预处理,建立基于连续投影算法(Successive projections algorithm,SPA)和径向基函数-支持向量机(RBF-SVM)的鸡肉判别模型,模型准确率高达93.33%;王昱陆[10]利用特征光谱建立的线性模型对牛肉、羊肉、猪肉进行品种识别,识别准确率分别为100%、94.1%、95.5%;王松磊等[11]使用高光谱成像技术对宁夏地区滩寒杂交、盐池滩羊、小尾寒羊三个品种羊肉进行识别,结果表明,不同波段高光谱对羊肉品种识别均有较好效果;王靖等[12]使用900~1700 nm高光谱成像系统对宁夏不同产地的羊肉进行品种识别,结果表明CARS-PLS-DA为最优模型,校正集正确率90.48%,预测集正确率84.21%。综上可知,已有学者利用高光谱成像技术对鸡肉、猪肉、羊肉以及掺假肉等进行鉴别分析,但对不同品种牛肉的鉴别鲜有报道。
本研究利用可见/近红外高光谱成像技术对不同品种的牛肉进行鉴别分析,并比较不同特征波长提取方法及建模方法对牛肉品种鉴别效果的影响,进而为牛肉品种的快速无损鉴别提供技术参考。
1 材料与方法
1.1 材料与仪器
3~5头5岁左右产奶率低的荷斯坦奶牛(母牛) 采自宁夏吴忠市涝河桥分割肉加工有限公司;3~5头3岁左右的秦川牛、西门塔尔牛(公母均有) 采自宁夏固原市宁夏尚农生物科技发展产业有限公司。
Hyper Spec-VNIR高光谱成像系统(包括Imspector N型成像光谱仪、G4-232增强型EMCCD相机、VT-80自动电控位移平台及2个卤素灯光源。其中,光谱分辨率2.8 nm,狭缝宽度25 μm,相机像素尺寸8.0 μm) 美国Headwall公司
1.2 实验方法
1.2.1 牛肉样本采集 各品种牛经屠宰后在0 ℃下冷藏,排酸48 h。取出牛肉样品进行分割,每个品种的牛分别取4个部位肉(肩颈肉、眼肉、瓜条肉、里脊肉),剔除多余的油脂和筋膜后,放入保温箱运至实验室,贮藏在4 ℃冷柜备用。其中,奶牛肉108个(脖肉、眼肉、瓜条肉、里脊肉各15、17、39、37个)、秦川牛肉117个(脖肉、眼肉、瓜条肉、里脊肉各16、16、40、45个)、西门塔尔牛肉样品各113个(脖肉、眼肉、瓜条肉、里脊肉各10、17、43、43个)个。光谱扫描前将肉样整形切块(大小约为40 mm×30 mm×10 mm),室温下放置2 h,待肉样中心温度达到室温水平后,用滤纸吸干样品表面的水分,进行光谱扫描。
1.2.2 高光谱图像采集 由于肉样本纹理形状、色泽等会造成光源漫反射,影响光谱信息采集效果。因此,图像采集时需设置合理的曝光时间和位移平台移动速度。经预试验最终确定牛肉样品的采集参数为:相机曝光时间:15 ms,物距:380 mm,电控位移平台移动速度:15 mms。
同时,由于光源强度分布不均及相机中暗电流的存在,使采集到的信息中含有大量噪声。因此在采集高光谱图像之前需进行黑白校正。具体方法为:开启高光谱系统,调整焦距和曝光时间,获取标准全反射白板的白图像Rw,然后盖住镜头,获取全黑图像Rd。根据式(1)计算出样本的校正图像I:
式(1)
其中:I为校正后的漫反射光谱图像;R为样本原始的漫反射光谱图像;Rd为全黑图像;RW为白板的漫反射图像。
图像采集前,需打开高光谱仪器预热30 min。试验过程中,每组取5块肉样依次置于电控位移平台上,进行光谱扫描。图像数据处理之前,利用ENVI 4.8软件选取整块肉表面作为感兴趣区域(Range of interest,ROI),计算ROI内的平均反射光谱,作为样本的反射光谱。
1.2.3 光谱数据预处理 在光谱采集过程中,由于试验样本、测定环境及仪器噪音等因素的影响,所采集的光谱数据中会夹杂一些无用信息,从而影响建模性能。因此,需要对原始光谱数据进行预处理。本试验通过卷积平滑(Savitzky-golay smoothing,SG)、区域归一化(Area normalize)、一阶导数(First derivative,FD)、基线校准(Baseline)、标准正态变量变换(Standard normal variate,SNV)、MSC方法[13]对原始光谱进行预处理。
1.2.4 样本划分 不同的样本划分方法对所建模型具有不同的预测性能。本试验尝试的样本划分方法有:随机法(Random select,RS)、选样本(Kennard-stone,KS)、光谱-理化值共生距离法(Sample set partitioning based on joint X-Y distances,SPXY)[14]及顺序划分法。
1.2.5 特征波长提取 由于牛肉样本的全波段光谱数据量大、信息混杂,且大量的光谱数据会造成模型复杂、计算量大等问题。因此,选用适当的特征波长提取方法可有效降低光谱数据的维度,减少运算量,提高模型稳健性和预测准确性[15]。本文选用应用竞争性自适应重加权算法(CARS)、连续投影算法(SPA)和无信息变量消除算法(UVE)CARS、SPA、UVE法提取特征波长[16-19]。
1.2.6 模型建立 本试验采用PLS-DA、KNN及RBF-SVM法建立牛肉品种鉴别模型。PLS-DA算法是在PLS回归算法基础上建立样本分类变量与光谱特征间的回归模型的分类方法。KNN算法是将一个样本在特征空间中的K个最相似或者最邻近的样本进行比较,样本中的大多数属于某一类则将该样本则归结为此类[20]。RBF-SVM法是基于统计学习理论提出的一种机器学习识别方法,对非线性及高维信息识别具有较好的处理能力。该算法的原理将向量映射到高维空间,构建一个超平面,进而建立合适的分隔超平面,使两个与之平行的超平面距离达到最大,从而解决复杂数据的分类及回归问题[21]。
1.3 数据处理
光谱数据预处理在The Unscrambler X 10.4中进行,其余算法在Matlab R2016a中实现。
2 结果与分析
2.1 光谱反射率曲线分析
3种牛肉的高光谱原始图像如图1所示。对3种牛肉样品的光谱数据取平均,得到的平均光谱曲线如图2所示。可以看出,不同品种牛肉的光谱曲线走势相似。在400~590 nm波段范围内,反射率较低。而在650~780 nm波段,光谱反射值较高。在可见光区域,牛肉中的肌红蛋白与血红蛋白相互作用,使其肉色呈现红色;在近红外区域,光谱吸收取决于物质分子基团中光子能量吸收与能级跃迁,不同物质具有特定的波长吸收组合,牛肉脂肪、蛋白及水分含量约占牛肉总质量的99%,因此光谱吸收主要与其本身所含的-OH,-CH和-NH2等基团密切相关。由图2可知,荷斯坦奶牛肉的反射率值明显低于秦川牛肉与西门塔尔牛肉,这可能是由于荷斯坦奶牛肉中三大营养物质的含量较其他两种牛肉较少,所含关键集团的数量也较少,因此反射率较低。秦川牛肉与西门塔尔牛肉在各个波段的反射率值接近,说明两种牛肉中所含关键官能团的数量相似。在部分波段范围内存在光谱交叉及重叠现象,但是在690~930 nm范围内,各波段反射率差异比较明显,这为牛肉品种的快速鉴别提供了大量信息。不同牛肉品种的光谱反射值差不同应归结为成分含量、组成结构及品质之间的差异,为光谱特征波长选择及不同品种牛肉识别提供理论分析依据。

图1 三种牛肉样品的高光谱扫描图像Fig.1 Hyperspectral scan image of 3 kinds beef samples

图2 牛肉样品平均光谱图Fig.2 Original average spectra of beef simples
2.2 预处理方法的选择
经不同预处理方法后建立PLS-DA模型,结果如表1所示。
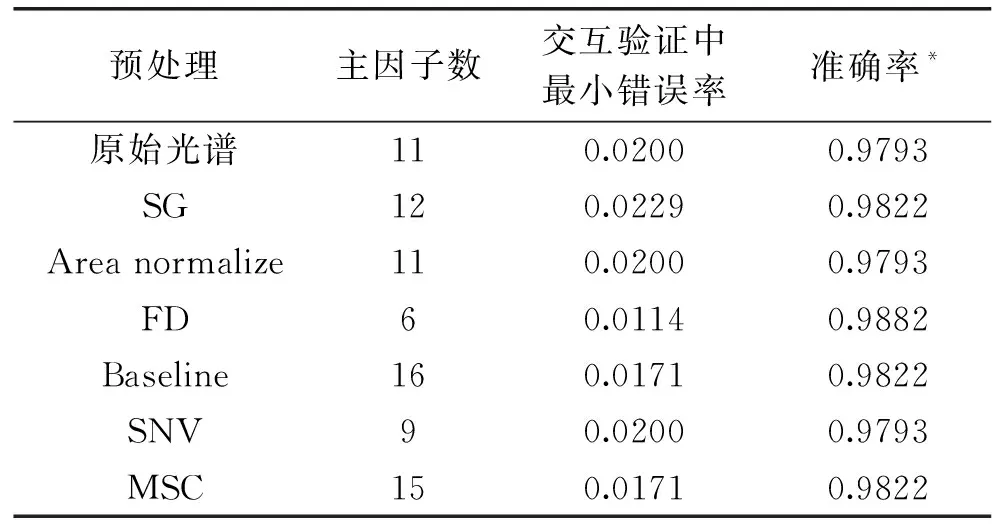
表1 不同预处理方法后的PLS-DA模型结果Table 1 Results of PLS-DA models by different pretreatment methods
由表1可知,经过FD法预处理后所建模型的交互验证中最小错误率小于原始光谱及其他预处理方法,其模型的准确率达到0.9882。且经过FD法预处理后所建的PLS-DA模型最优主成分数为6,低于原始光谱11,表明采用一阶导数预处理所建模型的准确性最好。故选择FD方法对原始光谱进行预处理。原始光谱图像及经FD法预处理后的如图3所示。由图可知,经FD法预处理后的光谱有效减了原始光谱的背景噪音和重叠现象。

图3 牛肉样本光谱曲线Fig.3 Spectrum curves of beef samples注:(a)为原始光谱图;(b)为FD法预处理后的光谱图。
2.3 样本集划分方法选择
样本集的划分方法在一定程度上决定了所建模型的优略性,本研究对四种常见的方法进行对比分析,进而优选出最佳样本划分方法。对牛肉样品进行取样时选择3/4样本作为校正集,剩余1/4作为预测集。其中,顺序法划分取每种样品的前3/4为校正集,后1/4为预测集。不同样本划分方法的预测准确率见表2。
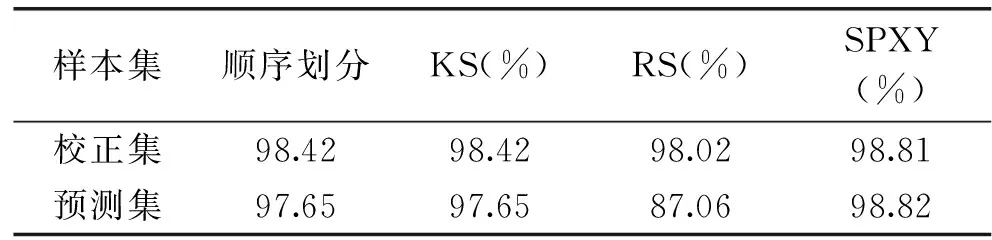
表2 不同样本划分方法的PLS-DA模型结果Table 2 Results of PLS-DA model by different sample partitioning methods
从表3可以看出,使用SPXY法进行样本划分,所建的模型的校正集与预测集的准确率均高于其他样本划分方法。因此,选用SPXY法进行样本划分,划分结果如表3所示。

表3 利用SPXY法划分样本结果Table 3 Results of sample partitioning by SPXY
2.4 特征波长提取
2.4.1 应用CARS提取特征波长 CARS算法的原理是从偏最小二乘(Partial least squares,PLS)模型中优选出回归系数权重大的波长点,并利用十折交叉验证选出校正集中交互验证均方根误差(Root mean square error of cross validation,RMSECV)最小的子集,将其作为最优组合。由于每次运行CARS的结果具有随机性,所以试验过程中在每个设定的蒙特卡洛采样次数下运行20次,取所建立的PLS-DA模型中最小的RMSECV值,即为最优变量。经过试验,最终设定CARS参数为:蒙特卡洛采样次数50,主成分数20,交叉验证组数10。牛肉品种鉴别筛选过程如图4所示。

图4 CARS方法特征波长筛选过程Fig.4 Process of CARS characteristic wavelength selection
由图4a可知,变量数与运行次数之间呈指数关系递减,表示波长变量选择分为“粗选”与“精选”两个过程[22]。图4b表示筛选过程中均方根误差的变化,由图可知,当采样次数为11时,交互验证均方根误差达到最小值0.2679。图4c是各变量在采样过程中回归系数的变化路径,“*”所对应的位置为第11次采样保留下来的变量,此时交互验证误差达到最小。分析可知,CARS法挑选出的关键变量共24个,分别为:410.9、415.7、444.6、449.4、487.8、497.4、516.6、531.0、550.2、598.3、603.0、612.6、622.0、627.0、684.6、799.9、804.7、910.3、939.1、958.3、963.1、982.3、987.1、991.9 nm。利用CARS优选出的特征波长占全部波长的19.2%。
2.4.2 应用SPA提取特征波长 由图5可知,特征波长数在17之前时,RMSECV处于明显下降状态,之后随着波长数的增加,RMSEC处于较平稳的变化状态。当波长数为17时,RMSECV=0.3312。表明特征波长所含牛肉品种差异信息与真实值之间具有较高的一致性。利用SPA法所选的特征波长为439.8、444.6、454.2、459.0、463.8、468.6、497.4、502.2、511.8、516.6、521.4、526.2、535.8、540.6、545.4、550.2、564.6 nm。利用SPA法优选出的特征波长占全部波长的13.6%。

图5 SPA方法提取特征波长Fig.5 Extracting the characteristic wavelengths using SPA
2.4.3 应用UVE提取特征波长 应用UVE提取特征波长时,先根据RMSECV最小确定PLS的最佳主成分数。本研究中当主成分数为19时,所对应的RMSECV值最小为0.1732,因此,确定最佳主成分数为19。运行UVE计算125个输入变量和随机变量的稳定性结果如图6所示。
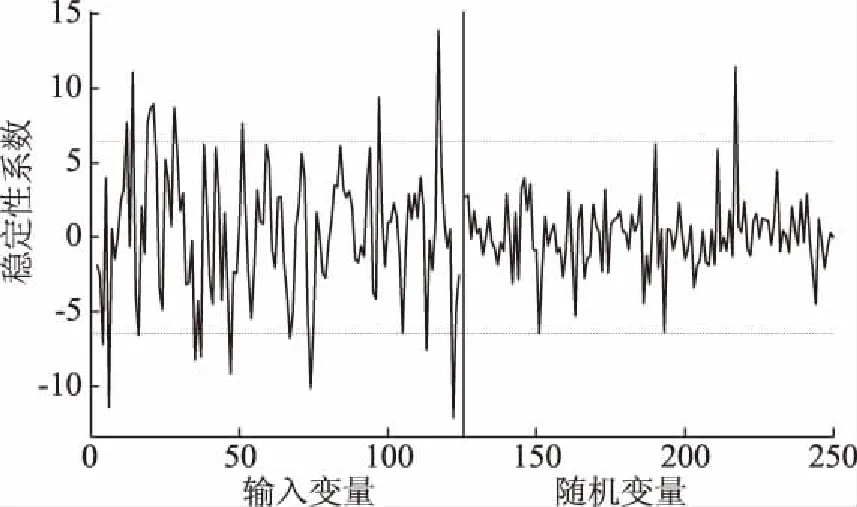
图6 UVE方法筛选变量Fig.6 Extracting the characteristic wavelengths using UVE
图6中竖线左侧为全光谱(Full spectra,FS)条件下的125个波长变量,右侧为125个随机变量。两条水平虚线之外的变量所对应的波长为有效波长,虚线之内的变量为无用变量。UVE法共选取的19个特征波长,分别为:415.7、425.4、454.2、463.8、473.4、487.8、492.6、497.4、531.0、564.6、574.2、622.2、641.4、718.2、751.9、863.2、939.1、958.3、982.3 nm。利用UVE提取出的特征波长占总波长的15.2%。
2.4.4 不同方法提取特征波长的结果比较 对不同方法提取的特征波长进行比较,结果如下表4所示。

表4 3种特征波长提取方法结果比较Table 4 Comparison of extracting the characteristic wavelengths by three methods
由表4可知,SPA法提取出的特征波长数目最少,只占全波段的13.6%,CARS法提取的波长数目最多为24个,但也只占到全波段的19.2%。
对三种不同方法提取的特征波长进行分析对比,结果发现,优选出的特征波长主要集中在光谱吸收较强且反射率较低的410~550 nm波段。
2.5 建模方法及建模结果的比较分析
2.5.1 建模参数的设定 KNN算法中K值的确定十分关键。K值的大小不仅会影响模型的稳定性,同时对模型的预测效果也有很大的干扰[23]。试验中将最大主成分数设定为10,利用马氏距离算法[24]并进行数据归一化处理,采用百叶窗交互验证[25],设置交互验证组数为10,原始光谱的交互验证错误率随主成分数的变化如图7所示。

图7 KNN算法中K值选择Fig.7 K values selection for KNN algorithm
图7为全光谱交互验证的错误率与K值大小的分布图,根据交互验证错误率最低确定K值,由图7可知,当K=6时,交互验证错误率达到最低值,所以选择K=6时建立KNN模型。同理可得,CARS、SPA、UVE的K值,结果如表5所示。

表5 KNN和PLS-DA建模参数的设定Table 5 Modeling parameters of KNN and PLS-DA
在建立PLS-DA模型时,需确定模型的最佳主成分数。试验中将最大主成分数设定为20,进行数据归一化处理,并采用百叶窗交互验证,设置交互验证组数为10,原始光谱的交互验证误判率随主成分数的变化如图8所示。从图8中可以看出,在主成分数为6时误判率为0.015,之后随主成分数的上升误判率缓慢增大,当主成分数达到19时,错误率达到最低为0.011,但仍将6确定为最优主成分数。以此类推,可确定CARS、SPA、UVE特征波长的最佳主成分数,分别建立对应的PLS-DA模型,结果如表5所示。

图8 交互验证中不同主成分下的错误率Fig.8 Error rate of different principal components in cross validation
建立SVM模型时首先需要确定核函数类型、惩罚因子c和核参数g,本研究选用径向基函数支持向量机(RBF-SVM)[26]。RBF-SVM模型的性能由参数c和g共同决定。经寻优对比,采用5折交叉验证方法确定c和g。先粗略设置参数c和g,接着利用网格搜索法进一步确定取值范围,然后计算RMSECV,根据最小RMSECV确定最优的c、g值。不同变量筛选下的最优c和g值如表6所示。
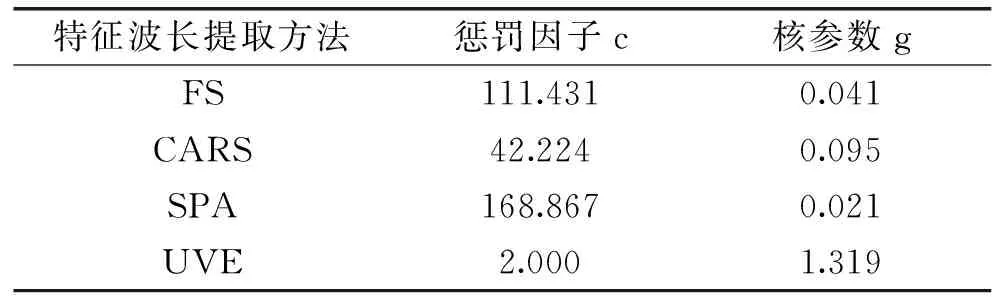
表6 不同变量选择方法下SVM模型参数Table 6 Parameters of SVM with different variable selection methods
2.5.2 建模结果 经FD法预处理后的光谱数据,分别建立基于全部波段及3种特征波长提取波段下的KNN、PLS-DA及RBF-SVM牛肉品种鉴别模型,并对模型效果进行比较分析。所建模型结果如表7所示。

表7 3个品种牛肉的鉴别准确率Table 7 Identification accuracy of three beef breeds
由表7可知,基于3种特征波长提取方法建立的KNN、PLS-DA及RBF-SVM模型中校正集与预测集的正确率均大于90%,说明3种特征波长提取方法所建模型稳定性和预测能力较好。对比三种模型发现,RBF-SVM建模效果优于KNN及PLS-DA。在KNN模型中,FS-KNN校正集模型有63个样本被误判,鉴别正确率最低。SPA-KNN模型的校正集与预测集的鉴别准确率分别为95.65%、94.12%,分别有11、5个样本被误判,表明SPA-KNN模型效果较好。在PLS-DA判别模型中,FS-PLS-DA模型对校正集与预测集的准确率分别为98.81%和98.82%,分别有3、1个样品发生误判;基于CARS与SPA所建PLS-DA模型对校正集的鉴别准确率分别为97.63%、97.23%,各有6、7个样品被误判,预测集准确率CARS高于SPA。CARS-PLS-DA模型的校正集与预测集准确率分别为97.63%、95.29%,略低于基于全波段所建的模型,校正集与预测集中分别有6、4个秦川样本被误判。在RBF-SVM建模结果中,除SPA法外,其他3种方法所建模型的校正集准确率均为100%。
综上可知,在特征变量选择方法中,CARS法优于SPA和UVE法,得到的14个特征波长包含了大量的有用信息,可以代替全光谱建模。RBF-SVM法所建模型效果明显优于PLS-DA及KNN算法,CARS-RBF-SVM模型结果最佳,鉴别结果图如图9所示。

图9 CARS-RBF-SVM法对三种牛肉分类鉴别结果Fig.9 Discrimination results for 3 kinds of beef sample under CARS-RBF-SVM
由图9可知,CARS-RBF-SVM法对三种牛肉分类鉴别中,校正集准确率为100%,预测集准确率为98.82%,其中有一个秦川牛肉被误判为西门塔尔牛肉。此结果与表7中的结果一致。
3 结论
本文利用近红外高光谱技术对不同牛肉品种进行鉴别研究。利用400~1000 nm高光谱系统采集3种牛肉样本的高光谱图像,分别提取其光谱信息,对比分析不同的光谱预处理方法,优选出FD预处理方法;并采用4种样本分类方法对数据进行分类,优选出SPXY法划分样品;然后对光谱数据进行特征变量选择,应用CARS、SPA、UVE算法提取的特征波长分别为14、17、19个;分别建立基于全波段和特征波长下的PLS-DA、KNN和RBF-SVM牛肉鉴别模型,优选CARS法提取的14个特征波长特征变量选择效果最好,提高了模型的稳定性和准确性,CARS-RBF-SVM模型的校正集与预测集准确率分别为100%、98.82%,具有较好的鉴别效果,且能大幅降低冗余信息,为牛肉品种快速无损鉴别提供理论依据。
猜你喜欢
阅读(科学探秘)(2021年8期)2021-09-01
趣味(语文)(2021年11期)2021-03-09
国学(2020年1期)2020-06-29
海峡姐妹(2020年4期)2020-05-30
海峡姐妹(2019年4期)2019-06-18
中国医学影像学杂志(2018年9期)2018-10-17
摄影之友(影像视觉)(2017年10期)2017-11-07
摄影之友(影像视觉)(2017年1期)2017-07-18
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
