
基于椭圆曲线加密的多关键词可搜索加密方案
2019-07-30 00:48:02
济南大学学报(自然科学版) 2019年4期
(1.山东师范大学 信息科学与工程学院,山东 济南 250358; 2.山东师范大学 山东省分布式计算机软件新技术重点实验室,山东 济南 250014)
近年来,云计算技术不断发展形成的第三代信息技术深刻影响着人们的生产和生活方式,该技术的发展为学术界、互联网行业和全球经济的发展提供了重要机会。在这个信息大爆炸的时代,用户利用网络进行资源共享,在共享资源的过程中,用户将数据资源上传至云服务器,共享数据的安全性成为一大隐患,因此,对用户上传的数据进行隐私保护性研究具有非常重要的意义。用户将数据文件上传至云服务器之前,对隐私数据进行适当加密,有助于保护合法访问和数据隐私,但是这种加密机制给数据高效利用和搜索带来了挑战。加密数据的另一个问题是为合法数据用户提供无障碍访问。大多数情况下,数据用户只想检索特定会话的几个特定数据文件,为了确保用户的需求,最常用的方法是提供基于关键词的可搜索机制。到目前为止,为了实现对数据文件检索的高效性、安全性以及低开销,国内外许多云计算数据安全领域的专家在可搜索加密方案中对模型和算法进行了大量的研究和改进[1-3]。当用户下载数据文件时,为了迅速找到相关文件,系统就会使用关键词搜索方式来寻找数据文件。
传统的单一关键词可搜索加密方案是建立一个加密的可搜索索引,使相关内容被隐藏,当用户搜索文件时,首先提交需要查询的文件的关键词,然后系统根据该关键词形成相关的查询门限,根据查询门限来遍历文档,返回最佳结果。2000年,Song等[4]在可搜索加密方案中加入对称密钥思想,该方案利用单一关键词进行遍历文档,耗费时间长,效率低。2003年,Goh[5]在搜索方案中加入布隆过滤器对数据文档建立索引,攻击者很难获得已加密密文的具体内容;但是,由于它对关键词进行检索时需要对每个文件进行计算与判断,因此,在判断过程中存在正向误检概率,导致检索时间增加。2006年,Curtmola等[6]在可搜索加密方案建立索引过程中使用倒排索引的方式,该方案在搜索过程中能够同时实现搜索的精确性和有效性,但也存在问题,如系统无法对已经搜索过的关键词进行相关性评估。2007年,Boneh等[7]在基于可搜索加密方案的基础上加入了公钥密码系统(public key cryptosystems,PKC),在该方案中,拥有公钥的用户将加密数据文件上传至云服务器,加密是为了保护数据文件的安全性,只有拥有私钥授权的合法用户才能够访问服务器,使用数据资源。2009年,Zerr等[8]提出了基于秩序保留映射的相关性分数的训练和预采样,每当需要插入不同的分数时,该映射面临分数变换函数的重建问题。由于有助于加快查询执行速度,因此高效检索与给定查询最相关的前k个文档(top-k)成为标准的信息检索方法,即使对大型索引也是如此。信息过载是搜索方案带来的一个主要问题,而top-k方法就是通过处理仅限于高排名和最相关的文档来减少信息过载。2010年,Pang等[9]提出了一种基于向量模型的安全搜索方案,该方案中加入了访问控制技术的思想,但是,该技术的加入使用户在计算方面增加一定的开销,同时,用户在使用查询关键词进行遍历文件时,隐私信息也容易泄露。2011年,Cao等[10]提出一种云环境下对多关键词进行排序的密文排序检索方案,该方案在计算关键词与文档相似性方面使用了“内积相似性”的计算方法,该方法简化了计算过程,提高了计算效率,并使用基于安全k近邻分类(k-nearest neighbor classification,KNN)查询技术对关键词进行相关度排序。2012年,Chen等[11]使用双线性配对思想对多关键词检索方案进行改进,但是,该方案中配对的方式会导致服务器和用户计算成本较高。2014年,Sun等[12]提出了基于关键词分数的多关键词搜索方案,为了提高搜索效率,该方案将树的索引结构和多维算法相结合,使得实际搜索效率远优于线性搜索。2015年,陆海虹等[13]提出了安全云环境中基于最小哈希函数的多关键词检索方案,该方案根据数据所有者生成并外包给云服务器的加密可检索索引进行加密云检索。2017年,王恺璇等[14]在密文检索方案中加入用布隆过滤器和位置敏感哈希函数技术,提出一种针对模糊的多关键词的密文搜索方案,能够有效地实现多关键词的密文模糊搜索。
基于以上对可搜索加密方法的研究,本文中对关键词可搜索加密技术进行改进,利用椭圆曲线加密(elliptic curve cryptography,ECC)的思想和多关键词可搜索加密方案相结合的方法,将ECC算法用于可搜索的索引,对关键词进行加密、编码以及解密处理。使用词频-逆文档频率计算公式对关键词与数据文档相关性进行相关性分数计算,系统根据相关性分数可以选择出最符合用户查询的数据文件。另外,索引结构使用倒排序索引结构,用以提高数据文件关键词的遍历速度。
1 基本知识
1.1 椭圆曲线加密机制
Diffie和Hellman于1973年引入的公钥加密技术为密码学领域带来了一场动态革命,这一巨大的发展缓解了对称密钥密码的密钥分配问题,例如利用Rivest-Shamir-Adleman(RSA)公钥加密算法定义整数分解问题,将公钥密码体制和椭圆曲线思想相结合解决离散对数问题。1985年,Koblitz和Miller在椭圆曲线和密码学的基础上,提出了将二者相结合的椭圆曲线密码学模型,在此之前,专家Lenstra提出椭圆曲线大数分解模型,Goldwasser和Kilian提出素性检验的思想。椭圆曲线密码学模型的提出使得数学与密码学相结合的理念得到巨大的发展。该模型的思想是由线域上的椭圆曲线构成的群来代替公钥密码体制中有线域乘法群,从而获得加入椭圆曲线思想的公钥密码体制。椭圆曲线密码学的安全性基于陷门功能,其中假设找到关于公知基点的随机椭圆曲线元素的离散对数是不可行的,这被称为椭圆曲线离散对数问题(elliptic curve discrete logarithm problem,ECDLP),其被认为在计算上是不可行的。与其他方案相比,ECC机制具有更多动态可用性,可用于消息加密、描述、密钥交换以及数字签名。与RSA算法相比,ECC算法的优势在于密钥小,可以使用相当小的密钥来获得相同的安全标签。椭圆曲线Diffie-Hellman(elliptic curve Diffie-Hellman,ECDH)算法是广泛使用的密钥协商算法,并且在许多国际标准中有详细说明。基于消息的ECC算法显然涉及发送方执行短暂静态ECDH密钥协议,然后使用生成的共享密钥和对称加密算法对数据加密,因此,椭圆曲线集成加密方案(elliptic curve integrated encryption scheme,ECIES)是目前加密方法中是最流行的方案。ECC算法能够用于身份验证、数字签名验证、安全密钥交换和加密,在本文中仅用于关键词的加密和解密。
1.2 加性同态加密
同态加密是一种主要用来解决数学难题的计算复杂性理论的密码学技术。输入数据A,系统对数据A进行同态加密处理,将处理完毕得到的数据输出,得到A′,系统对加密的数据A′进行解密操作,得到解密数据,解密得到的数据结果与用同一方法处理未加密的原始数据得到的输出结果是一样的。同态性被广泛地分类为多种类型,广义上称为加性同态、乘法同态、线性同态、指数同态、有针对性的同态和完全同态。定义1对加法同态做了简单的介绍。
定义1加性同态加密。
如果存在有效算法⨁,E(x+y)=E(x)⨁E(y)或者x+y=D(E(x)⨁E(y))成立,则该方案是加性同态加密。
本文中将加性同态加密属性用于可搜索加密方案,对获取每个文件关键词进行编码以及加密处理,使其更加安全,数据用户根据加性同态性质能够获得真实值并选择正确的文件。
1.3 词频-逆文档频率

1.4 倒排序索引结构
倒排序索引结构主要用于位置的定位。该索引结构中保存着某一单词在一组文档中的位置信息,因此在文档检索系统中得到广泛的应用。在文档检索系统中,根据倒排序索引结构能够迅速找到包含所查询关键词的相关文档列表。倒排索引结构由“词典”和“倒排文件”2个部分组成。文档集合中出现过的所有单词所形成的集合即“词典”,“词典”索引项中不仅仅包含单词的相关信息,还包含指向“倒排列表”的指针。文档中出现的所有单词放在列表中,形成倒排列表,该表按一定的顺序存放在某个文件中,形成倒排文件。倒排索引项主要由以下几部分组成:某一个文档的信息,例如文档的编号(FiID);文档中某一个单词出现在该文档中的频率(TF);该单词在文档中的位置信息(Loc)等。倒排列表就是由这些包含相关信息的倒排项组成。在用户下载文件过程遍历索引结构时,首先查找到索引项,根据索引项中的关键词位置的信息找到相关文件中的记录,倒排文件根据关键词建立索引形成倒排表,利用倒排表进行关键词的搜索遍历。在任何复杂的布尔询问过程中,倒排序索引结构只需要访问一次,访问后即可得到肯定或否定的回答,因此,它的文档检索效率比较高。图1所示为传统的倒排索引结构。

图1 传统的倒排序索引结构
在可搜索加密过程中,用户将数据文件上传至云服务器便于其他用户共享,其他用户在下载资源的过程中容易造成数据泄露,受到非法用户攻击。为了更加安全地保护数据资源以及实现更加安全的高效密文检索方案,本文中在传统的倒排序索引结构上进行改进,利用ECC算法生成的关键词点进行加密后(加密曲线点-文件)作为倒排序索引结构“关键词-文件”的结构,用加密得到的密文逻辑指针、密态逻辑地址,替换原来索引结构中的逻辑指针和逻辑地址,形成安全的倒排序索引结构,如图2所示。
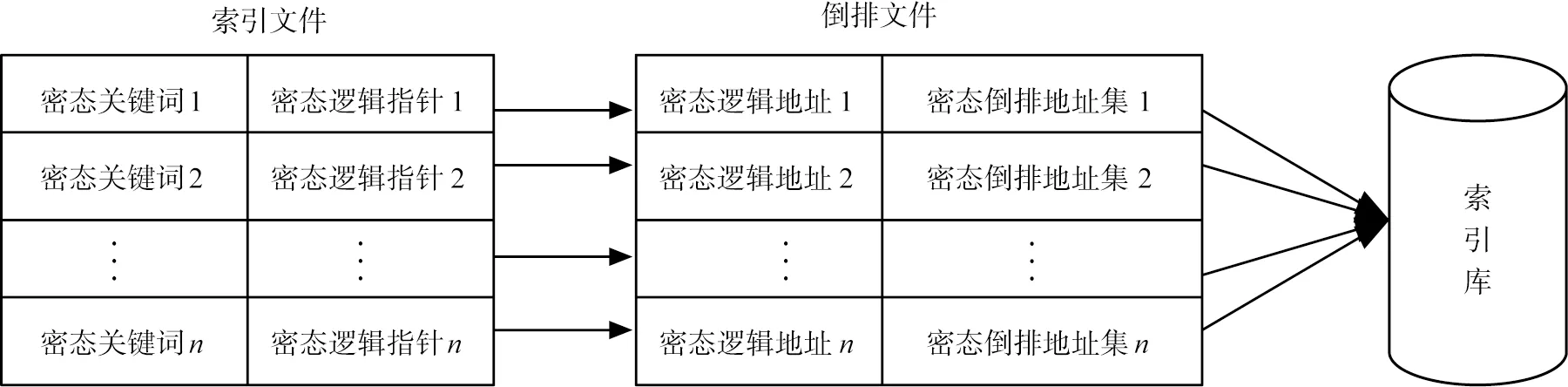
图2 安全的倒排序索引结构
2 方案设计
2.1 方案模型
系统参与者包括3个主体,即数据拥有者、数据用户和云服务器,模型图如图3所示。
1)数据拥有者。数据拥有者被视为数据集的主要贡献者和控制者,负责通过云服务器外包数据,以方便使用相应的合法数据。数据拥有者对关键词进行处理,利用椭圆曲线的思想,将关键词集合加载在曲线上形成曲线点,并对其进行加密。在可搜索加密方案中,数据拥有者使用加密关键词集合创建倒排序索引结构,并将加密的数据文件、索引结构等相关信息上传至云端服务器。
2)数据用户。数据用户接收数据拥有者共享的关键词、对称密钥和其他参数。数据用户生成对所需关键词的请求,并将查询向量发送给云服务器,在接收到返回值后对其进行解码并选择所需文件,数据用户用相应的对称密钥解密。
3)云服务器。云服务器提供数据托管服务,并存储从数据拥有者外包的加密数据和索引,为数据用户提供相应关键词陷门请求的搜索服务。本文中所提方案倾向于在云服务器端保持最大可能地处理和计算,以使其适合数据用户,并希望保持最少的计算开销。
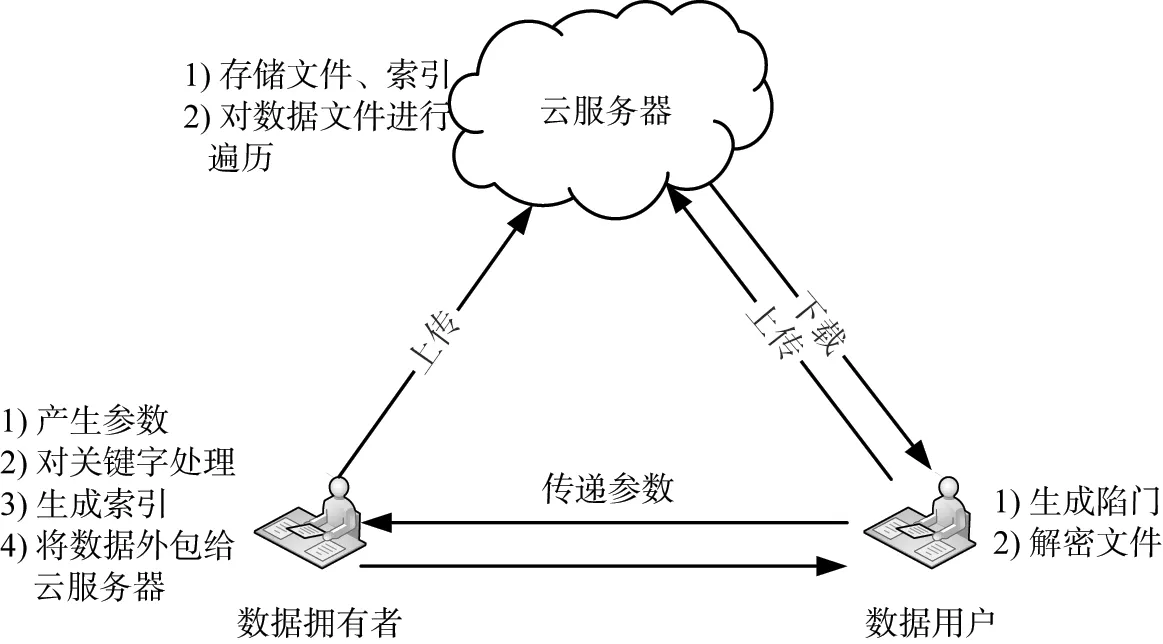
图3 方案模型
2.2 可搜索加密过程
基本的可搜索加密过程主要有4个步骤,即参数生成、索引建立、陷门生成以及检索查询。
1)参数生成。在可搜索加密过程中,数据拥有者根据选择的加密方案产生相关密钥,该密钥用于对文件、可搜索索引以及检索请求的加解密。
2)索引建立。多个数据文件形成文件集合C,数据拥有者从中提取关键词,形成关键词集合W,利用关键词集合生成可搜索索引I,选择加密算法,将索引I加密形成更加安全的索引结构I′,最后将安全索引I′与加密的数据文件集合上传至云端服务器。
3)陷门生成。数据用户在使用云端文件时,首先获得数据拥有者的授权,根据查询关键词w生成检索请求Q,并根据该检索请求生成与安全索引兼容的陷门T进行检索。
4)检索查询。数据用户将安全陷门T上传至云服务器端,云服务器根据陷门遍历,并返回给数据用户相关度最高的文档,数据用户对文档进行解密并使用。
2.3 具体工作过程
基于ECC算法的可搜索加密过程主要由7部分组成。
1)初始化阶段。
①在所提出的方案中,数据拥有者与数据用户共享关键词、对称密钥、ECC密钥和参数。ECC公钥实际上是椭圆曲线上的点。
②数据拥有者从包含n个文件的数据集C中提取关键词集合W=(w1,w2,…,wi),并且计算每个关键词的词频F和逆文档频率F′,得到相关性分数Sw,对每个数据文件设置标识符,形成文件标识符FidD=(fid1,fid2,…,fidn)。
2)对关键词进行预处理,将关键词编码在椭圆曲线上。
①曲线密钥生成。数据所有者选择ECC参数,其中E是有限域GF(P)上的椭圆曲线,V是曲线E上的点,生成随机安全参数λ,λ∈GF(P)。公钥Pλ=λV,输出私钥λ和公钥Pλ。
②关键词消息编码。编码(W,PW),将提取的关键词集合W编码到曲线E的生成点Vi上,输出PW(PW为椭圆曲线E上的关键词集合W的表示),PW=WVi,PW∈E。
③加密关键词信息点。前面已经对关键词信息编码到椭圆曲线上,为了更加安全,需要对其进行加密处理,加密过后的关键词信息点更加安全。利用公钥Pλ对PW进行加密,输入(Pλ,PW),输出PS(S1,S2),PS是加密关键词信息对,PS∈E。随机选取整数d∈[1,h-1],h是曲线上的的E顺序,其中S1=dV1,S2=Pwi+Pλ,处理完毕后,返回PS(S1,S2)的加密关键词信息对。
④解密。在对关键词进行加密的同时还需要对关键词进行解密操作。具体的解密操作为:输入密钥λ,加密关键词信息对PS(S1,S2),输出PW,其中Pwi=-λS1+S2,S2=PW+dPλ,计算完毕后,返回PW。
3)索引建立。
将加密的关键词信息对PS、加密得到的密文逻辑指针、密文逻辑地址以及密文倒排地址集建立倒排表,这样加密的项保证索引结构的加密性。系统输出倒排索引结构I,其中I=(I1,I2,…,In)。为了索引的安全性,利用公钥Pλ对倒排序索引结构进行加密操作E(Pλ,I),形成加密索引结构I′。
4)文件加密。

5)陷门生成。

6)检索文件。
由云端服务器执行检索算法。服务器根据安全的加密索引结构I′,密态关键词信息对PS、密态逻辑指针、密态逻辑地址以及密态倒排地址集找到对应的密文文档M(Dwi),根据相关性分数Sw返回合适的文档,并将其返回给数据用户。
7)文件解密。
由数据用户执行密文解密算法,即输入密钥Ky和得到的密文文件M(Dwi)进行解密,输出包含检索关键词wj的明文文档Dw。
3 分析
3.1 安全性分析
1)索引和查询机密性。该方案利用ECC算法对关键词进行处理,并对其进行加密,曲线上存在许多可能性,并且返回的加密结果值永远不会相同,该值总是出现在不同的点上,使得猜测或模式分析攻击变得不可行,保证了其安全性。方案中使用倒排序索引结构,对倒排表中的项都进行加密处理,建立安全的倒排序索引结构,保证可搜索加密方案实施过程中的安全性。
2)ECC算法的性质决定了所有加密值都是以点对的形式出现的,这种非常随机的点对使得它可以抵御统计分析攻击。
3)对关键词安全的加性进行证明。有关键词w1、w2,在椭圆曲线E上编码为点PW1、PW2,利用Pλ对关键词Pw1、Pw2加密,形成的密态关键词对PS(S1,S2),PS(S1,S2)是编码到椭圆曲线上的点。
(Pλ,PW1)=PS1(S1x,CS1y),
证明:加密时,对关键词PW1、PW2分别加密得到
(Pλ,PW2)=PS2(S2x,CS2y),
式中
S1x=d1V,CS1y=PW1+d1Pλ,
S2x=d2V,CS2y=PW2+d2Pλ,
其中d1、d2是对应生成的随机数。
有加性同态解密公式
(PS1+PS2)=PW1+PW2,
利用该公式可以证明关键词解密的正确性,证明过程如下:
PS1+PS2=(S1x,CS1y)+(S2x,CS2y)=
(d1V,PW1+d1Pλ)+(d2V,PW2+d2Pλ)=
(d1V+d2V)+(PW1+d1Pλ+PW2+d2Pλ)=
(d1+d2)V+(PW1+PW2)+(d1+d2)Pλ。
解密时,取加密后的关键词对PS1+PS2、(d1+d2)V以及私钥λ,得到(d1+d2)Vλ,其中Pλ=λV,有等式
-(d1+d2)Vλ+(PW1+PW2)+(d1+d2)Pλ=PW1+PW2,
因此,PS1+PS2=PW1+PW2。
以上分析过程证明了关键词加、解密过程的正确性。
3.2 实验分析
以下对所提出的方案进行实验。实验操作系统采用Linux操作系统(Ubuntu 14.04.1),语言采用Python 2.7.3,虚拟机工作站上使用Intel i5,2.20 GHz双核处理器和1 GB存储器。在可搜索加密过程中,计算关键词相关性分数,采用的数据集通过社交网络应用程序接口(API)收集。数据集合有数据文件500个,包含93 572个的单词,选取10个单词作为搜索索引的关键词。同时对关键词进行加密操作,最多可以包含90个文件作为样本。
1)ECC算法与RSA算法加密时间。计算性能是衡量一个密码系统的重要指标。图4所示为相同的密钥长度下的ECC算法和RSA算法的加密时间的对比。从图中可以看出,除了密钥长度为1 B时两者加密时间差不多,其他相同密钥长度时,基于ECC算法的加密时间都明显小于RSA算法的。
2)陷门生成时间。用户将数据文件上传至云服务端,通过一系列加密操作,对数据文件进行保护。

图4 椭圆曲线加密机制与公钥加密算法加密时间的对比
其他用户在使用该文件时需要对数据文件进行遍历,需要获得合法许可才能使用。用户在搜索文件时需要产生陷门,图5所示为椭圆曲线加密算法与文献[15]中的算法陷门生成时间的对比。由图可见,随着关键词数量的增加,陷门产生的时间也随之增加,ECC算法与文献[15]中的算法相比较,二者陷门产生时间相差不是很大,但是也显示出一定的优势。

图5 椭圆曲线加密算法与文献[15]中的算法陷门生成时间的对比
3)检索时间。在数据文档遍历过程中,随着关键词数量的增加,检索数据文档的时间也会随着增加。图6所示为传统的倒排序索引结构与安全的倒排序索引结构检索时间的对比。从图中可以看出,随着关键词数量的增加,两者的检索时间逐渐增加。在安全的索引结构中,需要对关键词进行提取以及解密等一系列操作;因此,密文检索的时间开销必然会增大,但是增加的幅度不是很大,对各个检索关键词都是毫秒级的。

图6 传统的倒排序索引结构与安全的倒排序索引结构检索时间的对比
4 结语
为了提高数据的遍历速度以及加强数据的安全性,本文中对关键词可搜索加密技术进行改进,将ECC的思想与多关键词可搜索加密方案相结合。在可搜索加密过程中用ECC算法对关键词进行编码、加密以及解密操作,使用词频-逆文档频率公式对关键词进行相关性分数计算,用户在遍历文档时可以根据分数获取最符合查询要求的文档,使用倒排序索引结构,提高遍历文件的速度。在Linux系统中进行实验,并与其他算法进行对比,本文中提出的方案在关键词检索以及陷门生成效率方面有所改善,因此,本文中提出的基于ECC算法的多关键字可搜索加密方案在检索文件方面具有高效性和安全性。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
太原科技大学学报(2019年3期)2019-08-05 01:18:18
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
信息安全研究(2016年4期)2016-12-01 06:06:54
专利代理(2016年1期)2016-05-17 06:14:36
信息安全研究(2016年10期)2016-02-28 20:18:19
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电子设计工程(2015年17期)2015-02-27 12:08:03
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:52
电脑迷(2012年4期)2012-04-29 06:12:13
