
基于语义分割的车辆行驶车道定位方法
2019-08-16 12:06裴晨皓黄立勤
福州大学学报(自然科学版) 2019年4期
裴晨皓,黄立勤
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
视觉信息在车辆辅助驾驶中起到很大的作用[1]. 利用图像处理和计算机视觉技术,对车辆行驶车道进行定位,来保证安全的车距和正确的车道,并能对一些异常状况及时做出反应和处理. 在车辆行驶车道定位中,车道定位策略和目标识别很重要.
在车道定位策略中,车道线和车道的信息是可以利用的. 传统的车辆行驶车道定位方法,大部分是利用车道线检测来实现的. 采用 Hough 变换来检测车道线[2],利用道路的边缘信息来拟合直线段,但其抗干扰不好,复杂环境可能导致计算量过大; 采用设置阈值来分割车道线检测[3],但阈值的设置需要许多先验知识,不够灵活; 采用模版匹配来检测车道线[4],需要提前制作好不同类型道路样式的模板库. 为了解决这些问题,本研究利用完整的车道信息来辅助车道定位,将不同车道区域完整地分割出来. 而在图像语义分割方法中,传统采用阈值的方法,其阈值的选取需要实验确定,适用于色彩对比度强的图像; 采用区域分割[5]的方法,计算量过大; 聚类分析的方法[6],需要人为干预参数,对噪声和灰度不均匀敏感,对于K-means聚类来说,聚类簇数K没有明确的选取准则,需要实验获取; 采用深度学习的方法[7],利用卷积神经网络(convolutional neural network, CNN)卷积特征来分割语义,在图像上获取不同的窗口,预测结果作为窗口中心像素前景背景的概率[8]. 在图像识别分割中,相比传统的手工特征,卷积神经网络表现出良好的性能. 但全卷积网络(fully convolutional network, FCN)[9]方法分割的结果粗糙,其感受野的大小是固定的; 而许多其他种类FCN[10-12]可以使结果更加精细,其中FCN结合条件随机场的方法得到的结果较好[13-14].
车辆辅助驾驶中对系统实时性的要求比较高,试验中希望找到一个在准确度和实时性上都具有不错表现的网络. 目标识别上,基于卷积神经网络的方法在效果和精度的表现上不错,如R-CNN[15]、 Fast-RCNN[16]、 Faster-RCNN[17]、 YOLO v2[18]等,试验中采用YOLO v2算法来进行目标识别.
本研究结合卷积神经网络,针对双车道进行分割,采用编码器-解码器架构网络实现端到端训练双车道语义分割模型,以达到检测实时性的要求. 利用YOLO v2检测前车车辆,结合车道分割结果做分析定位. 课题组利用卡尔斯鲁厄理工学院和丰田美国技术研究院公布的数据集(KITTI)中城市道路(urban marked, UM)数据,标注制作双车道训练集和测试集,用于不同车道分割.
1 车辆行驶车道定位算法
车辆辅助驾驶中,车道车辆检测分割的准确度和实时性同等重要. 研究利用语义分割对输入的车载图像进行道路分割,同时检测车载图像中车辆,然后对车辆行驶的车道进行定位. 整个系统分为多车道语义分割和车辆检测两个部分,最后融合结果,分析出车辆所在车道的位置,进行车道定位. 系统流程如图1所示.
1.1 双车道语义分割网络
图像语义分割一直是图像处理中受关注的部分,输入一张图像,对图片上的每一个像素进行预测分类. FCN全卷积网络的出现,使深度学习更好地用于图像语义分割,全连接层变为卷积层,适应任意尺寸输入、 输出低分辨率的分割图片.
车道分割设计网络基于SegNet网络[11],这是一种编码器-解码器网络架构,它的特点是训练参数更少、 速度更快、 内存需求更低,网络总体架构如图2所示. 输入车载视频中的图像,输出图像的车道分割掩膜图,分为对称的两个部分—前半段的卷积部分和后半段的反卷积部分. 卷积部分由4个卷积层、 4个批标准化(batch normalization, BN)[19]层加激活函数(rectified linear unit,ReLU)及4个池化层组成,主要作用是对输入图像进行特征提取,最后输出多个特征图,输入反卷积部分; 反卷积部分由4个上采样层和4个卷积层组成,对卷积部分的输出图进行反卷积,最后一个卷积层得到的特征图大小将与原始输入图像大小一致,再通过最后的3分类卷积层,得到整幅图像上每个像素点属于左车道、 右车道还是非车道情况.

图1 整体算法示意图Fig.1 Schematic diagram of the overall algorithm
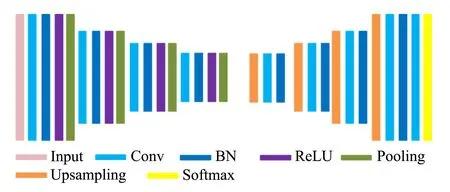
图2 网络结构Fig.2 Network structure
为了权衡精确度和实时性,对 SegNet 网络进行不同的池化层数、 卷积核个数、 卷积核大小的对比实验,分析其预测准确度(predicted accuracy, PA)和时间(t),实验数据采用利用KITTI数据制作的双车道数据集,实验结果如表1所示. 最终选取池化层数4层,卷积核个数32,卷积核大小7×7作为网络结构参数.

表1 不同网络结构参数的预测准确度和时间的对比
网络的卷积部分是卷积与池化交替对输入的图像进行卷积运算. 每个卷积核相当于一个特征提取器. 通过每个卷积-池化结构的作用,提取出图像的局部特征,然后采用最大值池化,于第4个池化层输出64个局部特征图,输出到反卷积部分进行处理.
本研究的反卷积部分采用与FCN不同的反卷积,过程如图3所示. 在编码部分做池化操作的时候,记录像素点的位置信息,在上采样阶段将保存下的位置信息重新分布像素,还原到池化前的图像大小,然后再进行卷积操作,使稀疏图像变回密集图像.

图3 本研究的上采样方法和FCN的反卷积对比Fig.3 Comparison of the upsampling method in this paper and FCN deconvolution
1.1.2SoftMax概率分类
SoftMax层在网络反卷积部分后,将反卷积得到的特征图输送进最后一层卷积层,该层卷积核大小为1×1,输出特征图个数为2,是为了实现最后的左道路、 右道路和非道路的3分类.
引入SoftMax层,对图像像素进行分类,输出左道路、 右道路和非道路的预测概率值,通过比较概率值大小确定最终所属类别. SoftMax层采用SoftMax回归模型,该模型是逻辑回归在分类问题上的推广,假设类别标签为y,有k个不同取值,输入X和标签y,表示为如下公式:
{(X1,y1), (X2,y2), (X3,y3), …, (Xi,yi)},yi∈{1, 2, 3, …,k}
其中:k=3.
假设对于每一个输入对应每个类别j的概率值P(y=j|X),输出一个k维向量,表示k个估计值. 假设函数如式(1)所示. 其中,θ1,θ2,θ3,θ4, …是模型参数.

(1)

(2)
1.2 车辆检测与分析
在节1.1中获得车道在图像上的位置,结合车辆检测就可以更精确定位车辆行驶车道的位置. 由于YOLO v2在如PASCAL VOC和COCO标准检测任务方面是最先进的. 性能比使用ResNet的Faster-RCNN和SSD[21]要好,而且运行速度明显快很多. 因此研究采用YOLO v2检测车道上的车辆.
1.2.1车辆检测YOLOv2网络
车辆检测使用YOLO v2网路,其基础网络模型是Darknet-19,包含19个卷积层和5个最大池化层,每个卷积层使用规范层来稳定训练,加速收敛和规则化模型. 利用标记的检测图像来学习精确地定位目标,同时使用分类图像来增加它的鲁棒性. 其具体网络结构如表2所示

表2 Darknet-19网络结构
在VOC2007+VOC2012的训练测试集上得YOLO v2和其他几个算法精度和速度的对比,如表3所示.

表3 YOLO v2与其他算法在VOC上的精度和速度对比
1.2.2车辆检测实验
实验使用YOLO v2检测车载图片下的车辆,标出车辆在图像上的位置,与第2节中双车道语义分割的结果融合,分析出车辆所在的车道的位置,实验结果如图4所示.

图4 YOLO v2检测车辆的结果Fig.4 YOLO v2 vehicle detection results
2 实验结果与分析
为验证方法的有效性,对双车道道路进行实验. 实验中的训练和测试数据利用KITTI道路数据制作,数据公布在开源网站github上. 实验硬件平台为酷睿i5-7500处理器,内存16 GB,GPU显卡为NVIDIA GTX1080TI,软件平台Cuda 8.0,Caffe.
2.1 制作的数据集
利用KITTI道路数据中的UM数据制作,训练数据83张图片,测试数据53张. 制作的数据可视化标注如图5所示.
2.2 双车道语义分割
2.2.1实验结果
采用优化的SegNet网络训练自制的双车道训练集,在测试集上测试,结果如图6所示.

图5 原始图像和可视化标签图Fig.5 Original image and the visually annotated image

图6 训练网络检测结果Fig.6 Detection results of network training
2.2.2实验评价
对双车道语义分割的实验结果进行评价,分为实验的速度和精度两个部分. 精度采用了PA、 MPA、 MIoU和FWIoU 等4种语义分割常用的标准[10].
定义:k+1个类(从L0到Lk),Pii,Pij,Pji分别表示分类正确的像素数量、 假正的像素数量和假负像素数量.
像素精度(pixel accuracy, PA)预测正确的像素占总像素的比例,如式(3)所示

(3)
均像素精度(mean pixel accuracy, MPA)指每个类内被正确分类像素数的比例,再求所有类的平均,如式(4)所示

(4)
均交并比(mean intersection over union, MIoU)表示正真数比上真正、 假负、 假正(并集)之和. 在每个类上计算IoU,之后平均,如式(5)所示.

(5)
频权交并比(frequency weighted intersection over union, FWIoU)根据每个类出现的频率为其设置权重,如式(6)所示.

(6)
实验中的测试集是利用KITTI数据制作的53张测试图像,结果如图7所示. PA、 MPA、 MIoU、 FWIoU平均值分别为0.991 5、 0.981 7、 0.964 2、 0.983 5. 实验速度测试结果如图8所示.

图7 实验评价曲线图Fig.7 Experimental evaluation curve

图8 实验速度曲线Fig.8 Experimental speed curve
2.3 车辆行驶车道定位
融合前车检测和车道语义分割结果,获得前车在车道的位置信息,分析车辆位于左车道还是右车道. 双车道分割网络输出图片的Mask图,根据Mask图画出双车道的中线位置,效果如图9所示.

图9 车辆行驶车道定位Fig.9 Vehicle driving lane positioning
3 结语
车辆行驶中定位和分析车道环境是车辆辅助驾驶的重要部分. 研究制作了针对双车道语义分割的数据集,设计改进的SegNet网络很好地解决了针对双车道语义分割问题,在测试集上速度55 ms,精度在0.95以上. 针对车辆车道定位问题,提出一种新的思路,把道路分成不同的车道来进行实验,取得不错的效果.
课题仅针对双车道的情况,实际车道场景中的车道数多样,还有更多复杂的情况,下一步研究是针对多车道的情况进行车道定位.
猜你喜欢
卫星应用(2021年11期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
中国交通信息化(2015年10期)2015-06-06
