
基于数据挖掘和分析的食品安全智能测评系统
2019-08-20 07:27符雨童聂笑一肖毅
现代计算机 2019年20期
符雨童,聂笑一,肖毅
(湖南农业大学东方科技学院,长沙410128)
0 引言
许多不良商家因为利益等因素,通过虚假交易和评价欺骗电商平台的搜索引擎,借机获得优等的排名,从而得到巨额的流量与用户资源获得订单。为了解决这个问题,我们的食品安全智能测评系统从大量混杂的数据中提取隐藏在其中真实、有用的目标数据,利用处理后的真实评分数据,为人们尤其是18-35 岁青年上班族推荐性价比最高的美食店铺。模型系统利用朴素贝叶斯等算法,筛除美团、大众点评中的不实评论,根据有效数据为每个店铺重新打分,为使用者呈现最真实的食品信息情况以及根据评分高低和使用者需求为其推荐相应的性价比最高的店铺。让使用者及时掌握真实的店铺好评率波动情况,以及从清洗过的有效评论中分析区分出每个店铺每个菜肴的好坏与否,为消费者提供正确评价的信息。
1 相关工作
食品安全数据分析离不开对大量评论与卖家概述的抓取,本文采用PHPQuery 和CURL 的类方法采集数据。即时更新各个店铺的评价的变化情况,并将数据可视化,以图表的形式给点餐者呈现店铺某一时间段的好评率波动图。通过图表分析模式辅助点餐者找到安全的美食店铺,给青年上班族来极大的便捷,实现食品食用的安全性。
本阶段项目中主要运用主流的PHP 服务器端语言和JavaScript、HTML 前端技术语言的支撑来完成模型系统。
2 算法描述

图1 模型构建结构图
2.1 数据采集
使用PHPQuery 采集数据,实际上是通过链接地址找到源码,再将源码转换为jQuery 语法,然后通过jQuery 语法获得大量的评价数据(约500000 条)。
$curl=curl_init();
curl_setopt($curl,CURLOPT_URL,'http://www.baidu.com');
curl_setopt($curl,CURLOPT_HEADER,1);
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);
$data=curl_exec($curl);
curl_close($curl);
var_dump($data);
?>
在代码中首先初始化一个CURL 的对象,然后设置所要抓取的URL,配置CURL 参数要求结果保存到字符串中或者输出到屏幕。之后运行CURL 请求网页。最后关闭URL 请求,显示所获得的信息数据。
2.2 数据分析
通过PHPQuery 和CURL 的类方法采集食品数据的评价后,本模型系统的重难点在于如何对这些冗杂数据进行清洗和筛选。针对如何提取有效真实的评价,我们做出了以下的处理:
2.2.1 得到清洗数据后的好评率
经过粗略的评论浏览,我们得到以下几种无效评论。
(1)全是标点符号或者只有一两个字,如表1所示。

表1
这种情况可以利用正则表达式来去除。
(2)凑字数、灌水,不含任何产品的特征的语句
此种评论的处理方法有两种。一种是观察评论中涉及的名词是否是食品相关的词语,如[色泽,香味,气味]但实际情况会十分复杂,例如:
“真的很不错”、“太美味了”...
因为评价中缺少主语,所以机器并不知道它评价的是什么。这里我们反过来,假设每一类无效评论都有类似的关键词,一个评论中的词语只要有一些垃圾评论关键词,我们就把它判定为无效评论。当然并也不需要给定所有的无效评论词,利用TF-IDF 可以通过一个词语顺藤摸瓜关联到其他类似的词语。当然,我们也可以利用文本相似性算法寻找。
2.2.2 语义理解
语义理解是非常复杂的课题,本文中不追求绝对精准,仅希望能对外卖店铺的评论有一个快速的理解,找出用户使用最多的形容类词语。
(1)数据云图。它会统计一段文本中各个词语出现的次数(频数),频数越大,在词云中对应的字体也越大。通过观察词云,我们可以知道一段文本主要在讲哪些东西。
通过将主题分解提炼出的关键词并生成词云。
%matplotlib inline
Warningds.filterwarnings(“ignore”)
for k in[‘正分’,’负分’]
keywords=comments . get_keywords(comments . scores==k)
Print(‘{}的关键词为:’.format(k)+’|’.jain(keywords))
comments.find_topic(comments.scores==k,n_topics=5);
filename=’wordcloud of{}’.format(k)
comments . genwordcloud(comments.scores==k,filename=filename);
Print(‘=’*20)
应用如下:

图2 词云图
(2)通过关联分析寻找显性特征-形容词对,需要克服以下难点:
①语句不只含名词-形容词对,两个名词,形容词-动词对等都有可能;
②没有考虑两个词语在文本之间的距离。例如名词位于第一句话中,形容词则是最后一句话中。

表2 词频权重比
关联分析只会挖掘支持度大于一定数值的特征,我们称这种特征为“常见特征”。除此之外还有支持挖掘度没有超过一定值的特征,我们把它叫做“不常见特征”,不常见特征根据食品的最常见评价词反向挖掘得出。挖掘过程中将大数据关联分析中处理过程按特征性任务分解,不同任务继续分解为子任务,不同任务在不同的模块或层流中协作完成相关性分析。
利用用户对店铺其评价的语义,筛选出一系列有代表性的特征关键词,如:
口感度关键字:好吃|美味|不好吃|还行 等进行分析。
匹配关键字:利用MySQL 的全文搜索进行关键字匹配。
自定义关键字,将每条评论取出,利用PHP 函数匹配与自定义关键字相符的记录。
利用App 使用者对店铺评价的优劣,主要表现评论中重复字与重复性评论的剔除,评论字数小于10剔除。
(3)朴素贝叶斯算法
分析词云、关键词和主题可以区分出集中在正面评价和负面评价中的词语。但是这个时候词语中并没有配套的情感,本测评模型系统中用到基于贝叶斯定理与特征条件独立假设的分类方法的朴素贝叶斯数据情感数据算法来判断一句话的情感方向是正面的还是负面的。
朴素贝叶斯其实是由以下的联合概率公式推导出来:
P(Y,X)=P(Y|X)P(X)=P(X|Y)P(Y)P(Y,X)=P(Y|X)P(X)=P(X|Y)P(Y)
其中P(Y)P(Y)叫做先验概率,P(Y|X)P(Y|X)叫做后验概率,P(Y,X)P(Y,X)叫做联合概率。
用朴素贝叶斯进行文本特征提取和分类。
flag='sklearn'
deleteNs=range(0,1000,20)
test_accuracy_list=[]
for deleteN in deleteNs:
#feature_words=words_dict(all_words_list,deleteN)
feature_words=words_dict(all_words_list,deleteN,stopwords_set)
train_feature_list, test_feature_list = text_features(train_data_list,test_data_list,feature_words,flag)
test_accuracy=text_classifier(train_feature_list,test_feature_list,train_class_list,test_class_list,flag)
test_accuracy_list.append(test_accuracy)
print test_accuracy_list
(4)TextRank
TextRank 算法是一种用于文本的基于图的排序算法,可以给出一段文本的关键词,适用于食品评价安全模型系统的构建。其基本思想来源于谷歌的PageRank算法,通过把文本分割成若干组成单元(单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序,仅利用单篇文档本身的信息即可实现关键词提取、文摘。和LDA、HMM 等模型不同,TextRank 不需要事先对多篇文档进行学习训练,因其简洁有效而得到广泛应用。
TextRank 公式推导为:
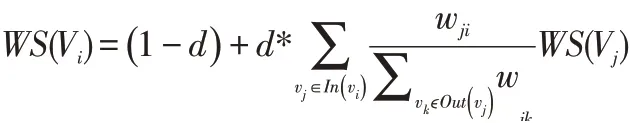
cm=defaultdict(int)
words=tuple(self.tokenizer.cut(sentence))
for i,wp in enumerate(words):#(enumerate 枚举的方式进行)
if self.pairfilter(wp):
for j in xrange(i+1,i+self.span):
if j>=len(words):
break
if not self.pairfilter(words[j]):
continue
if allowPOS and withFlag:
cm[(wp,words[j])]+=1
else:
cm[(wp.word,words[j].word)]+=1
3 实验

图3 功能展示
3.1 评价监测工具
通过特定的算法,筛选出美团、大众点评中各店铺网站真实的评价及评分,并利用真实信息为店铺重新打分以及显示出真实评价。
3.2 好评率趋势分析图

图4 调研店铺好评率分析
如下,即时更新各个店铺的评价的变化情况,并将数据可视化,以图表的形式给点餐者呈现店铺某一时间段的好评率波动图。通过图表分析模式辅助点餐者找到真正健康安全的美食店铺,给青年上班族来极大的便捷。
3.3 个性化菜谱即时推送
根据用户的浏览足迹以及店铺收藏情况,每隔三天会为用户打造一份包括早中晚三餐的个性化菜单,并以邮件的形式发送给每一位用户。
4 结语
在本食品评论监测模型系统中,首先是利用了PHPQuery 和CURL 的类方法采集原始数据;接下来,将采集下来的分散数据清洗、冗余去重得到干净数据;然后,提取评价信息主题中关键词,根据词语出现频率生成数据词云图,接着通过关联分析判断提取出食品特征描述的形容词;最后,使用朴素贝叶斯数据模型机器判断配套的情感,并通过构建TextRank 文本网络图,迭代计算得到句子权重做出排序建立图模型,生成可视化好评率趋势分析图。
在数据挖掘和分析中对数据模型的优化是数据挖掘任务在网络环境进行中的关键。本节中,优化的目的是为了保证筛选评价的真实性及将基于大数据挖掘的分散式搜取数据顺利转化为直观性、联系性可视化图表,只有真实性的数据才能保证可视化图表的准确性,真正做到对广大人民群众的用餐安全问题负责。
经过一段时间的网络外卖评论数据的检测调研后,我们绘制出调研店铺的好评率分析图。具体机制
