
结合显著区域检测和手绘草图的服装图像检索
2019-08-08 07:37:38吴传彬付晓东刘利军黄青松
纺织学报 2019年7期
吴传彬, 刘 骊,2, 付晓东,2, 刘利军,2, 黄青松,2
(1. 昆明理工大学 信息工程与自动化学院, 云南 昆明 650500;2. 昆明理工大学 云南省计算机技术应用重点实验室, 云南 昆明 650500)
随着时尚服装的发展和移动终端设备的普及,网上购买服装已成为主流。然而,由于网上商店提供用来检索服装的关键词数量和类别有限,用户很难从海量图像中获得自己想要的服装款式;因此,“以图搜图”[1-2]的服装检索技术出现。目前在各大电子商务平台上应用基于拍照购物的方式进行服装检索时,并不是所有用户都能随时随地拍到想要检索的图片,加之拍照图片极大地受到光照、场景以及设备性能的影响,导致检索准确率不高。相反,基于手绘草图的服装图像检索可以不受任何限制,简单的手绘草图更容易表达出服装款式且没有任何歧义。此外,常用图像通常包含了丰富的色彩、纹理,检索中需要对这些特征信息进行匹配或估计,导致检索实时性差。而在服装检索中,用户主要关心的是服装款式,并不是色彩、纹理等特征,因此,研究人员提出不使用任何颜色和纹理特征,只用形状特征的方法来进行服装图像匹配,即基于手绘草图的服装图像检索[3]。不同于自然图像,草图只有单纯的黑白线条,二者间存在很大的差异,难以与真实自然图像直接匹配。Tseng等[3]采用Jseg的分割方法提取服装图像的轮廓特征,然后进行草图与服装图像轮廓匹配,但Jseg分割方法只针对背景清晰且服装图像平整的情况。Kondo等[4]采用多种算子对服装图像进行特征提取,通过平衡不同算子的权重作为检索依据获得检索结果。由于不同服装款式对不同的算子敏感度差异很大,通过调节权重来改善检索结果并不是很理想。文献[5]通过形态学的预处理并结合Canny算子边缘检测提取服装轮廓,该方法只提取了服装外部轮廓,丢失了服装款式中的重要内部细节。文献[6]提出利用相关反馈技术的服装图像检索算法,然而,该方法只考虑了相似性,忽略了整个数据集中图像之间的相关性。Li K等[7]通过强监督的可变形部件模型(DPM)[8]检测器对属性进行检测,利用支持向量机(SVM)对属性分类得到检索结果,该方法要求数据需经大量人工标注,无法适应大规模数据的应用。
为有效解决上述问题,Zhang Y等[9]提出利用显著区域检测提取目标对象的轮廓。显著区域检测通常应用在图像分割中,可较好去除背景噪声的干扰,有效地得到目标区域,从而提高了检索准确率。在此研究基础上,本文提出基于视觉显著区域的手绘草图服装图像检索方法。区别于上述方法,本文通过超像素分割后的服装图像首先去除错误边界,采用正则化随机漫步模型生成的服装显著区域并结合边缘信息加权得到服装显著边缘,更加注重服装的完整性,而文献[9]侧重于利用局部区域来提高仿射变换的性能,并没有注重对象自身特点。在图像检索过程中,为提高检索的效率和鲁棒性,引入重排序策略[10],本文提出的图像重新排序方法首先根据距离相关系数来测量任何2个图像的相似度分布的对应关系;其次,通过1次聚类而不是多次迭代来更新相似性分数;使用距离相关系数以自适应方式更新分数。
1 方法概述
本文方法流程如图1所示,由离线阶段和在线阶段组成。离线阶段: 1)首先采用正则化随机漫步算法对输入的服装图像进行服装显著区域检测和采用globalPb[11]算法提取图像的轮廓信息,通过二者加权得到服装显著边缘;2)对输入服装显著边缘图像进行HOG特征提取;3)通过量化特征来构建特征索引库。在线阶段:针对给定的查询草图,首先通过提取用户草图的HOG特征,量化成视觉词汇;然后计算查询草图特征与数据集之间的相似性图像,得到初始的检索列表;最后采用基于距离相关系数的重排序算法对其相似度进行排序并输出结果。
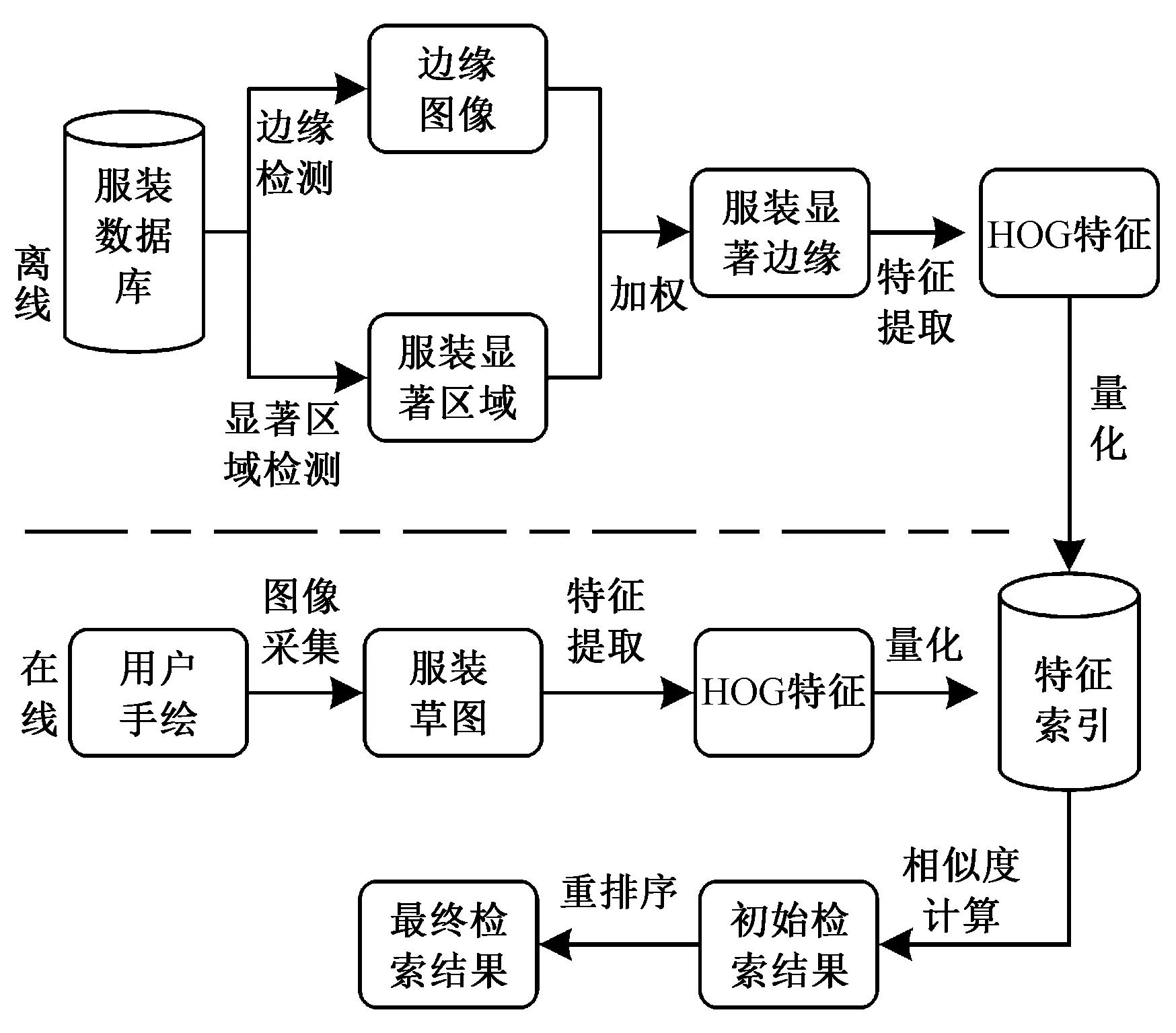
图1 本文方法流程图
Fig.1 Process flow diagram of proposed method
2 显著区域检测方法
为解决草图和真实服装图像间的差异,需要将真实服装图像转换成类似服装草图的图像,并消除其他噪声的干扰,从而有利于检索。
2.1 显著区域检测
采用简单线性迭代聚类[12]算法对服装图像过分割为超像素,分割完成后,所有超像素的每个边界作为1个连通区域,利用下式计算每个边界的归一化颜色(RGB)直方图:
(1)
式中:b∈{top,bottom,left,right}表示4条边的位置;l表示服装区域总像素数,r=0,,255;Iq表示像素q的强度值;δ(·)为单位冲激函数。计算4个边界直方图中任意2个的欧氏距离:
(2)
式中:b1,b2表示任意2条不同的边界,将直方图差值最大的边界确定为服装区域边界。它作为前景估计,其剩余的3个边界为不属于服装区域的错误边界,将作为背景估计。用S(i)表示显著估计结果,i=1,,n;n为超像素的总数量。

(3)
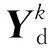
(4)
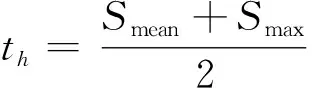
2.2 服装显著边缘
由于服装图像自身的特性(如褶皱、阴影等带来的噪声),一般的边缘检测算法不能很好地应用于服装图中。本文采用globalPb算法[11]对服装图像进行语义边缘检测。该方法利用切割高曲率的点将边缘图转化成多个边缘片段V={v1,v2,,vi}。通过计算边缘轮廓片段之间的距离和长度的比率来得到主边缘轮廓。本文进一步定义了一个能量函数来计算边缘片段之间的平滑程度,只有平滑度较高的片段才会保留为生成的边缘。对于一组边缘片段Vi∈V,通过能量函数对边缘进行平滑,得到初始的边缘检测图,用F2(x,y)表示:
(5)
式中:E(Vi)表示能量函数;|U|表示Vi中高曲率折点的数量;L表示Vi中所有曲线段的总长度。
最后将服装显著区域图与初始的边缘检测图进行逐像素相乘,得出服装显著边缘图像,并形成服装显著边缘图像库,服装显著边缘图可表示为
F(x,y)=F1(x,y)×F2(x,y)
(6)
3 手绘草图的服装检索算法
3.1 特征提取与表示
为加强方向梯度直方图(histogram of oriented gradient,HOG)[13]描述子的位置和空间方向的描述能力,文献[14]以一组稀疏笔画(草图)构造了一个密集的边缘方向场,并在多个尺度上计算梯度直方图,得到梯度场的HOG(gradient field HOG,GF-HOG)特征。基于该方法,本文首先将输入的草图和服装显著边缘图进行了GF-HOG特征提取,部分实验结果如图2所示。其次将得到的GF-HOG特征通过K-means生成单个视觉词汇字典。每个服装边缘图构建频率直方图HI′,它表示出现在该图像中的GF-HOG特征的视觉词的分布,然后对直方图归一化。对待检索的服装草图,使用相同码本从服装草图中提取GF-HOG特征,得到归一化的直方图Hs。

图2 GF-HOG特征提取图
Fig.2 GF-HOG feature extraction map. (a) Salient edge; (b) Salient edge feature; (c) User sketch; (d) User sketch feature
3.2 相似度计算
基于得到的特征库O,本文构建了一个特征索引库,采用直方图相交方法计算草图s和服装显著边缘图像I′之间的特征相似度,进行特征匹配。Sim(Hs,HI′)可表示为
(7)
式中:wij=1-|H(i)-H(j)|,Η(i)是第i个bin的归一化计算,i={1,,k}。考虑到服装图像款式多样性特点,初始的检索结果包含了很多部分相似的图像,这些结果并不准确,导致检索鲁棒性差,因此,需要对初始的检索结果进行排序优化。
3.3 距离相关系数
为从数学角度表示2幅图像的相似关系,本文引入距离相关系数[15](distance correlation coefficient,dCor)。设Ms和Mi分别表示向量形式的草图和服装图像的相似矩阵。Mi∈O,则距离相关系数可以表示为
(8)

(9)
式中:w为阈值参数(参数大小将会在实验中讨论)。根据赋值函数的定义,可将初始的检索列表分成2个部分:
如果φ(Is,Ii)=1,则Ii在第1个部分p1中;
如果φ(Is,Ii)=0,则Ii在第2个部分p2中。
其中:p1表示与检索草图高度相似的图像;p2表示与检索草图可能相似的图像。
3.4 重排序
设Sl为给定检索草图Is和服装图像Il∈Sl生成的初始检索列表,则通过自适应方式应分成3个簇,如下所示:
如果Il∈P1,则Il被分在C1聚簇;
如果Ir∈P2,则Il被分在C2聚簇;
如果Il∉C1,Il∉C2,则Il被分在C3聚簇。
通过定义的3种不同的更新规则来计算C1,C2和C3组图像的相似性分数。设Siminit(Ip,Iq)表示手绘草图与服装图像初始的相似度分数,则通过以下规则计算优化后的分数:
1)若(Ip,Iq)∈C1,则Sfinal(Ip,Iq)=Siminit(Ip,Iq)×dCor(Ip,Iq);



4 实验与分析
实验选用Intel Core i7 7700K CPU, 4.20 GHz,32 GB RAM 的硬件平台以及Ubuntu 16.04系统下MatLab R2016a版本进行测试,所有实验都在统一环境下进行。
4.1 数据集
实验数据集来源于2部分。一个是由Liu Z等提出的DeepFashion[2]服装图像数据集,是目前公开规模最大的服装图像数据集。本文选用其数据集中的一部分服装图像,共包含20多类服装,主要有连衣裙7 849张、夹克4 500张、长款大衣3 845张、吊带5 560张、长裤4 721张、短裤4 564张、连衣裤5 957张、女裙裤4 090张、针织衫5 592张、卫衣4 495张、背心5 532张、衬衫4 385张、T恤6 548张、披肩3 234张、长袍2 584张、斗篷989张以及其他款式5 856张,共计80 301张图像。
另一个为服装草图数据集,来源于阿里巴巴的众包平台,本文从服装图像数据集中选取了120张服装图像进行手绘。服装草图数据的收集遵循以下2个规则:1)草图都是由没有绘画基础的人员在触摸设备上绘制,这与平常大部分人使用手机绘制是相同的情况;2)数据集中的图像涵盖了日常生活中经常见到的大部分服装类别。通过以上规则的筛选,共收集了360张服装草图,每款服装草图均来自3个不同的人员,其目的是为了保证每款服装草图的具有不同的手绘风格,大小均为256像素×256像素。图3展示了本文使用的部分草图数据。

图3 草图数据
Fig.3 Sketch data. (a) Dress; (b) Overcoat; (c) Jersey; (d) Kilt; (e) Shorts; (f) Trousers
4.2 实验结果与性能分析
4.2.1 检测结果分析

式中:ri为正确检测到的服装像素;si为利用算法检测到的服装总像素;gi为图像i中真实的服装总像素。检测实验中所输入的服装图像区域来自手工标注,以此作为计算依据。为更好地说明本文方法的性能,与其他同类方法MR[16]以及文献[9]中所采用的RC[17]方法进行了对比,比较结果如表1所示。MR采用流行学习方法生成服装显著区域,流行矩阵维度高,计算量大,要求硬件性能高;RC则是利用局部区域和全局对比度差异的方法进行显著区域检测。从表1看出,本文方法有明显优势,综合指标F值最优。部分实验结果见图4。其中:图4(a)为原始图像;图4(b)示出服装显著区域检测结果;图4(c)为边缘检测图;图4(d)示出最终加权得到的显著边缘结果。
表1 检测结果对比
Tab.1 Comparison of detection results

方法 召回率精确率F值MR0.8520.6580.745RC0.5960.9210.728本文方法0.8130.8210.826

图4 显著区域检测结果
Fig.4 Results of salient detection. (a) Clothing image; (b) Salient detection; (c)Edge detection; (d) Salient edge
4.2.2 检索结果分析
考虑到检索结果的排名情况,本文使用2个指标来衡量检索的性能。一是top-K的检索精度,假设1次有效的检索中,检索列表中发现前K个完全相同的服装图像,则表示命中的top-K检索精度。二是采用归一化折损累计增益(normalized discounted cumulative gain,NDCG)指标,定义如下:
(10)
式中:relq(j)表示查询草图q的检索结果列表中j图像位置排名的相关性分数;K表示检索列表中排名前K个结果。
实验中,随机选用了120张不同的服装草图作为查询图像,来检验本文方法的实验效果。输入1张服装草图,检索到K个图像,在这K个图像中存在相似的服装图像,则说明检索成功。图5示出本文所提的方法对检索准确率的影响。图中,GF-HOG指的是不采用任何优化方法得到的检索结果;VSR+GF-HOG曲线指的是采用视觉显著区域检测后得到的检索结果;RK+GF-HOG曲线指的是只考虑重排序的检索结果;VSR+RK+GF-HOG曲线指的是基于视觉显著区域和重排序二者优化得到的检索结果。由图可知,基于视觉显著区域检测的方法相比经典的GF-HOG有了很大的提升,重排序对检索性能也有了进一步的提升。其主要原因在于:通过显著区域检测后得到的显著边缘有效地解决了图像与草图之间的差异;其次采用基于距离相关系数的重排序策略对整个图像数据库首先进行子集划分,再对初始的检索列表进行优化排名,提高了检索的性能。

图5 本文方法与其他方法的比较
Fig.5 Comparison with other methods
4.2.3 实验参数设置的影响
为展示重要参数对整个检索性能的影响,分别在本文数据集上比较了2个参数,包括构建聚类中心的字典大小和阈值w大小对检索性能的影响,如图6、7所示。
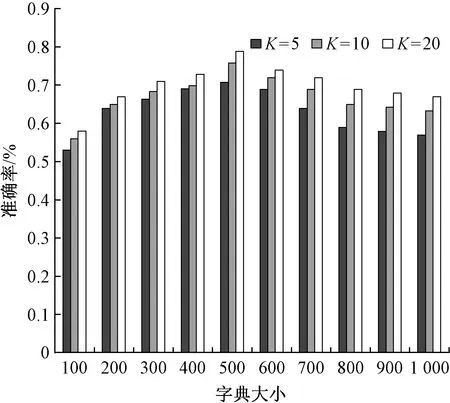
图6 字典大小的影响
Fig.6 Influence of codebook size

图7 参数w大小的影响
Fig.7 Influence of size of parameterw
从图6可以发现:随着字典大小从100增长到500,K=5,10,20的准确率都有了快速的提升;在字典大小为500时达到最大值;之后随着字典大小的增长而开始下降;当字典大小大于800时,趋于稳定。可以得出,当在字典大小为[400,600]时,可以得到最佳的检索性能,在本文的数据集上,字典大小为500最为合适。由于草图的编码信息本身比图像稀疏多,可有效提升检索效率,加之视觉显著区域检测能够有效地抑制除服装以外的噪声干扰,因此本文的字典大小要比同类的词包模型(bag-of-features,BoF)方法小很多,更有利于检索。
参数w是距离相关度量的阈值,这个参数影响了最后排名分数的情况。在改变w的大小时,检索准确率如图7所示。由图可知:当w值从0.2增长到0.4时,检索准确率有了明显的提高;从0.6到0.8时,检索准确率有所下降。主要原因是初始检索结果列表中的排序分数随着参数w的增长重排序的影响将增大,当w=1时,表示重排序分数确定最终的检索列表,初始检索结果被丢弃。图8示出部分检索实例,是没有应用重排序的检索结果,其中包含一些相似的图像,但也包含一些部分相似的图像,这些部分相似的图像并不是用户所要的结果。而在图9中,采用本文提出的重排序策略后,不仅去除了部分相似的图像,而且提高了检索性能。

图8 没有使用重排序的检索结果
Fig.8 Retrieval results without re-ranking. (a) Retrieve images; (b) Top 10 of search results

图9 使用重排序后的检索结果
Fig.9 Retrieval results with re-ranking. (a) Retrieve images; (b) Top 10 of search results
4.2.4 检索对比实验结果
本文方法在NDCG(K20)(表示检索结果排名前20的比较情况)上明显要优于其他方法,如表2所示。文献[9]通过改进的AROP算子对草图进行角分区表示,相比文献[10],检索性能提升很大;文献[10]在检索匹配上根据最近邻的相似度分数的相关性来更新图像之间的距离以提升检索性能,该方法对噪声敏感,其表现一般;基于传统的HOG[13]特征与基于边缘像素匹配的Edgel[18]方法检索准确率有限;HLR[19]方法利用草图线的关系直方图,有效降低了对象边界的噪声,准确率有了一定的提升,而本文方法结合视觉显著区域检测,减少了干扰信息,通过对初始结果进行优化排序,对检索结果有了很大的改善,相比RST-SHELO[20]方法提高了10%。
表2 几种算法的NDCG(K20)比较
Tab.2 Comparison with several algorithmson NDCG(K20)

方法 NDCG(K20)时间/s文献[9]0.6583.18文献[10]0.3915.56HOG[13]0.3676.53Edgel[18]0.2802.96HLR[19]0.5843.23RST-SHELO[20]0.6792.39本文方法0.7852.42
4.2.5 检索效率对比
在检索效率方面,从表2可以看出,本文算法与其他几种算法的平均时间成本对比。其中,文献[9]计算成本相对于文献[10]和HOG[13]并不是很高,耗时3.18 s;文献[10]采用的是多次迭代方式得到最后的排序结果,计算时间成本高,而本文采用1次迭代方式,效率上具有明显优势;Edgel[18]采用的是构造边缘像素字典进行匹配,有效提升了检索速度,但准确率有限;HLR[19]方法采用稀疏方式对草图进行描述,相比Edgel[18]方法略差;RST-SHELO[20]采用角度直方图作为描述草图和图像的特征,特征维度相对其他方法要小很多,所以时间成本最低。而本文方法在效率上相对RST-SHELO[20]略高,但在准确率上要比其高出近10%。
4.2.6 鲁棒性分析
用户在手绘输入时,手绘草图可能存在笔画冗余、聚点交叉等[21]问题,导致手绘草图质量不高,从而影响检索准确率和效率。类似笔画较轻、长度较小、转折处内聚集,首先通过计算每个笔画前后端点处的曲率,如果该点是曲率最大的点,则去除从该点起至距离其最近端终点的冗余笔画;其次采用滑动窗口(参照文献[21],大小设置为8)依次采样检查图中是否存在重复相同的点,如果有,则消除该聚点。消除不需要的笔画冗余和聚点可提高手绘草图的质量,同时减少匹配计算时间,从而降低由于手绘草图质量不高带来检索性能下降的问题。
此外,每个用户的手绘技巧是不统一的,因此,用户草图存在很大的差异,主要在于对服装图像的细节有不同的表达。为了解不同手绘风格对服装图像检索的影响,本文进一步验证了方法的鲁棒性。在创建本文实验数据时,随机线下邀请了15名手绘人员,将其分成5组,每组由3人完成。每组都给予相同的服装图像并由他们绘制服装草图,然后分别进行检索实验。图10示出一组实验结果,从总体来看,基于手绘草图的服装图像检索性能会因不同手绘风格的输入而导致检索结果有所变化。一般情况下,对服装的细节描述越好,准确率越高。
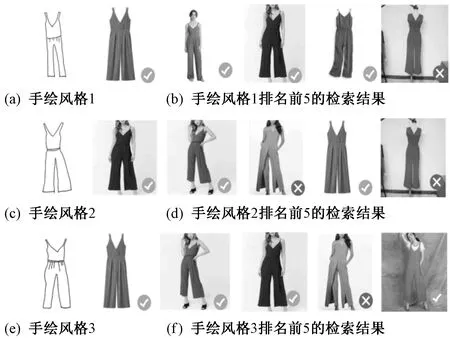
图10 手绘连体裤在不同风格下的检索结果
Fig.10 Retrieval results of connected pants in different drawn styles; (a) Drawn style 1; (b) Top 5 of search results of drawn style 1; (c) Drawn style 2; (d) Top 5 of search results of drawn style 2; (e) Drawn style 3; (f) Top 5 of search results of drawn style 3
5 结束语
本文提出了一种基于视觉显著区域和手绘草图的服装图像检索方法,即通过显著区域检测对输入的服装图像提取服装显著边缘信息,采用基于距离相关系数的重排序算法对其相似度进行排序优化,并输出检索结果。该方法能够采用手绘草图较准确地检索出相应的服装图像,相比已有方法而言,较好地解决了服装图像背景或者服装款式内部细节信息丢失而带来的检索不准确的问题,可较好地应用到服装图像检索中;但还存在由于人体姿态的遮挡或者背景色彩重叠而导致服装区域的检测结果不理想以及不同手绘风格影响检索准确率的问题,后续将着重围绕这些问题展开进一步研究。
猜你喜欢
阅读(高年级)(2022年9期)2022-10-08 01:20:16
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
疯狂英语·初中天地(2021年5期)2021-07-21 02:24:38
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
神州学人(2016年9期)2016-10-20 17:37:31
福建中学数学(2016年4期)2016-10-19 05:09:02
中学生理科应试(2016年2期)2016-05-30 10:48:04
学苑创造·A版(2016年4期)2016-04-16 17:08:02
