
面向军事信息服务的智能推荐技术
2019-08-21 08:44王中伟裘杭萍寇大磊
指挥控制与仿真 2019年4期
王中伟,裘杭萍,孙 毅,寇大磊
(中国人民解放军陆军工程大学,江苏 南京 210007)
随着信息技术的飞速发展,网络信息呈现出爆炸的现象,需要寻找有效的方法来解决信息的精准服务问题。而在军事领域,随着我军侦察装备的换代和通信网络的升级,军事信息的收集和获取能力大幅提高。军事信息呈现出积累快、来源广、异构性和数量大的特性。寻找相应的方法对军事信息进行快速识别筛选,并在合适的时空条件下推荐给合适的信息使用方,切实将信息优势转化为战斗力,是一个极具意义的研究课题。
目前,解决信息爆炸问题有两种主要方法:一种是搜索引擎,例如以谷歌、百度等为主的搜索引擎,可以方便用户快速检索出包含自己感兴趣关键词的内容,但其存在检索结果不准确和单一化的缺点;另一种方法是推荐技术,可以针对用户独有的特点进行个性化和多元化的推荐,是一种较为有效的解决方法。
鞠亮等基于网络环境提出并构建了军事情报信息智能获取方法和利用方式[1];秦树鑫等提出了一种用户相关智能化搜集整合系统[2];马建威围绕海量军事信息,利用过程中的热难点问题,主要研究了军事信息的特征捕获和军事信息资源智能挖掘与汇聚方法,为军事信息资源的精准保障提供了技术支持[3];蔡飞以数据挖掘技术为支撑,围绕军事信息检索和查询推荐所面临的理论问题和技术难点,展开了深入研究[4];黄震华等对基于排序的民用推荐算法进行了总结[5];赵子慧等设计了基于用户浏览模式的新闻推荐系统[6];Liu J等基于位置感知和个性化协同过滤算法,设计了一种Web服务推荐方法[7]。综合看来,目前推荐技术在民用领域研究较为深入,而在军事信息服务的智能推荐研究上偏少,仅仅是针对某些具体的技术作了一些研究,没有形成系统性和整体性的研究。
1 推荐技术简介
推荐技术最早出现在电子商务领域,主要是利用电子商务网站,模拟销售员向客户提供购买商品建议的技术。推荐技术主要包括三个重要的方面,分别是:用户建模技术、对象建模技术和推荐算法。
通用的推荐流程[8]如图1所示,首先是对用户偏好特征的获取,进而通过计算建立用户模型和推荐对象模型,最后依据推荐算法计算出不同用户和对象间的相似度,根据相似度值的大小对用户进行信息推荐。
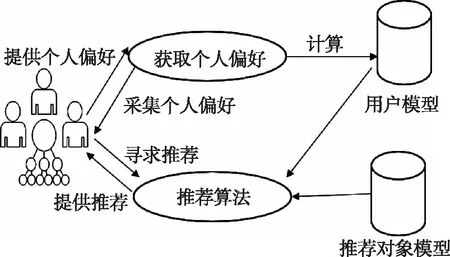
图1 推荐流程图
推荐流程的形式化表示为:设U为所有用户集合(如成千上万的作战人员),O为所有待推荐对象的集合(如成千上万的军事信息文档),f()为相似度函数,推荐的意义就是寻找每个用户对应的满足相似度值排前n个的推荐对象集S′,即
∀c∈C,S′=aggregate Topnf()
(1)
2 关键推荐技术分析
2.1 用户建模技术
对于不同的军事信息用户,其关注的军事信息内容是不同的。在进行军事信息的智能推荐之前需要先对军事信息用户进行特征建模,用以描述不同军事用户的信息偏好。用户建模的过程图如图2所示。
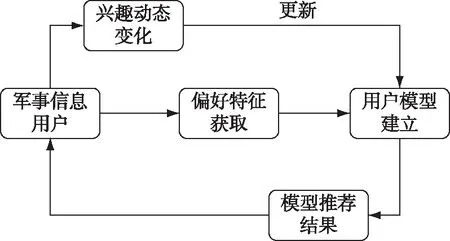
图2 用户建模过程图
军事信息用户的偏好特征模型S可以表示为m个显性特征Sd(如姓名、角色等)和n个隐性特征Sr(如作战计划、战场态势等),进一步,特征模型可以表示为m+n元组,如式(2)所示。
S=Sd+Sr={d1,d2, …,dm,r1,r2, …,rn}
(2)
对于用户的显性特征可以通过用户注册填写或个性化标签设定等主动方式获取,该方式的优点是简单高效,能够快速定位用户偏好;缺点是浪费用户浏览时间,泄露用户隐私信息。对于用户的隐性特征,主要是通过数据挖掘技术,对用户的浏览行为数据进行分析挖掘,从而得到用户潜在的偏好特征。该方式的优点是节省用户浏览时间,挖掘出用户潜在的一些独特偏好,缺点是分析结果未必理想准确,可能出现与实际不符的现象。
由于军事用户的特殊性,导致其偏好是动态变化的,因此还要考虑区分用户的长期偏好特征和短期偏好特征。以作战人员为例,平时可能关注更多的是关于训练动态的信息,战时可能关注的更多是关于战场作战的信息。在构建军事信息用户偏好特征模型时应加入情景(如时间、地点、天气、需求等)特征,基于用户的情景感知进行智能推荐,将合适的信息在合适的情境下推荐给合适的用户。情景感知需要对情景进行建模,可以采用逻辑模型(用规则表示)、本体模型(对客观存在进行抽象)、图模型(UML建模)等方法来实现。
2.2 对象建模技术
对不同的军事信息对象进行推荐时,用到的对象建模方法也就不同。常见的军事信息对象主要以文本类为主,此外还有图像、视频、音频等。因此,对于不同类别的推荐对象要分别建模。
对于文本类推荐对象,可以采用基于内容的建模方法,利用关键词抽取算法对文本内容进行关键词抽取,基于文本内容对应的关键词进行相似度计算,进而判断文本间的相似性。目前可用的关键词抽取方法主要有TF-IDF算法、TextRank算法、LSA/LSI算法和LDA算法。
1) TF-IDF算法[9]
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率算法)是一种基于统计的计算方法,常用于文档集中一个词对某份文档的重要程度。计算方法如式(3)(4)(5)所示。

(3)

(4)
TF-IDF=词频(TF)*逆文档频率(IDF)
(5)
2) TextRank算法[10]
TextRank算法的基本思想源自于谷歌的PageRank算法,主要用于文本关键词抽取。它的优点是可以不依靠语料库,具有较高的独立性。通过对某一文本内容的单独分析,就可以实现关键词的自动提取。其基本原理是将文本划分成若干语句,基于句子组成成分分析,利用图模型对单词重要性进行排序,最后,选择出Topn个词语作为该文本内容的关键词。算法步骤如下:
Step 1 对给定的文本T按照完整句子分割,即
T=[S1,S2, …,Sm]
(6)
Step 2 将分割好的句子进行词语划分,并为划分好的词语进行词性标注。然后,将停用词去除,只留下选定词性的词语,如动词、名词、形容词等。式(7)中ti,n是筛选后的候选关键词;
Si=[ti,1,ti,2, …,ti,n]
(7)
Step 3 构造候选关键词图模型G=(V,E),其中V是由式(7)产生的候选关键词构成的节点集。然后通过共现关系(Co-Occurrence)构造图中每两节点之间的边。当两个节点对应的单词都出现在长度为N的窗口中时,才认为它们之间存在边。其中,N为窗口大小,即最多允许同时出现N个单词;
Step 4 根据上面的步骤,重复迭代并更新各节点的权重,直到最后收敛;
Step 5 将节点权重按照由大到小的顺序进行排序,选择出前面的M个单词,就成为候选关键词;
Step 6 由得到的M个候选关键词,在原始文本中进行标记,如果可以形成相邻词组,便组合成多词关键词。
3) LSA/LSI算法[11]
LSA,其全称为Latent Semantic Analysis。 LSI,其全称为Latent Semantic Index。两者可以认为是同一种算法,但又有些区别。相同点是都要统计大量文本集,对文本的潜在语义进行分析。不同点是LSI还会在统计分析结果的基础上创建相关的索引。主要算法步骤如下:
Step 1 分析文本集,使用BOW模型将每个文本表示为向量;
Step 2 将所有的文本词向量拼接起来构成词-文本矩阵(m*n);
Step 3 通过奇异值分解(SVD)将词-文本矩阵进行矩阵分解([m*r]. [r*r]. [r*n]);
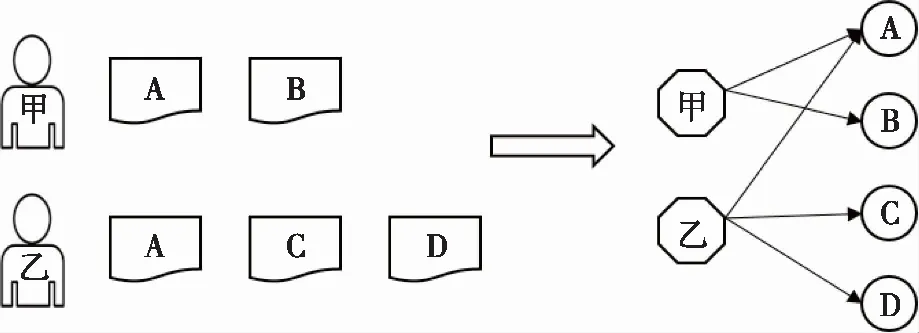
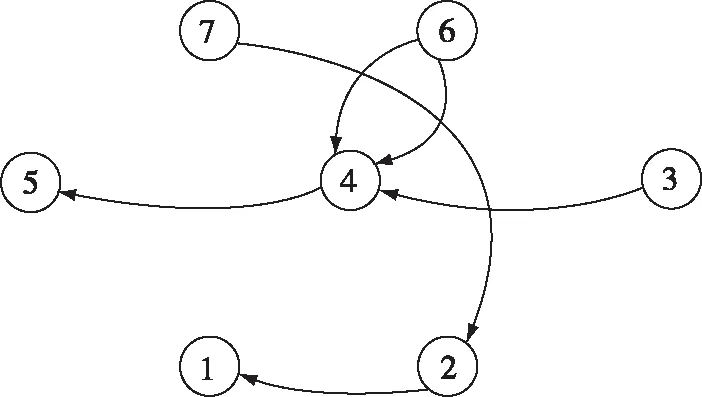
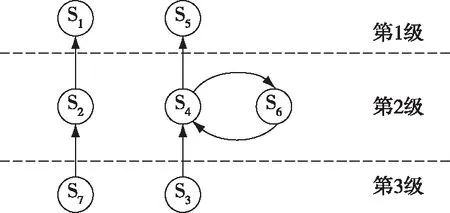
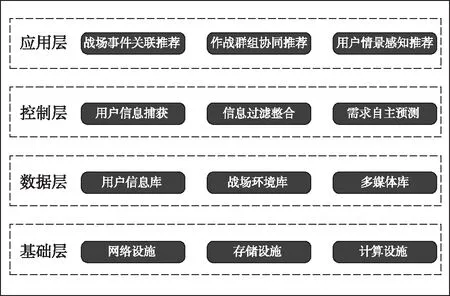
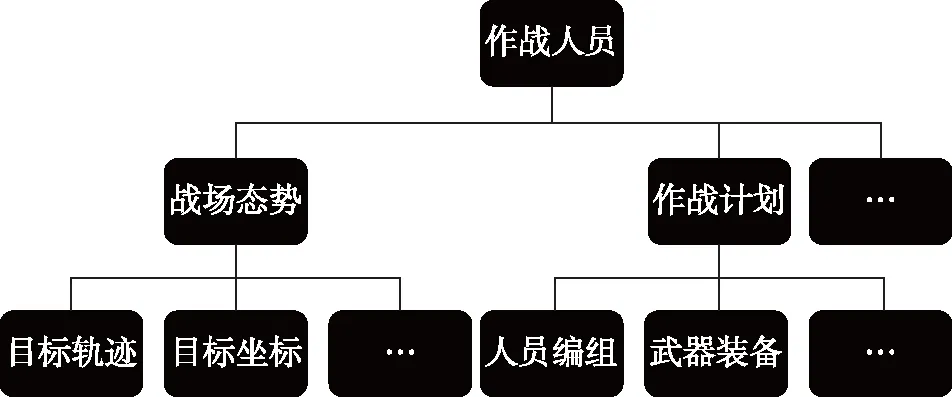
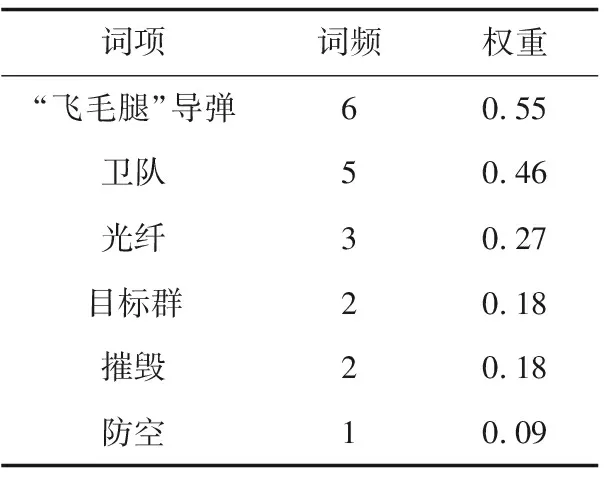
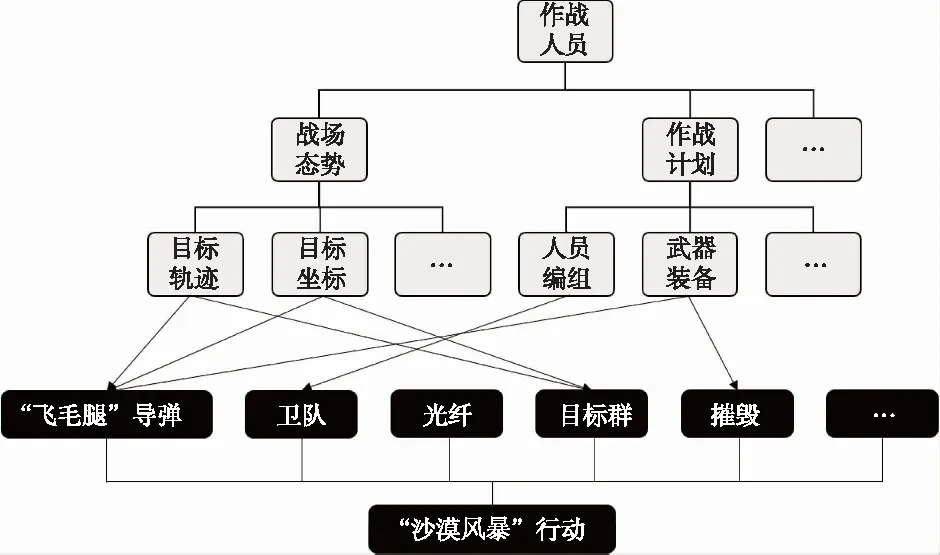
Step 4 将分解后的词-文本矩阵进行降维处理,k([m*k]. [k*k]. [k*n],0 4) LDA算法[12] LDA,其全称为Linear Discriminant Analysis,是人工智能领域中的经典算法。其基本思想是先假定文本中主题与文本关键词服从狄利克雷分布,根据先验分布和数据观察,拟合出多项式分布规律,得出Dirichlet-multi共轭结果。最后,根据共轭结果预测文本中主题与文本关键词的后验分布,即算法得到的关键词抽取结果。LDA模型的训练过程如下: Step 1 对语料库中每篇文本内容中的每一个词w进行随机初始化,赋予一个主题编号b; Step 2 按照吉布斯采样公式重新扫描语料库,并重新采样每个词w的主题编号b,及时在语料库中更新编号; Step 3 当吉布斯采样收敛时,停止重复采样过程,进入下一步; Step 4 统计语料库的主题-词共现频率矩阵,即关键词抽取需要的LDA模型。 接下来就可以按照一定的方式对新文本的主题进行预估,具体步骤如下: Step 1 对当前文本内容中的每一个词w进行随机初始化,赋予一个主题编号c; Step 2 按照吉布斯采样公式重新扫描当前文本并重采样文本主题; Step 3 当吉布斯采样收敛时,停止重采样过程,进入下一步; Step 4 统计文本中的主题分布即为预测结果。 对于图像类推荐对象,同样可以采用基于内容的建模方法,主要是对图像内容进行相似度对比计算。目前常用的方法有像素点对比、重心对比、投影对比和分块对比。而对于视频、音频类推荐对象,可以采用基于分类的建模方法,目前常用的分类方法有支持向量机、K最近邻和朴素贝叶斯等方法。 在推荐算法方面,目前商用推荐算法大致可以分为四类,即:协作过滤推荐算法、基于内容的推荐算法、基于网络结构的推荐算法和混合推荐算法。 1) 协作过滤推荐算法[13] 关于协作过滤算法,可以分为基于用户的和基于对象的。基于用户的方法是指经过对用户间的相似度计算,从而把相似用户感兴趣的内容推荐过来。如用户甲偏好A类信息,用户乙偏好A类和B类信息,就能够将B类信息推荐给用户甲。基于对象的方法是指经过计算对象间的相似度,从而把与某一用户感兴趣的对象的相似对象推荐出来。如某用户偏好X类对象,Y类与X类对象较为相似,就能够将Y类对象推荐给用户。 协作过滤算法最主要的是相似度计算方法的设计,目前有余弦相似(式(8))、Jaccard相似(式(9))、欧氏距离相似(式(10))等计算方法。协作过滤算法的优点是可以针对用户自身行为记录进行计算,容易发现用户的潜在信息偏好特征;缺点是会带来数据稀疏性、“冷启动”问题、“信息茧房”问题。 (8) (9) (10) 2) 基于内容的推荐算法[14] 基于内容的推荐是指依据用户浏览的信息内容特征进行推荐。需要计算出用户与不同内容信息间的相似度,而后根据相似度值的大小排序,将Topn对象推荐出来。优点是简单高效,缺点是推荐内容较为相似,缺乏多样性。 3) 基于网络结构的推荐算法[15] 基于网络的推荐算法是将用户和对象间的行为关系转换为网络中的节点和边,通过对网络结构的分析进行推荐,如图3所示。优点是可扩展性强,新用户或新对象可以作为新的节点加入网络,不存在“冷启动”问题,缺点是网络结构较为复杂,计算量太大。 图3 用户行为记录结构图 4) 混合推荐算法 混合推荐算法是指采取混合策略使用多种推荐算法,这样可以弥补单一算法的不足,从而将更佳的推荐结果展示给用户。但对于不同的推荐用户和对象,如何选择推荐算法进行混合推荐是关键。 此外,针对军事用户的特殊性,可以基于情景感知为作战行动单元进行地理条件、气象环境等的推荐;基于情报分析为心理战、舆论战提供情感分析推荐;基于关联规则为战场事件行动决策进行推荐;基于社交网络对作战群组协同进行推荐等。 ISM法即解释结构模型法,其全称为Interpretative Structural Modeling Method,主要用于解决变量较多、结构复杂的系统分析问题。通过将该方法引入智能推荐中,可以优化推荐对象建模技术,构建军事信息用户偏好特征层次模型,解决新用户刚加入时缺乏特征数据无法进行推荐的问题,即“冷启动”问题。对于新加入的用户来说,就可以依据其特征层次结构模型来进行共性特征相关推荐。随着用户的个人行为数据逐渐积累,后期可挖掘分析其个性特征实现更精确的推荐。 对于某类军事用户来说,采用上述传统对象建模技术提取的偏好特征可以由m+n元组表示。而实际中,不同特征间可能存在影响关系。现假设经判定某类用户的7个偏好特征中存在如下关系:S2影响S1,S3影响S4,S4影响S5,S7影响S2,S4和S6互相影响。进一步,可依据该影响关系构建有向图,如图4。 图4 特征关系有向图 下一步,根据有向图得出邻接矩阵A,并求出邻接矩阵的可达矩阵M。 (11) 通过ISM方法,对可达矩阵M进行区域划分和级位划分,提取骨架矩阵,得出特征关系层次结构图,如图5所示。 图5 层次结构图 进一步,依据特征关系层次结构图,构建军事信息用户偏好特征层次模型,并将其进行布尔向量化。用户模型可以表示为X=[x1,x2,…,xN]。 对于推荐对象建模,可以通过TF-IDF方法进行军事信息文本关键词抽取,构建文本的关键词特征模型,并通过布尔模型对文本关键词进行特征向量化。对象模型可以表示为Y=[y1,y2,…,yN]。 采用相似余弦算法,计算用户和对象内容间的相似度大小,如式(12)所示。并依据相似度大小进行排序,将对象推荐给相似度值最大的军事用户,从而实现军事文本信息的智能推荐。 cosineXY=|Y*XT| (12) 针对军事信息用户的特殊需求,结合上述对建模方法和推荐算法的研究,可以采用分层思想,设计出面向军事信息服务的智能推荐系统架构,其中主要包括基础层、数据层、控制层和应用层。系统总体架构设计如图6所示。 图6 军事信息推荐系统架构 1) 基础层 其主要依托我军建设的网络设施、存储设施、计算设施,作为构建面向军事信息服务的智能推荐系统的硬件基础。 2) 数据层 其主要用来存储各种各样的信息,包括用户行为记录信息、战场环境信息(地形、地貌、水文、气象等)、多媒体信息(文本、图像、视频、音频等),作为推荐系统的数据支撑,对数据进行加密和安全性保护。 3) 控制层 其主要实现用户信息偏好特征的捕获、各式信息的过滤整合以及用户需求的自主预测,进而为用户从海量信息中推荐出有价值的信息,发挥出信息优势。 4) 应用层 其用于接收并可视化展示控制层处理后的结果,对用户进行交互操作,满足用户需求。 本文以美军海湾行动“沙漠风暴”空中作战计划的文本信息为例,首先对文本内容进行用户分析和关键词分析。 根据任务不同,可以对军事用户进行角色分类,如表1所示。 表1 不同军事用户信息偏好 本文采用上述ISM方法,构建出不同角色的用户信息偏好特征层次模型,图7展示了作战人员的特征层次模型。 图7 军事信息用户偏好特征层次模型 进一步,本文通过TF-IDF方法,提取出该文本内容的特征关键词顺序依次为:“飞毛腿”导弹、卫队、光纤、目标群、摧毁等,详见表2。 表2 案例文本特征权重 最后,本文通过余弦相似度算法,计算出该文本关键词与不同军事用户特征的相似度值。图8展示了:对于美军“沙漠风暴”这篇军事情报文本,与作战人员信息偏好特征更为相似,因此,可以将其推荐给作战人员。 图8 用户与文本内容间的相似度 本文针对军事信息服务中的信息推荐问题进行了技术研究,分别介绍了目前的研究现状、关键技术和系统设计,并给出了一种基于ISM方法的军事文本信息智能推荐算法。关键技术方面详细分析了用户建模技术、对象建模技术和推荐算法,并就一些常用方法给出了优缺点对比。军事文本信息智能推荐算法中引入了ISM方法,优化了用户建模技术,解决了“冷启动”问题。本文的研究对于我军利用军事信息的智能推荐服务具有重要意义,可以为其提供技术支持。下一步工作中,将采用本文研究的方法设计并实现面向军事信息服务的智能推荐系统,为我军作战人员决策提供辅助信息,为广大普通人员提供个性信息。同时,未来工作中,还要结合具体应用场景,综合考虑用户的真实复杂的需求,优化推荐技术,进一步提高智能推荐质量。2.3 推荐算法
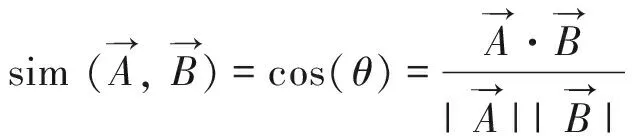

3 基于ISM的军事文本信息智能推荐
3.1 军事用户建模

3.2 推荐文本建模
3.3 基于内容的推荐
4 系统设计与案例分析
4.1 系统设计
4.2 案例分析

5 结束语
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
廉政瞭望·下半月(2021年5期)2021-07-20
天津外国语大学学报(2021年1期)2021-03-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
好家长·青春期教育(2014年7期)2014-07-05
军事文摘(2009年9期)2009-07-30
全国新书目(2009年24期)2009-07-17
