
基于D-S证据体的异构日志文件融合方法
2019-07-26 09:26:04胡若彤于树松侯瑞春
制造业自动化 2019年7期
胡若彤,于树松,侯瑞春,陶 冶
(1.中国海洋大学 信息科学与工程学院,青岛 266000;2.青岛科技大学,青岛 266000)
0 引言
随着大数据、云计算等技术的不断发展,应运而生的电子商务平台也在不断壮大,从起初的简单网上购物、网上消费的升级为互联网经营,据CNNIC于2017年1月份公布统计调查报告显示[1]:到2016年12月,我国网民人数达到了7.31亿,达到53.2%的互联网覆盖率,2018年11月11日的淘宝双十一交易额达到2132亿元,同比上一年增长26%。
越来越多的企业级应用软件和网站需要对客户源信息进行分析形成可供企业应用的用户标签信息,在庞大的互联网环境下产生了大量的用户行为,传统的用户画像研究数据源主要是企业通过用户的授权获得的用户数据,是相对被动的数据,而记录软件运行状况的日志文件则记录了各类角色在系统上的操作信息以及软件的运行状态信息。
日志文件作为近几年数据源关注的焦点,数据量庞大,信息多样化是日志文件的基本特点,同时网络日志在运行过程中会产生大量的系统日志、应用日志、安全日志和网络日志[2],这些日志文件记录了系统以及设备的运行状态信息、事务处理信息等系统信息,如何利用这些日志文件并将这些日志文件内的信息聚合转换成用户想看到的信息是近几年国内外学者关注的焦点。
每一个web网站以及软件都拥有的日志文件是记录着人们的一言一行的文件,对于一个web应用,后台生成的日志文件是海量的,每一种日志文件包含不同类型的数据信息,通过对日志进行分析,不但可以发现系统运行状况同时也可以发现隐藏的各种系统角色的行为信息,例如当下所流行的软件微服务架构内的每一个微服务所生成的日志文件也是各有不同,这些日志文件记录了系统整体的运行状态、客户的操作状态以及末端传感器对数据的采集状态信息而不同的日志文件类型以及不同的日志文件源构成了日志文件异构性的特点。
本文基于storm实时流处理框架对异构日志文件做整合和实时处理,在不同的服务器上配置Filebeat以及logstash对日志文件进行采集,利用日志中蕴含的用户稳定的行为信息分,抽取出用户兴趣性、行为性以及倾向性的三个维度的标签,主要方法为经过D-S证据体算法对采集的异构数据文件进行融合生成了用户画像里兴趣性、倾向性和行为性三个维度的标签值,为融合日志文件获取用户的消费习惯、消费倾向以及消费兴趣提供了解决方案。通过对技术和算法的探讨,推动了多源日志的研究和探索。
1 异构日志特点
日志文件以记录内容分类可以分为三种:访问型日志文件(主要对服务器的请求和应答信息进行记录)、应用日志文件(主要对软件的业务流程信息进行记录)、操作系统日志文件(主要对操作系统运行状态信息进行记录),事务型日志文件(主要用于保持数据的一致性,记录数据的增删改查操作,用于数据回滚操作以及防止数据冲突的发生)、消息型日志文件(主要对用户间即时通讯信息进行记录)。
日志模块作为操作系统、软件框架以及程序中的重要的组成部分,它记录着计算机系统的操作、运行状态以及安全等信息,日志模块内的日志文件的数据特点主要是数据量大、内容涵盖广泛且详细,由于操作系统、软件框架、程序甚至是设备的差异性而导致了日志的格式、类型、内容不能够完全统一,本文将异构日志文件主要研究对象。
虽然基于Syslog的日志文件通用格式被广泛运用于网络设备日志以及linux系统日志中,但是由于不同的软件框架中的日志文件系统都是由程序开发人员在系统要求下自行定义的,许多系统以及软件框架的日志文件格式、内容、类型并不统一,我们需要从这些文件中提取出有用的用户信息则需要建立异构日志收集系统。
异构日志文件采集步骤[3]:
1)异构数据获取,不同服务器、系统的日志文件的存放位置以及日志文件类型不同,需要配置不同的Filebeat数据输入文件。
2)异构数据预处理,原始的日志文件内有一些信息对于日志分析是无用的,我们需要将这些信息过滤掉,减少下游系统的处理压力。还有一部分信息比较隐私(比如用户的访问IP),不希望被他人获取,可以将其匿名化处理。
3)模式发现,对获取的数据进行数据挖掘处理,包括分类、统计、聚类等方法。
4)模式分析,对发现的模式进行进一步的挖掘,根据系统需求对模式进行分析处理,例如发现用户行为偏好,并将所发现的信息可视化,方便用户更为直观的观察数据,做出更正确的决策或者产生引导消费的功能。
本文以异构日志作为数据源,构建基于Filebeat和Logstash的异构日志收集系统,收集的日志文件将通过以Storm为框架的日志数据融合系统完成异构日志文件到用户画像的流程。
2 用户画像
随着云计算、大数据、传感器网络和高速无线传输网络等高科技快速发展和广泛的应用,用户定制服务、服务内容推送等个性化功能也应运而生,用户画像是根据用户属性、生活习惯和消费行为等信息而抽象出的一个标签化的用户模型,web应用生成的日志文件详细记录了用户在web应用内所做的操作,而用户对web应用的访问都是带有目的性的[4]。
用户画像是根据用户社会属性、生活习惯和消费行为等信息抽象出得而一个标签化的用户模型,构建在线社交用户画像模型的过程中,通常会使用较为通俗且贴近现实生活的语义标签去描述在线社交用户的属性特征、行为特征和偏好特征[5]。而标签是人为的将数据内的特征提取出来抽象数据的过程,是一种把数据形象化的方法,与属性不同,标签是对该属性状态给出的结论,可以将标签理解为业务规则的标准组成部分[6]。
对于一个用户画像来说场景的设定是必不可少的,本文设定D-S证据体的每一个识别框架作为用户画像的应用场景,如图1所示。
依据文献[7]中所述的用户画像构建步骤,本文的用户画像的构建步骤主要为:
1)基础数据采集,采用filebeat+logstash从不同的服务器内收集异构日志文件,通过storm实时流处理系统处理日志文件。
2)行为建模,基于AHP层次权重赋值法和D-S证据体融合的方法进行行为建模,抽象出用户标签,本文以用户对当前网站的兴趣性、购物倾向性以及网站操作行为性三个维度的属性构造用户标签。
3)数据可视化分析,此项步骤不在本文的讨论范围之内。
用户画像评价指标如图1所示。
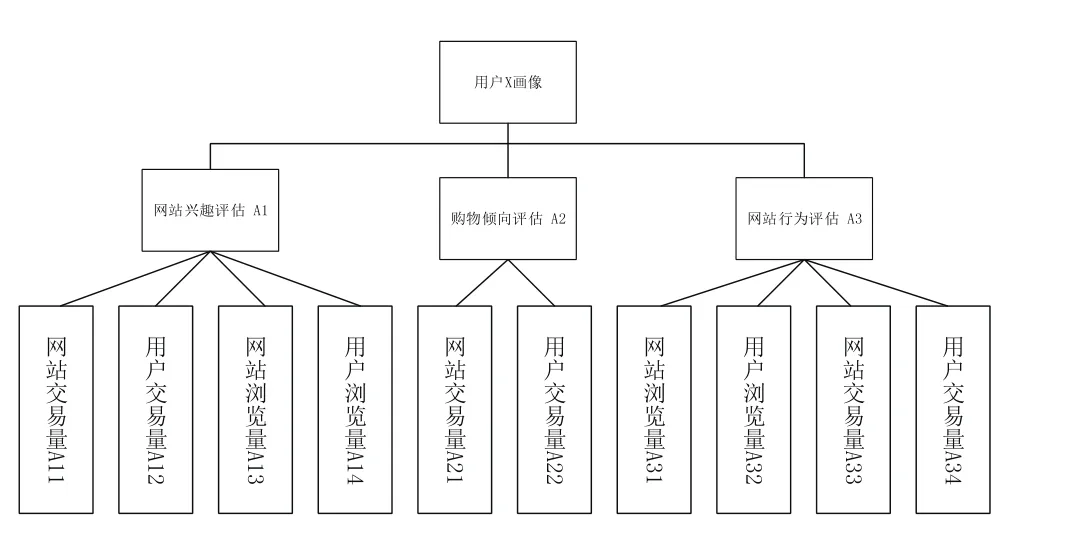
图1 用户画像评价指标体系图
其中Ai表示为识别框架。将用户的兴趣性、倾向性以及行为性设计成三个维度的评价指标,三个维度的语义表示为:兴趣性是指用户A对网站a的感兴趣程度;倾向性是指用户A可能在商品网站a购物的倾向程度;行为性是指用户A可能在网站a上做与网站相关的行为程度。
A1表示用户X对子网站的兴趣评估标准,A2表示用户X在子网站(购物类型网站)的购物倾向评估标准,A3表示用户X在子网站的行为评估标准。
第三列的子模块作为每一个评价标准的所需的元证据,本文设定为当前评估标准的能力值。其中元证据主要包括:1)网站交易量:当前交易网站的全部交易成交量;2)用户交易量:用户在当前交易网站内的成交量;3)网站浏览量:当前网站全部的浏览量;4)用户浏览量:用户在当前网站内的浏览量。

图2 异构日志文件采集流程图
3 异构日志处理系统整体设计
3.1 异构日志收集系统的设计
Filebeat是一个轻量级日志文件采集工具,属于本地文件的日志数据采集器,用于监听和采集日志,日志采集若直接通过logstash获取文件对于服务器太过沉重且资源消耗量大,加入Filebeat的设计可以轻松获得日志文件推送到中心logstash。
在所需获取日志文件的服务器上安装Filebeat,依次配置数据源的文件内容,独立出一台服务器搭建logstash,本文取一台服务器做数据源,此台服务器的ip地址为:192.168.153.1,搭建logstash的服务器的ip地址为:192.168.153.255。
配置Filebeat,由于服务器的差异,所有在每台服务器安装和配置Filebeat时需要特别修改一下配置文件,配置日志文件获取方式以及日志文件路径地址。
更改服务器本地Filebeat的配置文件 fi lebeat.yml下日志文件目录路径:

3.2 日志文件采集系统流程图
本文中的异构日志文件类型为:交易日志、消息日志和访问日志,从这三类日志文件内提取出网站交易数据,用户浏览数据以及网站访问量数据进行数据融合,数据分析统计。
经过上述讨论,异构日志文件采集系统流程设计如图2所示。
3.3 Storm异构日志融合系统的设计
Strom是区别于Hadoop的开源实时计算工具,它的框架处理模式与Hadoop非常相似,但随着数据规模爆炸式的增长以及对实时数据处理功能的需求水涨船高,适用于海量数据处理的Hadoop对于实时数据的处理略显吃力,然而针对实时数据处理Storm框架则可以满足此类需求,其框架中提供的一系列基本概念是使其能够进行海量日志实时计算的基础,而支撑其平稳运行的是内部处理模型。
Storm与Hadoop最显著的不同在于Hadoop是需要结束的,而Storm则不需要结束,在下一个新数据到来的时候作为一个新的开始,如同水流一样由高到底源源不断。
Storm的主体数据结构为Tuple(元组),也是Storm被处理的流数据(stream)的基础组成单位,是消息传递的基本单元;storm的数据接受单元(spout)以及数据处理单元(bolt)是由用户根据业务的复杂程度自行决定的。
Spout主要负责向一个指定的频道发送数据,而每一个bolt需要在内部逻辑结构中对这个频道订阅数据。
本文中Storm实时计算拓扑流程设计如图3所示。
DateCollectSpout是从redis中获取日志文件,并以tuple的形式发送给FilterBolt的数据源,FileterBolt是日志过滤模块,由于日志文件内的记录分为多种,我们需要将用户购物记录、网站整体浏览记录、网站交易记录获取并下分到各个Bolt,此处的Bolt涉及两种判断:
判断log的完整程度,包括用户名/网站地址、浏览量/交易量,当上述类别缺少则将其过滤掉。
判断产品状态值是否为空,根据海尔COSMOPlat的日志定义,日志记录产品为空无法交易的情况,则将其过滤掉。
过滤出的t u p l e将通过批处理分别发送给WebPageViewInfoBol、DealInfoBolt、UserInterviewInfoBolt、UserPdInterViewBolt执行页面信息统计、交易信息统计、用户浏览信息统计以及用户产品页面浏览信息统计的操作,生成的统计信息发送到WeightingBolt赋予内外信息的权重并生成决策矩阵,DSEvidenceBolt则将决策矩阵作为识别框架融合生成DS证据体。
本文的日志主要来源于海尔COSMOPlat平台,其中有n个用户和m个子网站,在子网站中有s个交易类型的网站。
4 D-S证据体伪代码设计实现
D-S证据体是一种不确定性推理方法,指一项事物由与之相关的外项进行评定所得到的关于此项事物的不确定程度,1967年Shafer[8]该理论进行了扩充引入了信任函数表达概率的上、下界,形成了基于“证据”和“组合”来处理不确定性推理问题的数学方法,在此基础上形成了“证据理论”。
4.1 识别框架的设定
识别框架为用户画像评价标准体系:根据图1所示,其中倾向性、兴趣性、行为性设置为一级证据层,其他下分为二级证据层。
4.2 AHP权重的设置
层次分析法又称AHP构权法(Analytic hierarchy process)是将复杂评价对象排列成为一个有序的递阶层次结构的整体,再在各个评价项目之间进行两两的比较、判断、计算各个评价项目相对重要性系数的方法,由Satty教授在20世纪70年代初期提出的一种定性和定量相结合的多准则决策方法,首先需要通过专家咨询评定重要性比值,再经过公式进行相应的计算,本文用层次分析法构造权重以及1~9标度法,对元证据赋予相关权重[9]。
设置专家组对一级和二级证据层评分,由于元证据只有四种,所以我们需要给一级证据赋予相应的权重以区分相同元证据在不同的语境下不同的重要性。

表1 一级证据层决策判断矩阵和权重
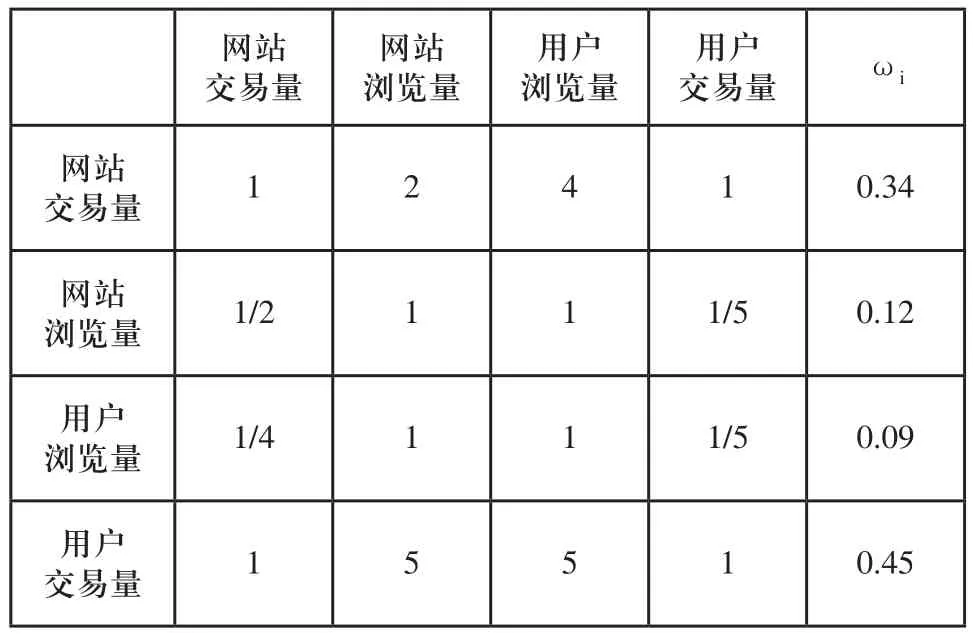
表2 二级证据决策判断矩阵和权重
4.3 基础概率函数的设置
在D-S证据体中,需要设定BPA(Basic Probability Assignment)基本概率函数,本文中的元证据的基本概率函数是以支持度的形式出现的,支持度代表的是个体占总体的比列,例如整个web网站的总浏览量为S,子网站a的浏览量为Sa,则子网站a的支持度为Sa/S;用户A对子网站a的浏览量为S(A),对子网站a的支持度为S(A)/Sa。
以βij表示支持度,i表示第i个一级证据评价指标,j表示第j个二级证据评价指标(下同)。则用户A对子网站a的支持βij=S(A)/Sa;而子网站a的全局支持度为βi=Sa/S。
设识别框架θi=Aij,其中θi的数据结构是矩阵,用户画像指定了特定的用户,所以在一级证据处设K=(1,2,…,k,…,m)表示子网站编号,一级证据的语义设定为用户X对子网站K的属性,二级证据处设置q为二级证据的个数。系统获取了n个用户和m个网站的数据,则以n×m的矩阵形式展示出所采集的数据,每一行代表一个用户的数据向量,每一列代表一个网站的数据向量。
根据每个元证据的权重指数及其支持率构成D-S证据理论的基本概率分配函数(即mass函数):
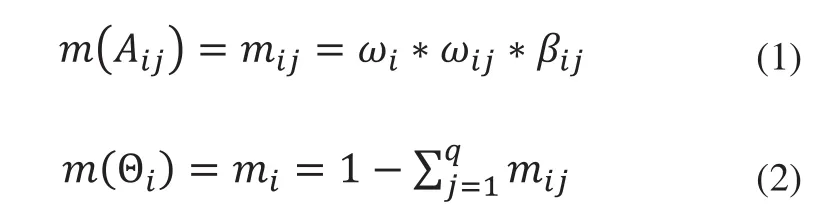
式中m(Aij)表示Aij的支持度,而m(Θi)表示Aij所表示的元证据不确定性的支持度。
4.4 信任函数
D-S证据理论中信任函数Bel(θ)是指θ的可信程度[10],即本文定义的对一级证据评价标准的支持程度。而似然函数PL(θ)则是对θ的可能性的不怀疑程度,本文将其定义为一级证据不确定性的支持度。
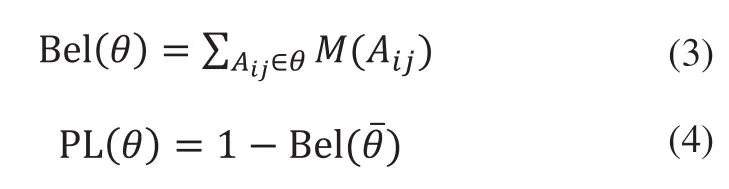
信任函数与似然函数构成对一级证据体的支持度区间。
4.5 D-S证据体算法伪代码
D-S证据体代码核心为将两个元证据向量内的核心证据值进行融合形成统一指标的过程。

5 实验与结果
5.1 基础数据采集
本文的log数据来自海尔COSMOPlat平台,以其中的访问日志和交易日志为例,所采集的日志文件格式如下所示:
1)访问日志:
Time:[2018 十一月 22 16:03:29(125985 ms)] Type:(INFO):com.nsneo.pub.moduleAC.MoudleAccessControlManImp:用户[admin]登录系统,初始化第一个访问界面[index.html]
Time:[2018 十二月 21 11:31:13 (460042 ms)] Type:(INFO):com.nsneo.pub.moduleAC.ModuleAccessControlManImp:用户访问系统,切换系统模块,ModuleId[datasb2b. fi rstPage.yhhinfo]
Time:[2018 十一月 22 16:03:29(125940 ms)]Type:(INFO):addons.haier.pub.HaierUserAccessRecord SimpleFactory : 海尔登记用户访问系统...
T i m e:[2 0 1 8 十二月 2 1 1 1:3 4:3 6(662495 ms)] Type:(INFO):addons.haier.pub.SysUserManFactoryforHaier:加密用户信息字段,字段名为[CosmoStoreUser.loginPwd],字段值为[haier1234]
[2018 十二月 21 11:34:36 (662495 ms)] INFO:addons.haier.pub.SysUserManFactoryforHaier:加密用户信息字段,字段名为[CosmoStoreUser.loginName],字段值为[胡懒懒]
2)交易日志:
[2018 九月 15 15:48:34 (527272 ms)] INFO :addons.haier.pub.HaierDataRule:产品[257],产品网站[],[大蒜]商户[吉林农嫂]用户[USERNAME]
[2018 九月 15 15:45:49 (361971 ms)] INFO:addons.haier.pub.HaierDataRule:产品[910],产品网站[],[]状态为空,不能交易
5.2 行为建模
基于D-S证据体识别框架的三个维度的属性,建立当前用户的语境,根据识别框架内的给出的支持度区间建立用户画像的标签[11]户X的用户画像如表3所示。
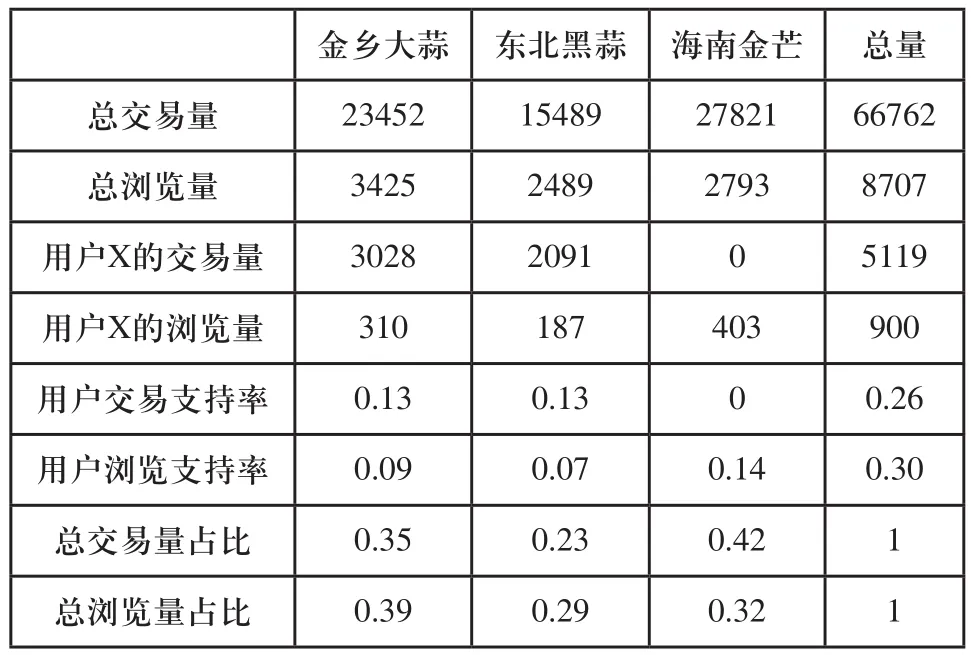
表3 用户X的基本数据
根据式(1)计算其mass函数,得到的mij如表4~表6所示。

表4 一级证据体mij的mass函数

表5 一级证据体m2j的mass函数

表6 一级证据体m3j的mass函数
经过D-S证据体融合后,如表7所示。
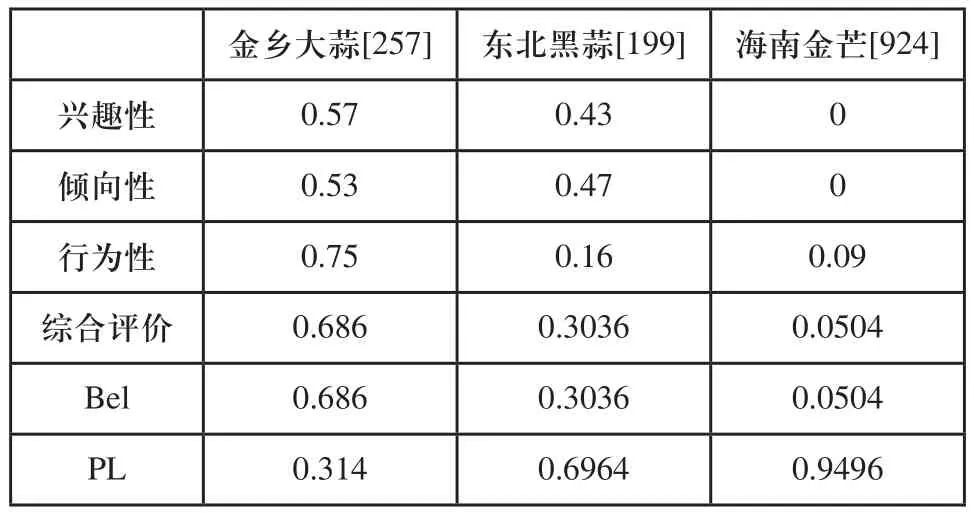
表7 用户X的D-S证据体融合数据
根据以上的基础数据,用户X的用户画像为:目标产品为金乡大蒜,网站可以根据此项行为性的标签值推荐相同产品的不同商户给用户,或者将用户作为大蒜商家的目标用户推荐给商家,对于海南金芒用户的兴趣性和倾向性都为0,却存在轻微的行为性在海南金芒这个产品里,所以我们可以将海南金芒作为用户的潜在产品购买倾向里。
5.3 数据可视化
系统根据上述数据描述利用可视化工具在前端直观的展示出用户X的用户画像,使得营销和运维人员更加直观的挖掘客户行为性的指向,具体的可视化工具并不在本文的讨论范围之内。
6 结束语
随着大数据等科学技术的不断向前发展,各个软件业务的拓展不仅仅限于传统的业务模式,它们需要通过新兴技术将自己的业务模式改善到更加广阔的领域,获得更好的用户粘度以及用户特性。
本文以异构数据文件作为出发点,通过提取异构日志文件内具有特殊含义的字句,提取分析融合生成特定的用户画像。
使用storm实时流处理大数据框架以及Filebeat、logstash和redis等技术,设计了异构日志处理系统,storm与hadoop最大的差异是其能够完成实时处理的任务,在当时当刻给出大数据处理结果,满足用户画像的实时性,采用redis消息队列存储模式可以使得数据存储转换更加便捷。
传统的用户画像数据源为用户授权的数据或者企业采集的用户数据,来源复杂且不易获得,企业因此对数据带有很强的被动性,日志文件是系统本身记录运行状态的文件,是属于企业的,本文提出的数据源为日志文件,使得企业在获取数据上更占主动性。
用户画像的属性值划分往往是复杂的,本文将属性值划分为三个维度建立了评价指标,应用AHP权重法和D-S证据体将获得的数据融合成三个维度的属性值,在此理论基础上可以延伸到未来更加广泛的评价标准维度计算,更加有利于企业通过应用以及网站系统获得详细精确的用户信息,不再被动的获得用户信息,推动企业走向更完整规范的道路。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:39:34
小学教学研究(2022年5期)2022-04-28 21:29:36
华人时刊(2021年13期)2021-11-27 09:19:02
新世纪智能(高一语文)(2020年9期)2021-01-04 00:42:42
非公有制企业党建(2020年10期)2020-10-27 06:30:14
心声歌刊(2020年4期)2020-09-07 06:37:14
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
汽车零部件(2014年10期)2014-11-11 12:25:04
