
基于平均多粒度决策粗糙集和NNBC的滚动轴承故障诊断
2019-08-19 02:10何勇军
振动与冲击 2019年15期
于 军, 丁 博, 何勇军
(1. 哈尔滨理工大学 自动化学院,哈尔滨 150080; 2. 哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080)
滚动轴承作为旋转机械的核心部件,已广泛应用于风电机组、运输车辆和精密机床等设备的传动系统中[-2]。然而,由于长期运行在高速重载等复杂恶劣工况,滚动轴承的内圈、外圈和滚动体等部位极易发生裂纹、点蚀或剥落等故障[3];从而降低设备精度,甚至造成人员伤亡等严重后果。因此,滚动轴承的故障诊断研究具有十分重要的意义。
近年来,人工智能技术已广泛应用于滚动轴承的故障诊断方法中,如深度神经网络(Deep Neural Network, DNN)、支持向量机(Support Vector Machine, SVM)和模糊逻辑(Fuzzy Logic, FL)等。作为一种新颖的机器学习工具,DNN能够自动地从原始数据中获得有价值的特征,并且其具有简单的结构和极强的表示能力。Gan等[4]提出了一种基于分层诊断DNN的滚动轴承故障识别方法。该方法通过一个二级DNN,实现轴承故障程度的分级诊断。Guo等[5]将自适应改进DNN用于判断滚动轴承的故障类型和程度。Zhang等[6]为滚动轴承的故障诊断构建了一种卷积DNN模型。该模型可实现变载荷和高噪音环境下轴承的故障识别。DNN虽能准确地诊断滚动轴承的故障类型和故障程度,但其模型结构和参数的获取需要大量的训练样本。而且,较高的计算成本和较低的适应能力仍然没有解决。
SVM是一种基于统计学原理的监督式机器学习方法,它具有突出的泛化特性和较强的容错能力。Liu等提出了一种基于短时匹配追踪和SVM的轴承诊断策略。实验结果表明该策略可根据复杂非静态信号,实现滚动轴承早期微弱故障的诊断。Li等[7]将多尺度置换熵和基于二元决策树的SVM相结合,用于判断滚动轴承故障。Ziani等[8]提出了一种基于二元粒群优化和SVM的轴承故障诊断方法。与其它方法相比,SVM具有较高的模式识别精度。但SVM较难确定最优超平面,依据反复试验和操作经验确定。而且,基于SVM的模式识别方法难于实现动态特征下的故障诊断。
FL是对二值逻辑的扩展,它将模糊或不确定的数据转换成数值项,用隶属度衡量部分肯定或部分否定。Straczkiewicz等[9]提出了一种基于振动特征融合的滚动轴承模糊识别技术。Ziani等[10]建立了一种自适应模糊神经分类器,用于判断滚动轴承状态。Li等[11]引入概率模糊系统判断轴承故障类型。该系统中的决策规则可用于诊断轴承故障,并给出故障发生的概率。然而,FL策略的核心是将输入空间映射到输出空间,是通过决策规则的描述来实现的。模糊规则的生成需耗费大量时间,一些来自专家的规则并不可靠。
作为粗糙集的扩展,多粒度粗糙集因其多层次、多视角的数据挖掘特性,已成功应用于属性约简和故障诊断领域。Qian等[12]引入征兆属性重要性的概念,提出了基于悲观多粒度粗糙集的属性约简算法。Tan等[13]通过基于证据理论的置信约简算法,获得悲观近似集的最小约简。Zhang等[14]建立了基于双论域的单值智能多粒度模型,用于解决不确定信息下的故障诊断问题。然而,采用求同排异思想的悲观多粒度粗糙集是一种规避风险的决策策略,其限制条件过于苛刻,导致约简后的征兆属性集维数过低,难于对滚动轴承的状态做出准确判断。
为此,本文提出一种基于平均多粒度决策粗糙集和非朴素贝叶斯分类器(Non-Naive Bayesian Classifier, NNBC)的滚动轴承故障诊断方法。该方法首先提取训练样本中滚动轴承的故障特征,用于构建平均多粒度决策粗糙集;其次,采用基于平均多粒度决策粗糙集的属性约简算法,降低训练样本中征兆属性集的维数;最后,根据约简后的训练样本构建NNBC,用于判断待诊样本中滚动轴承状态。
1 平均多粒度决策粗糙集和NNBC简介
1.1 平均多粒度决策粗糙集
决策粗糙集[15]是对概率粗糙集的扩展。它将条件概率引入粗糙集,用一对阈值代替概率粗糙集中的精确值。通过决策的风险代价,并采用系统化的方式确定阈值。利用贝叶斯决策过程最小化决策成本。因此,决策粗糙集具有容错性和灵活性的特点。
在贝叶斯决策过程中,状态集记为Ω={X,~X},决策集记为A={aP,aN,aB},其中aP,aN和aB分别表示正域决策、负域决策和边界域决策。λ11,λ21和λ31代表样本属于X状态下分别采取决策aP,aN和aB的风险代价。同理,λ12,λ22和λ32代表样本属于~X状态下分别采取相应决策的风险代价。对于样本x,采取三种决策的期望风险分别为
R(a1|[x])=λ11P(X|[x])+λ12P(~X|[x]),
R(a2|[x])=λ21P(X|[x])+λ22P(~X|[x]),
R(a3|[x])=λ31P(X|[x])+λ32P(~X|[x])。
根据贝叶斯决策过程,可获得以下最小风险决策规则:
(P) 若P(X|[x])≥γ且P(X|[x])≥α,则x∈POS(X);
(N) 若P(X|[x])≤β且P(X|[x])≤γ,则x∈NEG(X);
(B) 若β≤P(X|[x])≤α,则x∈BND(X);
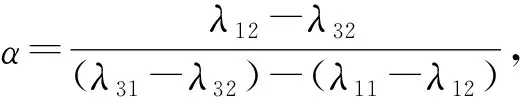
然而,在许多实际应用中,决策粗糙集难于解决高维多源数据的分析、属性约简和模式识别问题。为此,Qian等[16]将多粒度粗糙集和决策粗糙集相结合,提出了平均多粒度决策粗糙集。
定义1设信息系统S=(U,A=C∪D,V,f),令B={B1,B2,…,Bm}是集合C的m个属性子集;在m个粒度结构下,集合X在样本x下的条件概率的数学期望为
E(P(X|x))={P(X|[x]B1)+
P(X|[x]B2)+…+P(X|[x]Bm)}/m
(1)
式中:[x]B1(1≤i≤m)是样本x在属性子集Bi上的等价类,P(X|[x]Bi)是集合X在等价类[x]B1下的条件概率。
定义2设信息系统S=(U,A=C∪D,V,f),令B={B1,B2,…,Bm}是集合C的m个属性子集,集合X关于B的平均多粒度决策粗糙集下、上近似集和边界域分别定义为
P(X|[x]B2)+…+P(X|[x]Bm)}/m≥α}
(2)
P(X|[x]B2)+…+P(X|[x]Bm)}/m≤β}
(3)
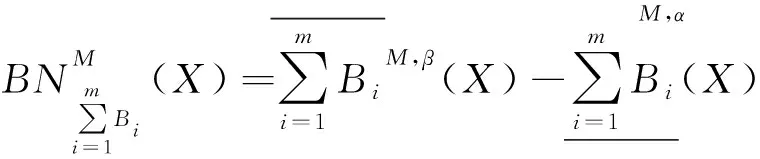
(4)
式中:α,β是一对阈值。
当阈值α>β时,平均多粒度决策粗糙集有如下决策规则:
(MP1) 若{P(X|[x]B1)+…+P(X|[x]Bm)}m≥α,则x∈POS(X);
(MN1) 若{P(X|[x]B1)+…+P(X|[x]Bm)}m≤β,则x∈NEG(X);
(MB1) 若β<{P(X|[x]B1)+…+P(X|[x]Bm)}/m<α,则x∈BND(X)。
平均多粒度决策粗糙集不但保留了决策粗糙集的容错性和灵活性的特点,还具有多层次数据挖掘特性,并克服了悲观多粒度粗糙集限制条件过于苛刻的不足。因此,平均多粒度决策粗糙集的应用领域更加广泛,如多源高维数据的分析和属性约简。
1.2 非朴素贝叶斯分类器
NNBC是一种新颖的基于概率统计理论的模式识别工具[17]。它采用积分均方误差最小化的策略选择最优带宽,利用联合概率密度函数估计代替边缘概率密度函数估计,并克服了朴素贝叶斯分类器条件独立性假设的约束。因此,NNBC被成功应用于滚动轴承的故障诊断中[18]。
(5)

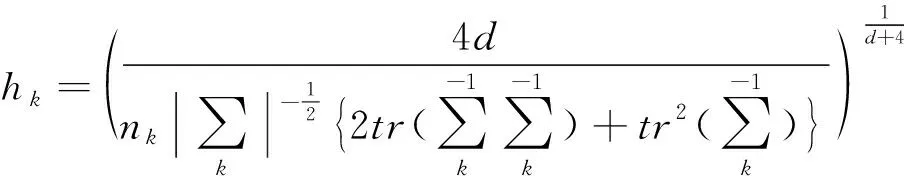
(6)
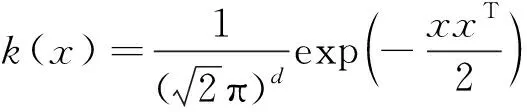
(7)

2 滚动轴承故障诊断方法
平均多粒度决策粗糙集不但具有容错性、灵活性和多层次性的特点,还克服了悲观多粒度粗糙集限制条件过于苛刻的不足。NNBC利用联合概率密度函数估计代替边缘概率密度函数估计,并克服了朴素贝叶斯分类器条件独立性假设的约束。在现有的贝叶斯分类器中,NNBC可实现最佳的模式识别效果和最低的时间消耗。为此,提出基于平均多粒度决策粗糙集和NNBC的滚动轴承故障诊断方法,方法框架如图1所示。该方法首先提取训练样本中滚动轴承的故障特征,用于构建平均多粒度决策粗糙集;其次,采用基于平均多粒度决策粗糙集的属性约简算法,降低训练样本中征兆属性集的维数;最后,根据约简后的训练样本构建NNBC,用于判断待诊样本中滚动轴承状态。
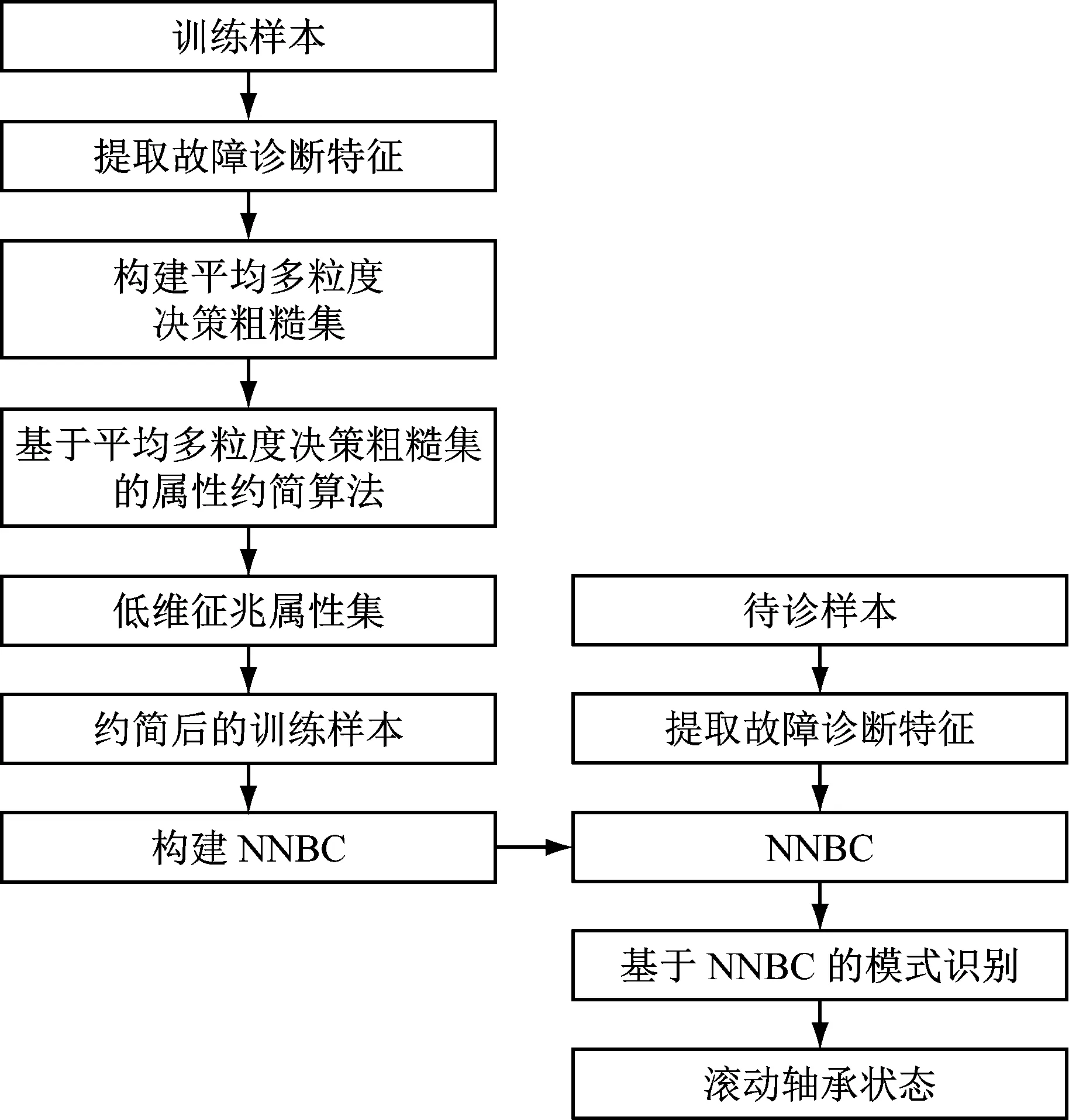
图1 滚动轴承故障诊断框架
2.1 基于平均多粒度决策粗糙集的属性约简
属性约简是降低训练样本征兆属性集维数的关键环节,即在不改变系统分类决策能力的前提下,去掉冗余的征兆属性,降低征兆属性集维数。而系统分类决策能力不变也就是约简后的所有征兆属性所确定的正域未发生变化。为定量评价征兆属性对系统分类决策能力的影响,本文给出平均多粒度决策粗糙集中征兆属性重要度的定义。
定义4设信息系统S=(U,A=C∪D,V,f),令B={B1,B2,…,Bm}是征兆属性集C的m个属性子集,则征兆属性集C关于决策属性D的分类质量为
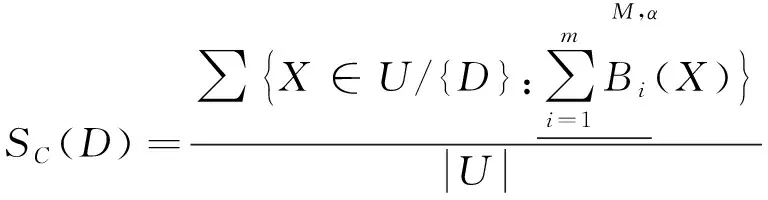
(8)
定义5设信息系统S=(U,A=C∪D,V,f),令征兆属性集C={c1,c2,…,cn},∀ci∈C(1≤i≤n),征兆属性ci在征兆属性集C中关于决策属性D的重要度为
Sig(ci,C,D)=SC(D)-SC-{ci}(D)
(9)
定义6征兆属性ci在征兆属性集C中关于决策属性D是下近似冗余的,当且仅当Sig(ci,C,D)=0。
平均多粒度决策粗糙集的限制条件既比悲观多粒度粗糙集宽松,又比乐观多粒度粗糙集严格,还具备多粒度粗糙集的容错性、灵活性和多层次性的特点。而平均多粒度决策粗糙集中征兆属性重要度可定量评价征兆属性对系统分类决策能力的影响。在此基础上,本文提出一种基于平均多粒度决策粗糙集的属性约简算法:
输入:信息系统S=(U,A=C∪D,V,f),B={B1,B2,…,Bm},风险代价λp,q(p,q=1,2,3)
输出:低维征兆属性集
步骤1:根据风险代价λp,q,计算阈值α;
步骤2:计算征兆属性集C关于决策属性D的分类质量SC(D);
步骤3:依次对每一个征兆属性ci,i=1,2,…,n进行如下操作;
步骤4:计算征兆属性ci的重要度Sig(ci,C,D);
步骤5:如果征兆属性ci的重要度Sig(ci,C,D)=0,那么征兆属性ci是冗余的,否则征兆属性ci必不可少的;
步骤6:对其它征兆属性重复步骤4和5,直至最后一个征兆属性cn;
步骤7:删除所有冗余的征兆属性,获得低维征兆属性集。
2.2 基于NNBC的模式识别
步骤1:根据式(6)和(7),分别计算约简后训练样本的最优带宽hk和高斯核函数k(x);
3 实验验证
3.1 实验设备
为了验证所提出故障诊断方法的有效性,采用本实验室研发的滚动轴承实验组件进行故障诊断实验,实验组件如图2所示。三相交流电机通过联轴器与轴的一端连接,两个滚动轴承将轴支撑在轴承座上,远离电机一侧安装测试轴承,轴的一端悬挂砝码来模拟轴承径向负载。滚动轴承为6205深沟球轴承,轴承正常状态(NC),采用电火花加工轴承内圈故障(IRF)、外圈故障(ORF)和滚动体故障(REF)。其中,内外圈故障孔径分别为0.4 mm和0.8 mm,滚动体裂纹宽为0.2 mm,滚动轴承状态如图3所示。实验中将电机的输出转速分别调为400 r/min、800 r/min、1 200 r/min,并通过悬挂不同个数的砝码模拟3种轴承径向负载,所以共模拟9种滚动轴承运行工况。通过安装在轴承座上的声发射传感器采集滚动轴承的声发射信号,采样频率为98 kHz。滚动轴承的每种运行工况采集10组样本,每种滚动轴承状态可获得90组样本,6种滚动轴承状态一共可获得540组样本,图4为其中4种滚动轴承状态的声发射信号。
3.2 实验结果
总体平均经验模式分解(Ensemble Empirical Mode Decomposition, EEMD)方法[19]引入高斯白噪声改善信

(a) 正常状态(b) 内圈故障(0.4 mm)(c) 内圈故障(0.8 mm)(d) 外圈故障(0.4 mm)(e) 外圈故障(0.8 mm)(f) 滚动体故障(0.2 mm)
图3 滚动轴承状态
Fig.3 Rolling bearing conditions
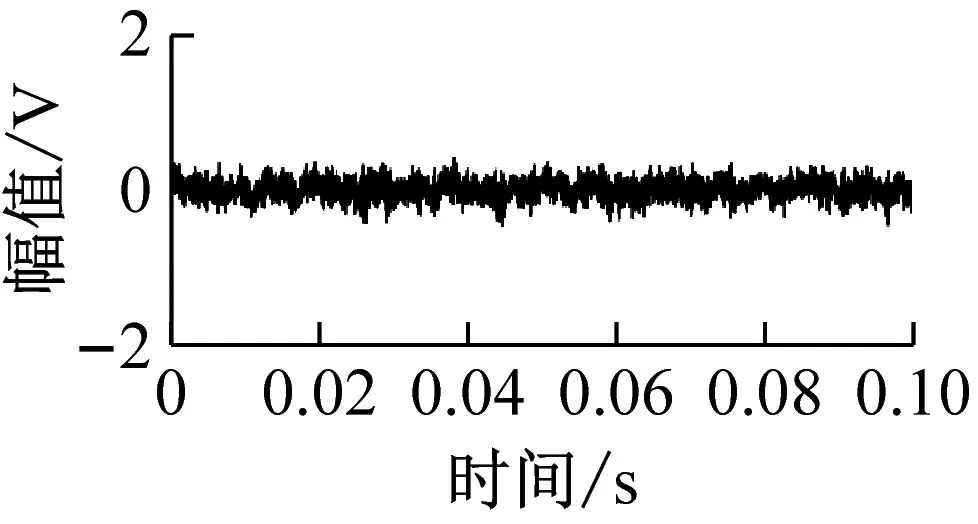
(a) 正常状态
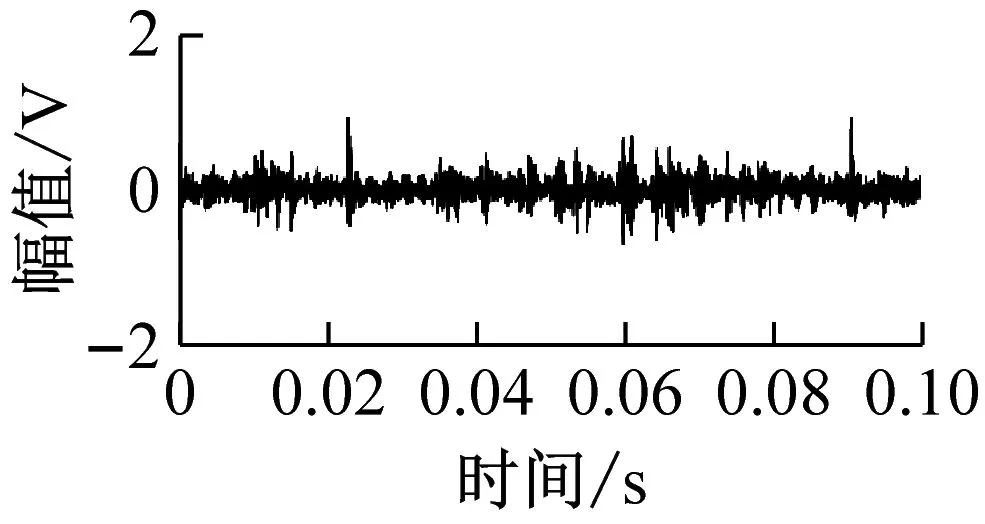
(b) 内圈故障(0.4 mm)
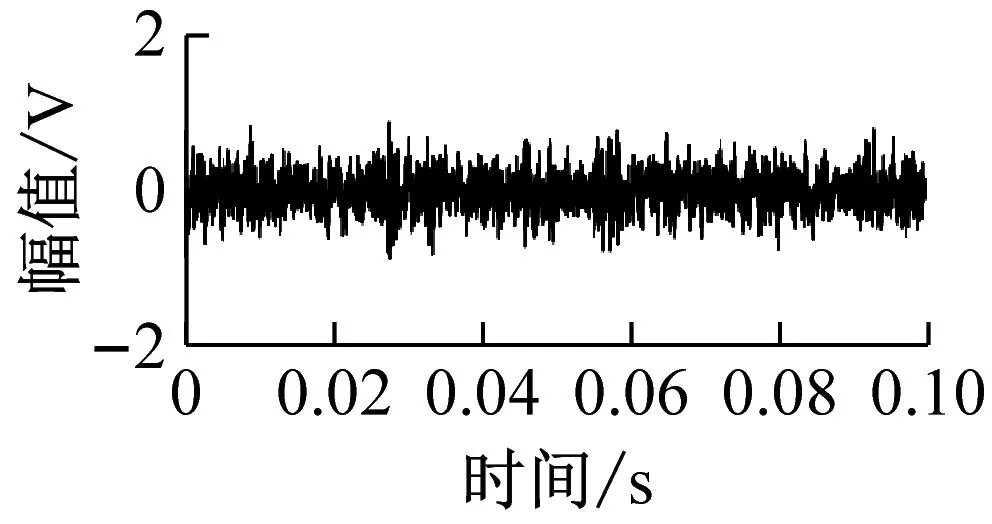
(c) 外圈故障(0.4 mm)
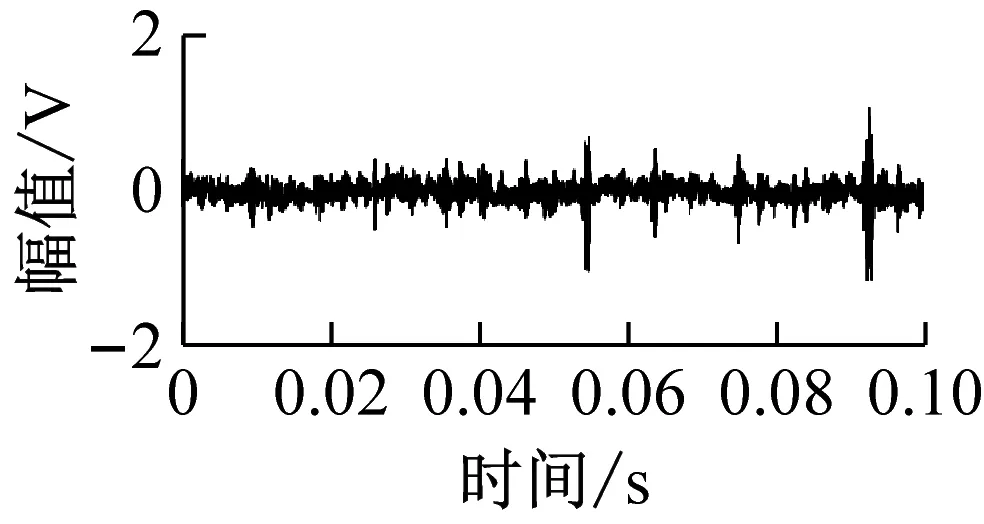
(d) 滚动体故障(0.4 mm)
图4 滚动轴承声发射信号
Fig.4 Acoustic emission signals of rolling bearings
号的极值点分布,较好地抑制了EMD分解中的模式混叠现象。所以,本实验采用EEMD方法提取滚动轴承声发射信号本征模式函数(Intrinsic Mode Function, IMF)的时域特征和频域特征,用于刻画滚动轴承状态。时域特征包括标准偏差(SD)、峭度(K)、波形指标(SF)和脉冲指标(IF)。频域特征包括平均频率(MF)、均方根频率(RF)、标准偏差频率(SDF)和谱峰值比(SR)。将每个特征的前3个最大IMF值看作滚动轴承故障特征,并用下标表示,所以一共可提取24个故障特征形成故障征兆属性集。
为了验证本文提出方法的有效性,本实验将获得的540组样本分成训练样本和待诊样本,样本数之比为5∶1。由于提取的24个故障特征为连续变量,所以需进行离散化处理,将故障特征值分配到3到4个区间,每个区间由数字“1,2,3或4”表示。采用基于平均多粒度决策粗糙集的属性约简算法,降低训练样本征兆属性集的维数,设阈值α=0.7,约简后的滚动轴承故障诊断信息系统如表1所示。然后,利用主元分析法(Principle Component Analysis, PCA)绘制约简前后训练样本的主成分散点图,如图5所示。可以看出,约简后的低维征兆属性集将同一类滚动轴承状态很好地聚集在一起,而使不同的状态有效地分开。这是由于低维征兆属性集中包含的是核心且敏感的征兆属性,从而避免了冗余或不相关征兆属性的干扰。根据约简后的训练样本构建NNBC,用于判断待诊样本中滚动轴承状态,诊断结果如表2所示。从表2可以看出,每种滚动轴承状态的待诊样本准确率超过93%,平均准确率接近100%。因此,本文提出的故障诊断方法能够准确地判断滚动轴承的故障类型及故障程度。
3.3 比较分析
为了分析阈值对故障诊断平均准确率的影响,分别将决策粗糙集和平均多粒度决策粗糙集用于属性约简,降低训练样本征兆属性集的维数。然后,计算不同阈值下滚动轴承故障诊断的平均准确率,平均准确率与阈值之间的关系曲线如图6所示。从图6中可以看出,平均准确率随阈值变大,先上升后下降。这是由于较小的阈值会导致属性约简的约束条件过于宽松,一些冗余或不必要的征兆属性被保留下来;而较大的阈值会导致属性约简的约束条件过于苛刻,一些敏感且核心的征兆属性被去掉。因此,在实际应用中,合理的阈值选择能获得最佳的故障诊断效果。从两种粗糙集下的故障诊断平均准确率可以看出,尽管平均准确率受阈值影响,但本文提出的故障诊断方法仍具有较高的平均准确率。原因在于平均多粒度决策粗糙集可从多层次的角度实现数据分析,而且它通过多粒度结构的融合描述目标概念。因此,该方法非常适用于滚动轴承多种故障的诊断。
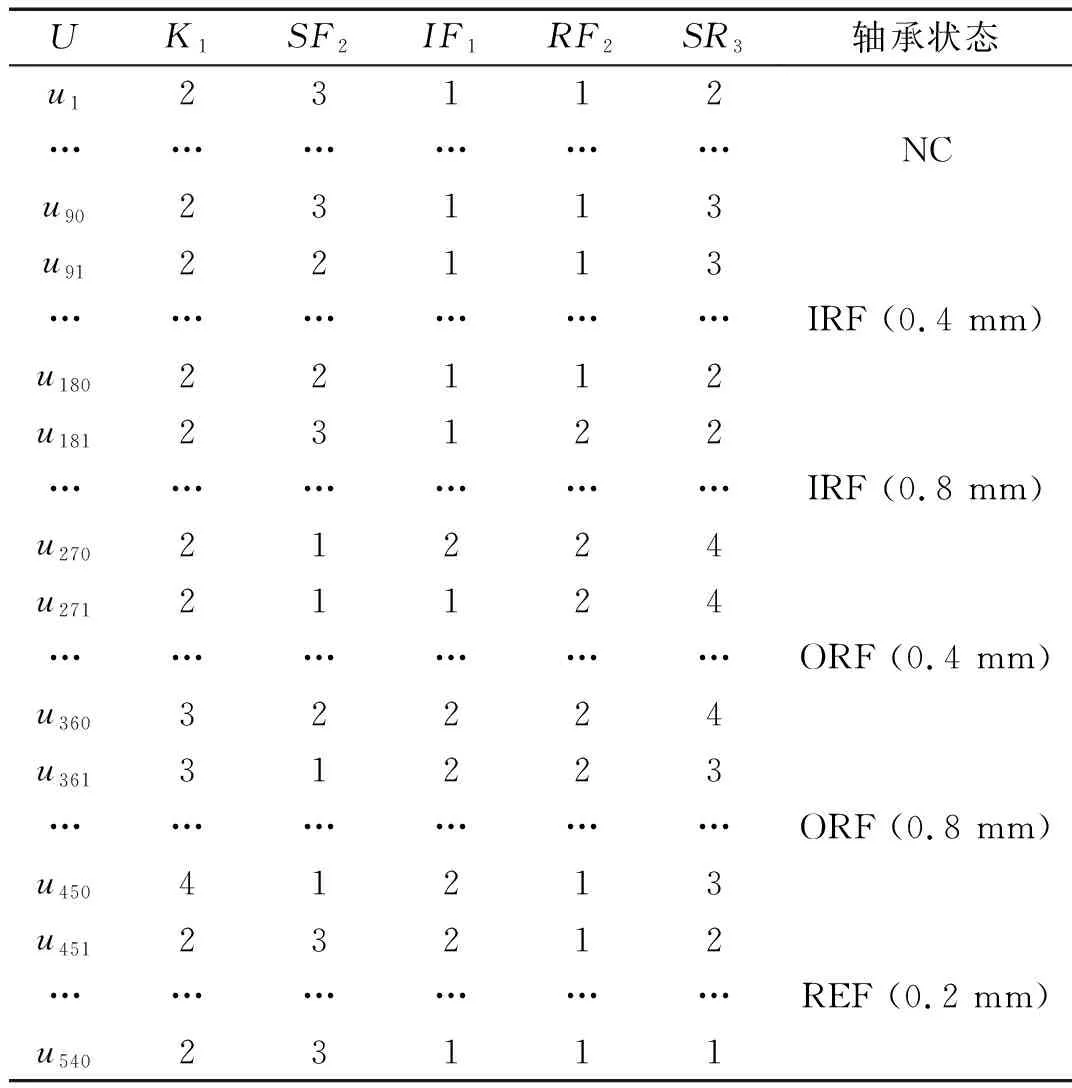
表1 约简后的滚动轴承故障诊断信息系统
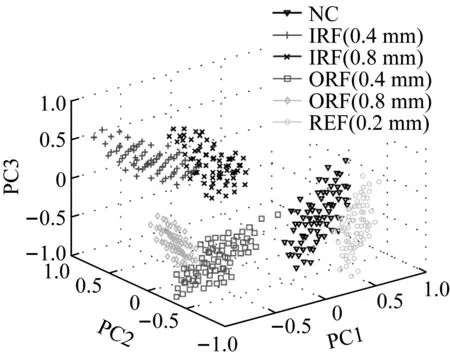
(a) 约简前
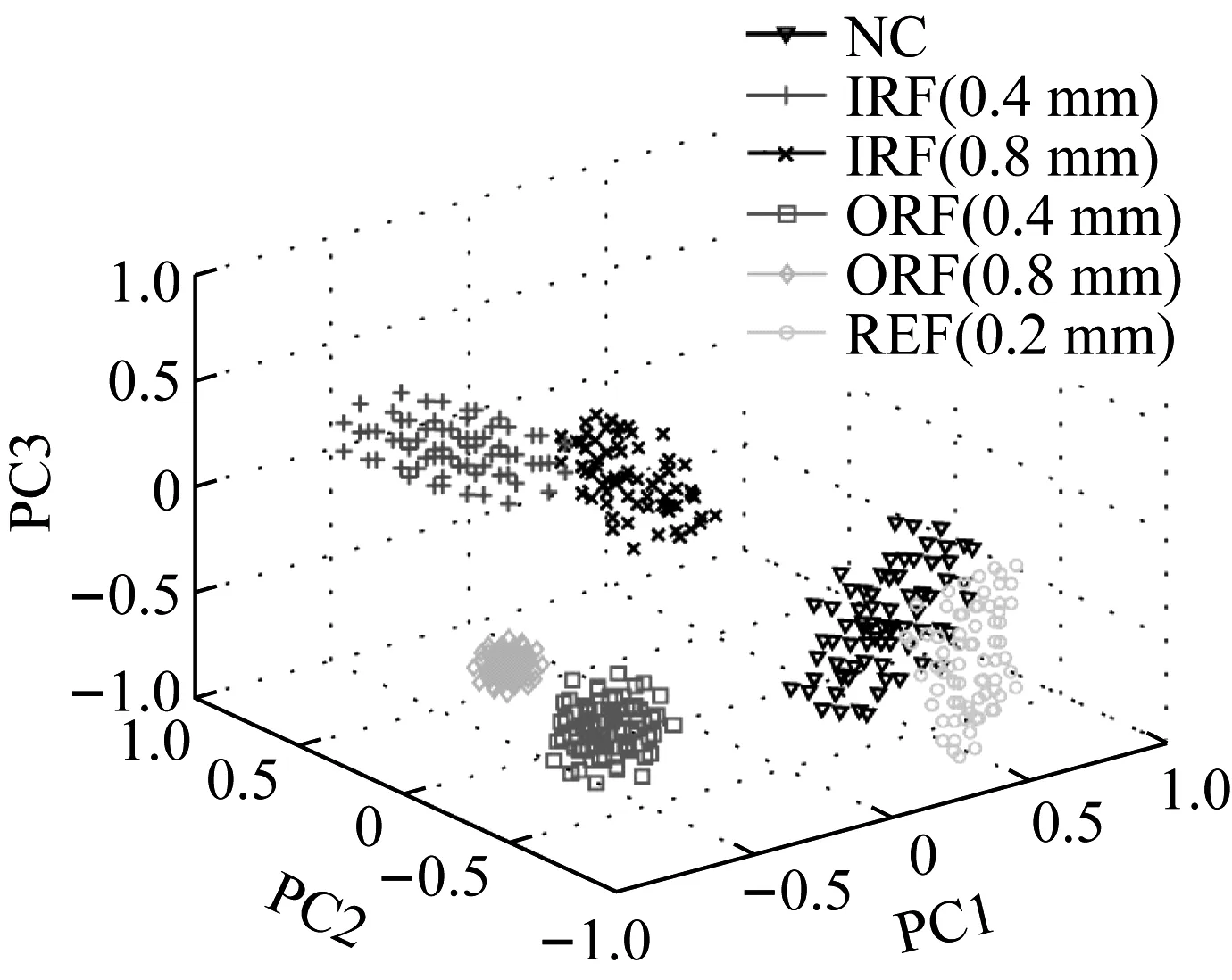
(b) 约简后
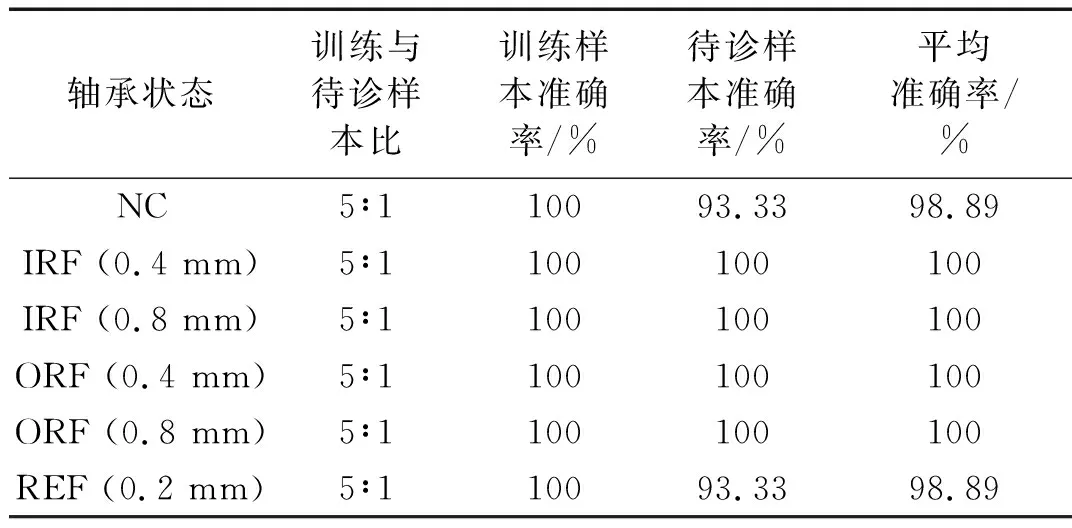
轴承状态训练与待诊样本比训练样本准确率/%待诊样本准确率/%平均准确率/%NC5∶110093.3398.89IRF (0.4 mm)5∶1100100100IRF (0.8 mm)5∶1100100100ORF (0.4 mm)5∶1100100100ORF (0.8 mm)5∶1100100100REF (0.2 mm)5∶110093.3398.89
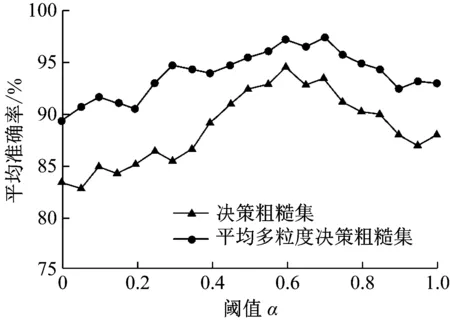
图6 平均准确率与阈值之间的关系曲线
为了进一步验证该方法的诊断效果,将该方法与FL、SVM和DNN进行对比,训练与待诊样本数之比分别为2∶1、3∶1、4∶1和5∶1,四种方法的诊断结果如图7所示。通过对图7的观察,发现平均准确率随样本数之比的提高而上升。训练与待诊样本数之比越高,诊断效果越好。在三种不同样本数之比的情况下,该方法均获得最高的平均准确率。这是由于较多的训练样本会带有较多的诊断信息,能更精确地确定模型结构和参数。约简后的低维征兆属性集使同一类滚动轴承状态很好地聚集在一起,而使不同的状态有效地分开。此外,基于最优带宽参数选择的NNBC克服了条件独立性假设的条件约束,用联合概率密度函数估计替代边缘概率密度函数估计。
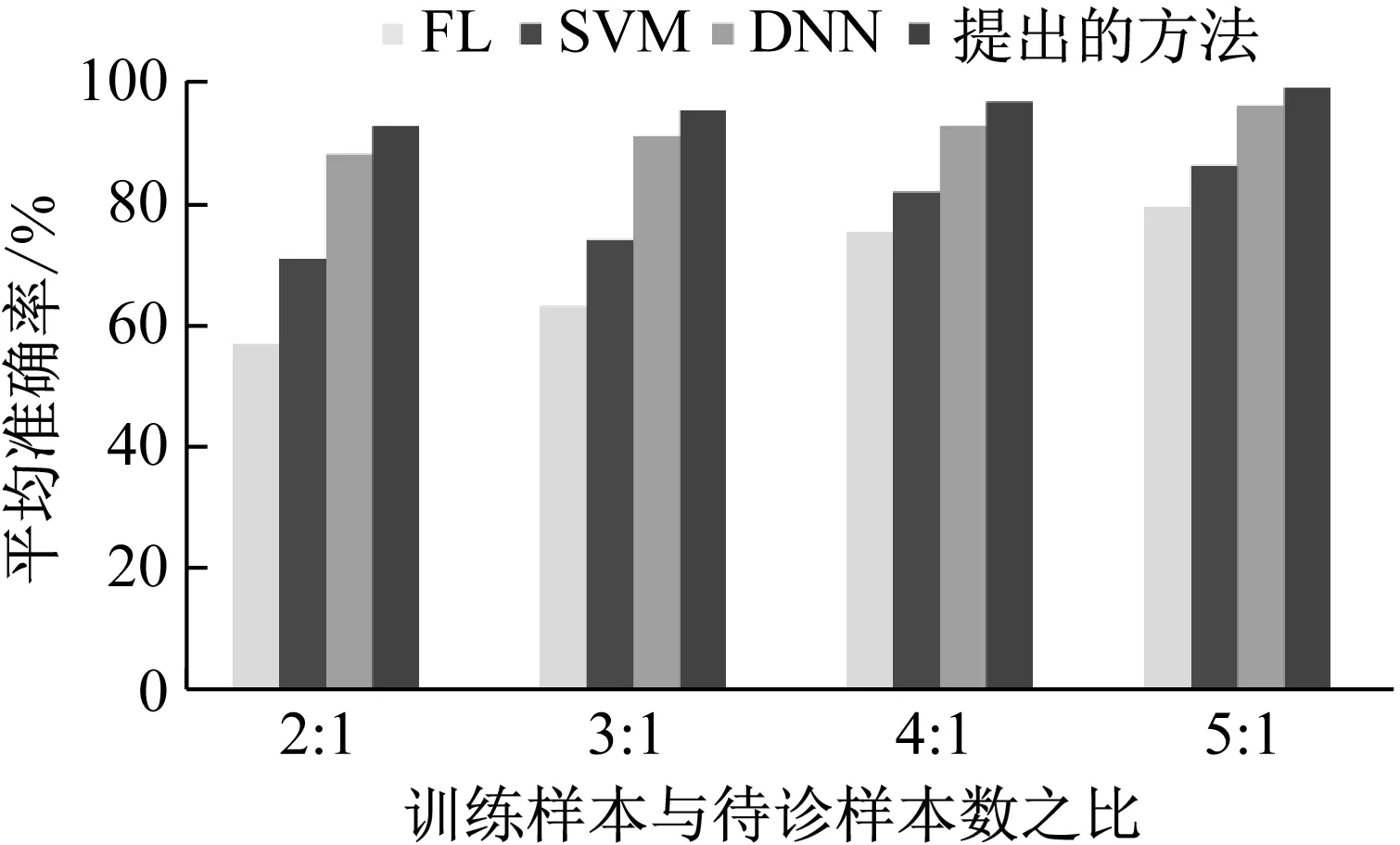
图7 四种方法的诊断结果
4 结 论
悲观多粒度粗糙集的限制条件过于苛刻,难于对滚动轴承的状态做出准确判断。为此,本文首先介绍了平均多粒度决策粗糙集和NNBC;然后,提出了基于平均多粒度决策粗糙集和NNBC的滚动轴承故障诊断方法;最后,采用滚动轴承实验组件进行故障诊断实验,结果表明该方法具有以下优点:
(1) 平均多粒度决策粗糙集不但保留了决策粗糙集容错性和灵活性的特点,还具有多层次数据挖掘特性,可通过多粒度结构的融合描述目标概念,并克服了悲观多粒度粗糙集限制条件过于苛刻的不足。因此,该方法非常适用于滚动轴承多种故障的诊断。
(2) 基于平均多粒度决策粗糙集的属性约简算法,可用于删除训练样本中冗余的征兆属性,获取敏感征兆属性,并降低训练样本征兆属性集的维数,从而改善同一滚动轴承状态的聚类效果,并减少模式识别过程中输入变量个数,降低计算复杂度。
(3) 从实验结果的比较分析中以看出,该方法在故障诊断准确率方面明显优于传统的滚动轴承故障诊断方法。利用该方法可准确地判断滚动轴承的故障类型及故障程度。
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
科技创新与应用(2020年6期)2020-02-29
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
智能系统学报(2017年3期)2017-08-01
青年文学家(2016年34期)2017-03-31
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
小星星·阅读100分(高年级)(2016年5期)2016-05-14
小星星·阅读100分(高年级)(2016年4期)2016-04-28
郑州大学学报(理学版)(2014年2期)2014-03-01
