
人类面部属性估计研究:综述*
2019-08-13 05:06马廷淮陈松灿
软件学报 2019年7期
曹 猛, 田 青, 马廷淮 , 陈松灿
1(南京信息工程大学 计算机与软件学院,江苏 南京 210044)
2(南京航空航天大学 计算机科学与技术学院,江苏 南京 210016)
近年来,在计算机视觉与模式识别等领域,人脸相关研究得到了越来越多的关注.这主要由于人脸拥有丰富且稳定的特征信息,且易于被摄像头等仪器捕捉,进而被广泛应用于人机交互[1]、智能消费推荐[2,3]、访问控制[4-6]和辅助身份识别[1,7]等领域.
当前,人脸属性估计相关工作主要集中在人种估计、性别识别、年龄估计等几个方面.在相关研究方向上,分别已有大量工作被提出.例如,文献[8,9]利用集成学习进行人种分类估计;文献[10-25]借助贝叶斯分类器和SVM分类器等进行人脸性别识别;文献[26-61]将人类年龄估计分别视为分类问题、回归问题或者混合问题进行研究;文献[62]基于字典学习进行人脸老化合成研究等.然而,相关研究[26,63-65]表明,不同面部属性之间存在关联性影响,并且某一属性估计受到其他属性的影响.因此,依据是否考虑人脸不同属性之间的内在关联和影响,本文将现有人脸面部属性研究工作划分为两大类,如图 1所示:一是未考虑不同属性间关联影响的独立属性估计方法,这与朴素贝叶斯理论[66]中不考虑属性间关联、独立对待不同属性的假设相类似,因此本文称其为朴素的(naïve)方法;二是考虑并利用不同属性之间关联影响的属性估计方法(例如,男女之间存在老化差异,该差异会对人类面部年龄估计准确性产生影响[26]),在建模估计面部属性时,考虑面部其他属性对当前属性估计的影响,能够更好地迎合人脸属性演化的自然规律,因此,本文将该类方法称为自然的(natural)方法.
尽管目前已有大量的人脸属性估计相关工作被提出,然而研究者们通常基于 FG-NET[6]、Morph[3]、Adience[67]、CACD 2000[68]等单一数据集进行研究.而单一的相关数据集普遍存在属性标记不完备(如FG-NET、CACD 2000仅有年龄标签)、样本缺失(如Morph样本的年龄标记空间为16岁~77岁,缺少0~15岁样本)、样本不均衡(如Morph含有55 000多张人脸样本,其中男性样本占84.6%;黑种人与白种人样本占总体的96.4%,黄种人与其他人种仅占 3.6%)等固有缺陷,这将严重影响属性估计器的识别准确性,并限制其泛化性能.因此,可基于多属性跨库标记以扩充训练数据集,并构建人脸年龄、性别和人种等多属性联合估计模型,探索属性之间和属性内在的关联,以实现更可靠的属性联合估计算法.
本文第1节总结并分析朴素的人脸年龄、性别、人种等面部属性估计相关工作.第2节回顾自然的人脸年龄、性别和人种等面部属性识别相关工作.第3节探索未来的面部属性估计研究方向.最后,对本文进行总结.
1 朴素的人脸面部属性识别
本节主要回顾朴素的人脸年龄、性别、人种等面部属性识别相关工作,即完全不考虑属性间关联影响的单一属性识别.
1.1 人种分类
人种分类(race classification,简称 RC),顾名思义是对给定的人脸图像识别出其属于哪一类人种,例如白种人、黑种人、黄种人等人种类型,如图2所示.
相对于性别和年龄属性,人脸人种估计相关工作较少.代表性工作如下.
(1) 文献[8,9],对于给定的人脸图像,先抽取 Haar-like特征(简单来看,该特征反映了图像的灰度变化情况,能够描述简单的图形结构,对边缘与线段较为敏感),然后采用Adaboost集成分类器进行人种估计,并在FERET等人脸数据集上获得了较好的人种分类结果.
(2) 文献[72],首先提取灰度图像的人脸外观特征,然后使用多尺度描述算子提取人脸特征,并利用主成分分析(principal component analysis,简称PCA)进行特征降维,最后借助线性判别分析(linear discriminant analysis,简称LDA)实现测试人脸的人种分类.
1.2 性别识别
所谓性别识别(gender recognition,简称GR),即对给定的人脸图像估计判断其为男性还是女性,如图3所示.
不同于RC的多分类问题,人脸性别估计为二值分类问题(非男即女).其代表性实现方法总结如下.
(1) 贝叶斯分类器(Bayesian).文献[10,11]先将给定人脸图像分割成多块互不重叠的网格块,然后通过学习出来的公共数据库L获取相似网络块表示,最后使用这些相似网格块进行后验概率估计,获得性别估计结果.
(2) 支持向量机(SVM)分类.文献[12-17]首先提取脸部特征,经过降维获取主要面部特征,最后使用SVM分类器得到性别识别结果.其中,文献[13,14]直接借助线性 SVM 分类器;为应对人脸样本的线性不可分问题,文献[12]采用高斯径向基函数(radial basis function,简称RBF)核化的非线性SVM进行人脸性别分类;并且,为了更好地融合利用人脸不同部件的语义判别信息,文献[15-17]通过集成头部、面部、眼部和嘴(如图4所示)等不同部位的性别识别结果,以得到最终的性别识别结果.
(3) 贝叶斯与 SVM 融合分类.为应对复杂的人脸获取环境并充分利用人脸区域的特有信息,文献[18]提出人脸多区域SVM性别识别融合的GR.其算法流程如图5所示,通过贝叶斯准则(见公式(1))融合人面部不同区域的决策结果获取GR.
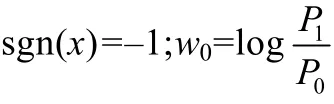
其中,PFP和PFN分别表示分类器判别当前样本为女性的正确概率和错误概率,δ(x)表示当x为0时,函数值为1,反之为0.
(4) 决策树.为挖掘利用三维人脸的空间分布信息,文献[19]首先提取人脸的三维梯度和空间距离信息,然后利用随机森林(random forset)法对提取的面部特征进行性别分类.
(5) 极速学习机.文献[20]采用极速学习机(extreme learning machine,简称ELM)构建性别分类网络.与传统的神经网络不同,ELM不需要迭代地调整学习参数,在设定好网络结构后,仅需随机初始化输入层到隐藏层的权值,隐藏层到输出层的权值即可直接解出,进一步提高了人工神经网络的训练效率.典型的ELM由输入层、隐藏层、输出层构成,其网络输出可表示为
其中,W1表示输入向量到隐藏节点层的随机权重矩阵,σ表示激活函数,W2为隐藏节点层到输出向量的权重矩阵,Ypredict表示网络的预测输出.当W1随机初始化后,W2可由最小二乘法计算得出(见公式(4)、公式(5)).
其中,Yreal表示期望输出,σ(W1X)+表示矩阵的Moore-Penrose广义逆.
(6) 神经网络.鉴于深度卷积学习(convolutional neural network,简称CNN)在计算机视觉等领域的成功应用,研究人员开始将CNN用于性别识别之中.为此,文献[21-25]首先提取归一化的人脸样本集,然后借助CNN提取人脸语义表示并采用“端-端(end-to-end)”学习方式训练性别分类器,在 Morph等人脸数据库上获得了更准确的GR结果.其流程如图6所示.
1.3 年龄估计
所谓年龄估计(age estimation,简称AE),就是根据给定的人脸图像估计其年龄值(或年龄范围),如图7所示.
截止目前,已有大量AE工作被提了出来.依据这些工作的方法类型,本文将其归纳为基于分类的AE、基于回归的AE、基于分类与回归混合的AE这3种类型.
1.3.1 基于分类的AE
若将年龄(诸如0岁、5岁、23岁等)看成互不相关的离散类,则AE可视为多分类问题.
年龄相关特征表示在 AE中的利用.文献[35,36]分别采用非负矩阵分解(构建图像局部信息)和独立成分分析(获取图像本质结构特征)的方法,构造低维子空间获取人脸特征,然后采用浅层神经网络作为年龄估计器进行 AE.随后,文献[26-34]将更丰富的特征描述方法应用至 AE当中,主要包括主动外观模型(active appearance model,简称AAM)、生物启发特征(bio-inspired feature,简称BIF)、局部二值模式(local binary pattern,简称LBP)等,然后借助SVM进行年龄分类.
然而,上述研究方法仅将年龄看作是互不相关的离散类,并没有将年龄的有序信息(例如,20岁大于10岁,却小于25岁)考虑其中.
考虑年龄有序性的 AE.文献[37]提出了一种 LBP特征的代价敏感版本(cost-sensitive local binary feature learning,简称 CS-LBPL),将代价敏感学习融入 LBP特征当中,然后使用超平面序列排序器(ordinal hyperplanes ranker,简称 OHRanker)借助年龄的有序性进行 AE分类估计.与文献[37]相异,文献[73]考虑直接在特征上利用年龄的有序性,该文作者提出一种用于保持人脸图像局部流型结构与年龄间序列特性的特征提取方法,具体模型见公式(6).
其中,M表示原始图像特征维度,d表示获取后的特征子空间维度,yu表示是否利用原始特征中的第u维特征.在公式(6)中,第1项用于获取人脸图像的局部流型结构信息(用来刻画M维原始特征各自的权重),第2项用于保持年龄间的有序信息(利用wu维护),超参数α用于平衡两种信息之间的重要程度.通过最大化这一模型,可以获得一个较小维度的既保持序列信息又保有面部局部的流型结构,同时也保持了人脸特征子空间的相对完整性,最后通过该特征子空间,借助OHRanker获取AE结果.
考虑年龄近邻相似性的 AE.年龄属性不仅具有序列性,同时还具有近邻相似性.如图 7所示,对于同一个人的人脸图像,18岁时,与其 16岁和 20岁时的面部较为相似.为此,文献[38]提出采用标记分布学习(label distribution learning,简称LDL)方法刻画年龄属性的近邻相似特性.对于年龄标记,LDL并不认为其为单一的标签,而是将其转成一个标记分布向量(包含临近年龄的描述度),并将标记分布向量作为训练集中的类别信息.例如,20岁的年龄图像同样也可以作为标记为21岁的样本,只是描述度相比描述20岁时要低,即真实年龄的描述度最高.当前样本辅助描述(标记)的年龄距离真实年龄越远,描述度越低,且所有描述度之和为 1.文献[38]通过条件概率假设,利用最大熵模型来构建映射关系,采用KL散度作为衡量预测分布和真实分布距离的损失函数,获得了比较好的效果.然而,这些年龄标签分布需要基于某些先验假设从训练样本中获得,年龄近邻关系的描述必然不是十分准确的.同时,由于人类各阶段年龄变化速度不同,各年龄阶段相似度描述也就相异(如图 8所示),文献[39]提出一种自适应版本的LDL(adaptive label distribution learning,简称ALDL)来解决上述问题.鉴于文献[38]使用固定的标记分布以及文献[39]对于不同样本集分布描述不灵活的缺陷,文献[74]提出基于数据依赖的标记分布算法.
同时利用年龄有序性和近邻相似性的 AE.为建模利用年龄类的有序性和近邻相似性,文献[42]利用马氏距离度量,构建了如下度量目标函数,以学习有序度量空间来实现AE:
跨库年龄类别互补的 AE.为解决单一年龄库存在部分年龄样本不完备的问题(即某些年龄类别无对应训练样本),文献[44]尝试跨越多个年龄数据库构建混合表示空间(如图 9所示),利用典型相关分析(canonical correlation analysis,简称 CCA)合并样本空间,并在所得样本表示空间通过样本联合表示构建年龄估计器,并实验验证了其优越性.
借助深度神经网络的AE.近年来,深度学习在计算机视觉、模式识别等领域得到大量成功的应用.相较于以上传统方法将特征表示(feature representation)与目标决策(decision making)分离学习的模式,深度学习通常以end-to-end学习方式将二者融合到一起同时进行学习,并可在特定任务上取得更优的性能.受此启发,文献[75-78]等借助CNN或VGG网络抽取图像特征,然后采用Softmax函数等分类方法预测年龄实现AE.其中,文献[75,76]采用较深的 VGG-16网络结构以获取更高维的特征表示.为防止训练过拟合,同时也为了利用年龄属性间的近邻关系,文献[40,41]借助高斯分布生成年龄分布标记,并采用IMDB-WIKI数据集微调网络以获取更好的泛化能力.
1.3.2 基于回归的AE
基于分类的AE方法将不同的年龄模式视作相互独立的普通的多类问题进行处理,然而人脸面部老化是一个连续和渐变的过程.因此,将 AE视作连续的回归问题加以处理似乎更为合理.为此,文献[13,45-51]尝试从人脸图像中提取不同的特征表示,然后借助回归器(如支持向量回归,SVR)进行年龄回归预测.其中,文献[45]采用先提取人脸不同区域的特征,然后借助贝叶斯准则融合特征以获取分层的人脸特征表示,如图10所示.
文献[47,49,51]采用多元岭回归模型(multi-ridge regression,简称mRR)来拟合年龄回归函数.mRR优化目标如下所示:
其中,yi表示期望输出,W表示投影矩阵,b表示偏置项.在公式(8)中,第1项用于估计拟合损失,第2项用于控制模型复杂度,当λ取 0时,模型退化为普通的最小二乘线性回归问题.然而,文献[52-54]认为,相对于线性回归模型,二次回归模型具有更好的年龄估计拟合能力,并通过如下优化目标实现对年龄估计器f(xi)的学习:
其中,f(xi)=α0+α1Txi+α2Txi2表示二次年龄回归模型(αi表示回归系数),yi表示真实年龄标签.
文献[55]认为:(1) 人脸老化模式不可控;(2) 存在个人因素;(3) 人脸老化模式是随时间而变化的.基于以上考虑,文献[55]将人脸按时间顺序排列构建年龄模式空间(aging pattern subspace,简称AGES)(如图11所示).鉴于所用数据库中每个个体年龄标记存在部分缺失的问题,该文作者提出一种编码再解码的方式重建缺失的年龄模式,并构建年龄模式空间进行 AE.具体来说,使用相同年龄图像均值初始化缺失部分xl,并与已存在部分xa用PCA降维后,再重新变换回原始空间,利用重建后的xanew与xa进行误差估计;反复上述过程,直至重建误差低于预定值.
文献[56]为了保证局部语义相似,借助马氏距离度量,重新调整同一邻域内样本对的距离,同时扩大邻域外部的样本距离,构建空间度量模型mkNN,并将其用于AE度量.mkNN目标函数如下:
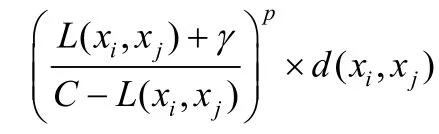
文献[47]为利用年龄类的有序性和近邻相似性,将累积属性编码(cumulative attribute coding,简称CA)融入mRR模型当中,保证人脸的累积变化特性.其中,CA编码的编码长度与当前所有样本的最大年龄相关(如,最大年龄为100岁,编码长度为101),具体表示为
其中,y表示样本年龄,li表示第i位编码.为利用CA编码间的关系,文献[49]借助差分运算将CA编码的0阶关系与1阶关系融入年龄估计模型,获得了性能更优的AE结果.
在深度学习方面,文献[79]在CNN网络中融入有序回归思想,在Morph II数据集上取得较好的AE结果.文献[71]借助同一网络模型主体架构,对比了5种方案在AE问题上的识别性能,发现基于拉普拉斯损失的回归型方法略优于其他对比方法.这 5种方案分别为基于交叉熵损失的分类型方法(分别采用 One-Hot编码和LDL编码两种标号编码方式)、基于最小平方损失和基于拉普拉斯损失的回归型方法以及基于有序损失的回归型方法.与此同时,文献[69]在CNN网络中借助CA编码的累积特性以解决训练样本类分布不均衡问题,提出采用对比信号来刻画人脸有序性以增强特征表示的判别能力,并构建 D2C网络实现 AE.D2C网络结构如图12所示.
其中,CRL(comparative ranking layer)用于学习样本的排列函数f(即若输入样本xi年老于xj,则f(φi)>f(φj),φi与φj分别表示样本i,j的特征向量).D2C网络整体损失函数定义为
其中,α与β为超参数,第1项对应年龄预测的损失项,第2项对应CA编码损失,第3项辅助约束样本排序.文献[69]认为,年龄的有序性比单一的年龄标签信息更加稳定.更为重要的是,通过CRL构建样本的序列关系可实现重复利用训练样本,以减缓样本类不均衡的状况.
1.3.3 基于分类与回归混合的AE
为了获得性能更优的年龄估计器,文献[48,57-61]采用分类和回归相结合的策略实现 AE.其中,文献[61]认为,SVR回归预测年龄不精确,仅能预测全局的老化趋势(如图 13(a)所示).为此,该文提出借助局部调整策略来构建LARR(locally adjusted robust regressor)估计器,并利用其在测试人脸样本上进行年龄识别.具体而言,采用局部偏移(如图13(b)所示)策略,使得预测年龄ypredict更接近真实年龄yreal(即期望yreal∈[ypredict-d,ypredict+d]);为了获取每类偏移方向,文献[61]还采用二叉树构造多分类SVM进行最后的决策.之后,很多对LARR的改进工作被提了出来,如文献[60]将流型学习融入LARR;文献[59]对LARR进行了概率化扩展,并在UIUC-IFP-Y等数据集上取得了比LARR更优的AE识别结果.在深度学习方面,文献[57]采用CNN和LDL分别对人脸图像进行特征表示与年龄编码,通过集成两套网络(一套基于分类、一套基于回归)的预测结果实现AE.
1.4 性能对比
本节通过列表对比形式对有代表性的人脸单一属性估计工作给出总结性性能对比.具体见表1.
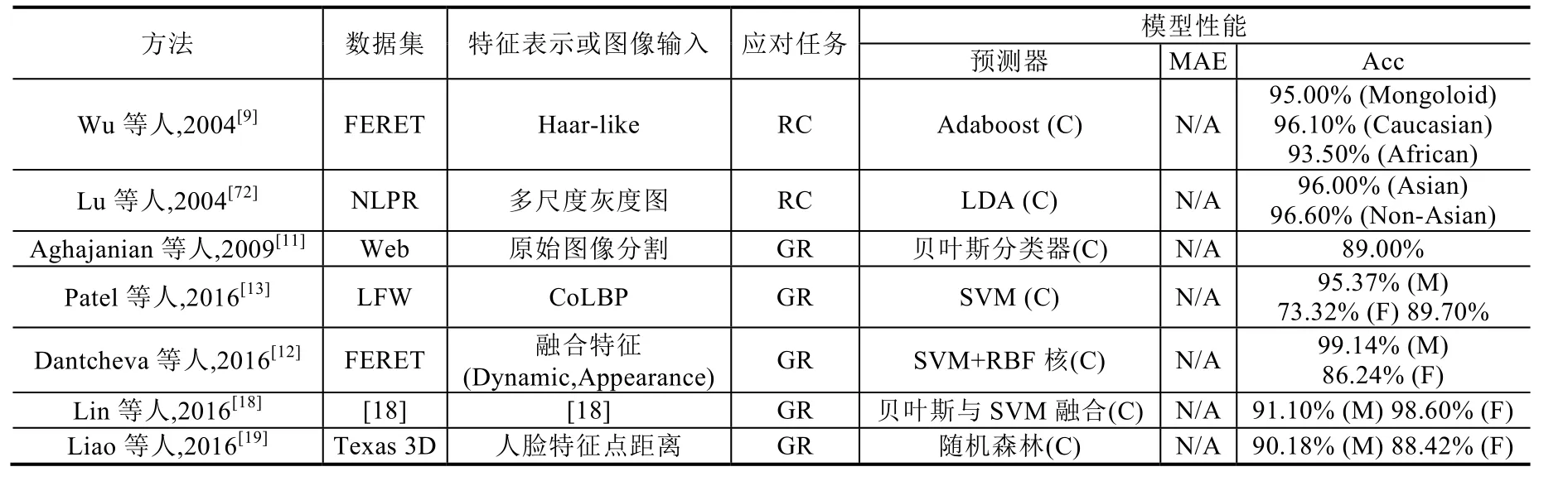
Table 1 Summary and comparison of naïve-group human facial attributes estimation techniques on different databases表1 在不同数据集上的人脸单一属性估计方法的对比与总结
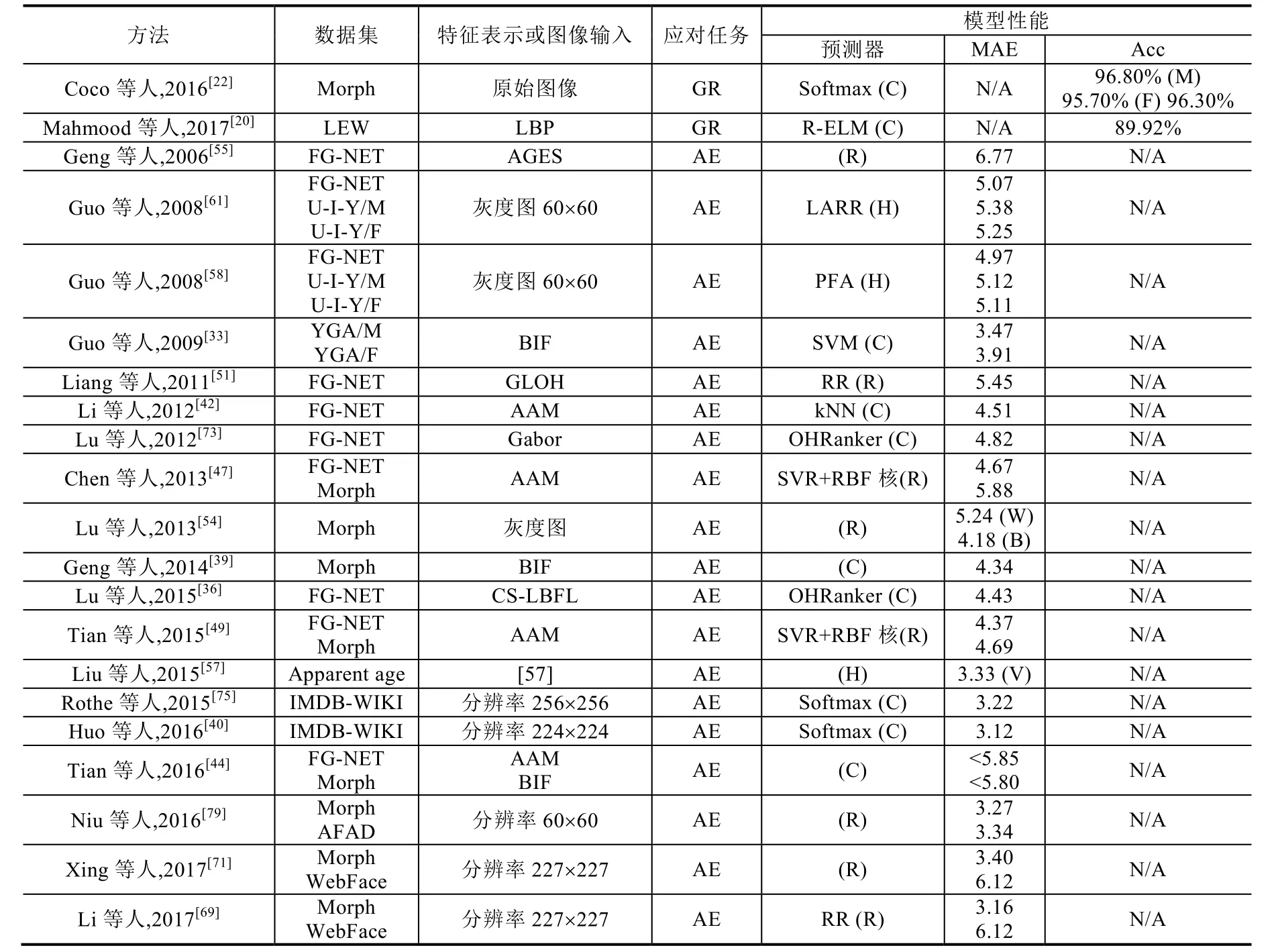
Table 1 Summary and comparison of naïve-group human facial attributes estimation techniques on different databases (Continued)表1 在不同数据集上的人脸单一属性估计方法的对比与总结(续)
2 自然的人脸面部属性识别
上述朴素的人脸年龄、性别和人种等面部属性识别方法未考虑人脸年龄、性别和人种等不同属性间的潜在关联和影响,而是将它们视作独立的问题分别加以考虑.相关研究[26,63-65]表明,不同面部属性之间存在关联性影响,并且某一属性估计受到其他属性的影响.为了与上述朴素的人脸年龄、性别和人种等面部属性识别相区别,我们称此类考虑属性间关系的识别方法为自然的人脸年龄、性别和人种等面部属性识别.
2.1 考虑性别、人种属性对AE的影响
为探究性别属性是否对AE产生影响,文献[31]分别在按性别拆分的样本集与在相同样本集混合情况(即性别当成未知)下,借助SVM进行AE.通过比较实验结果可知,性别属性显著地影响AE的准确率.文献[26]采用相同的方式在Morph II数据集上(划分见表2)研究性别、人种属性对AE是否存在关系.
鉴于同一年龄层内,男性和女性的人脸在年龄特征上的差异较大,文献[1]首先基于提取的人脸 Gabor特征进行GR,然后依据性别分类结果再借助SVM进行AE以提高AE的性能,具体流程图如图14所示.

Table 2 Distribution on Morph Ablum II database[26]表2 Morph II数据集使用情况[26]
与文献[55]相异,为构建人脸老化空间,同时考虑到性别间的差异与不同年龄段人脸相似性差异不同,文献[62]划分年龄段,并将同一人的训练样本填充至相邻年龄段中构建老化空间.鉴于当前数据集的固有缺陷,同一个人的训练样本不可能完全填充至每一个年龄段中,文献[62]在保证至少一组相邻年龄含有同一人样本的情况下,借助耦合字典学习构建空间,其学习目标函数如下:
其中,Xg表示第g个年龄段中所有人的样本图像,Yg表示在g+1个年龄段中对应人的样本图像,Dg(:,d)表示第g个年龄段第d幅图像特征.在公式(13)中,第1项用于度量第g个年龄段的损失,第3项用于度量第g+1个年龄段的损失,第2项用于保持人脸的个性细节,第4项为稀疏项;通过第1项与第3项的级联,可以利用人脸对之间存在的关系促进人脸老化关系的学习.然而,文献[62]为获取结果需要依赖中间层输出,中间层结果存在误差,必然导致实验效果降低.为此,文献[80]将老化字典学习模型层次化,以获得更优的结果.
考虑到性别、人种属性对AE的影响,文献[81]借助LDA的思想将来自不同性别和人种的同一年龄类的年龄模式相融合进行研究.其主要思想为:同年龄类内散度小,同人种不同类间尽量分离,同类不同人种之间尽可能接近(如图15所示).经过映射后,来自不同群体的老化模式被投射到共同空间中,在该空间中不同群体的老化模式可以产生相似或更接近的分布.
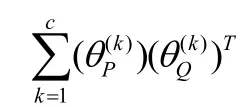
2.2 考虑年龄属性分别对RC、GR的影响
为探究年龄等属性对RC的影响,文献[65]在Morph II图像集上首先进行年龄和性别属性的人群划分(同文献[26]),然后针对每类人群进行RC,并发现RC准确率在不同人群间存在较大差异.
为探究年龄等属性对 GR的影响,文献[83]对 YGA等人脸集进行“老”“中”“青”这 3类人群年龄组的分类,然后针对每个分组进行 GR;文献[84]首先将人脸集划分为“未成年”和“成年”两类,然后针对每个子类进行 GR,并发现后者的GR准确率高于前者.
2.3 考虑性别属性和人种属性对GR和RC的相互影响
针对人脸面部属性关系的建模利用问题,同时考虑性别属性与人种属性相互关系的有关研究十分稀少.为了将性别和人种两种属性间内在关系融入到GR和RC中,文献[85]借助SVM分别对不同模态的3D图像进行预测,最后进行决策融合以实现性别与人种的联合估计.尽管文献[86]借助架构较浅的神经网络模型进行性别与人种的联合估计,却获得了较好的识别性能,其具体网络结构如图16所示.整体网络除输入输出层外,仅包含4层卷积层,前 3层卷积层之间由 2×2大小的最大池化层连接进行特征选择,而第 3层卷积层的输出采用 ReLU函数激活送往第4层卷积层,最后借助Softmax函数实现联合分类估计.
2.4 考虑年龄属性和性别属性对AE和GR的相互影响
为了将年龄属性和性别属性两者内在关系融入到AE和GR中,文献[87-89]借助深度卷积网络(CNN)获取性别和年龄相关的语义特征表示,再基于年龄和性别联合输出编码实现AE和GR.
在传统方法中,文献[70,90]认为:(1) 文献[1]提出的性别识别与年龄估计的级联模型不能避免性别分类器对整个模型带来的误差累计效应(即初始性别分类错误,造成年龄估计误差增大);(2) 文献[63]虽然联合了人脸多种属性,但其标签连接不仅可能混淆性别和年龄之间的语义关系,还忽略了男性和女性之间的老化差异.为此,文献[76]提出一种语义空间中近邻正交的方案,对性别与年龄属性内在关系联合建模,同时研究 AE和 GR,其基本模型如下:
其中,第1项表示性别分类损失项,第3项表示有序回归方法下的年龄估计损失项,第2项、第4项用于控制模型复杂度,第5项定义为RNOSSpaces=(waTwg)2,期望在语义空间中,不同性别间样本尽可能地分离.
2.5 同时考虑年龄、性别和人种三者属性之间的内在关联
偏最小二乘(partial least square,简称PLS,见公式(16))与典型相关分析(CCA,见公式(17))可以在输入样本集X与输出集Y之间建模,获取两者最大相关的子成分,其中,wx与wy表示投影向量.因此,文献[63,64,91]借助PLS与 CCA及其变种,将年龄、性别、人种整合为三元集标签,采用回归策略在样本空间与联合属性间建立关系,实现AE、GR和RC的联合估计.
为了同时利用三者属性信息,文献[71,92]借助深度模型 CNN实现对年龄、性别和人种这三者属性的同时估计.文献[71]认为,AE、GR、RC这3种属性估计任务难度并不相同,因此,各任务所需特征表示的精细程度相异.该文通过共享底层以实现三者属性之间的公共特征表示,然后为各属性分别构建网络以满足不同的特征表示需求.网络基本结构如图17所示,损失函数定义为
其中,La、Lg与Lr分别表示年龄估计损失、性别分类估计损失、人种分类估计损失,α与β为非负超参数,用于平衡3种任务间的重要程度.然而,对于AE,此框架仅利用了性别与人种信息,没有兼顾到任务之间的内在关系.尽管此后,文献[71]提出一种混合模型以利用任务之间的内在关联,并在Morph II数据集上获得MAE结果首次低于3的优异成绩,但其本质与文献[1]提出的级联模型相同,仍然存在分类器分类错误带来的累计误差等问题,还有提升空间.
2.6 性能对比
本节通过列表对比形式对有代表性的人脸多属性联合估计工作给出总结性性能对比.具体可见表3.
3 分析与展望
目前为止,学者们提出了多种方法利用单一的人脸属性和不同程度地联合多属性进行研究,以提高AE、RC和GR的准确率或者精度.文献[1,26,63-65]的研究表明,男性和女性在面部年龄老化方面存在差异,即性别因素对年龄估计存在影响;白种人、黄种人和黑种人等不同人种的年龄老化规律和性别外观差异也不尽一致.同时,不同年龄阶段的男性和女性的面部性别外观差异也不尽相同.能否有效地利用多属性内在关系将成为影响实际应用的主要因素.
然而,现有方法模型训练通常基于单一的相关数据集(如FG-NET、Morph Album、Adience、CACD 2000等),这些数据集通常存在以下两个严重问题:(1) 单一数据集在某些属性上的标记分布不完备.如表 4所示,Morph数据集上样本的年龄标记主要集中分布在16岁~70岁范围;而FG-NET数据集上样本的年龄标记主要分布在0~70岁.(2) 单一数据集在某些属性上的标记缺失.如表4所示,Morph数据集上的每张人脸图像同时标记了年龄、性别和人种这3种属性信息;而 FG-NET集合中的人脸图像仅提供了年龄属性等标记信息.人脸不同属性在现有单个脸库的标记不完备,使得对其联合估计变得困难.同时,单个数据库样本的缺失导致单独基于该数据集获得的属性估计器泛化能力存在严重缺陷.

Table 4 Label distributions between Morph Album II and FG-NET表4 相关属性在不同人脸数据集上的标记信息对比(以Morph和FG-NET为例)
本文中所指自然的人脸属性估计仅是相对朴素的方法而言,第 2节所回顾的相关工作仅是一定程度上考虑并利用了属性之间的关系,然而利用得并不完善.除文献[63,64,71,91,92]等所做的工作之外,本文上述总结回顾的绝大部分人脸年龄、性别和种族等面部属性识别相关工作都未同时实现以上多属性的联合估计.然而,即便是文献[63,64,71,91,92]等给出的联合估计模型,也未能很好地利用年龄、性别和种族等面部属性关系.例如,文献[63]、文献[70]指出其标签连接的方法不仅可能混淆性别和年龄之间的语义关系,而且忽略了男性和女性的老化差异;而文献[70]也仅利用了性别与年龄之间的内在关系,并未考虑人种属性的影响.
在零星的跨语义库研究中,尽管文献[44]实现了跨库训练的年龄单种属性估计,同时通过实验表明跨语义库进行 AE的效果优于单一数据集,但其并未考虑面部性别和种族等其他属性对年龄估计的影响.此外,该方法亦未实现人脸多个属性的联合估计.
基于以上考虑,人脸面部属性未来的研究方向应基于多属性跨库标记搜集训练数据集,并构建人脸年龄、性别和种族等多属性联合估计模型,探索并建模利用属性间内在关联,以实现更可靠的属性联合估计算法.
4 总 结
就基于人脸图像的性别、年龄、人种等面部属性估计,本文首先系统地回顾了朴素的(不考虑属性之间的相关关联和影响)和自然的(利用了属性之间的相关性)人脸属性相关研究工作.通过对现有工作的回顾和总结,发现现有工作的以下问题和不足:单一训练库属性标记不完备致使估计器泛化性有缺陷;未对年龄、性别和人种等面部多属性进行完全估计;未很好地利用年龄、性别和人种等面部属性间关系.为应对以上问题以获得更好的面部属性估计结果,本文认为进一步工作可基于多属性跨库标记以扩充现有人脸属性数据集,并构建人脸年龄、性别和人种等多属性联合估计模型,探索并建模利用属性之间和属性内在的关联,以实现更可靠的属性联合估计算法.
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
孩子·小学版(2020年7期)2020-02-24
当代陕西(2019年19期)2019-11-23
少年文艺·开心阅读作文(2018年10期)2018-10-16
小学生作文选刊·低年级版(2017年2期)2017-03-06
小学生导刊(低年级)(2016年8期)2016-09-24
奇闻怪事(2014年5期)2014-05-13
