
基于交叉验证网格寻优支持向量机的产品销售预测①
2019-07-26 03:15张文雅范雨强崔晓钰
计算机系统应用 2019年5期
张文雅,范雨强,韩 华,张 斌,崔晓钰
1(上海理工大学 能源与动力工程学院,上海 200093)
2(上海交通大学 机械与动力工程学院,上海 200240)
21世纪的飞速发展,人们生活水平得到了极大提高,越来越多的家庭购买汽车作为代步工具,我国汽车市场已进入品牌营销时代,市场竞争也从传统的产品和价格竞争转移到品牌和渠道的竞争[1].汽车制造企业若能在生产、制造、销售等环节实现定量化预测,为其决策提供必要依据,则可在满足客户个性化需求的同时,使其在日益激烈的市场竞争中占得先机.
前人已经进行了一些销售预测的尝试.2011年,Yu Y 等[2]提出了一种最大程度学习机制对人工神经网络进行了优化,并通过对某品牌销量数据的学习训练,在给定时间内精准的预测了服装产品的月销量.张闯等[3]采用后向传播(Back Propagation,BP)神经网络预测方法,通过新浪微博数据预测电影票房,模型拟合效果较佳,但因存在数据不完全和干扰数据的情况,使预测精度不够.严洪森等[4,5]分别采用了混沌ν-支持向量机和扩展的径向基函数核支持向量机建立了产品销售预测模型,在预测精度上具有一定的优势,但也增加了模型的复杂度、需要优化的参数个数和最优参数组合的获取难度,使模型难以推广.本文拟采用支持向量机这种先进的机器学习方法,在尽可能不增加参数及少量增加模型复杂度的情况下,对模型进行优化,以期实现较为精准的汽车产品的销售预测.
支持向量机(Support Vector Machine,SVM)是近几年来发展起来的基于统计学习的机器学习方法[6].它以统计学习理论为基础,直接从小样本出发,放弃了传统的经验风险最小化(Empirical Risk Minimization,ERM)准则,而采用结构风险最小化(Structural Risk Minimization,SRM)准则,在最小化样本误差的同时,考虑模型的结构因素,从根本上提高了泛化能力.支持向量机解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,它既能够有限的训练样本得到小的误差,又能够保证对独立的测试集仍保持小的误差,而且支持向量机算法是一个凸优化问题.因此,局部最优解一定是全局最优解.在支持向量机的具体应用中,惩罚系数C和核函数参数g的选取对预测性能具有关键性的影响[7].目前,支持向量机的参数选择方法主要有:网格搜索法、遗传算法和混沌优化等,其思想主要是在初始化范围内进行寻优以获得模型最佳效果时的参数[8].王宁等[9]在训练过程中采用网格搜索法对支持向量机回归模型参数进行优化,提出基于支持向量机回归组合模型的中长期降温负荷预测方法,成功的把预测值与真实值的误差控制在5%以下,且该模型得到了实际应用.Gao 和Hou[10]为了提高SVM 预测的精度和减少计算负荷,采用了网格搜索(GS)算法优化SVM 参数,进而预测田纳西伊斯曼(TE)过程的状态,发现GS 方法比产生类似分类精度的遗传算法(GA)和粒子群优化算法(PSO)效率更高.Gencoglu MT 等[11]将混沌理论与SVM 结合,通过重构相空间的饱和嵌入维数确定SVM 最佳输入变量的选取,以混沌序列的最大Lyapunov 指数确定SVM 预测模型的最大有效预测步数,但所处理的时间序列必须具有混沌性.本文所处理的是小样本汽车销售数据,时间序列的混沌性并不显著,采用基本的SVM 并采用GS 算法进行参数优化进行销售预测是可行的.
为了增加模型的鲁棒性,有效地避免过学习以及欠学习状态的发生,使得到的结果更加可靠,所以在优化过程中结合了K-fold 交叉验证[12],降低了支持向量机参数选择随机所带来的误差,提高了模型的推广能力.本文提出了基于交叉验证网格寻优的支持向量机方法,分别建立了采用每3个月、6个月、9个月、12个月、18个月和24个月的汽车销售额数据预测下一个月销售额的预测模型,对预测结果进行详细的比较分析,以期找到最佳的预测模型,为汽车制造商及销售商提供可信度更高的销售预测数据,作为决策参考.
1 基于网格搜索与交叉验证的SVM 回归模型
1.1 SVM 回归基本理论
支持向量机(Support Vector Machine,SVM)由Cortes 和Vapnik 等于1995年提出,此后,Vapnik 又提出引入ε不敏感损失函数[6]的ε-SVR 算法,将支持向量机应用于回归领域.ε-SVR 通过事先确定ε来控制算法大致希望达到的精度.ε不敏感损失函数的用途在于能够用稀疏数据点来表达如下要找的回归函数.
设样本向量为{(x0,y0),(x1,y1),···(xk,kk)} (xi∈Rn,yi∈R,i=1,2,···,k),其中k为样本个数.支持向量机回归的基本思想是通过一个非线性映射Φ,将数据xi映射到高维空间F中,并在这个高维空间中构造最优线性回归函数:

式中,ω 和φ(x)为m维向量,b为偏置量.支持向量机采用结构风险最小化原则(SRM)[13]确定参数 ω和b的值,即:

式中,Rreg为正则化风险;‖ω‖2为控制模型的复杂度;杂度较大,易造成过学习;C为惩罚系数,用来调节模型复杂度和训练误差,C越大,对数据的拟合程度越高,但过大时会使机器学习复为误差控制函数,通常采用ε-不敏感函数来度量,定义如下:

根据结构风险最小化原则,考虑在数据集上获得的回归模型的复杂度,持向量机回归本质上就是求解一个优化问题[11]:
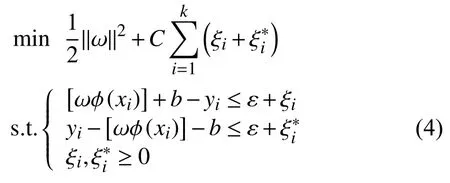
式中,ξi和为松弛变量,此问题称为支持向量机的原始问题.由于ω 维数很大,为了便于求解,根据强对偶定理引入Lagrange 乘子 αi和,建立Lagrange 函数,将这一优化问题转化到对偶空间中得到原始问题的对偶问题[14]:

式中,K(xi,xj)为核函数,可将原问题通过非线性变换,映射为某个高维特征空间上的线性问题,进行求解.本文采用的汽车销售数据属于非线性数据,故需采用核函数.,αi是对偶问题的解,由此可得回归函数为:

1.2 核函数的选择
在高维特征空间中,线性问题中内积运算可以用核函数来代替,即

支持向量机不同的内积核函数将形成不同的算法,回归支持向量机常用的核函数有三种,即多项式核函数、径向基核函数和Sigmoid 核函数.对于多项式核函数,当特征空间位数很高时,其计算量将大大增加,甚至对某些情况无法得到正确的结果,而径向基函数不存在这个问题.另外,径向基函数的选取是隐含的,每个支持向量机产生一个以其为中心的局部径向基函数,使用结构风险最小化原则,能找到全局的径向基函数参数[15].对某些参数,RBF 与Sigmoid 核函数具有相似的性能,在一般情况下,首先考虑的是RBF[16].因此本文选取径向基核函数(RBF)建立预测模型[17-19],即:式中,σ为径向基函数的宽度,σ越小,径向基函数的宽度越小,越有选择性.是径向基核参数,g越大,径向基函数越有选择性.把径向基核函数代入(6)式得到完整的回归函数,即:
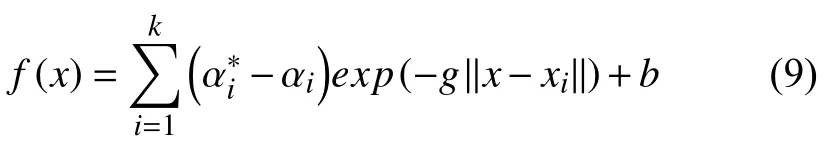

研究发现,支持向量机计算过程中涉及到的两个参数:惩罚系数C和核函数参数g,是影响支持向量机回归模型的主要因素.
1.3 基于网格搜索的SVM 参数优化
在本案例中支持向量机(SVM)的核函数采用的是径向基核函数(RBF),径向基函数中的参数g和惩罚系数C的选择对汽车销售量的预测值有着很大的影响,为了寻找最佳的参数C和g,本文根据前文和样本特性选择的是网格搜索法(grid search).网格搜索法首先是要把所有的可能的参数值做统计然后进行分组,分组的依据是由步距决定的网络.然后对逐个网络中可能的最优参数值进行计算,并验证观察结果是否最优,即找到的最优参数[19].
交叉验证(cross validation)是一种消除取样随机性所带来的训练偏差的统计学方法.常用的交叉验证方法有重复随机抽样法、K-fold 交叉验证法、留一法等.基于支持向量机原始预测模型,C和g的初始值均为1,预测精度较低,当使用交叉验证网格寻优的方法以后,C和g值在设定的范围内进行寻优,对每个预测模型均进行MSE 值得比较,这样可以建立最佳的预测模型,保证MSE 值为最小,避免原始模型预测精度低的问题.所以本文将交叉验证与网格搜索相结合,以MSE 最小化为参数优选的目标,提高了参数优选的效率和准确性,同时极大规避了样本的抽样随机性对模型性能的影响[20,21].网格搜索法参数优化的基本流程如下,流程图见图1所示.
(1)先初始化网格搜索中惩罚系数C和核函数参数g的搜索范围和搜索步长,本文在寻优时分为粗略选择和精细选择.
(2)进行粗略选择,粗略选择时C的取值范围是[2-8,28],当输入变量(C的取值范围、g的取值范围、交叉验证的折数等)个数小于8,则指数的步长为0.8,g的取值范围是[2-8,28],指数的步长为0.8.得到粗略选择的C和g.
(3)根据粗略选择结果再进行精确选择,C和g的取值范围是粗略选择后确定的范围,指数步长为0.5.

图1 基于交叉验证网格寻优的支持向量机预测模型
图2 给出Model-12m模型(每12个月预测下一个月)精细选择参数后的等高线图和3 D 视图.以log2C为横坐标,log2g为纵坐标,MSE(下文公式求得)为Z 轴(见下文公式).如图1所示,图中红点就是精细选择时找到的最佳参数点,此时log2C=1/2,log2g=1/2,所以得到最佳参数,.
2 当前的预测模型
进行销售预测时,由于预测对象可能是产品销售数量、销售价格、销售金额,预测的地域、客户、时间长度等的不同,可以有不同的预测方法分类.本文案例主要研究某汽车公司的销售额预测,适用于这种场合的常用预测方法分为两大类:定性预测方法和定量预测方法,见图3.
第一类是(qualitative)预测方法.依据人们对过去及现在的经验、判断和直觉作预测.一般常用的定性销售预测方法有四种:高级经理意见法、销售人员意见法、购买者期望法和德尔菲法.
第二类是定量预测方法.包括时间序列分析法和(causal)预测方法.本文提出的基于支持向量机优化模型的预测方法属于时间序列分析方法.
图4 亦可见,销售预测及其预测方法的选择受到诸多内部因素及外部因素的交互影响,相当复杂.某汽车公司当前的销售预测模型是建立在汽车行业预测的基础上,是定性与定量相结合的预测模型,而汽车行业的经济预测是建立在宏观经济预测的基础上的.某汽车公司通过对中国车市的发展阶段、增长潜力、国家补助政策、各地区的引导政策、消费者收入与开支、出口、利率、企业车型开发进度、企业投资和与整车有关的其他重要因素和事件进行预测,得到公司未来某一阶段的产出/销售预测.定性预测模型预测流程图如图3所示,可见该方法包含一些简单的定量分析,但更多地依赖于上级决策者的决定及销售人员的建议,偏重于定性方法.

图2 Model-12m模型参数精细选择等高线图和3D 视图
按照该流程,以2 0 0 9年的实际销售额预测2010年到2015年共计72个月的销售额,示于图5中.图中,Sales 为实际销售额,PredSales 为某汽车公司当前预测模型预测的销售额.L 汽车公司的预测销售额与实际销售额的绝对误差相差幅度较大,绝对误差最大值如图中红圈所示,是2013年12月(约14 万元),最小值是2014年11月(约8.4 万元),最大值是最小值的160 倍.

图3 销售预测内在的逻辑关系图

图4 某公司当前的销售预测方法流程图
将该预测的相对误差示于图6中.相对误差最大值是2015年8月,达61.4%;最小值是2014年11月,为0.27%,前者是后者的200 倍.在72个月的总样本中,有15个月的相对误差在30%以上,占样本总数的21%;8个月的相对误差在20%和30%之间,占样本总数的11%;其余49个月的相对误差小于20%,占样本总数的68%.可见,某公司目前所采用模型的预测并不理想.下文将采用基于网格搜索交叉验证的SVM 优化算法对某公司的销售额进行预测,以期获得更加准确的销售预测模型,为某公司的生产及销售决策提供更为可靠的参考与指导.
3 基于SVM 优化模型的汽车销售预测与分析
采用基于网格搜索和交叉验证的SVM 回归模型对某公司2009年到2015年共计7年(84个月)的销售额进行预测,选取2010年到2015年共计72个月的预测数据与实际销售额进行比较分析.多次尝试的结果表明,采用一个季度(3个月)或多个季度的销售数据进行预测较其他不以季度为周期的预测模型预测效果更佳.假定每3个月数据预测下一个月销售额的模型为Model-3m,其他各模型名称见表1.

图5 某公司预测销售额和实际销售额比较图

图6 某公司预测销售额和实际销售额的相对误差值
为了说明所建预测模型的优劣,将预测模型的预测值和真实值的均方误差(Mean Squared Error,MSE)、绝对误差(Absolute Error,AE)和相对误差(Relative Error,RE)作为评价指标来评价模型,其中均方误差主要评价预测模型的整体性能,相对误差和绝对误差可用于评价预测模型的局部性能[22],以季度为周期的预测模型的绝对误差相较别的预测模型更小,对整体性能亦可作为参考.

表1 各模型名称
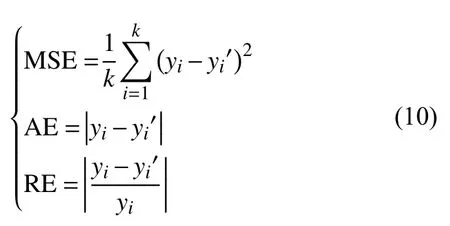
式中,yi为原始销售额,yi′为预测销售额.
3.1 Model-3m 预测模型
参见图1 交叉验证网格寻优的支持向量机预测模型流程图,使用原始C,g建立原始预测模型Model-3m-original,此时C=1,g=1.模型的平均相对误差为11.849%,均方误差为9.232×10-2,决定系数为0.509 73.其预测性能虽优于Model-X,但较下文所提的经过交叉验证与网格搜索的Model-3m 预测性能仍显不足,所以证明经过交叉验证与网格搜索的支持向量机预测模型得到改进,提升了预测精度和可靠性.
经网格搜索与交叉验证寻优,采用三个月数据预测下一个月销售额的Model-3m模型的最优SVM 参数组合为C=2-3/2,g=2,预测结果见图7.图中,绝对误差最大值是2015年12月(约1,1.57 万元),最小值是2011年3月(7.8 万元),最大值是最小值的150 倍.相较于某公司当前采用的Model-X模型,实际销售额和预测销售额之间相差幅度有所减小.Model-3m模型预测结果的相对误差示于图8中,相对误差最大值为38.02% (2015年8月),比Model-X的最大相对误差61.4%小23.38%;最小值为0.23% (2011年3月),且75%的样本(54个月)相对误差在20% 以下,比Model-X 增加了5个月;相对误差在20%和30%之间的有14个月,占样本总数的19.4%,比Model-X 增加了6个月;相对误差30%的仅有4个月,占样本总数的5.6%,比Model-X 减少了11个月.可见,Model-3m模型对销售额的预测效果明显优于Model-X模型,后文将对基于优化SVM的其他模型进行研究,以期获得更优的预测效果.

图7 Model-3m 预测模型实际销售额和预测销售额对比图

图8 Model-X模型和Model-3m模型相对误差对比图
3.2 Model-6m 预测模型
采用6个月数据预测下一个月销售额的Model-6m模型优化后的SVM 参数组合为C=2,g=4.该模型预测销售额与实际销售额的绝对误差较Model-X模型和Model-3m模型均有大幅下降,绝对误差最大值约为14 万元(2010年2月),最小值是约为4.6 万元(2010年1月),前者仅为后者的3 倍,而非200 倍(Model-X)或150 倍(Model-3m).Model-6m的绝对误差主要集中在13 万元到14 万元之间,幅度比较稳定.
由Model-6m 预测模型的相对误差图9 可见,该模型的相对误差基本以0.45% 为中心上下浮动,落在0.15%到0.75%之间,最大相对误差是2014年1月的0.724%,最小的相对误差值是2010年1月的0.18%,二者较为接近.
将Model-6m 与Model-3m的相对误差示于图10中进行比较分析.与Model-3m模型相比,Model-6m模型的相对误差紧贴着横轴,总体上明显较小,除3个月的相对误差略有上升外(2011年3月,2013年4月,2014年8月),其余月份的相对误差均大幅下降,降幅最大的是2015年8月,达 37.39%;降幅超过10%的有33个月,占样本总数的45%.表明,Model-6m模型的预测效果较Model-3m模型有显著提高.

图9 Model-6m 预测模型的相对误差图
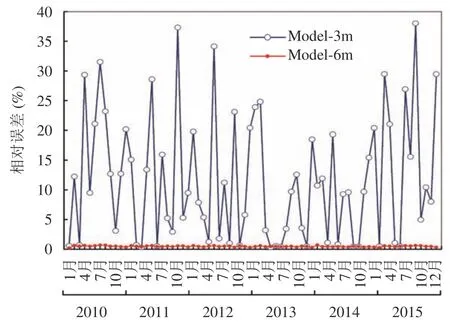
图10 Model-3m模型和Model-6m模型相对误差对比图
3.3 Model-9m 和Model-12m 预测模型
采用9个月数据预测下一个月销售额的Model-9m模型,其优化后的SVM的最优参数组合为,g=2.以一年(12个月)数据作为预测基准的Model-12m模型,优化后的SVM的参数组合为,.
Model-9m模型和Model-12m模型预测销售额与实际销售额绝对误差相差较小.Model-9m模型绝对误差最大值是2012年10月的14 万元,最小值是2011年6月的12 万元;Model-12m模型绝对误差最大值是2010年10月的12.8 万元,最小值是2013年4月的7.45 万元.将Model-9m模型、Model-12m模型与前述最佳模型Model-6m的相对误差共同示于图11中.可见,Model-6m的相对误差在0.15%~0.75%之间,Model-9m模型的相对误差在0.25%~0.75% 之间,Model-12m模型的相对误差在0.25%~0.65%之间.三个模型相对误差低于0.45%的月份数分别为29个月,29个月和42个月,分别占样本总数的40%,40% 和58%.相对于Model-9m模型,Model-12m模型每一个月的相对误差均有所下降;相对于Model-6m模型,Model-12m模型除了2010年1月、2015年1月相对误差分别增大了0.286%和0.152%,其余的月份均有不同程度下降.表明,以6个月、9个月、12个月的数据进行销售额预测,效果均较佳,其中Model-12m模型的整体性能更好.数据有限时,Model-6m模型亦可实现较为准确的销售额预测.
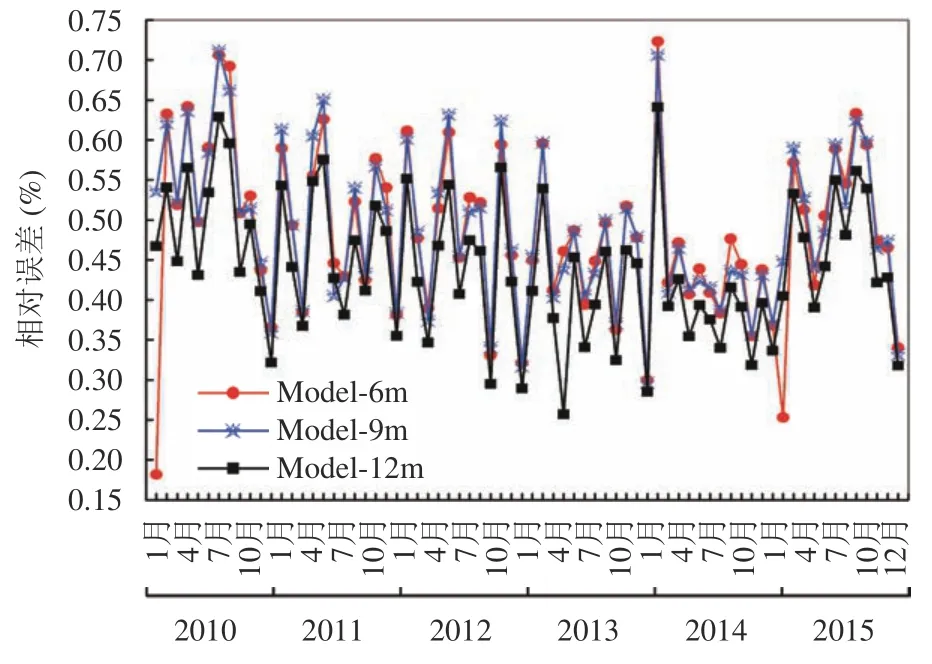
图11 Model-6m,Model-9m 和Model-12m 三种模型的相对误差对比图
总体上,图11中的3 种模型在中间段预测能力较好,尤其是2013年和2014年,相对误差多在0.45%附近,而2011年和2015年的预测能力相对较差.2011年正处于全球金融危机,大部分消费者有危机感,更愿意把钱存在银行,对投资买车可能处于观望状态,不同月份销售的汽车数量波动较大,因而影响预测.而2013年和2014年,金融危机缓和,国家大力提倡人民消费,每个月的销售量都较为平稳,有利于预测.2015年国家出台限制公车购买量的政策,一定程度上影响了每个月的销售额,增加了预测难度.
3.4 Model-18m 预测模型
Model-18m模型优化后的SVM 参数组合为C=1,g=0.707107.该模型在2013年12月的相对误差达到了3.10%,比Model-6m、Model-9m 和Model-12m的最大相对误差均大三倍以上,此处不加详细讨论.
3.5 Model-24m 预测模型
采用24个月数据预测下一个月销售额的Model-24m模型,其优化后的SVM 参数组合为C=1,g=0.5.Model-24m模型的相对误差在0.25%~0.65%之间,相对于Model-12m模型,有38个月的相对误差减小,22个月的相对误差增大.与Model-6m 和Model-9m模型一样,Model-24m模型在中间月份,即2013年和2014年的预测性能较好,而在起始和末端月份的预测性能较差.
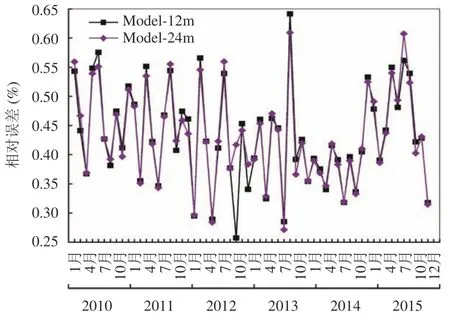
图12 Model-12m 和Model-24m 相对误差对比图
综合以上可知,以年(12个月)的数据为周期的模型预测效果最佳,因Model-24m模型所需数据量较为庞大,性能提高却并不明显,Model-12m模型即可进行较为准确的销售预测.
3.6 各模型评价指标的比较与分析
决定系数R2是预测值拟合程度的指标[23],R2的数值大小可以反映实际销售额与预测销售额之间的拟合程度,R2越大,数据拟合程度越高,预测销售额的可靠性就越高.
表2 列出了各模型的决定系数,平方相对误差和均方误差三项评价指标.Model-24m模型的决定系数最大,平均相对误差最小;Model-12m模型均方误差最小,决定系数和平均相对误差与Model-24m 相近.在基于优化SVM的模型中,采用三个月数据进行预测的Model-3m模型,决定系数是某公司当前采用的Model-X模型的近3 倍,平均相对误差小4.67%,而Model-24m 和Model-12m的平均相对误差更是Model-X的1/25(即4%),充分说明基于交叉验证网格搜索的SVM 预测模型整体性能非常好,最佳模型是Model-12m 和Model-24m,当数据有限时,亦可以采用Model-6m模型进行预测.为了验证经过交叉验证和网格搜索后的支持向量机预测模型的优越性,对最佳模型Model-12m 随机选取销售数据进行测试,并计算其各项评价指标,列于表2中:平均相对误差为0.446%,均方误差1.012×10-4,决定系数为0.99970,各项指标与Model-12m模型性能相差不大,可见经过交叉验证和网格搜索后的支持向量机预测模型预测精度高,鲁棒性强.

表2 各模型评价指标
4 结论与展望
本文针对汽车销售预测问题的特点,运用了交叉验证和网格搜索方法优化了支持向量机的惩罚系数和核函数参数的选择,建立了改进支持向量机汽车销售预测模型,提高了汽车销售的预测精度.尽管预测效果可能受到国家政策、消费模式等的影响,但本文提出的基于改进支持向量机优化的预测模型仍然可达到较小的预测误差,预测数据可靠性高,可给汽车企业在日常生产、 销售管理中,提供科学有效的预测方法,从而为决策者制定或调整相关计划提供可靠的理论依据,具有一定现实意义及应用价值.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
今日农业(2021年12期)2021-11-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
房地产导刊(2020年5期)2020-06-24
初中生世界·八年级(2019年6期)2019-08-13
中国计算机报(2018年16期)2018-10-08
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
高中生学习·高三版(2016年9期)2016-05-14
纺织服装周刊(2016年8期)2016-03-16
