
融合分类与协同过滤的情境感知音乐推荐算法
2019-08-16 12:20吴海金
福州大学学报(自然科学版) 2019年4期
吴海金, 陈 俊
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
音乐是人们生活中重要的娱乐元素,随着信息技术的发展,音乐资源呈海量增长态势[1]. 个性化推荐作为信息过载问题的有效解决手段,在音乐领域得到了较为广泛的关注[2],并取得了广泛应用. 目前几乎所有的音乐平台都提供个性化音乐推荐服务,例如Spotify、 Pandara、 豆瓣音乐电台、 网易云音乐等,不少平台因推荐的音乐较为准确而取得了较好的口碑. 当前大多数音乐推荐系统基于用户的历史行为,发掘用户的长期喜好[3]. 而在音乐推荐领域,根据一些学者的研究,用户对音乐的短期偏好容易受用户所处的情境影响[4],情境包含生理状态、 行为、 外界环境等因素[5],如果只考虑用户和被推荐的项目,会在一定程度上影响推荐系统的性能,个性化音乐推荐系统中很重要的一个环节是考虑用户当时的情境信息,并合理利用用户的情境进行个性化推荐[6].
针对如何融合丰富的情境信息,得到更能满足用户的个性化需求的推荐列表,以提高个性化推荐系统的性能和用户体验,本研究在传统协同过滤算法的基础上,融合了分类模型,实现基于情境感知的个性化音乐推荐算法,通过融入用户情境信息的相似度计算方法,使得传统的协同过滤算法具备情境感知的能力,并通过融合分类模型提高了推荐系统的性能,有效降低推荐过程的复杂度和改善冷启动问题,实现为用户提供符合当前情境的个性化音乐推荐.
1 融合分类模型与协同过滤的情境感知推荐算法
1.1 融入情境信息的协同过滤算法
协同过滤算法是在推荐系统领域中研究最为深入、 最为业界认可、 应用最为广泛的推荐手段[7]. 但传统的协同过滤推荐算法基本没有考虑情境信息[8],将不同用户不同情境下的兴趣偏好同等看待,忽略了用户兴趣随情境发生的变化,因而对推荐系统的性能产生影响[9]. 本研究将情境信息融入到协同过滤算法中. 协同过滤算法的核心思想是找寻近邻用户或近邻项目对象,根据近邻的程度,将用户或项目进行排序,从而得到top-N列表. 所以,基于协同过滤的推荐算法的核心步骤为用户或项目的相似度计算. 常见的相似度计算方法包括欧氏距离、 曼哈顿距离、 明氏距离、 余弦相似度、 皮尔逊相关度等[10]. 这些相似度计算方式各有侧重点,在实际应用中,往往是根据实际的场合进行选择.
由于情境信息种类繁多,上述相似度计算的方法实现较为复杂. 而融入情境信息的用户相似度计算方法更关心的是用户各类情境信息的区间是否一致,如是否都处于下雨天、 开心、 操场、 跑步等情境,即比较内容的相似度. 而海明距离常用于比较内容的相似程度,故采用海明距离计算情境信息的相似度,在一定程度上简化了相似度的计算,具体的处理方法为: 对于给定用户u的特征向量用U={u1,u2, …,un}表示,给定用户u的特征个数为u.length; 用户v的特征向量用V={v1,v2, …,vn}表示,sim表示用户之间的相似度,则可以通过公式(1)来计算用户之间的相似度.

(1)
融入情境信息的协同过滤算法的核心代码为相似度计算,将包含用户情境信息的训练集定义为T={(u1,u2, …,un), (v1,v2, …,vn), …, (x1,x2, …,xn)},则相似度算法的实现过程描述如下

算法1 融入情境信息的相似度计算伪代码输入: 训练集T输出: 用户相似度simStep1: Initialize sumStep2: For i from 0 to u.length If u[i]==v[i] sum++ EndStep3: sim= sum/u.lengthStep4: Return sim

图1 协同过滤模型示意图Fig.1 Collaborative filtering model
最后,给定一个相似度的阈值,当用户之间相似度大于这个阈值时,则判断两个用户为相似度高的近邻用户,将他们喜欢的音乐进行相互推荐.
综上,算法的实现过程主要包括融入情境信息的相似度计算以及近邻用户选取. 相似度计算主要是通过海明距离计算出包含用户情境的特征向量的相似度,然后根据协同过滤的常用处理手段获取近邻用户. 最后根据用户之间的距离及用户对音乐的喜好信息生成推荐列表,将与被推荐用户最相似的用户所喜爱的音乐呈现给被推荐用户. 协同过滤模型的示意图如图1所示,对于待推荐用户u,通过上文的融入情境信息相似度计算的协同过滤算法解算得到用户u的近邻用户集为{v,w,x,y},并根据近邻用户集与用户u的距离关系得到top-N推荐列表.
1.2 分类模型

图2 分类模型示意图Fig.2 Classification model
机器学习发展至今,诞生了许多可用于分类的算法. 分类算法各有特色,在前人的研究和实践的基础上,得出的结论是支持向量机(support vector machine, SVM)、 随机森林以及XGBoost[11]的分类效果较为理想. 本研究的分类模型将以SVM、 随机森林和XGBoost 3种算法分别构建单模型,分类模型示意图如图2所示.
采用机器学习算法的分类模型的训练过程,可以归纳为根据提供的训练数据进行学习,从而得到特征与标签之间的关系模型,由该模型可以根据相关特征为新数据贴上标签[12]. 将用户的心率、 情绪、 状态、 时间、 天气和位置等情境信息作为训练数据的特征集, 以及将所听音乐的风格、 年代、 节奏、 情感等类别信息作为训练数据的标签,通过3种分类算法分别进行机器学习模型的训练,构建听众在特定情境下所偏好音乐类型的推荐模型,再结合Top-N算法生成用户在特定情境下的音乐推荐列表.
1.3 模型融合
当推荐系统中项目数量庞大,而有的类别却在较小的数量范围内时,采用协同过滤算法,会出现用户-项目矩阵较为稀疏,在很大程度上影响推荐系统的性能[13]. 此外,每个人都有自己固有的类型偏好,而基于协同过滤的推荐算法得到的推荐列表包含的是近邻用户的全部类型偏好,可能包含了目标用户并不感兴趣的类型,因而对推荐系统的性能造成影响. 采用融合分类与协同过滤的推荐方法可以在一定程度上解决上述问题,这种推荐方式实际是由粗到精筛选过滤过程,根据用户情境信息分类获得用户的音乐类型偏好是粗粒度的过滤,在确定音乐类型的基础上进行协同过滤是细粒度的过滤,这种方式实现难度较低,而推荐的精度将会得到提升.

图3 模型融合示意图Fig.3 Process of hybrid model
假设通过分类模型得出用户u会偏好类型为9的音乐,而通过协同过滤模型得出的用户u的相似用户v喜欢听的两首音乐b1,b2都不是类型9,则忽略用户v所喜欢的歌曲,再从协同过滤模型中获得下一首应该推荐的音乐,直到满足推荐的音乐类型为9为止,实现分类模型和协同过滤模型进行模型融合,得出推荐结果.
模型融合的示意图如图3所示,其实现的主要步骤如算法2所示.

算法2 融合算法的构建输入: 数据集Data, 目标用户u输出: 目标用户u的推荐列表Step1: 根据前文介绍的数据预处理的实现方式将数据进行清洗得到规整数据格式的CSV子数据集, 然后进行通过训练好的分类模型得到用户音乐类型偏好Step2: 根据构建融入情境相似度计算的协同过滤推荐模型生成预推荐列表Step3: 根据两种算法得到的推荐候选集, 进行融合规则过滤操作, 对预推荐列表进行筛选, 得到最终的个性化音乐推荐列表
此外,对于个性化推荐系统因新用户没有历史数据而产生的“冷启动”问题[14],情境感知音乐推荐算法可以较好地解决该问题,新用户虽然没有历史数据,但可以根据该用户的当前情境信息,找到与该情境信息相似的已有用户,根据已有用户在该情境下的音乐偏好为新用户推荐音乐.
2 实验结果与分析
2.1 实验数据
为了验证本研究所提出的情境感知推荐算法的有效性,选取60名志愿者日常采集的音乐情境数据, 评估算法的性能. 志愿者佩戴特定的传感器,如智能手环、 智能手表等,采集用户心率、 运动状态等数据,并记录不同情况下的用户情境数据. 为了最大限度发挥特征价值的多样性,在不同的场景下收集数据,尽可能保证覆盖所有情境信息的类别. 收集的原始数据包含大约32 400条记录. 经过预处理后,完整且干净的数据集包含29 880条记录. 采用10次交叉验证的方式对推荐算法的性能进行验证.
2.2 评价指标
个性化推荐算法的评价指标不能完全等同于分类算法的指标,因为分类算法完全可以只用准确率等类似指标进行评价. 推荐系统的评价指标较为多元化,有准确率、 召回率、 平均绝对差异、 多样性和惊喜度等[15]. 过高的准确度会使得推荐列表的项目数量减少,提升推荐系统的多样性和惊喜度必然会使得准确率有所下降[16],而用户满意度可以综合评价推荐系统的性能. 因此,采用推荐准确率和用户满意度两个指标综合评估算法的性能,对研究进行验证.
准确率指的是推荐的列表中被用户标注为喜欢的项目数占列表总项目数的比例. 设Precision代表准确率,T(u)表示用户标注为喜欢的相关列表,R(u)为给定推荐列表,则准确率公式为
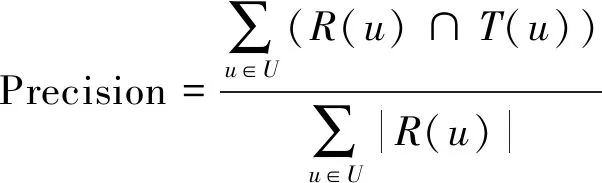
(2)
为了得到系统体验测评结果,另外邀请50名志愿者分别体验基于不同推荐算法的推荐系统,在一段时间后给出满意度评价,根据用户对两种系统的推荐列表进行打分,取打分的平均值为对该推荐系统的满意度. 此外,根据用户具有针对性的反馈,可以更好地改进推荐系统.
2.3 实验结果与分析
在协同过滤模型中,首先要知道用户情境相似度阈值大小对准确率的影响以及其具体的表现分布. 在协同过滤模型准确率验证的实验中,根据阈值的不同设计了实验,得到模型的准确率如图4所示. 从图4中可以看出,模型的准确率和情境信息的相似度阈值存在一定关系. 根据实验结果,本研究选取用户情境信息的相似度阈值为0.75.
在验证融合模型的准确率之前,对于分类模型的准确率进行了实验验证,分类模型预测的平均准确率如图5所示. 从实验结果可以看出, 随机森林和XgBoost算法的模型准确率较高.

图4 协同过滤模型准确率Fig.4 Precision of collaborative filtering model
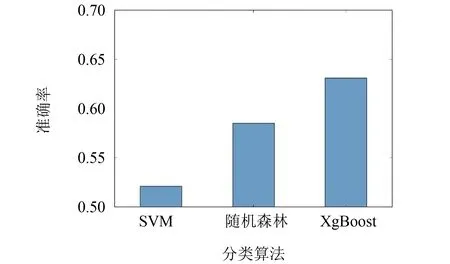
图5 分类模型准确率Fig.5 Precision of classification model
融合模型的准确率如图6所示. 用户满意度对比如图7所示. 由图6、 7可以看出,通过模型融合,算法的准确率明显提升,当融合模型中的分类模型采用XgBoost算法且推荐项目数为10时,模型的正确率最高,明显高于基于协同过滤模型的准确率,此外,融合模型的用户满意度也最高,由此可以得出,融合模型的策略是正确有效的.

图6 融合模型准确率Fig.6 Precision of hybrid model

图7 协同过滤模型和融合模型的用户满意度对比Fig.7 User satisfaction comparison user satisfaction between collaborative filtering model and hybrid model
3 结语
情境信息对个性化音乐推荐系统的性能有着重大的影响,针对如何融合丰富的用户情境信息,提出一种融合分类与协同过滤的情境感知音乐推荐算法,为特定情境下的用户提供个性化音乐推荐. 实验结果表明,融合分类与协同过滤的推荐算法比融入情境信息的协同过滤推荐算法更能提供准确率高和满意度高的推荐结果. 由于实验数据与涉及的情境信息有限,因此研究还有待进一步拓展与深入. 在分类模型中只是采用音乐的类型标签,并没有深入去分析音乐的音频特征,这在一定程度上会影响推荐算法的性能. 未来将尝试融合基于内容的推荐算法,分析音乐的音频特征,进一步提高分类模型的准确率; 考虑在推荐模型中融入更多影响因子,如用户的影响力、 可信度特征等,并采用机器学习算法分析各类因素的重要性,在融入情境信息等特征时考虑相关特征的权重进行推荐.
猜你喜欢
新班主任(2022年4期)2022-04-27
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
科学大众(2020年23期)2021-01-18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
汽车观察(2019年2期)2019-03-15
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
