
基于对抗式神经网络的多维度情绪回归*
2019-08-13 05:06朱苏阳李寿山周国栋
软件学报 2019年7期
朱苏阳, 李寿山, 周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215008)
情绪分析(emotion analysis)作为一种细粒度的情感分析(sentiment analysis)任务,旨在判别自然语言文本中所蕴含的情绪,是自然语言处理领域中的研究热点[1-3].一条文本中通常包含两类情绪:作者情绪(作者以什么样的情绪写下这条文本)和读者情绪(读者看到这条文本会产生什么样的情绪).而情绪分析可进一步分为以下两个任务.
1) 情绪分类(emotion classification).通过分类模型判别输入文本所属的情绪类别(emotion category).例如,例句1(取自Yao等人[2]的作者情绪分类语料库)表达了一种开心(happiness)的作者情绪.
2) 情绪回归(emotion regression).通过回归模型对输入文本的情绪维度(emotion dimension)进行打分.其中,情绪维度一般是多维的,包括极性(valence,简称V)、强度(arousal,简称A)以及可控性(dominance,简称D).例如,例句 2(取自 Buechel等人[4]的多维度情绪回归语料库 EMOBANK)的 3个作者情绪维度分数(V,A,D)=(2.4,3.6,2.8).
例句1:时间真的过的好快,我从一个未成年到奔三了,感谢一路上很多人,感谢我认识你们大家,谢谢你们.
例句 2:You see, Nathan, there is …separate from your society …oh damn it.(你懂的,内森,有这样的人…与你的社会所隔绝…哦,该死的.)
情绪分类的研究工作开始得较早,有许多相关工作,包括传统的基于统计模型的方法和最新的基于神经网络模型的方法.例如,Yang等人[5]利用情感词典作为外部语言资源训练SVM分类器来判别博客文本所属的情绪类别.Tripathi等人[6]利用深度卷积神经网络判别文本的情绪类别.然而,由于缺乏公认的情绪分类体系(emotion taxonomy),不同的情绪分类语料库大多会采用不同的情绪分类体系,其分类体系中包含的情绪类别也不尽相同.例如,例句1所在语料库使用的是基于Ekman[7]的6类情绪分类体系之上设计的7类情绪分类体系,而例句1若在Huang等人[8]所使用的情绪体系下则会被标注为正面复合(positive complex)的作者情绪.因此,基于单一语料库的情绪分类任务所训练的分类模型很难简单复用到使用其他情绪分类体系的语料库上[9].
与情绪分类相比,情绪回归任务受限于回归任务的难度和情绪回归语料库的缺乏,相关研究起步较晚.情绪回归语料库相比于情绪分类语料库的一大优势在于,其多使用公认的在心理学上用于描述情绪的极性-强度模型(valence-arousal model)[10]对语料进行情绪维度分数的标注.Buechel等人[4]在极性-强度模型的基础上将其拓展为极性-强度-可控性模型(valence-arousal-dominance model),并基于这一模型构建了一个包含超过10 000条样本的多维度情绪回归语料库EMOBANK.本文致力于在该语料库上进行多维度的情绪回归研究.
近年来,基于神经网络的方法在许多自然语言处理任务中都取得了较好的成果.例如,句法分析[11,12]、情感分析[13,14]、信息抽取[15,16]、机器翻译[17,18]等.在神经网络的相关研究中,生成式对抗网络(generative adversarial network,简称 GAN)通过对抗式学习(adversarial learning)来训练能够生成接近真实样本的生成器[19].基于对抗式学习的学习框架在图像处理领域中已经取得了很好的成果[20,21],在自然语言处理领域也被初步应用到文本生成任务中去[22,23],这是一种很有潜力的学习框架.并且,该学习框架可被应用到全监督、半监督以及无监督的机器学习任务中.
目前,将对抗式学习框架应用于分类任务的相关研究还较少[24,25],而应用于回归任务的研究则更为罕见.本文提出一种基于对抗式神经网络的多维度情绪回归方法.本文提出的方法包括对抗式神经网络(adversarial neural network)模型和对抗学习算法.对抗式神经网络包含特征抽取器、回归器、判别器这3个部分,通过联合训练多个特征抽取器和回归器,以对输入文本的不同情绪维度进行打分.而对抗学习算法借由判别器在不同的特征抽取器之间进行对抗式训练,从而获得能够抽取出泛化性更强的针对不同情绪维度的特征抽取器,以提高情绪回归的性能.在EMOBANK多维度情绪回归语料上的实验结果表明,本文的方法优于其他基准系统和领域内先进系统,在EMOBANK新闻领域和小说领域的情绪回归上均取得了较好的性能.
本文第1节介绍情绪分析和对抗式神经网络模型的相关工作.第2节详细描述本文提出的对抗式神经网络模型以及对抗学习算法.第 3节介绍 EMOBANK语料库以及实验设置,并对实验结果进行详细分析.最后,第 4节给出本文的结论并展望未来工作.
1 相关工作
本节首先介绍情绪分类与情绪回归的相关研究,然后给出对抗式神经网络模型的相关研究工作.
1.1 情绪分类研究
情绪分类研究的主流为基于语料库的方法.随着互联网的发展,许多研究者通过各类在线社交平台用户发布的文本构建情绪语料库.Mishne等人[1]从在线博客平台LiveJournal的815 494篇博客文章中构建情绪分类语料库.Pak等人[26]从Twitter用户发布的推文(tweets)中构建情绪分类语料库.Yao等人[2]和Huang等人[8]分别从新浪微博与腾讯微博中构建中文情绪分类语料库.除情绪分类语料库的建设之外,情绪词典(emotion lexicon)的构建也是重要的语料库构建工作.Xu等人[27]利用同义词词典、语义词典等语言资源,通过基于图规则的方法构建包含 5类情绪的情绪词典.Yang等人[28]提出了一种情绪意识隐狄利克雷分布模型(emotion-aware LDA model)来构建特定领域的情绪词典.
根据输入文本的粒度,情绪分类任务可以分为文档级(document-level)情绪分类和句子级(sentence-level)情绪分类.基于传统方法的文档级情绪分类包括以下代表性工作:Mishne等人[1]利用LiveJournal的博客文章训练SVM分类器来对博客文档情绪进行分类.Yang等人[5]借助情感词典等外部语言资源训练SVM分类器与CRF序列标注器在博客文章上进行情绪分类任务.Lin等人[29]在雅虎新闻(Yahoo! News)上进行读者情绪分类的研究.新闻的读者情绪由新闻末尾的读者情绪投票结果确定.基于传统方法的句子级情绪分类主要依靠情绪词典确定句子包含的情绪,包括以下的代表性工作:Amam等人[30]提出了一种基于知识库的句子级情绪识别方法.Mohammad等人[31]对情绪词对句子情绪的影响进行了研究.他们使用了基于 Word Net与NRC-10语料的情绪词典辅助训练最大熵分类器与SVM分类器,用以识别句子的情绪.Das等人[32]在Bengali博客上识别句子级的情绪.他们首先识别句子中所包含的情绪词,之后利用情绪词典确定这些情绪词所属的情绪类别,最后综合确定句子的情绪.
近年来,基于神经网络的方法也被应用到情绪分类的任务中去.Bertero等人[33]提出一种基于卷积神经网络(convolutional neural network,简称CNN)的模型来对交互对话系统中的实时对话情绪进行分类.文献[33]给出的实验结果表明,使用单层卷积神经网络配合最大池化(max-pooling)的特征抽取方法便能够取得较好的分类准确率.Felbo等人[34]提出了一种基于双向长短期记忆网络(bi-directional long short term memory,简称Bi-LSTM)的方法在8个基准数据集上进行情绪分类任务研究.除了双向长短期记忆网络之外,Felbo等人还利用推特中的情绪表情符号辅助训练模型,使之能够从文本中抽取出包含更丰富的情绪信息的特征,并在所有基准数据集上都取得了先进的性能.Abdul-Mageed等人[3]提出了一种基于循环神经网络(recurrent neural network,简称RNN)的情绪分类模型EmoNet.该方法结合了循环神经网络与远程监督(distant supervision)方法对未标注数据进行自动标注,并在他们自己收集的包含24类情绪的语料上取得了87.58%的准确率.
上述情绪分类研究大多采用不同的情绪分类语料库,而这些语料库往往使用不同的情绪分类体系.因此使用这些方法训练的分类模型无法直接应用到其他语料库上,而是需要在新的语料上重新训练模型.此外,由于情绪分类任务本质上是将文本特征通过模型映射到离散的标签空间中去,因此,若所使用的情绪标签种类较少,则无法进一步进行更加细粒度的情绪分析.大量增加情绪标签会大幅度提高每一类数据的稀疏性,而克服这一稀疏性需要耗费大量的人力标注成本.
1.2 情绪回归研究
与情绪分类任务相比,受限于回归任务本身的难度和情绪回归语料库的缺乏,情绪回归任务研究的起步较晚.Yu等人[35]实现了一种基于带权图(weighted graph)的词语级情绪回归模型.该方法通过带权图来建模多个情绪词节点之间的关系与相似度,从而给情感词的极性-强度分数进行打分.该方法在中文和英文的情感词典上的词语级情绪回归任务中的性能均优于线性回归(linear regression)、核方法(kernel method)以及 Pagerank算法.Wang等人[36]提出了一种局部卷积神经网络-长短期记忆网络(regional CNN-LSTM)的文档级情绪回归模型.该方法将一段文本划分为多个局部,并通过卷积神经网络抽取每个局部的特征.抽取得到的特征经过融合后,经由一个长短期记忆网络来预测整个文本的极性-强度分数.在多个语料上的实验结果表明,该方法优于传统的基于词典的方法以及基于单层卷积神经网络和单层长短期记忆网络的方法.Buechel等人[37]在SemEval 07语料上探讨了将极性-强度-可控性分数映射为SemEval 07语料所使用的Ekman这6类情绪类别标签的可行性.他们首先人工地为SemEval 07语料标注了极性-强度-可控性分数,之后通过k近邻算法构建情绪分数和情绪标签之间的映射,并取得了较好的准确率.
在相关语料库的构建方面,现有的情绪回归语料库数量极少,并且语料库规模大多较小.Preoţiuc-Pietro等人[38]收集Facebook用户发布的信息,构建了规模为2 895条文本的英文情绪回归语料库.Yu等人[39]发布了一个规模为2 009条句子的中文情绪回归语料库.该语料库的文本数据源自多个在线平台.由Buechel等人[4]标注的EMOBANK语料库是目前罕有的包含样本数超过10 000的大规模多领域情绪回归语料库.
与情绪分类相比,情绪回归所使用的语料库在标注上都采用心理学上公认的极性-强度模型或极性-强度-可控性模型.因此,这些方法训练的模型具有较好的普适性.此外,由于情绪回归任务本质上是将文本特征通过模型映射到连续的情绪分数空间中去,因此适合进行更细粒度的情绪分析任务.
1.3 对抗式神经网络研究
基于神经网络的对抗式学习方法是目前深度学习的热点之一.这类方法最早源自 Goodfellow等人[19]提出的GAN模型.GAN模型由两部分组成:生成器G和判别器D,并使用对抗式学习算法来训练这两部分.G的输入通常为一组满足正态分布的随机噪音,输出为一张图片;D的输入为一张图片,输出为判别该图片为原始数据集中的真实样本还是由G生成的伪样本.对抗式学习发生在G与D之间:G需要生成尽可能能够欺骗D的图片,而D需要尽可能判别出G所生成的样本为伪样本.GAN的目标在于通过对抗式学习使得G能够生成尽可能接近真实样本分布的伪样本.当两个网络之间达到纳什均衡时模型收敛.GAN的优点在于G的输入可以任意采样,并且整个模型在实现上可以使用任何可微模型,但同时也存在众多缺陷.在 GAN的基础上,研究者们尝试解决该方法的不足,许多衍生模型被提了出来,并在图像处理领域取得了较好的效果.Mirza等人[20]提出了条件式GAN(conditional GAN,简称CGAN)来解决GAN生成样本不具可控性的缺陷.CGAN在G和D的输入上分别增加了一个条件信号作为辅助输入以实现对生成数据的控制.CGAN在MNIST手写数字图像数据集上用0~9的数字符号作为辅助的条件输入,通过实验表明这一改进能够生成指定的质量较好的手写数字图像.Radford等人[21]探索了G与D的具体实现,通过穷举法发现,分别用4层卷积神经网络实现的G与D能够获得较好的生成效果,并在 MNIST和亚洲人脸数据集(Asian face dataset)上通过实验证明了这一点.Arjovsky等人[40]提出的Wasserstein GAN(WGAN)则进一步解决了 GAN训练不稳定、缺少一个具体的数值来指示训练进程的缺陷.WGAN最主要的改进在于使用真实样本分布于生成样本分布之间的Wasserstein距离来取代原始GAN中使用的两个分布之间的简森-香农散度作为判别器D的损失函数,从而避免了当两个分布之间没有重叠或重叠很小时,D的损失函数值无法度量两个分布之间的真实距离.在具体实现中,两个分布之间的Wasserstein距离通过一个全连接层的神经网络来近似拟合而得到.
除了图像生成之外,近年来,基于神经网络的对抗式学习算法也被应用到其他任务中去.在自然语言处理领域,该方法在文本生成的任务上取得了一定的研究进展.Zhang等人[22]、Zhao等人[23]均使用卷积神经网络、长短期记忆网络等模型构建GAN进行文本生成实验,并能够生成比较接近自然语言的文本语句.除了文本生成任务外,该方法还被应用到分类任务上.Wu等人[24]分别使用卷积神经网络与循环神经网络构造两种 GAN模型,在纽约时报语料与华盛顿大学语料两个数据集上进行关系抽取实验,并探讨了这两种实现的优劣.Liu等人[25]利用对抗式学习框架构建了两个基于长短期记忆网络的分类模型进行多任务文本分类.对抗式学习发生在两个分类网络之间.在Liu等人收集的16个不同的文本分类数据集上的实验证明了这一方法在分类准确率上超过了其他单任务的深度神经网络模型.近两年来,有研究者利用对抗式学习算法的特点,将其用于跨领域的文本分类任务之中.Li等人[41]与Peng等人[42]先后提出基于对抗式学习算法的神经网络模型,利用判别器对输入文本所属领域进行判别,以此从来自源领域的输入文本中学习更接近目标领域的特征,用于训练针对目标领域测试集的文本分类器.这两种方法均在Yelp多领域情感分类数据集上取得了优于传统跨领域学习的分类性能.
2 基于对抗式神经网络的多维度情绪回归方法
本节详细描述了我们所提出的基于对抗式神经网络的多维度情绪回归方法.首先,给出多维度情绪回归任务的定义.接着,介绍本文提出的对抗式神经网络模型的框架与每一部分的具体实现,包括特征抽取器、回归器以及判别器的具体实现.最后,介绍本文在训练模型时所使用的对抗式学习算法.
2.1 任务定义
本文在 EMOBANK多领域情绪回归语料上进行多维度情绪回归任务.首先,记整个语料库为X={x1,x2,…,xn},其中,n为语料库容量.对于语料库中第i个文本输入xi,本文的模型最终输出该文本的包含极性-强度-可控性情绪分数的三元组yi=(Vi,Ai,Di),其中,xi为由第i个文本中词语的词向量序列组成的词向量矩阵,Vi、Ai、Di分别对应文本xi包含的极性(valence)分数、强度(arousal)分数、可控性(dominance)分数.最后,记整个语料库X对应的输出为Y={y1,y2,…,yn}.
关于词向量的训练,本文在EMOBANK语料库上使用Skip-gram算法[43]预先训练词向量查找表E∈ℝd|V|,其中,d为词向量的维度,V为EMOBANK包含的单词的集合.对于第i个文本,文本中的每个单词通过查表的方式转换为词向量:
其中,ei为第i个词对应的词向量,wi为第i个词的单热点表示.此时可得到词向量矩阵xi=[e1,e2,…,ek]T,其中,k为每个文本的固定序列长度.对于长度小于k的文本,本文采用随机正态初始化的方法构建不足部分的词向量添加于序列首部;对于长度大于k的文本,本文从序列尾部开始截断超出的部分.k作为模型的超参,其具体设置将在实验部分另作介绍.
2.2 对抗式神经网络模型框架
本文实现了一种对抗式神经网络模型,用于实现 3个维度之间的两两对抗学习.以极性和强度两个维度间的对抗为例,模型的框架图如图1所示.
模型由 3部分组成:特征抽取器(ExtV、ExtA)、回归器(RV、RA)、判别器(D).特征抽取器用于抽取文本中针对不同维度的特征向量.抽取的特征向量被输入到相应的回归器中以对情绪维度进行打分.为了抽取具有维度特定性且泛化性更好的特征,两个维度的特征抽取器之间通过判别器进行对抗式学习.判别器用于判断抽取的特征属于何种维度.特征抽取器不仅通过常规的有监督训练来学习抽取具有维度特性的特征,还通过欺骗判别器来学习抽取泛化性更好的特征.
除图 1所示的极性-强度对抗模型之外,本文还实现了极性-可控性、强度-可控性的对抗模型.其中包括输出可控性特征FeatD的可控性回归器ExtD、输出可控性分数Di的可控性回归器RD.判别器D的输出Pi∈(-1,1)为输入的特征属于两个维度中某一个的判别分数.本文在此分别定义了3个对抗模型中判别器D输出的判别分数Pi如下.
1) 在极性-强度对抗模型中,若Pi越接近1,则代表输入特征越可能是极性特征;反之,若Pi越接近-1,则代表输入特征越可能是强度特征.
2) 在极性-可控性对抗模型中,若Pi越接近1,则代表输入特征越可能是极性特征;反之,若Pi越接近-1,则代表输入特征越可能是可控性特征.
3) 在强度-可控性对抗模型中,若Pi越接近1,则代表输入特征越可能是强度特征;反之,若Pi越接近-1,则代表输入特征越可能是可控性特征.
为方便起见,在本节剩下的内容中,若不作特殊说明,则均以极性-强度模型为例来解释模型的详细实现.
2.3 基于长短期记忆网络的特征抽取器
自然语言处理领域中的许多研究表明,长短期记忆网络(long short term memory,简称LSTM)能够从文本中抽取富含信息量的特征[3,35,37].Hochreiter等人[44]提出的LSTM是循环神经网络的一个变种模型.由于传统的循环神经网络在反向传播梯度时存在梯度消失(gradient vanishment),因此,当输入序列较长时,传统循环神经网络会丢失一部分靠前的序列中的信息.LSTM在循环神经网络的基础上引入LSTM单元(LSTM cell)来解决梯度消失的问题.LSTM单元由4部分组成:输入门(input gate)i、输出门(output gate)o、遗忘门(forget gate)f以及记忆单元(memory cell)c.给定词向量矩阵xi=[e1,e2,…,ek]T,在t时刻LSTM单元的计算如下:
其中,et为t时刻LSTM单元的输入,亦即输入矩阵x中第t个行向量,ht为t时刻LSTM单元的输出,σ表示sigmoid激活函数,⊙表示点乘运算符,W、U、V均表示 LSTM 单元的参数矩阵.输入门控制每个记忆单元的更新信息.输出门控制每个记忆单元的输出信息.遗忘门控制每个记忆单元在时间t时刻丢弃的信息.c˜t表示t时刻记忆单元的候选值.ct根据t-1时刻的记忆单元状态ct-1和t时刻的候选值c˜t计算得到.
作为模型的原始输入,词向量矩阵xi输入LSTM之后,计算得到输出序列H=[h1,h2,…,hk]T.由于最后一个时刻k的计算实际上取决于时刻1~k-1的输出,因此,在过去的研究中大多选用hk作为LSTM所抽取的序列中的特征向量.为了从文本中获取更加丰富的信息,本文另对输出序列H进行平均池化(average pooling)操作.
平均池化后得到的输出向量与hk进行拼接操作后通过tanh激活函数得到特征抽取器最终输出的特征向量Feat为
图2给出了特征抽取器的神经网络结构.在极性-强度模型中,特征抽取器抽取词向量矩阵xi中的极性特征与强度特征的计算流程定义如下:
2.4 回归器
回归器接收特征抽取器所抽取的输入文本特征作为输入,用于对输入文本某个情绪维度的分数进行打分.本文所提出的对抗式模型并不限制回归器部分的具体实现,因此,只要模型每个部分的梯度能够在网络中传递,回归器既可以是基于传统方法的回归器,也可以是任何可微神经网络模型构成的回归器.本文为了突出对抗式学习在训练特征抽取器上的优越性,仅使用简单的单层全连接神经网络层作为回归器的实际实现方式.
其中,W表示全连接层的参数,b为偏置项,h为全连接层的隐层状态,relu表示Relu激活函数.最终输出为某个情绪维度的分数S.在极性-强度模型中,回归器的计算流程定义如下:
2.5 判别器
判别器接收特征抽取器输出的文本中的特征作为输入,以判别抽取的特征是属于哪个情绪维度的特征.判别器在对抗式学习算法中起着重要的作用,模型不同部分之间的对抗均通过判别器来进行.在判别器的实现上,本文参照了Arjovsky等人[40]在WGAN上的工作,使用两个特征分布之间的Wasserstein距离来指示判别器的训练程度.相比于原始GAN中使用JS散度作为判别器的损失函数,Wasserstein距离在两个分布没有重叠或重叠很小的时候也能够度量两个分布之间的距离,从而为判别器的训练提供更加平滑的量度来衡量模型的训练水平.在实际实现中,本文使用单层全连接层来近似拟合Wasserstein距离.
其中,W表示全连接层的参数,b为偏置项,h为全连接层的隐层状态,tanh表示双曲正切激活函数.最终输出为判别结果P.在极性-强度模型中,判别器的计算流程定义如下:
2.6 对抗式学习算法与模型训练
本文提出一种对抗式学习算法来训练对抗式神经网络.该算法首先通过最小化以下的回归损失函数来训练特征抽取器ExtV和ExtA、回归器RV和RA.在具体实现上,本文采用均方误差作为回归的损失函数.
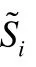
其中,FeatVi和FeatAi分别代表第i个样本的极性特征和强度特征.最后,对抗式学习算法通过最小化以下判别误差达到欺骗判别器的效果,从而再次训练特征抽取器ExtV和ExtA.
算法 1给出了详细的在一轮学习中使用对抗式学习训练整个网络的算法.模型在若干轮学习后收敛.其中,该算法在训练判别器时将判别器的参数的绝对值进行了裁剪.根据Arjovsky等人[40]在WGAN上的工作,进行判别器的参数裁剪是为了使判别器这一可微网络满足 Lipschitz连续性(Lipschitz continuity)条件,从而能够使用该网络的输出结果来近似拟合Wasserstein距离.t作为模型的可调超参,它的取值将在本文实验部分给出.
算法1.对抗式学习算法.
(1) 从训练集中顺序选取N条训练数据XN={x1,x2,…,xN}.
(2) 利用XN,根据训练样本所标注的两个维度的情绪分数分别训练特征抽取器ExtV和ExtA、回归器RV和RA.更新ExtV、ExtA、RV、RA的参数.
(3) 利用XN,训练判别器D.更新D的参数.ExtV、ExtA的参数保持不变.
(4) 将更新后D的参数的绝对值裁剪到一个不大于t的值.
(5) 利用XN,通过欺骗D再次训练ExtV和ExtA.更新ExtV和ExtA的参数.D的参数保持不变.
(6) 重复(1)~(5),直至整个训练集的样本被取完.
3 实 验
本节首先介绍所使用的情绪回归语料库 EMOBANK.之后给出实验的设置,包括衡量情绪回归性能的指标、模型中的超参设置.然后介绍实验中所使用的基准系统,以与本文提出的方法进行对比实验.本文使用的外部工具也在本节中相应部分给出.最后,给出详细的实验结果,包括具体的回归性能与结果分析.
3.1 EMOBANK语料库
本文使用 EMOBANK语料库[4]来验证我们所提出的基于对抗式神经网络的多维度情绪回归方法.该语料库的数据源自两个公开语料库:SemEval07:task 14(http://nlp.cs.swarthmore.edu/semeval/tasks/task14/data.shtml)与MASC(http://www.anc.org/data/masc/corpus/)语料库,人工标注了共6个领域的英文文本的10 325条读者情绪和10 279条作者情绪,由多个标注者分别对文本的3个情绪维度:极性、强度、可控性进行读者情绪和作者情绪打分,分数区间为[1.0,5.0].EMOBANK中的读者情绪和作者情绪的文本数量并不相同,这说明语料库在标注时有少量文本未作读者情绪或作者情绪的标注.表1给出了EMOBANK包含的文本数量在各领域上的分布.由于本文不涉及跨领域情绪回归的研究,而不同领域文本的相同情绪维度的特征分布存在一定的不同,因此本文仅在样本数最多的两个领域:新闻领域与小说领域上分别进行实验.
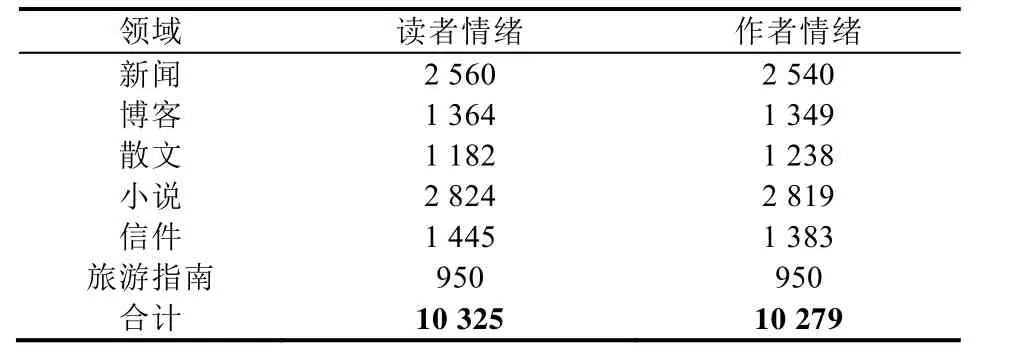
Table 1 Genre distribution of EMOBANK corpus表1 EMOBANK语料各领域文本数量的分布
表2给出了EMOBANK语料库的主要统计数据.从表中可以看出,无论是读者情绪还是作者情绪,3个情绪维度的标注分数平均值都在3.00上下.而情绪分数的标准差较低,样本的情绪分数大多落于区间[2.3,3.7]上.
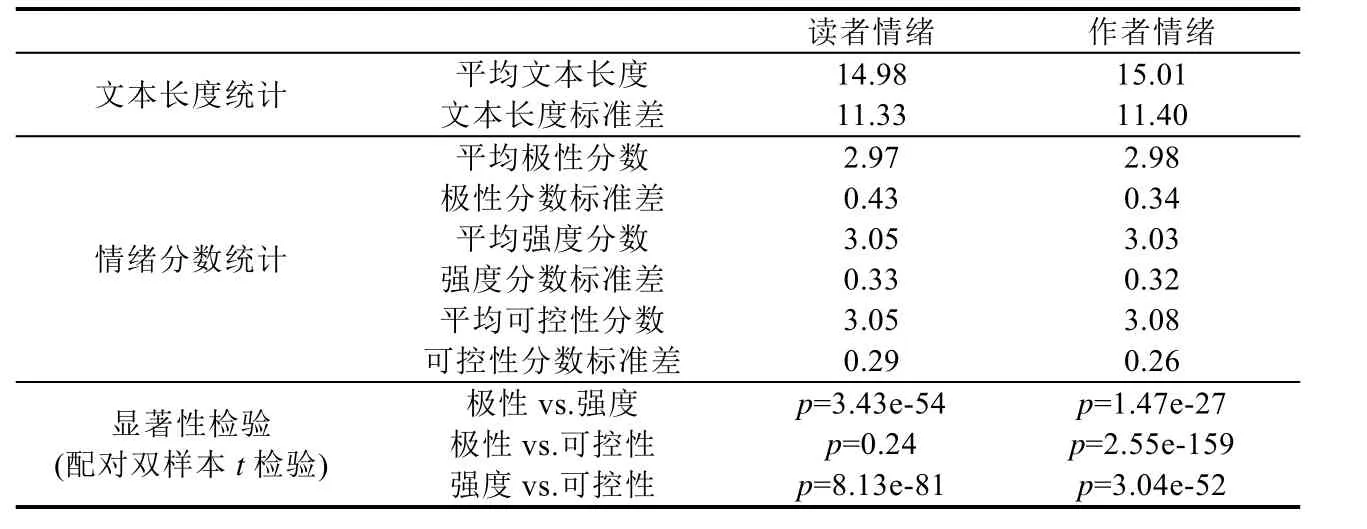
Table 2 Statistics of EMOBANK corpus表2 EMOBANK语料库的统计数据
EMOBANK中文本平均长度约为15个单词,而文本长度的标准差较大.由于本文提出的神经网络模型的输入需要保证每个词向量矩阵的行列相等,因此会预先将文本长度调整到等长.为了既不丢失绝大多数文本中的信息,也不在较短文本中加入过多的空白填充,本文在实验中将文本长度k统一设置为37(均值+两倍标准差).
除了文本长度与情绪分数的计量之外,本文还使用了配对双样本t检验来考察文本两两情绪维度分数之间是否存在显著差异.从表 2中可以看出,除了极性与可控性两个维度的读者情绪之外,剩余两两组合之间的差异性均相当明显.不同维度情绪分数间的明显差异说明了在EMOBANK上的多维度的情绪回归任务本身具有意义.
3.2 实验设置
本文在EMOBANK的新闻与小说领域上分别进行读者情绪与作者情绪回归的5倍交叉验证,并使用皮尔森相关系数(Pearson’s correlation coefficient,用r表示)与均方误差(mean square error,简称MSE)作为评估指标.
若系统在测试集上的r越高,MSE越低,则说明系统性能越好.本文在评估各方法性能时优先考虑皮尔森相关系数r,而MSE作为辅助参考指标.此外,本文使用配对双样本t检验来检验本文方法与基准系统性能之间的差异是否显著.实验中各超参的设置在表 3中给出.本文使用 gensim工具包(https://radimrehurek.com/gensim/)的word2vec训练词向量查找表,使用skipgram算法在新闻和小说领域的语料上分别进行无监督训练.

Table 3 Setting of hyper parameters during experimentation表3 实验中超参的设置
3.3 基准系统
为充分证明我们提出的方法在 EMOBANK上进行多维度情绪回归任务的优越性,本文进行了以下基准系统与所提方法的比较.
1) SVR(BOW):该基准系统使用了Smola等人[48]提出的基于支持向量机的回归器(support vector regerssor,简称 SVR).SVR被广泛地应用到自然语言处理的回归任务中,并被认为是该领域的先进回归系统之一[49].该系统使用文本的词袋模型(bag-of-words)作为输入特征.
2) SVR(TF-IDF):该系统与基准系统1)相同,使用SVR作为回归器.与1)的不同之处在于,该系统以文本中单词的TF-IDF度量作为输入特征.
3) SVR(W2V):该系统与基准系统1)相同,使用 SVR作为回归器.与1)的不同之处在于,该系统以文本中单词的词向量之和作为输入特征.该系统所使用的词向量查找表与本文提出的方法相同.
4) ANN:该系统由Bitvai等人[50]提出.其基本结构为使用多层并联的卷积神经网络抽取文本中的多个n元文法(n-gram)特征.该方法被应用于对电影评论的情感极性回归任务中,亦被认为是自然语言处理领域中的先进回归系统之一.本文所实现的该系统采用3层并联卷积神经网络,分别抽取文本中的一元文法(uni-gram)、二元文法(bi-gram)、三元文法(tri-gram)特征.抽取的 3种特征经过拼接后输入到一层全连接层来进行回归任务.该系统的输入特征与本文提出的方法相同,为文本的词向量矩阵.
5) LSTM:该系统为基于长短期记忆网络的回归器.与本文提出的方法相比,该系统仅使用图 2所描述的模型抽取文本特征,再以抽取的文本特征作为输入,使用第 2.4节所描述的回归器进行文本回归任务.该系统的输入特征与本文提出的方法相同,为文本的词向量矩阵.
6) C-LSTM:该系统由 Zhou等人[51]提出,为文本分类任务上的先进系统.本文通过修改模型最后一层的激活函数,将该方法应用到文本回归的任务中.该方法组合了卷积神经网络以及长短期记忆网络,首先利用卷积神经网络将句子转换为短语级特征,再将短语级特征输入到长短期记忆网络中进行分类任务.该系统的输入特征与本文提出的方法相同,为文本的词向量矩阵.
此外,本文提出的对抗式神经网络简称为AdvNN.
3.4 实验性能对比与分析
表4给出了AdvNN与其他基准系统在新闻领域上的情绪回归性能.由于本文实验采用5倍交叉验证,评估结果为每次验证结果的平均值.此外,表5进一步给出了3种情绪维度两两组合:极性-强度、极性-可控性以及强度-可控性3个模型的详细性能.以极性-强度模型为例,表中维度1表示前一维度——极性维度回归性能,维度2表示后一维度——强度维度回归性能.表4中AdvNN的每个维度的性能取自表5中各组合中皮尔森相关系数r最高的一项,例如读者情绪的极性维度在极性-可控性模型中的回归结果的r值较极性-强度模型中的r值更高,因此,表4中记录该最优r值以及相应的MSE值.
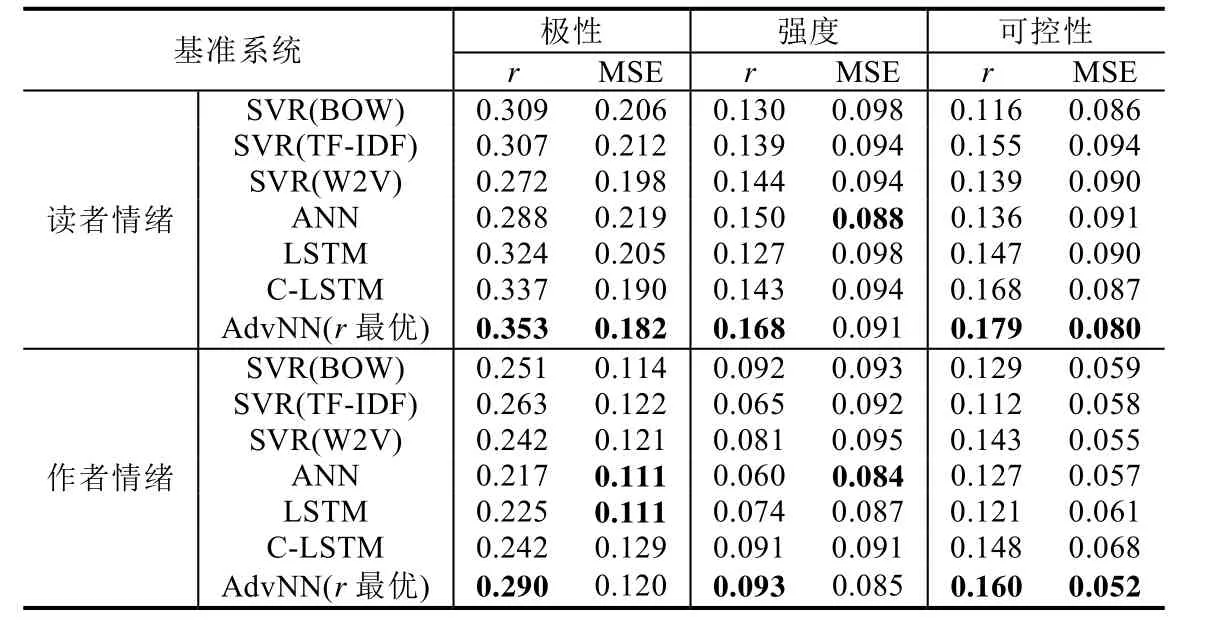
Table 4 The performances of various approach on the News domain表4 各种方法在新闻领域上的情绪回归性能
从表4可以看出:
1) 总体而言,在新闻领域上,所有方法取得的r值都较低.最高的r值为AdvNN在读者极性情绪上取得的0.353.作为参考,EMOBANK全领域上标注者两两间标注结果的平均r值约为0.6[4].由此可见,EMOBANK上的多维度情绪回归任务是一个较难的任务,不容易取得非常高的性能.注意到该领域上的作者强度情绪最高r值未超过0.1.造成这一结果的可能原因在于新闻领域文本的作者在撰写相关文本时倾向于不代入较强的情绪.例如,例句3的作者强度情绪为3.25,为中等强度,而读者强度情绪为4.00,为较高强度.例句3作为一条典型的报道负面消息的新闻文本,能够激发起读者较强的负面情绪.而作者在撰写这条文本时为了保证新闻的客观性,相比读者不会代入强烈的情绪(尽管例句3的作者情绪极性也为负面).同样,例句4作为一条报道正面消息的新闻文本,其读者强度情绪为较高的 3.80,而作者强度情绪为中等的 3.40.例句 5说明在读者强度情绪较弱情况(2.00)下,作者情绪依然趋于中等(2.80).可见,在新闻领域上,作者情绪倾向于为一个适中的强度.
2) 与传统方法(SVR)相比,一般的基于神经网络的回归模型表现并无明显优势.其中,ANN在所有基准系统中的总体性能最差,各情绪维度的平均r值为0.163,低于其他基准系统.相比之下,SVR方法的平均r值在0.171上下,优于ANN,相比LSTM取得的平均r值0.174亦无太大劣势.而C-LSTM取得了基准系统中最高的平均r值0.184,说明了文本分类任务中的先进系统在回归任务上亦能取得较好的效果.
3) 在新闻领域上,无论是读者情绪还是作者情绪,AdvNN的最高r值均超过了其他所有基准系统的r值.其中,在作者极性维度上的提升最多,较该维度上最强的基准系统 SVR(TF-IDF)提升了 0.027.AdvNN在作者强度维度回归上的提升最小,较该维度上最强的基准系统SVR(BOW)仅有0.001的提升.此外,AdvNN在新闻领域的平均r值达到0.207,亦超过了平均r值最高的基准系统C-LSTM.从这一结果来看,同样是在LSTM的基础上实现的神经网络模型,使用了对抗式学习的AdvNN相比融合了卷积神经网络的C-LSTM在本文的任务上能够进一步学习文本中的情绪维度特征,从而提高系统性能.
4) 除r值之外,AdvNN在 MSE评估指标下的表现也较为优秀.除读者强度、作者极性和作者强度之外,AdvNN均取得了最低的MSE值.尽管在作者强度维度上的r值提升较低,AdvNN与SVR(BOW)相比MSE下降了0.008,但总体而言,在该维度上的性能却存在一定的提升.AdvNN取得了平均0.102的MSE值,亦低于所有基准系统的平均MSE值.
例句3:Scam lures victims with free puppy offer.(骗局使用提供免费的小狗的方式来引诱受害者.)
例句4:Kidnapped AP photographer freed in Gaza.(被绑架的美联社摄影师在加扎被释放.)
例句5:I feel bad for Jorge he's a good friend of mine, Bengie said.(本吉说到:我为霍赫感到难过,他是我的好朋友.)

Table 5 Detailed performances of AdvNNs for three combinations of emotion dimensions on the News domain表5 新闻领域上3种情绪维度组合的对抗式神经网络详细性能
进一步分析表5,可以发现:
1) 除了强度-可控性模型中作者强度情绪的r值低于两个基准系统之外,各维度组合整体结果相比基准系统均有一定的提升.其中,AdvNN在读者强度情绪和作者极性情绪上的非最优r值亦超过最强基准系统至少0.019.
2) 除作者强度情绪外,其余情绪维度在不同组合下的平均r值亦超过相应维度的最强基准系统结果.尽管在大多数情绪维度上AdvNN的所有维度组合性能超过了最强基准系统,然而由于某些维度组合的r值提升幅度较小,如极性-强度模型的读者情绪相比该维度最强基准系统 C-LSTM 仅有 0.002的r值提升.因此,尽管AdvNN在新闻领域上的各组合的最优性能均超过了最强基准系统,但在个别情况下的提升并不稳定.
3) AdvNN在作者强度情绪这一维度上的较低性能也进一步证明,由于新闻文本自身的特性,新闻作者在撰写相关文本时为了维持新闻的相对客观性,并不会产生明显的情绪强度上的波动,因而难以在该维度上取得较好的回归结果.
表6给出了AdvNN与其他基准系统在小说领域上的情绪回归性能,具体结果亦为5倍交叉实验的平均值.表7进一步给出了3种情绪维度两两组合的详细性能.从表6中可以看出:
1) 与新闻领域相比,在小说领域上,所有方法取得的r值亦较低.而与新闻领域不同的是,小说领域的结果之中无很低(小于 0.1)的r值.造成这一结果的原因可能在于小说作者在撰写文本时会代入一定程度的个人情绪.例如,例句6标注了负面的读者情绪和作者情绪,而读者强度情绪和作者强度情绪分别为4.20与4.20,均为较强的情绪.而例句7的读者强度情绪和作者强度情绪分别为2.67与2.20,均为较弱的情绪.由此可见,小说领域上的作者情绪与新闻领域上的不同,是和读者情绪一样会产生较为明显的强度波动.因此,实验中所有系统相对来说在小说领域强度维度上的r值均高出新闻领域很多.此外,整体来看,所有系统取得的r值与新闻领域上一样并不高,亦证明了EMOBANK语料上的多维度情绪回归任务较难.
2) 不同于新闻领域,ANN在小说领域上的性能较好,其平均r值达到了 0.184,在基准系统中仅次于C-LSTM的0.190.LSTM在小说领域上的表现明显差于其他基准系统,平均r值仅为0.160,尤其是在读者极性维度和读者强度维度上与其他基准系统相比有较大差距.而SVR在小说领域的性能依然稳定,3种特征输入得到的结果平均r值均在0.170以上,最高为SVR(TF-IDF)取得的0.182,进一步证明了传统的SVR在回归任务中是不亚于一般的神经网络模型的先进系统.
3) AdvNN在小说领域上亦取得了所有情绪维度下最高的r值,并且在读者情绪与作者情绪的所有维度下较r值最高的基准系统有至少0.019的明显提升.此外,AdvNN在小说领域的平均r值达到了0.219,亦超过了平均r值最高的基准系统C-LSTM.在小说领域上的结果进一步证明,AdvNN相比C-LSTM在本文的任务上能够进一步提升基于LSTM的神经网络回归模型的性能.
4) 小说领域上,AdvNN在MSE评估指标下的表现也较为良好,并在作者极性维度和作者强度维度中取得了最低的MSE值.除了在读者可控性维度中的MSE值高出MSE值最低的基准系统C-LSTM较多之外,在其他未取得最低 MSE值的情绪维度上相比该维度的最低值差距亦较小.然而与新闻领域不同的是,AdvNN在所有情绪维度下取得了0.124的平均MSE值,与SVR(TF-IDF)相同,略高于C-LSTM取得的0.122,总体而言并未取得最佳的MSE值.
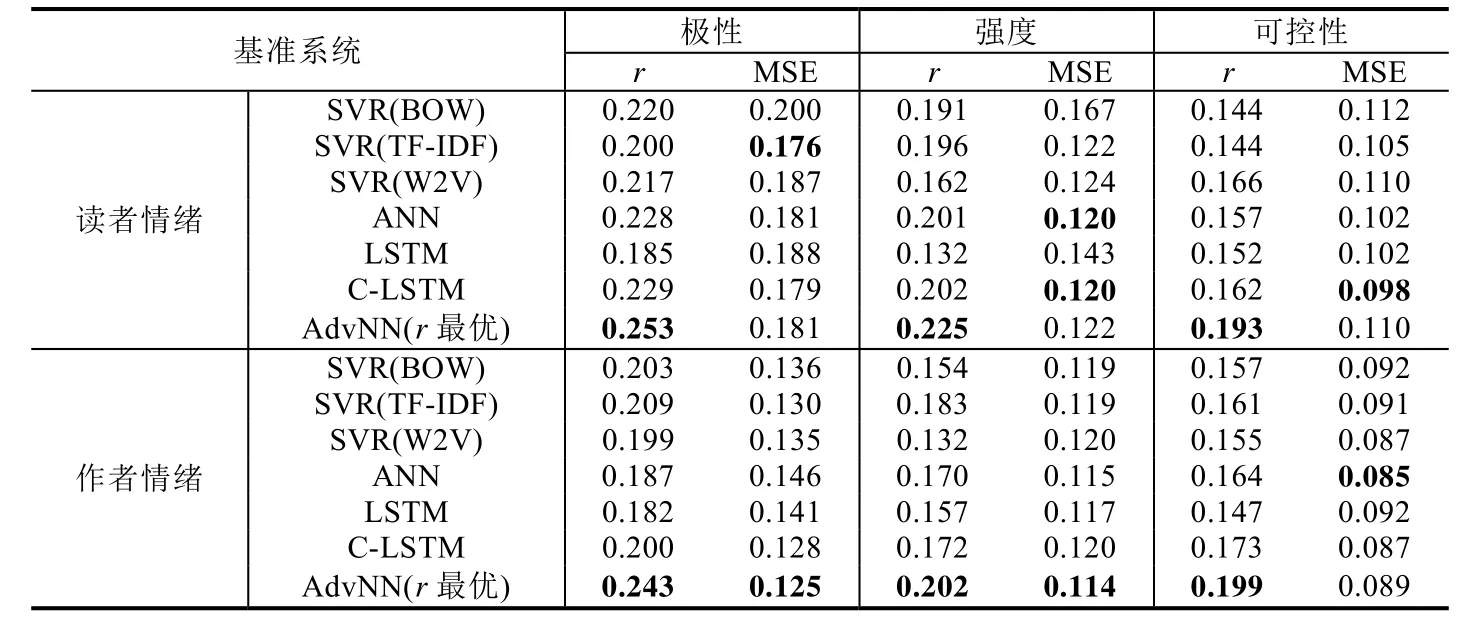
Table 6 The performances of various approach on the Fictions domain表6 各种方法在小说领域上的情绪回归性能
例句 6:She screamed I haven’t socialized with Terra’s elite for most of my life.(她尖叫到:我人生中大部分时间都没能与地球的精英社交.)
例句7:The only other illumination came from a lurid moonlight filtered through thin branches and clouds casting its bone-pale glow onto the pine floorboards.(唯一的其他照明来自一缕透过稀薄的树枝和云彩的月光,将其苍白的光芒投射到松木地板上.)
进一步分析表7,可以发现:
1) 在小说领域上,AdvNN在所有维度上的非最优r值依然高于最强基准系统,并未出现新闻领域上AdvNN在个别维度的非最优r值低于基准系统的情况.其中,读者极性情绪、读者可控性情绪以及作者极性情绪上AdvNN的非最优r值相比最强基准系统都有至少0.018的提升.
2) 各情绪维度在不同模型中的平均r值亦均超过相应维度的最强基准系统结果,其中,AdvNN在作者极性情绪上取得的平均r值达到0.239,相比该维度上的最强基准系统SVR(TF-IDF)的提升达到非常显著的0.030.
3) 通过上述结果可以看出,小说领域的文本由于领域的特性,其情绪分析的难度相对新闻领域较低.两个领域上的结果对比说明了读者在阅读一段包含情绪的文本时并不受领域差异性的影响,对于情绪的表达会有较明显的波动,使得情绪分析系统能够较好地从文本中挖掘相关的特征来完成情绪回归的任务.而作者情绪则会较明显地受领域差异性的影响,尤其是作者强度情绪.小说领域的作者情绪强度不同于新闻领域,作者不需要保持情绪上的客观性,因此小说领域的作者强度情绪和读者强度情绪一样,能够比较容易地被情绪回归系统识别.

Table 7 Detailed performances of AdvNNs for three combinations of emotion dimensions on the Fictions domain表7 小说领域上3种情绪维度组合的对抗式神经网络详细性能
3.5 显著性测试
除了上述的情绪回归实验结果之外,我们进一步给出了本文所提方法的输出结果与r值最优的基准系统输出结果之间的配对双样本t检验结果.表8与表9分别给出了新闻与小说领域中各情绪维度上双样本t检验的p值.与实验结果一样,表8与表9中的p值亦为5倍交叉验证每一组测试集上输出结果之间显著性测试的平均值.
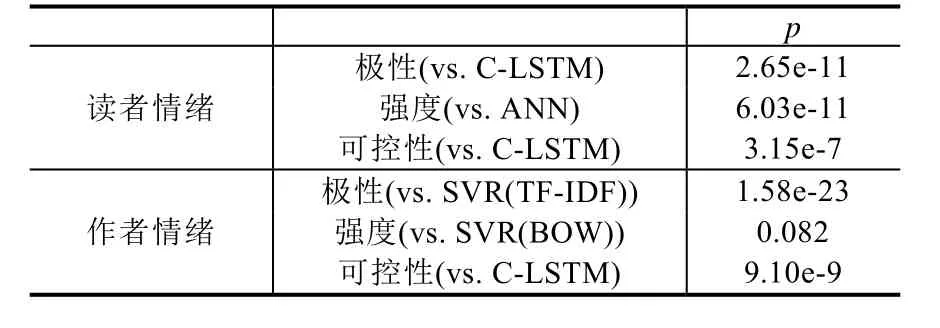
Table 8 Results of dependent t-test for paired samples between AdvNN and strongest baselines for each emotion dimension in the News domain表8 新闻领域上AdvNN与各情绪维度下最强基准系统之间的配对双样本t检验结果
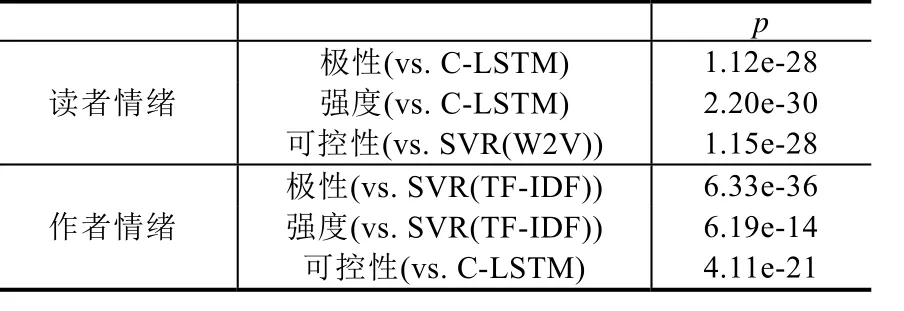
Table 9 Results of dependent t-test for paired samples between AdvNN and strongest baselines for each emotion dimension in the Fictions domain表9 小说领域上AdvNN与各情绪维度下最强基准系统之间的配对双样本t检验结果
从表8所示结果可以看出,在新闻领域中,除了作者强度维度之外,本文提出的AdvNN相比各情绪维度上最强的基准系统有显著的性能提升(p<0.05).仅在作者强度维度上,AdvNN相比最强基准系统 SVR(BOW)的提升不明显(p>0.05).而表 9的结果则表明,在小说领域中的所有情绪维度上,AdvNN相比各维度上的最强基准系统均有显著的性能提升.显著性测试的结果表明,本文提出的AdvNN相比其他基准系统不仅在r值评估指标下有明显的数值上的提升,并且这一提升具有统计显著性,从而进一步证明了AdvNN在EMOBANK语料中多维度情绪回归任务上的优越性.
4 结论与未来工作
本文针对多维度情绪回归这一任务提出了一种基于对抗式神经网络的多维度情绪回归方法.该方法包括了对抗式神经网络和对抗式学习算法.对抗式神经网络包括 3个部分:特征抽取器、回归器以及判别器.以在一对情绪维度上进行对抗式学习的情绪回归模型为例,首先,本文实现了两个基于 LSTM 神经网络模型的特征抽取器,以分别从输入的文本词向量矩阵中抽取与特定情绪维度相关的特征向量.其次,本文使用两个基于全连接神经网络的回归器,以分别根据特征抽取器输出的特征对特定情绪维度进行打分.最后,本文实现了一个基于全连接神经网络的判别器,以判别特征抽取器抽取的特征属于哪个情绪维度.该方法借助判别器,在两个情绪维度的特征抽取器之间通过对抗式学习算法进行对抗式训练,从而使两个特征抽取器能够从文本输入中抽取泛化性更好的针对不同情绪维度的特征向量,继而获得更好的回归性能.在EMOBANK语料的新闻和小说两个领域上的实验结果表明,无论是作者情绪回归还是读者情绪回归,本文的方法在3个情绪维度上的r值均超过了所有的基准系统,其中包括了文本回归领域中的先进系统 ANN.除了文本回归先进系统之外,本文还将文本分类领域的先进系统 C-LSTM 进行修改后用于本文针对的多维度情绪回归任务进行比较,而本文提出的方法依然在所有情绪维度上取得了更好的r值.除实验结果之外,AdvNN与各情绪维度上最强的基准系统间的显著性测试也表明,AdvNN取得的性能提升具有统计上的显著性,进一步证明了AdvNN在EMOBANK新闻与小说领域上的多维度情绪回归任务上的优越性.
然而,本文的方法目前仅为两个维度之间的对抗,并且在一些维度下取得的提升并不明显(例如新闻领域上的作者强度情绪维度).此外,一些情绪维度的对抗组合取得的性能提升也并不非常理想,甚至有个别组合在某个情绪维度下取得的r值相比部分基准系统有所下降.因此,我们未来的工作将首先集中于同时进行三维度之间的对抗.此外,我们还将改进对抗式学习框架与算法,例如引入共享参数的神经网络层来进一步学习抽取不同维度间的公共特征,以期能够在所有情绪维度对抗的组合上都取得稳定且明显的提升.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中学生报·教育教学研究(2022年1期)2022-04-18
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
外语学刊(2021年1期)2021-11-04
时代英语·高一(2019年5期)2019-09-03
电子制作(2019年24期)2019-02-23
外语教学理论与实践(2014年4期)2014-06-13
数理化学习·高一二版(2009年2期)2009-03-30
数理化学习·高一二版(2009年1期)2009-03-19
