
海洋经济统计数据质量控制方法探讨与实践
2019-08-13 03:41郑莉,彭星
海洋经济 2019年3期
郑 莉,彭 星
(国家海洋信息中心,天津 300171)
引言
近三十年来,我国海洋经济统计工作不断发展完善,通过制度统计、企业直报系统、调查等传统渠道及大数据等新兴渠道获取的海洋统计数据日益丰富,形成的海洋经济监测指标体系具有覆盖内容广,数据来源多且可信度不一等特点。然而,在实际统计过程中,海洋经济统计数据采集、处理、传输等一系列因素都可能对最终汇总结果产生影响,导致数据出现异常。在利用这些汇总统计数据进行海洋经济运行分析、海洋经济管理、决策制定及相关科学研究前,对海洋统计数据进行严格的质量审核与控制,保证报送数据的准确性和可靠性就显得尤为必要。
在国家统计局《国家统计质量保证框架》指导下,我国海洋经济统计数据的质量控制工作主要依据《全国海洋统计数据审核办法》、《全国海洋统计工作考评方法》等规范化管理办法,虽然建立了海洋经济统计数据审核、沟通反馈流程,形成了完整性、逻辑性、准确性等审核机制,数据审核工作仍存在审核方法简单、效率低、范围窄等不足,统计数据审核方法与工作机制有待完善。
关于统计数据质量控制,国外发达国家统计机构建立了比较健全的数据质量综合评价和管理体系[1-3],国内研究则相对起步较晚,侧重理论探索统计数据质量的涵义、管理和评估体系[4-9],而且针对海洋统计数据质量控制方法的研究文献较少,其中郭越等(2010)[10]指出可用逻辑判断法、增长率法、结构法、关联系数法、抽样调查法等方法监控海洋统计数据质量;郑琳等(2014)[11]提出了针对海洋监测数据的统计分布检验、值域检验、相关性检验等合理性质量控制方法,及时间序列检验、特征曲线拟合等代表性质量控制方法;向先全等(2015)[12]提出了逻辑一致性、值域一致性、时空分布检验等海洋环境数据质量控制方法。考虑到国内少有涉及海洋经济统计数据质量控制方法的研究文献,本文根据我国海洋经济统计数据特征,研究了适用于海洋经济统计数据管理与质量控制的方法并列举了实例,从而为海洋经济统计标准数据库建设、运行评估、政府决策提供高质量的数据支撑。
1 海洋经济统计数据质量内涵
海洋经济统计数据质量内涵的发展经历了以“准确性”为核心向以“用户需求”为核心以及从源头到终端全面质量管理的演变。当前,海洋经济统计数据的完整性、准确性、可比性、及时性,即“四性”是描述海洋经济统计结果预期性质的主要质量指标。
1.1 完整性
完整性是指海洋经济统计工作是否获得连续有效的统计数据,数据的总量是否满足预期的要求。主要表现在统计指标是否齐全,统计频次是否达到要求,其他必需的统计属性如指标单位、来源等是否有漏测漏报等。
1.2 准确性
准确性表示海洋经济统计结果与真实值的一致程度,是系统误差和随机误差的综合反映,决定海洋经济统计结果的可靠性。
1.3 可比性
可比性是指海洋经济统计数据在时间上和空间上的可比程度。这要求海洋经济统计的概念和方法在时间上保持相对稳定,保证数据的口径范围、计算方法在时间上衔接一致,在地区之间可比。
1.4 有效性
有效性是指利用海洋经济统计数据所产生的效益要大于采集数据的成本,即海洋经济统计工作的产出应大于投入。可通过减少统计数据重复调查、实现网络报送与审核等手段不断提高海洋经济统计数据的利用率。
海洋经济统计数据质量控制工作涉及数据的完整性、准确性、可比性和有效性,数据的完整性可根据在报送节点的填报率进行判定;数据的准确性可根据数据是否符合逻辑关系、经济变化趋势、统计分布规律等发现并剔除异常数据;数据的可比性根据数据在时间和空间上的变化是否异常判定;数据的有效性通过一定时期内数据是否保持合理利用率进行判定。
2 海洋经济数据质量控制方法与实证
根据海洋经济统计数据质量的内涵,结合海洋经济统计调查工作相关数据质量控制工作实践,将海洋经济统计数据质量控制方法分为基础性检验、逻辑性检验、值域范围检验、关联系数检验、数理统计检验五大类[13]。
2.1 基础性质控法
(1) 完整性检验
检验海洋经济监测指标数据是否报送,及指标相应统计属性信息是否完整(包括统计区域、企业名称、企业代码、指标名称、指标单位、统计频次、指标时间、数据来源等信息)。若存在指标缺报或属性信息填写不完整,系统将予以提示。需要说明的是,对于历年/季/月未报送的统计指标,可定义为无需报送;对于上期未报送统计指标,而当期未报送,定义为未报送。
特别说明:某些涉海企业通过重点涉(用)海企业直报系统填报数据时,为了提高指标数据的报送率和提交成功率,将很多指标填写为0,导致这类指标数据后期无法使用,此类问题也将通过系统检验出来认定为异常报送数据。
(2) 重复性检验
检验监测数据是否存在重复报送情况。同一指标名称、同一区域(企业)、同一频次的指标数据应具有唯一性。通过组织机构代码、单位名称等单位名录信息,对所有单位进行排重审核,消除同一单位多次报送相同指标数据导致的信息重复,以最近日期报送数据为准。若存在重复报送,系统将识别并予以提示。
2.2 逻辑性质控法
海洋经济统计数据逻辑关系检验法是以统计指标之间存在的包含、恒等以及相关等内在逻辑关系为判断标准,实现对海洋经济统计指标数据可信度的粗略检验。
(1) 增减逻辑法
海洋经济统计数据增减逻辑是指统计指标之间存在各种增减关系,通过计算看结果是否相互平衡。常见的平衡关系有合计等于各构成分项之和、年度数据等于季度数据的合计、季度数据等于月度数据的合计、当期累计值等于当期值与上期累计值合计,示例如表1。

表1 逻辑关系简要分类及举例
(2) 相关逻辑法
相关逻辑检验法所依据的逻辑关系是由紧密联系的客观海洋经济现象所决定的统计指标之间的高度相关关系。主要是根据指标间的比例关系、部分指标与整体指标间的结构关系等进行判断。其中,相对比例关系法指统计指标之间计算的相对指标应在特定的范围内取值;分项结构关系法指统计指标总量中不同项目的结构比重,反映总量的构成情况,通常经济指标的结构变化应比较平稳,示例如表1。
如通过逻辑关系检验,发现沿海某省初次报送的2016年海洋渔业增加值与海洋水产品、海洋渔业服务业和海洋水产品加工增加值之和,存在逻辑错误;某涉海企业报送的2017年1-10月累计营业收入均不等于1-10月各月份营业收入之和,存在逻辑错误;沿海某省报送的2011年直流冷却海水量大于海水直接利用总量,存在逻辑关系错误;某涉海企业上报的2018年1-4月累计主营业务收入与累计主营业务成本的比率为79,高于平均水平,数据质量存有可疑。
2.3 值域范围检验法
在海洋经济统计中,每个统计指标均有其对应的值域范围,通过值域统计规则检测该指标是否超出最大值或最小值。判断统计指标的值域范围可通过历史区间最大最小值法、增长率法、百分位数法、正态分布法等进行检验。
(1) 指标极值法
对海洋经济统计指标近十年或更长历史时间的值域范围进行统计,需求出指标在历史时间区间内的最大值和最小值等统计信息,海洋经济比重、比例等指标可用此法确定值域范围。
如2010-2016年近岸海域水质优良(一、二类)比例最大值为74.7%,最小值为63.4%,那么在经济平稳运行态势下,[63.4%,74.7%]可作为此指标的值域参考范围。
(2)指标增长率极值法
增长率法可根据本期数据与上期或历史同期数据增减变动,判断数据的增长或下降是否正常。增长率法的上下限可根据历史区间增长率的最大最小值和专家经验确定。
如通过基于增长率最大最小值的值域检验法,并结合专家经验法,可综合确定海洋渔业增加值增速的值域范围为 [-3%,15%],涉海企业资产总计增速范围为 [10%,30%]。沿海某省海洋与渔业局报送的2015年海洋渔业增加值增速高达1 384%,超出值域范围,存在可疑;某涉海企业报送的2018年1月资产总计值增长率为571950%,远大于30%,存在可疑。
(3) 百分位数法
百分位数法是根据样本数据,按照选定的百分范围计算相应的百分位数作为正常取值范围的方法。百分位数法可根据原始数据直接计算,亦可根据频数表计算。基本步骤如下:将n个观察值由小到大依次排列编上秩次:X1≤X2≤X3≤L≤Xn,X1为最小值,Xn为最大值。将n个秩次分为100等分,与r%秩次相对应的数称为第r百分位数,以符号Pr表示。例如在一组从小到大排列的数中,有10%的数等于或小于某个数,其余的90%都比这个数大,那么这个数就叫做第10百分位数,记为P10。用百分位数法确定r%参考范围就是求一组指标值的第r百分位数。采用百分位数法确定值域参考范围时,要考虑取单侧还是双侧,并根据具体情况选择百分界限。如果要确定中间95%范围,即分别除外2.5%最小值和2.5%最大值,这时需求P2.5和P97.5。
如根据百分位数法可检验得出某涉海企业报送的期末从业人员数的阈值范围为 [13 679,14 330](人)。根据2016年1月至2017年12月报送的期末人员数,若确定中间90%取值范围,可求得P5和P95分别为13 679人、14 330人,即当报送的期末人员数不在[13 679,14 330](人)范围内,可认为是可疑数据。
(4) 正态分布法
正态分布法是利用正态分布原理,运用正态曲线下面积与μ±μασ的关系来估计指标数值范围。其中,μ、σ分别为平均值、标准差(对于对数正态分布,μ、σ分别为几何平均数、几何标准差,估计范围为μσ±μα),μα为常数且可由t界值表查得。因此,可用μ±1.96σ(μσ±μα) 来估计正态分布(对数正态分布) 双侧95%的正常值范围,即有2.5%的例数其数据值大于μ+1.96σ(μσ1.96),另2.5%小于μ-1.96σ(μσ-1.96)。
如根据正态分布法可求得沿海某省海洋渔业增加值双侧95%的阈值范围为 [71.4,319.2]。根据相关研究文献,可认为该省海洋渔业增加值数据近似服从对数正态分布,根据2006-2017年该省报送的海洋渔业增加值数据序列,若确定中间95%取值范围,可用μσ±1.96来估计双侧95%的阈值范围为=[150.9*1.5-1.96,150.9*1.51.96]=[71.4,319.2],即当报送的海洋渔业增加值不在 [71.4,319.2](亿元) 范围内,可认为是可疑数据。
2.4 关联系数检验法
关联系数法来自于灰色系统理论,它主要是通过关联度分析提示变量之间动态发展态势的关联程度。在海洋经济发展系统中,往往存在一果多因的关系,将“果”作为参考数列,“因”作为对比数列(沿海经济、国民经济、世界经济等方面),就可计算参考数列与对比数列的关联系数,得到从基期到目标期参考数列和各对比数列变量之间的相关系数序列,由于这些变量相互存在着内在逻辑关系,因此变量之间发展态势也应保持一定的趋同(反)性,从而其关联系数值也应有一定的区间范围。若关联系数的数值从某时间点开始大幅变动或者由负(正)数转为正(负)数,即与对比数列相关性减弱或发展趋势相背离,则说明参考数列指标在该时点的数据存在可疑性,需要进一步核实确认数据的准确性。
如根据关联系数检验法可得出2016年沿海某省报送的海洋渔业产值数据可疑。从经济理论上看,海洋渔业产值与海水产品产量为强正相关,根据该省报送的2007-2016年海洋渔业产值数据和国家统计局公布的2007-2016年该省海水产品产量数据,计算得到两变量序列在 2007-2008、 2007-2009、 2007-2010、2007-2011、2007-2012、2007-2013、2007-2014、2007-2015、2007-2016年时间区间内的相关系数分别为100.0%、89.9%、96.0%、96.7%、98.1%、98.9%、98.7%、98.4%和53.6%,可知两变量在2015年及之前为强正相关,符合经济理论,但2016年相关系数值大幅降低,变量之间呈现弱正相关的关系,即说明2016年报送数据存有可疑性。
2.5 数理统计检验法
2.5.1 统计分布检验法
(1)基于常规统计分布的异常值检验法
根据相关研究文献,可知对于反映规模大小的海洋经济统计数据[14],其大多服从对数正态分布,可采用拉伊达(3σ)准则法、格拉布斯(Grubbs) 检验法、狄克逊 (Dixon) 检验法、肖维勒检验法检验其数据质量。而对于非正态分布的海洋经济数据,可依据《Ⅰ型极值分布样本离群值的判断和处理》(GB/T 6380-2008) 和《指数分布样本离群值的判断和处理》(GB/T 8056-2008) 中的狄克逊(Dixon)检验法、跳跃度检验法和欧文检验法检验其数据质量。
①拉依达(3σ) 检验法
若样本总体X服从正态分布,拉依达检验法用3倍的标准差即3σ作为异常数据的判别依据,当某个测量值xd(1≤d≤n) 的残差vi=|xd-|> 3σ时,其中则判定xd为异常数据,予以剔除。其中,n≥50时检验结果较严格,n≥20时检验结果较粗,n≤10时不适用。
②格拉布斯(Grubbs) 检验法
若样本总体X服从正态分布,格拉布斯检验法是根据顺序统计量的某种分布规律提出的一种判别标准,构造统计量其中观测值由小到大排列为x(1)≤x(2)≤…≤x(n-1)≤x(n),为样本均值,s样本标准差。选定显著性水平α,求得临界值G(α,n),若Gn≥G(α,n),则xn为异常值;若≥G(α,n),则x1为异常值。
③跳跃度检验法
若样本总体X服从指数分布,观测值由小到大x(1)≤x(2)≤…≤x(r)≤…≤x(n-1)≤x(n),对于任意1≤k<r≤n,样本均值的极大似然估计=可通过构造统计量M来检验样本中是否含有异常数据:-k) /(r-k):F(2r-2k,2k) 选定显著性水平α,若M≥F1-α(2r-2k,2k),则判定X(r)为异常值。其中k是使取值最大值时的k。
④欧文(Irwin) 检验法
若样本总体X服从Ⅰ型极值分布,则当样本量3≤n≤30时,使用狄克逊(Dixon) 检验法;当样本量30≤n≤50时,使用欧文(Irwin) 检验法:
根据样本观测值中的最小值x(1)、最大值x(n)以及次大观测值x(n-1),计算统计量In的值:其中:s=选定显著性水平α,查出临界值I1-α(n),若In>I1-α(n),则x(n)为异常值。
如主营业务收入近似服从对数正态分布,现以涉海企业直报中主营业务收入数据的对数为例,说明该方法的适用性。2016年1月至2017年12月某涉海企业报送月主营业务收入(单位:千元) 分别为615、47、2337、2003、2702、 2385、 1980、 1990、 2166、 3951、3299、4201、2835、2030、1019、1057、714、1928、 2344、 713、 968、 683、 1885、 1918。将其分别取对数:6.42、3.85、7.76、7.60、7.90、 7.78、 7.59、 7.60、 7.68、 8.28、 8.10、8.34、 7.95、 7.62、 6.93、 6.96、 6.57、 7.56、7.76、6.57、6.88、6.53、7.54、7.56,将其从小到大排序:3.9、6.4、6.5、6.6、6.6、6.9、6.9、7.0、7.5、7.6、7.6、7.6、7.6、7.6、7.6、7.7、7.8、7.8、7.8、7.9、7.9、8.1、8.3、8.3。计算对数序列均值=7.31,标准差σ=0.92。
根据拉依达(3σ) 检验法,判定3.85为异常值,即主营业务收入47为异常值。根据格拉布斯(Grubbs)检验法,选定显著性水平α=0.05,查表知G0.95(0.05,24)=2.644,对于3.9,G1=(-x(1))/s=3.74>G0.95(0.05,17),判定为异常值,即主营业务收入47为异常值;对于 8.3,Gn=(x(n))/s=1.12 >G0.95(0.05,17),判定为非异常值,即主营业务收入4 201为非异常值。
(2)基于探索性数据分析的异常值检验法
在无法通过经验分析获取海洋经济统计数据的统计分布情况下,可采用茎叶图法、字母值法、箱线图法等探索性数据分析法识别统计数据中异常数值。这些方法能够在不毁坏原始数据中其他数据的前提下突出表现极端或无用的数据,为评估数据准确性提供依据。
①茎叶图法
茎叶图是一种分析未分组原始数据的统计图,既能给出数据的分布状况,又保留着原始数据的个体信息,是有效的探索性数据分析工具。数据的高位数字对数据的大小起决定性作用,因此将高位数字按从小到大的顺序排成一列,作为“茎”,而把相应的低位数字从小到大排成行写在对应的高位数字后作为“叶”。样本的每一个数字被分配到茎上部分和叶上部分。
以2017年1月到2018年9月全国海运货物进口额同比增速(单位:%)为例说明该法适用性。增速分别为 25.97、47.36、29.82、17.52、 19.98、 18.97、 11.71、 12.94、 24.11、21.54、 22.66、 10.06、 30.69、 0.94、 8.34、18.25、 25.78、 12.55、 32.05、 23.18、 11.91,把这批数据从小到大排序得出:0.94、8.34、10.06、 11.71、 11.91、 12.55、 12.94、 17.52、18.25、 18.97、 19.98、 21.54、 22.66、 23.18、24.11、 25.78、 25.97、 29.82、 30.69、 32.05、47.36。
将以上同比增速数据用茎叶图表示如下:
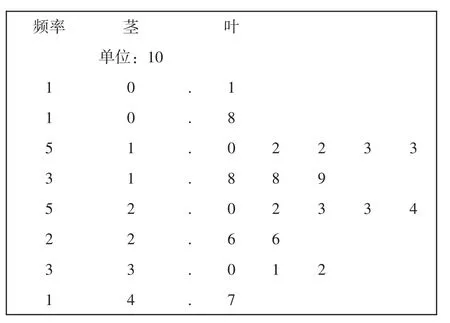
图1 2017年1月到2018年9月全国海运货物进口额同比增速的茎叶图
现对以上茎叶图作出解释。最左侧频率为茎上叶的个数,茎单位为10,如第一行茎值为0,只有1片叶子,叶值为1,则两者合在一起表示真实数值为0×10+1=1;再如第三行茎上有5片叶子,茎上第二个数为1×10+2=12。对于那些远离中行的数据怀疑其为异常值,如1和47,可对其进行进一步的检验。
②字母值法
字母值是一组总括值,实质是从数据序列中系统地提取的一些观测值。其方法是将数据按由小到大顺序排列,计算出中位数、四分位数、极端值,组成五数总括值。用FU表示上四分位数,FL表示下四分位数,定义四分展布为:dF=FU-FL,通常将在区间(FL-1.5 dF,FU+1.5 dF)之外的数据看做异常值。这种方法简单易操作,对于大样本里异常值的检验效果较好,但对于小样本则显得比较粗糙。实际问题中,对分离出来的数据需进行进一步的检验才能确定其是否为异常值。
以2017年1月到2018年9月全国海运货物进口额同比增速数据为例,极端值为X(1)=0.94,X(21)=47.36,中位数是X(11)=19.98,下四分位数FL=12.23,上四分位数为FU=25.875。四分展布dF=FU-FL=5.895,在区间(3.387 5,34.717 5) 之外的数据为异常值,则将0.94和47.36视为异常值进行进一步检测。
③箱线图法
首先构造五数总括,接着算出四分展布和基于四分展布的最大和最小观测值,最小观测值为FL-1.5 dF,最大观测值为FU+1.5 dF。然后画一个长方形,使长方形的两边分别在下四分数、上四分数位置,中间一道在中位数位置,再从两端向外各画一条线直到两个预测点,称之为“胡须”。如果存在离群点小于最小观测值,则胡须下限为最小观测值,离群点单独以点列出。如果没有比最小观测值小的数,则胡须下限为最小值;如果存在离群点大于最大观测值,则胡须上限为最大观测点,离群点单独以点列出。如果没有比最大观测值大的数,则胡须上限为最大值。
以2017年1月到2018年9月全国海运货物进口额同比增速数据为例,其上下预测值点分别为34.7和3.4,最小值0.94小于下预测点,最大值47.36大于上预测点,因此离群点为0.94、47.36,胡须的上下线分别为最大值和最小值。所以其箱线图如下:
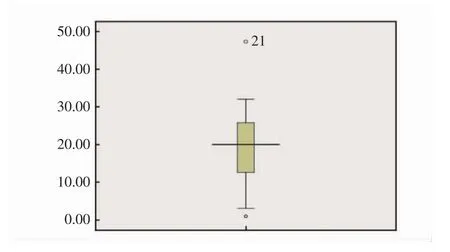
图2 2017年1月到2018年9月全国海运货物进口额同比增速的箱线图
2.5.2 计量模型分析检验
由于海洋经济统计指标之间关系十分复杂,相关逻辑检验法在检验数据质量时经常失效,此时需要借助传统回归模型、经典时序模型、面板数据模型等计量经济模型,选取样本数据对构建的模型参数进行估计,再根据相应理论或假设判断其统计数据的质量。通过构建计量经济模型,可从模型参数可靠性分析、异常点诊断以及预测误差分析等方面评估统计数据的质量。
(1) 回归模型检验法
对于存在线性关系的海洋经济统计变量,可通过构建线性回归模型,从参数可靠性、残差等角度诊断与识别异常值。以经典的多元线性回归模型为例,矩阵表示为Y=βX+ε,其中,Y是n×1的观测向量,X是n×(p+1)矩阵,β是(p+1)×1参数向量,ε是n×1随机误差向量且满足ε~N(0,σ2)。使用最小二乘法估计得到参数β估计值为可得向量Y的拟合值的残差定义为ri=yi-,即为第i次观测值的残差。
对于多元线性回归模型,可从以下两个方面诊断异常值:(1)参数的经济意义与稳定性分析,若参数值βˆi不在理论取值区间内,或不同时期或者不同经济体上的取值变动超出了理论变动范围,则说明样本数据可疑。(2)残差分析法,残差较大的观测点为可疑点,可通过观察残差rˆi对拟合值yˆi或自变量xi的散点图诊断识别出异常值点。
如通过线性回归模型可检验得出2001-2005年及2011年海洋生产总值与海洋渔业产值数据存有可疑。利用2001-2016年海洋生产总值(yi)与海洋渔业产值(xi),构建一元回归线性模型,得到模型为yi=14.26xi-6541.77,模型的拟合值R2为0.95,海洋渔业产值的回归系数大于0符合经济学意义,两个参数的P值显著。由于海洋生产总值与渔业产值均为水平数值不是比例数值,因此采用相对拟合残差诊断异常点,假设给定允许的相对拟合误差限度δ=0.1,则由计算结果可知,2001-2005年及2011年相对拟合残差大于0.1,存在残差偏大的现象,因此判断可能存在异常值。
(2) 时间序列模型检验法
对于长时间序列的海洋经济高频统计数据,可通过建立时间序列模型判别数据是否符合参数的发展变化趋势,从而识别可疑值。ARMA模型是最常用的拟合平稳时间序列的模型,若为它的前期值以及当前和前期随机干扰的线性函数,可构建MRMA(p,q)模型可如下:

其中,{Yt}为自回归移动平均序列,φk(k=1,2,…,p)自回归系数,p为自回归阶数,θk(k=1,2,…,q) 移动平均系数,q为移动平均阶数,随机项μt是均值为0,方差为的白噪声序列。当q=0时,上式为AR(p)模型;当p=0时,上式为AR(q) 模型。若时间序列在d阶差分后平稳,称为自回归求和移动平均模型,即ARIMA(p,d,q),其中,p,d,q分别为自回归、差分和移动平均的阶数。在海洋经济统计指标中,很多时间序列存在明显的趋势项,属于非平稳时间序列。
对满足ARMA(p,q) 或ARIMA(p,d,q)的时间序列 {Yt},通过计算待评估指标在评估期内的实际值与模型预测值的相对预测误差PT+j,(j=1,2,…,k,k为评估期样本容量),并与事先给定的准许限度δ比较可判断数据质量,若|PT+j|>δ,那么可初步判定YT+j数据存有可疑。
如通过对沿海某省海洋生产总值构建ARMA模型,可检验得出2003-2006年和2010年该省海洋生产总值数据存有可疑。利用2001-2017年沿海某省海洋生产总值时间序列数据构建ARMA(2,1)模型,得到模型为yt=0.98yt-2+μt+0.92μt-1+50 088.53,模型的拟合值R2为0.98,自回归系数和移动平均系数符合经济学意义且P值显著,对于给定的准许限度δ=0.1由模型进行静态预测可得相应年份预测值,与实际值比较,得2003-2006年和2010年相对预测误差数值较大,因此判断可能存在异常值。
3 结论
本文根据海洋经济统计数据质量控制的要求及内容,以评估统计数据的完整性、准确性、可比性、及时性为评估内容,提出了海洋经济统计数据基础性检验、逻辑性检验、值域范围检验、数理统计检验四大类质量控制方法,并进行了实证检验,以期为海洋经济统计调查实践部门开展数据质量控制工作提供更多可操作性的参考依据,解决了海洋经济统计数据质量审查与控制的一部分难题。
在今后海洋经济统计数据控制与管理工作中,在充分注重基础性检验、逻辑性检验、值域范围检验的同时,应不断加强与各类外围指标(如科技、教育、环境等)的相关性分析与检验研究、数理统计检验等,使海洋经济统计数据质量控制走上规范化、科学化,并不断推进海洋经济数据质量控制工作的信息化,从而提高海洋经济统计工作技术水平和工作效率。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
现代农业科技(2019年19期)2019-11-21
全球化(2018年6期)2018-09-10
中国经贸导刊(2018年12期)2018-05-29
理科考试研究·高中(2017年10期)2018-03-07
现代法学(2018年1期)2018-02-02
暨南学报(哲学社会科学版)(2016年11期)2016-11-26
世界热带农业信息(2014年8期)2014-09-23
