
基于混合自编码器的协同过滤推荐算法优化①
2019-07-26 03:16付立军刘俊明
计算机系统应用 2019年5期
张 杰,付立军,刘俊明
(中国科学院大学,北京 100049)
(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引言
推荐系统构建已经成为各类信息服务平台、电商平台等搭建过程中重要的技术要点,其核心思想是充分发挥信息过滤的作用,帮助用户快速获取到自己感兴趣的信息.以网络信息的获取为例,面对海量的、类别多样、条目复杂的网络信息,用户想要在短时间内辨别、获取自己感兴趣的信息,过滤垃圾无用的信息是非常困难的.在实际应用中,传统的推荐系统应用场景是基于用户个性化喜好特征和历史行为数据,向用户推荐一系列其可能感兴趣的信息或者预测用户对某些信息的喜好程度[1-3].实现过程中,推荐系统的数据来源主要由该用户的历史偏好数据和用户-项目的属性信息组成,推荐系统主要分为三种类别,分别是基于内容属性和协同过滤的推荐系统,以及将前两者结合的混合推荐系统[4,5].其中,协同过滤推荐系统由于具备提供新异性推荐的优势,可以提升用户体验而成为目前应用最为广泛的推荐系统.但实际应用场景下,数据稀疏性和冷启动问题依然存在,降低了推荐效率.
近年来,深度学习作为人工智能的研究热潮,在图像处理、自然语言处理、语音识别等领域取得突破性的进展,也为推荐系统的发展带来新的契机.在协同过滤算法实施过程中,借助深度学习的深层非线性结构构建用户和项目的潜在特征向量,从用户和项目相关的海量数据中学习到深层次表示信息,从而挖掘数据背后的隐含特征,提高推荐系统的效率[6-9].
本文提出一种结合自编码器和深度神经网络的混合协同过滤推荐模型,基于用户-项目的交互矩阵提取隐式特征向量,利用深度学习的深层特征表示能力来克服传统协同过滤算法中矩阵分解的低效性和稀疏性问题,以此来提高推荐算法的效率.本算法模型经在MovieLens数据集中反复试验,结果证明本算法比传统协同过滤算法的推荐效果更好.
2 相关技术
2.1 推荐系统技术现有研究
协同过滤推荐算法的思想是通过数据比对找到与目标用户具有相似喜好的邻居用户,然后将邻居用户的偏好项目推荐给目标用户;从实现原理的角度,将协同过滤算法定义为基于用户或项目之间的相似度和抽取隐式特征向量的协同过滤推荐算法[10].在实际应用中,用户-项目之间的交互行为数据存在较高的稀疏特征,以及对于新用户或新项目之类的冷启动问题等,都是推荐算法亟待解决的问题.
目前国内外学者已经针对这些问题进行一系列的研究.针对传统的矩阵分解算法,文献[11]提出了基于奇异值(SVD)分解的协同过滤算法,有效解决了数据稀疏问题;文献[12]利用包含用户喜好的隐性特征向量矩阵,提出非对称奇异值分解(ASVD)模型,提高了推荐算法的准确度;文献[13]通过评分矩阵计算得到显式信任和隐式信任,融入到SVD++算法中,提高对冷启动用户的预测表现;文献[14]提出基于LDA 主题提取,利用物品-主题概率分布矩阵和项目的辅助信息来构建用户兴趣模型,有效的解决了数据稀疏性和冷启动问题.文献[15]详细介绍了深度学习与推荐系统相结合的研究现状,提出了优化方向;文献[16]提出了结合协同过滤和基于内容推荐的混合模型,引入词向量模型,将用户和论文映射到词向量空间,以此来提高计算相似度的准确性;文献[17]提出了神经网络协同过滤框架(NCF),该框架取代传统特征向量内积的方式,训练用户-项目交互兴趣模型,充分挖掘评分矩阵的非线性深层特征表示,提高了推荐效率的准确度.
自编码器作为深度学习的分支,主要用于数据降维或特征学习,研究人员将其特征学习的优势结合到推荐系统中,已取得一定的成果.文献[18]通过传统的自编码器学习隐式特征向量来实现协同过滤算法,提高推荐效率;文献[19]在前者的基础上,引入栈式降噪自编码器来提高隐式特征向量的质量,并且在学习过程中加入用户和项目的辅助信息来提高推荐质量.文献[20]提出将降噪自编码与最近邻推荐算法结合,将模型提取到的抽象特征应用到最近邻评分来解决数据稀疏性问题.上述研究均忽略了用户-项目的交互兴趣行为,评分数据隐藏了用户和项目之间的交互关系,而此模型只能通过最优比较,在基于项目的自编码器网络和基于用户的自编码器网络中二选其一,进而实现评分预测,并且未充分挖掘用户-项目之间的深层特征表示.
上述研究内容中利用深度学习的自适应学习能力来优化构建隐式特征向量的过程,一定程度上解决数据稀疏的问题,提高推荐算法的准确度,为本文提供了思路上的建议.基于已有研究,本文主要结合栈式降噪自编码器和深度神经网络构建混合推荐模型,希望通过充分利用用户-项目的历史交互数据,优化隐式特征向量的质量,达到更好的推荐效果.
2.2 降噪自编码器
降噪自编码器(DAE)是一种特殊的神经网络,属于无监督学习的一种,本质是通过接收损坏的数据作为输入,并训练原始未被损坏的数据作为输出的自编码器.相比较传统的自编码器,引入一个损坏数据的过程,从损坏的数据的基础上学习到的隐特征变量更具有鲁棒性,并且在学习过程中,每个失真的样本是不同的,增加了训练集的大小,极大的缓和过拟合现象的发生.

图1 降噪自编码器的训练过程
降噪自编码器网络的训练过程如下:

算法.降噪自编码器训练1)将训练集中采样一个数据样本X;˜x 2)在数据样本X的基础上,随机添加高斯噪声得到受损数据 ;˜x y= f(˜x;θ)3)将受损训练数据 与原始数据X 作为训练样本来接入到隐藏层y,此部分为编码部分;z=g(y;δ)4)隐藏层y 连接到输出层Z,此部分为解码部分;5)根据输出层z 和原始数据X 来估计重构误差,采用随机梯度下降的方式来实现近似最小化.
现有的降噪自编码器,一般采用高斯噪声和均方误差作为重构误差,其中激活函数采用Sigmoid 函数,目标函数如下:
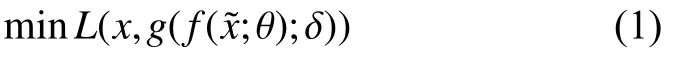
式(1)中,L为一个损失函数,θ和δ代表权重参数.其中L常采用均方误差函数,最终得到的y层数据就是对输入数据的压缩降维,即输入数据的隐式特征变量.
3 混合神经网络模型
3.1 问题定义
在显式反馈的推荐场景下,设用户数为m个,项目数为n个,存在一个用户-项目的交互评分矩阵Rm*n,则用户集为U={U1,U2,…,Um},项目集I={I1,I2,…,In},Ru,i代表用户u对项目i的评分数.当Ru,i=0时,代表用户u未对项目i评分,并不是代表用户u不喜欢项目i,因为可能用户u没有观察到项目i.对任意一个用户u∈U={1,…,m},根据其对项目的评分序列构成一个向量r(u)=(Ru1,Ru2,…,Run)∈ℝn,对任意一个项目i∈I={1,…,n},根据用户对项目i的评分序列构成一个向量r(i)=(R1i,R2i,…,Rni)∈ℝm.
基于模型思想的协同过滤算法的核心在于抽取用户-项目的隐特征向量,并基于隐特征向量来实现用户u对未评分项目i的预测评分.设定向量P(u)和Q(i)分别为用户u和项目i的隐特征向量,并且隐特征向量的维度为k.
3.2 构建混合深度网络模型
本文提出的混合网络模型总体分为两个部分,第1 部分为通过深度栈式降噪自编码器学习得到用户和项目的隐式特征向量,第2 部分为基于用户-项目的隐式特征向量,构建深度神经网络来学习用户和项目之间的交互模型,并实现预测评分,模型结构如图2所示.下面分别介绍混合神经网络的两个组成部分.

图2 混合深度神经网络结构
(1)抽取隐式特征向量
本部分的任务是抽取出用户和项目的隐式特征矩阵P,Q∈ℝk,故细分为两个学习过程U-SDAE 和ISDAE.以基于项目的栈式降噪自编码器网络模型(ISDAE)的学习过程为例,结构为栈式降噪自编码器,输入数据为项目的评分向量集合R=[r(1),r(2),…,r(n)],首先在输入数据中随机的进行损坏得到受损数据R˜,通过编码过程转换为低维的隐式特征向量矩阵Q,再重构出于原始数据R,使得重构误差的尽可能小,具体的编码和解码过程如下:
对于每一层隐藏层l∈{1,···,-1},隐藏层表示为hl:

对于输出层L的计算公式为:

目标损失函数为:

式(2)和式(3)中的g(·)和f(·)分别是编码和解码函数,W是权重矩阵,b是偏置值.网络模型中的前L/2 层理解成编码部分,后L/2 层理解成解码层.学习过程的目标函数为式(4),即最小化预测值和原始值的平方损失.采用反向传播算法来优化学习每一层的权重矩阵Wl和偏置值bl,本模型对比多种优化算法,选定随机梯度下降法来优化模型的学习过程.
I-SDAE的学习结果为获得最中间层的数据作为学习到的项目隐式特征矩阵,即L/2 层的特征数据.同样的方式,在U-SDAE网络中学习到用户的隐式特征矩阵P.由此,获得项目的隐特征矩阵P∈ℝk和用户的隐特征矩阵Q∈ℝk.
(2)学习用户-项目交互网络
从过程(1)中得到的用户和项目的隐特征矩阵P、Q作为深度神经网络的Embedding Layer,共同接入到深度神经网络来学习用户-项目之间的交互函数.在训练过程中,采用的目标评分数据为用户对项目已经评分的数据,过滤掉未被评分的数据.此深度神经网络的每一层可以理解成学习用户-项目的深层次交互关系,并且层的维度逐渐减小,直到隐藏层X,最后得出一个预测评分值,然后训练过程中的目标函数是尽量减少预测值与目标值的误差,那么深度神经网络可以表示为:

∈ℝm∗k∈ℝn∗k
式(5)中的P和Q为用户和项目的潜在特征向量矩阵,θf是交互函数f(·)的模型参数,并且该函数代表的是多层的神经网络,前一层隐藏层的结果作为后一层隐藏层的输入.学习过程中的损失函数即:
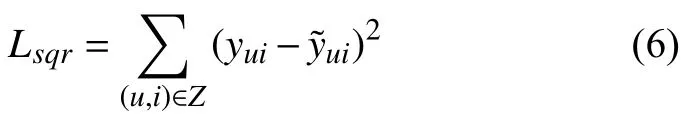
学习过程中取得Lsqr的最小值,注意式(6)中的Z代表用户u和项目i存在评分数据,即值不为0.采取的逻辑是仅用存在的评分来训练,部分研究人员在训练类似交互函数时采用用平均分来填充缺失值,这种方式的弊端是每个用户的评分准则不同,故只采用存在的评分数据作为训练数据.
在深度交互神经网络的学习过程中采用随机梯度下降法来优化.最终在预测分值时通过该用户和项目的隐特征向量,经深度交互网络模型来实现预测分值,即:
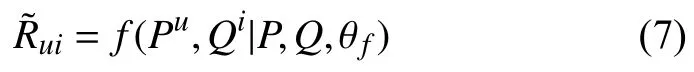
根据式(7)所示,Pu代表用户u的隐式特征向量,而Qi代表项目i的隐式特征向量,再经由用户-项目的深度神经交互网络模型得到最终的预测评分.
4 实验分析
4.1 数据集及评价指标
本实验采用的数据集为经典的电影评分数据集MoviesLen 进行实验,包括MovieLens-100K 和MovieLens-1M 两个数据集.其中,MovieLens-100K 数据集中包含943个用户和1682个电影,超过十万条评分记录,分值为1~5的整数;MovieLens-1M 数据集中包含6040个用户和3706个电影,以及超过一百万条评分数据.对于二者的数据稀疏度都非常高,分别是3.49%和2.57%.除此之外,在选取用户和项目的数据时,过滤掉少于20 次交互行为的用户或项目数据.
本实验选取数据集中的90%作为训练集,10%作为测试集,模型参数使用5 折交叉平均值作为最终结果,使用均方根误差RMSE作为实验的评价指标[21].
定义RMSE公式为:

式(8)中,Rij为用户i对项目j的评分,Rij为算法模型的预测评分,T代表测试集的数目大小.
4.2 实验中的参数介绍
在栈式降噪自编码器部分,加入噪声率为0.3,设定激活函数采用Sigmoid 函数,隐式特征向量的维度k∈{20,40,80,200,400,500},U-SDAE模块的网络层神经元个数依次为943-700-400-700-943,学习率为0.004,dropout为0.15;I-SDAE模块的各网络层神经元个数依次为1682-900-400-900-1682,dropout为0.15,学习率为0.004;深度交互神经网络部分,学习率为0.001,激活函数采用Sigmoid 函数,dropout为0.15,将用户和项目的隐特征向量进行拼接作为交互神经网络的嵌入层,网络层神经元个数依次为800-400-32.
4.3 实验结果对比分析
本论文与以下传统推荐算法进行了对比验证.
(1)基于平均分.此推荐算法通过用户或者项目的平均得分来实现预测评分,即ItemAvg和UserAvg.
(2)SVD 算法,实验过程首先对评分矩阵根据用户的平均评分来填充缺失数据,设定分解后的矩阵维度k需满足前k个奇异值的平方和占总奇异值的平方和的90%,得到的降维矩阵再根据皮尔森相似系数计算用户之间的相似度,设近邻用户数为5,最后根据相似度作为权重来预测最后的评分.
(3)PMF 算法,此推荐算法引入概率统计角度来实现矩阵分解,设定观测噪声符合高斯分布并且用户或项目的隐特征向量的值也符合高斯分布,得到特征矩阵后,再实现预测评分.实现过程中通过随机梯度下降(SGD)来训练函数,并利用指数衰减法(exponential_decay)来设定学习率,以此来优化模型表现.
(4)I-AutoRec 算法,此算法模型为文献[18]提出的基于自编码器实现协同过滤,并选取表现较好的基于项目的单层自编码器网络(I-AutoRec),隐藏层维度设为500,未被观察到的评分数据默认为3,激活函数采用Sigmoid 函数,正则系数取0.001,神经元个数依次为943-500-943,损失函数为,只考虑已存在的评分,最小化原始数据与重建数据之间的误差.

表1 各推荐算法在不同数据集中的效率比较
表1中所示的结果为传统协同过滤推荐算法和本文提出的混合神经网络算法的RMSE的平均值,通过对比得知,本文提出的混合神经网络模型在MovieLens上的表现均好于传统的协同过滤算法,并且在稀疏度较强的Ml-1M 数据集上的效率也优于传统算法,一定程度上解决数据稀疏性的问题.

图3 隐式特征变量的维度k 对推荐效率的影响
如图3所示,隐式特征向量维度k的不同对本算法效率的影响程度较明显.根据对比在实验中设定的不同k值,明显看出随着k值的递增,RMSE的平均值在不断减小,直到k=400时,RMSE的值趋于稳定,并且优于当k为500 维的效率,这是因为维度越高的隐特征变量所包含数据越充分,但随之带来的问题的网络的模型更加复杂,参数训练更加困难,综上,在进行对比实验时设定隐式特征向量的维度k为400.
5 结论与展望
本文针对传统的基于隐式特征变量的协同过滤推荐算法,提出一种结合栈式降噪自编码器和深度神经网络的混合神经网络模型,学习得到强鲁棒性的用户-项目的隐特征向量和交互兴趣模型,实验结果证明本算法一定程度上解决了数据稀疏性问题,较传统的协同过滤算法,提高了推荐效率.但算法的扩展性和模型训练中的参数优化过程会直接影响推荐系统的质量,这对模型的训练过程提出了较高的要求.当用户和项目的数据量逐渐增长,如何优化推荐算法的运算效率,达到实时推荐将是下一阶段的研究重点.
猜你喜欢
传感器世界(2022年4期)2022-08-05
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
数学学习与研究(2018年15期)2018-11-12
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
