
基于双总线架构的经编机双贾卡提花控制系统
2019-08-08 07:37:30夏风林蒋高明
纺织学报 2019年7期
张 琦, 魏 莉, 罗 成, 夏风林, 蒋高明
(1. 江南大学 教育部针织技术工程研究中心, 江苏 无锡 214122;2. 武汉纺织大学 湖北省数字化纺织装备重点实验室, 湖北 武汉 430077)
经编压电贾卡提花作为一种灵活的单针提花控制技术,可与梳栉整体横移提花组合出更加丰富的提花效应与立体效果,因而成为现代经编提花产品的主要生产技术。对经编机压电贾卡提花控制技术的研究,有德国公司最早开发的基于背板母线架构系统,国内研究人员亦曾先后利用单片机构建嵌入式贾卡提花控制系统[1-2],或者利用控制器局域网络(CAN)总线构建贾卡花型传输系统[3-4],或者直接将驱动电路嵌入到贾卡针块内部构建混合异构通信系统[5-6],上述研究虽已形成功能完备技术成熟的贾卡提花控制系统,但是其系统控制对象仍限于单把贾卡梳栉。
随着近年来经编塑身内衣与无缝服装等双贾卡编织工艺的研发,尤其是立体提花鞋材这种一次成形量大面广的贾卡提花产品的出现,使得经编贾卡提花控制系统中的控制对象从1把贾卡梳栉增加为2把,甚至3把;提花总针数增加1倍,提花信息量对应的数据量增加到8倍,同时每横列贾卡针的4次偏置动作又将动态数据的刷新时间缩短为单贾卡的四分之一。更多的数据量需要在更短的时间里完成处理,二者量变上的冲突迅速加剧了双贾卡提花控制系统生产过程中实时数据处理的大时滞特性,导致静态花型数据加载时间过长、产品工艺翻改周期长, 动态偏置数据刷新不及时、机器生产速度降低等系列问题,故而只是通过对现有单贾卡控制系统进行简单硬件倍增而成的双贾卡控制系统,难以真正满足双贾卡经编产品的生产要求,因此,基于双贾卡提花更加严苛的控制要求与时序特征,本文对双贾卡提花控制系统硬件的架构设计、控制软体的时序编排分别进行针对性分析研究,并构建100 Mbps以太网(Ethernet)与2 Mbps高速通用连接(G_Link)总线的双总线系统架构,设计双线程时序与双缓冲数据堆栈(FIFO)的控制软体,以平衡实际生产中提花数据量剧增与实时处理时间缩短之间的内在冲突,寻求经编机双贾卡提花控制系统可靠、高效的技术解决方案。
1 双贾卡编织机构与动作分析
1.1 双贾卡提花编织机构
双贾卡经编机多为配置有4片半机号贾卡导纱梳的双针床经编机,例如在RDJ6/2型双贾卡经编机的梳栉配置图(见图1)中,JB4.1与JB4.2,JB5.1与JB5.2可分别合并为2把完整贾卡梳栉JB4与JB5,且在前针床与后针床均可成圈[7]。其编织过程为:利用贾卡导纱梳的整体横移动作与单根贾卡导纱针独立的左/右偏置动作相互配合,形成厚、薄、网孔3种基本组织,利用双贾卡导纱梳栉在前/后针床选择性成圈的相互配合,形成缝合、镂空、透空、麻点等多种特殊组织[8],如若同时将基本组织与特殊组织进行巧妙组合,或再配以色纱与功能性差异纱线的穿纱设计,便可在编织出具备不同颜色与组织效应的双面织物时,同步形成特殊的双层组织结构,使得经编机以一次成形方式高效生产筒状中空织物以及间隔层立体提花织物成为可能,进而衍生出无缝连体服装与提花立体鞋材等多系列先进经编工艺与产品。
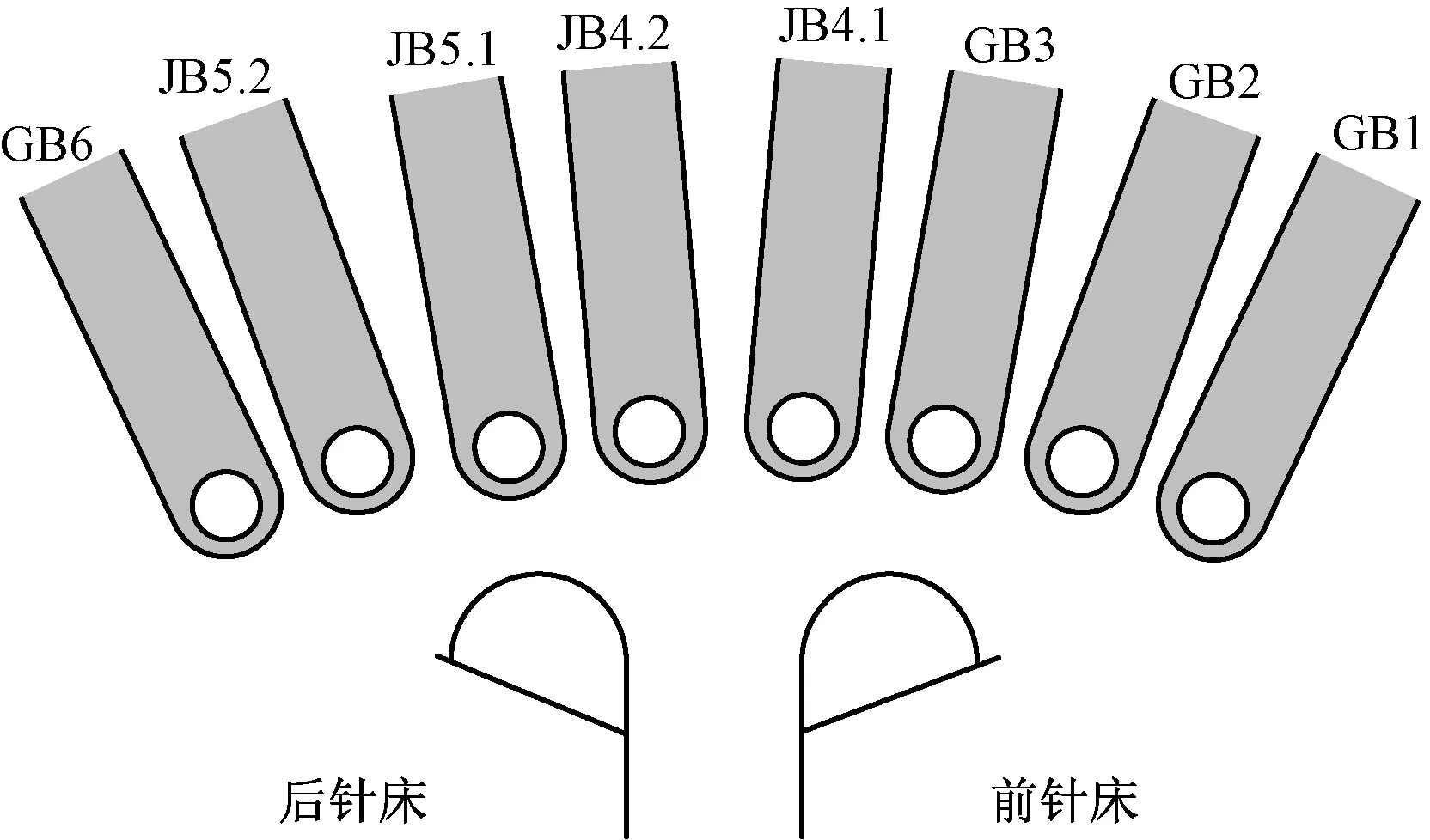
图1 RDJ6/2双贾卡梳栉配置图
Fig.1 Arrangement of double jacquard bar in RDJ6/2
1.2 双贾卡提花动作时序
为配合贾卡导纱梳在前/后针床的垫纱成圈编织,贾卡导纱针必须在前/后针床完成相应的偏置动作。如果将图1中JB4与JB5 2把贾卡梳上所有贾卡导纱针在前/后针床上的偏置动作时刻,投射到编织机构动作周期中的每个编织横列,也即经编机主轴的每个360°旋转周期中,可得如图2所示的双贾卡4次偏置时序图。即沿着经编机主轴的旋转方向,可依次得到4个触发偏置角度,其中偏置角度θ1对应前针床针前偏置动作时刻、θ2对应前针床针背偏置动作时刻、θ3对应后针床针背偏置动作时刻、θ4对应后针床针前偏置动作时刻,依主轴正向旋转循环,从而构成所有贾卡导纱针在每个编织动作基本周期内的偏置动作时序。
双贾卡控制系统的时序机制,就是根据不断循环的基本编织周期横列数与提花工艺信息之间的映射关系,实时并准确地从提花数据文件中提取对应横列的各次偏置动作数据,严格依据基本编织周期内的偏置动作次序,精准判别触发角度,在该角度时刻实时输出提取的所有工艺提花信息,确保所有贾卡导纱针在梳栉开始整体横移垫纱前同步完成偏置动作,并在随后的角度区间内稳定保持最后一次刷新的偏置状态,4个偏置角度之后的4个角度分区亦如图2所示。
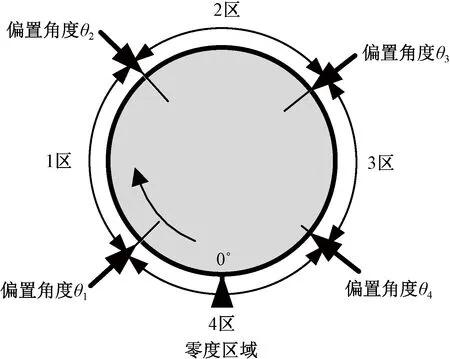
图2 双贾卡4次偏置时序图
Fig.2 Quartic trigger time series of double jacquard
2 控制系统硬件架构设计
对应于经编机整个幅宽长度内任一把贾卡梳栉上几千枚贾卡导纱针的提花信息,即使每枚针的左偏或右偏状态只用1位值为“0”或“1”的位变量来表示,1次偏置动作也需要几百个字节的数据量。相对于普通单贾卡系统在1个基本编织周期中只在针背进行1次偏置动作,双贾卡系统在1个基本编织周期中却需要4次偏置动作,2把贾卡梳的4次偏置动作数据量就是前者的8倍,另外在相同的生产速度条件下,若按照每完成1次偏置动作后刷新1次数据的方式,则后者刷新1次偏置动作数据的时间却只有前者的四分之一,因此,为在更短的时间内完成更大数据量的实时处理,构建了基于二级总线式系统架构和组合式贾卡控制单元的经编双贾卡提花控制系统。
2.1 双总线架构
双贾卡经编机的集成控制系统除包含对贾卡电子提花的实时控制外,一般还会包括电子送经、电子牵拉和电子横移等其他实时运动控制,为确保高速生产过程中贾卡电子提花控制功能的实时性,并避免与其他控制功能同时参与对上位工控机实时资源的抢夺争占,采用将贾卡提花工艺数据文件由上位工控机下载至位于控制层的、由嵌入式工控机担任的专用贾卡控制器内,再由贾卡控制器控制位于现场层的多个组合式贾卡控制单元,在整个集成控制系统中以相对独立的方式完成对贾卡电子提花的实时控制。为便于集成系统的模块增减,设计了3层2级总线式系统架构。
第1级数据总线选择速率为100 Mbps的Ethernet,借助传输控制协议/因特网互联协议(TCP/IP)可靠的点对点联接,以及以太网可以超过1 K字节的大数据包批量传送数据块的高容载量传输特性,来匹配双贾卡提花工艺数据文件的大量数据必需在极短时间内整体且快速地由上位工控机传送至贾卡控制器内的传输要求,实现贾卡提花工艺数据在静态下的频繁快速加载,以满足实际生产过程中频繁更换工艺的操作要求。
第2级数据总线选择速率为2 Mbps的G_Link总线,基于RS422全双工通信总线标准,可以较短的数据帧长度以自由数据格式进行高速实时通信,满足贾卡控制器与各贾卡控制单元之间一点对多点的周期性高速通信,用于动态传输某个基本编织周期内的实时偏置动作数据。
独立控制贾卡电子提花功能的贾卡控制器具有1个编码器信号输入接口,2条G_Link总线硬件接口与编码器信号输出接口,主轴角度编码器信号在送达贾卡控制器后,采用与G_Link总线同电缆的方式,硬联接延送至各贾卡控制单元,每个G_Link总线硬件接口最多可驱动16个贾卡控制单元。
2.2 贾卡控制单元
安装于经编机机台上直接驱动贾卡导纱针块的贾卡控制单元,是为了提高系统扩展的灵活性与安装调试的便利性,集驱动与实时控制于一体的可组合式扩展单元,每个单元包含1块采用复杂可编程逻辑器件(CPLD)硬件编程的嵌入式微控制单元(MCU)控制板以及最多16块贾卡驱动板。
为实现双贾卡控制系统中2把贾卡梳栉分别具有各自不同的触发偏置角度,以使得每把贾卡梳在工艺最需要的时刻才触发导纱针偏置,并保证同一把贾卡梳上所有贾卡导纱针的偏置同步性,采用将各自的触发偏置角度预存至每把梳对应的所有贾卡控制单元内,这样所有单元内的MCU控制板与贾卡控制器同时监测系统内唯一的主轴角度编码器信号,当主轴角度与本单元内预存的偏置角度相同时,立即触发16块驱动板上对应偏置数据的并行输出。由于主轴角度信息的唯一性,以及各贾卡控制单元并行同步处理的实时性,在保证同一把贾卡梳栉上所有贾卡导纱针并行输出的严格同步性时,还实现了2把贾卡梳利用分离角度在各自最需要的时刻位置精准动作。
3 控制系统软件时序设计
针对经编双贾卡提花控制系统中静态花型数据加载时间的缩短以及动态提花数据刷新率的提高,在依赖各级总线通道硬件支持与特性匹配的基础上,还需要针对不同软件环节设计高效率的通信机制与数据处理时序。
3.1 静态花型加载
静态花型加载包括在以太网上的高速数据传送,以及在贾卡控制器内数据的快速接收,并同步转换为大数据块文件格式完成本地存储2个加载环节。
按照GB/T 21547.4—2008《VME总线对仪器的扩展 第4部分:TCP/IP-IEEE488.2仪器接口规范》,TCP/IP协议作为以太网通信的一种可靠性连接,在通信开始前双方即确定通信的最大报文段长度(MSS),为避免携带TCP报文的IP数据包在IP层传输过程中超过最大传输单元(MTU)导致IP数据包被分片,通常将TCP的MSS值设置为MTU值减40字节(其中TCP报文与IP报文头部长度各占20字节),而对Ethernet而言,MTU最佳值为1 500,则MSS最大值是1 460字节[9]。Ethernet的MSS值直接决定了1个TCP数据包内单次能够传送的最大贾卡花型数据字节数。以每枚贾卡导纱针的偏置状态用1位布尔类型数据计算,则封装16枚导纱针的1块贾卡针块1次偏置需要2个字节,1个贾卡控制单元最多控制32块贾卡针块,故1条G_Link总线上最多16个贾卡控制单元内的所有贾卡导纱针完成1次偏置动作最大需要1 024即1 K字节数据,该最大值接近并且小于MSS值,因此若规定1个TCP报文1次发送所有贾卡导纱针的1次偏置数据,1个横列的花型数据分4次传送完成,则可完全避免IP数据包被分片,还能简化贾卡控制器内处理TCP/IP通信程序的复杂度,在保证Ethernet以最佳效率通信外,还在MSS允许范围内以最大数据容载量实现贾卡花型数据的高速传输。
当贾卡花型数据以100 Mbps的速率从上位工控机传送至贾卡控制器以完成失电存储的静态数据加载时,后者却由于最大20 Mbps的外部非易失存储数据写出速度和有限的随机存取存储器(RAM)内存空间[9],既不能以更快或相同的速度将高速到达的数据同步写出外部存储,也难以将所有接收到的花型数据均以变量形式全部存放于内存RAM,使得贾卡控制器必须在高速处理后续每个到达的TCP数据报文的同时,还要将之前所有处理完毕的偏置数据实时且完整地存入本地非易失存储空间内,直至所有横列的花型工艺数据传输完毕,不允许有任何数据的接收溢出与存储丢失。
为提高大数据量贾卡静态花型加载过程的实时性,避免以太网通信高速的数据写入操作因低速的外部存储数据写出操作而被中断处于频繁等待状态,设计了如图3所示的采用双级FIFO缓冲数据堆栈处理机制的双线程静态花型加载流程。2个线程作为2个相对独立的任务并行执行,其中线程1负责对高速到达的TCP数据包的实时接收,对每4个报文的数据进行提取并按照贾卡导纱针实际偏置逻辑需要重新组合拼装成1个横列的完整偏置数据结构体后,写入缓冲数据堆栈FIFO 0;当FIFO 0的堆栈指针到达指定深度后,利用内存数据块操作的高速指令将FIFO 0内的全部数据快速拷贝至缓冲数据堆栈FIFO 1内;线程2在发现FIFO 1内有新数据写入后,执行静态数据文件的外部存储连续写出操作。借助双FIFO对高速数据流的缓冲特性,以及双线程任务执行时在时间上的并发与互补特性,通过匹配2个线程的任务周期N与M值,可在真正发挥Ethernet 100 Mbps高速大容载量传输特性来压缩数据传输时间的同时,兼顾静态数据文件的存储操作,以最少的等待时间和最高的数据传输效率,实现大块数据流的高速流入与低速汇出之间的动态平衡。
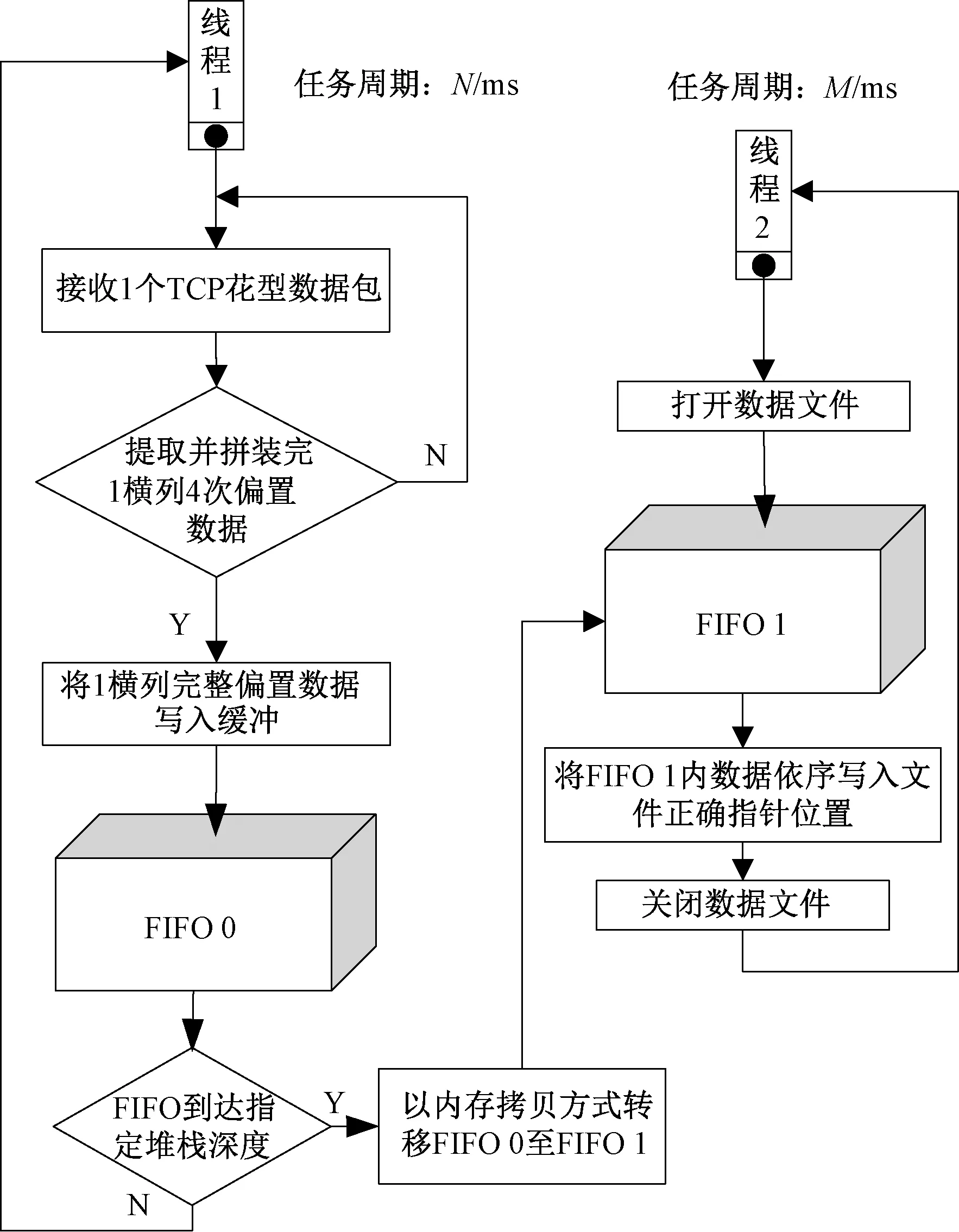
图3 静态数据加载与转存线程
Fig.3 Load-thread and store-thread of pattern data
3.2 动态数据刷新
动态数据刷新包括实时偏置数据在G_Link总线上的实时数据传输,及每个贾卡控制单元内偏置数据随主轴角度变化的瞬时偏置输出2个刷新环节。
相对于单贾卡经编提花在生产1个横列的过程中只需要1次偏置,其最多可利用经编机主轴转过1周的时间来完成1次动态数据的传输,双贾卡提花生产1个横列需要4次偏置,其1次偏置数据的传输时间只有1个横列的四分之一,理论上必然会导致经编机生产速度降低,因此,为提高生产过程中双贾卡经编提花数据的动态刷新实时性,并在一定程度上提高车速,为动态数据刷新争取足够的传输时间,利用CPLD有限的存储空间和G_Link总线的配合,设计了如图4所示的动态数据刷新时序。
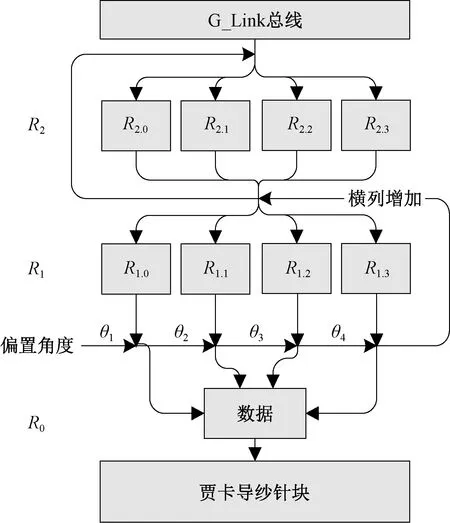
图4 动态数据刷新时序图
Fig.4 Time series of dynamic data refreshing
在每个贾卡控制单元内的MCU控制板上,开辟3组数据寄存器:R0长度为64字节,用以存放当前单元内16块驱动板上32块贾卡导纱针块的某1次动态偏置数据;R1由4个长度为64字节的存储单元构成,用于存放当前横列的4次动态偏置数据;R2同样由4个长度为64字节的存储单元构成,但用于存放当前横列下1个横列的4次动态偏置数据。在机器位于主轴0°时完成工艺花型数据的加载后,将3组数据寄存器R0、R1、R2的数据全部分别填满,其中R0为贾卡导纱针上立即输出的偏置状态数据,填写为花型起始编织横列的前一横列的第4次动态偏置数据,若起始编织横列为第1横列,则其前一横列为完整工艺花高的最后横列;R1的4个存储单元R1.0~R1.3中依次填写花型起始编织横列第1横列的4次动态偏置数据,R2的4个存储单元R2.0~R2.3中依次填写花型起始编织横列下一横列即第2横列的4次动态偏置数据,这样,在主轴开始旋转前,每个贾卡控制单元中已经预装了2横列完整的动态偏置数据。
随着机器的启动即主轴的旋转,主轴依次转过偏置角度θ1~θ4,寄存器R1中的4次偏置数据也被依次打入R0并即时输出刷新为所有贾卡针的偏置状态,当R1.3中的第4次偏置数据被打出后,MCU控制程序认为1个工艺横列已经完成,立即将寄存器R2内的全部数据同时打入R1对应的4个存储单元内,随后触发G_Link总线,开始下载第3横列的动态偏置数据,因此,当机器主轴开始生产第2个工艺横列时,G_Link总线上已同时开始第3个工艺横列的数据传输,且由于传输时间长度最大为经编机主轴转过1周的时间,因此同一横列内的4次偏置数据不必分开传输,可一次性传输至CPLD的R2.0~R2.34个存储单元中。
通过在位于控制底层的贾卡控制单元内以较少的存储字节数开辟R2与R1双级FIFO数据缓冲区,使R2与G_Link总线对接以缓冲总线预存数据,使R1与执行元件贾卡针对接以缓冲实时输出数据,从而实现动态数据刷新时的总线数据传输与偏置数据输出这2个原本存在严格先后时序依存关系的动作,由于被双缓冲FIFO从空间上分切隔离,从而使得二者可在同一时间内并发执行互不冲突,以有限的存储空间争取到宝贵的数据刷新时间。
4 控制系统生产验证
实验条件:采用2台相同幅宽(106.68 cm)与相同机号(E24)的RDJ6/2双针床织样经编机,其中一台经编机的贾卡提花控制采用本文所设计的基于双总线架构的第2代双贾卡提花控制系统(版本V2.0);另一台经编机的贾卡提花控制仍采用基于单贾卡控制系统进行硬件倍增扩展,采用CAN总线进行数据加载,且可对2把贾卡梳栉进行提花控制的第1代双贾卡提花控制系统(版本V1.0)。
实验方法如下。第1步进行优化实验,即针对第2代双贾卡经编机提花控制系统,调整图3中2个并行线程的任务周期N与M的值,反复加载花高为1 000横列的同一款花型文件,寻找最短加载时间下N与M的最优匹配值,实验的过程数据如表1所示。第2步为对比验证实验,对比实验包含花型加载速度与织样生产速度的对比:首先,在2台经编机上反复加载花高为1 000横列的同一个双贾卡工艺数据文件,对比第1、2两代贾卡提花控制系统加载花型消耗的平均时间,以比较二者对静态花型数据的传输速度;然后,在2台经编机上同时织造如图5所示,花高为390横列的同一款双贾卡经编立体提花鞋材产品,对比第1、2两代贾卡提花控制系统控制织样时的最高生产机速,以比较二者对动态偏置数据的实时处理效率。对比验证实验的过程数据如表2所示。
表1 双线程任务周期值优选
Tab.1 Optimization of double thread task cycle time

测试编号重复加载次数线程1周期N值/ms线程2周期M值/ms平均加载时间/sa10228b105220c102510d105522

图5 织样验证
Fig.5 Weave sample validation. (a) Drafted pattern; (b) Sample
表2 两代双贾卡控制系统性能对比Tab.2 System performance comparison betweentwo double jacquard control systems

双贾卡系统版本总线类型总线速率1 000横列花型加载耗时同款产品最高生产速度/(r·min-1)V1.0CAN250 Kbps20 min350V2.0Ether-net100 Mbps10 s450
从表1的实验数据可看出,线程1的任务周期时间对花型的加载时间影响较大,而线程2的任务周期对花型加载时间影响较小。这是由于受机器窄幅宽限制,在每横列数据量无明显增加的情况下每横列分4个TCP数据包传输的方式明显影响着传输时间。考虑到常规经编鞋材产品的花高一般不会超过1 000横列,且如果线程1与线程2同时采用最短的任务周期,会在实际生产中影响贾卡控制器通过G-link总线向底层贾卡控制单元刷新动态偏置数据的响应实时性,而且每次加载花型时间小于10 s生产厂家完全可以接受,因此综合考虑,最佳的数据加载中双线程周期分别取值N为2 ms,M为5 ms。
从表2可看出:由于第2代双贾卡控制系统采用的100 Mbps Ethernet总线速率远远超过第1代双贾卡控制系统CAN总线,使得二者在加载同一款1 000横列花高的花型文件时,加载时间由20 min缩短为10 s,相差120倍;且在织制相同产品时,实际机器生产速度从350 r/min提高到450 r/min,提升近30%。
5 结 论
本文针对经编双贾卡提花控制系统的具体特点与控制要求,进行了基于二级总线式架构和组合式贾卡控制单元的经编双贾卡提花控制系统设计,经生产验证后得出如下结论。
1)针对大字节数的双贾卡静态工艺数据的频繁加载要求,选择高传输速率和大数据容载量的百兆以太网作为一级总线,可明显压缩花型加载耗时,1 000横列、宽为106.68 cm、机号为E24针双贾卡工艺文件加载时间约为10 s;针对大字节数的双贾卡动态偏置数据的高速实时刷新要求,选择速率为2 Mbps的G-Link作为二级总线,通过与贾卡控制单元的数据预存机制相互配合,可将单横列偏置数据的传输时间争取为主轴旋转1周的时间。
2)在软件处理上采用双级FIFO数据缓冲技术,不仅可在贾卡系统控制层有效节省数据流的高速流入与低速汇出之间的等待延时,还可用于贾卡系统现场层对总线数据传输与执行元件的数据触发进行物理切分而实现二者时间上的并行执行,进一步挖掘软件执行效率以提高系统控制实时性。
3)所设计的新式双贾卡经编机提花控制系统可满足双贾卡经编机及相应工艺产品的生产要求,相对旧式贾卡系统,花型加载速度提升约120倍, 机器最高生产速度提升近30%,无论是静态花型加载速度,还是动态偏置数据实时处理过程中的生产速度,都有显著提升。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19 02:48:32
中国信息化(2022年5期)2022-06-13 11:12:49
设备管理与维修(2022年24期)2022-02-08 13:15:42
小资CHIC!ELEGANCE(2019年32期)2019-11-22 07:56:49
北京航空航天大学学报(2016年6期)2016-11-16 01:50:49
纺织学报(2016年8期)2016-07-12 13:28:41
广东石油化工学院学报(2016年6期)2016-05-17 05:17:33
中国纺织(2015年7期)2015-09-07 00:13:46
浙江理工大学学报(自然科学版)(2014年1期)2014-05-25 00:35:47
电子设计工程(2014年19期)2014-02-27 12:00:54
