
曲线数据压缩算法的研究及应用①
2019-07-26 03:16孟卫东龙美彪
计算机系统应用 2019年5期
孟卫东,龙美彪
(南岳电控(衡阳)工业技术股份有限公司,衡阳 421007)
矢量曲线压缩,也称曲线特征点提取,还称曲线特征点筛选或曲线抽稀,其实质是一个信息压缩问题,它是从组成曲线的数据集合A中抽取一个子集a,用这个子集作为一个新的信息源,在规定的精度范围内,该子集能够从内容上尽可能近似反映原集合A,从数据量上则尽可能大的压缩[1].数据压缩的目的主要是删除冗余数据、减少数据的存储量、节省存储空间、加快后继数据分析和使用速度,数据压缩的核心就是在不扰乱拓扑关系的前提下,对数据进行合理的加工.曲线压缩对于计算机图形学、计算机制图学等有着非常重要的意义,而在测量系统和控制系统中也需要采集和处理大量的随机分布的离散数据,这都需要用到数据压缩,数据压缩的结果直接影响后续应用研究[2].
目前已经出现多种较成熟曲线压缩理论,包括间隔取点法、角度限制法、垂距限值法、光栏法、道格拉斯-普克法[3]、最小面积重复删除法、新兴的基于小波技术的曲线压缩等,由于基于小波技术的压缩算法可能导致边界处变形,且压缩过程复杂,对计算机要求高等缺点,目前应用较少.大家公认的矢量曲线特征点提取的经典算法是道格拉斯-普克法,简称D-P 法.目前已有较多研究人员针对道格拉斯-普克法的缺陷进行了改进[4-19],这些算法各有利弊,并且在不同程度上存在阈值选取不确定、时间复杂度高、压缩效果不理想、未考虑数据点频数等问题.
针对上述存在问题,本文提出了一种改进的特征点提取方法,该算法选用数据点到基线的距离,数据点与相邻数据点间的夹角,考虑数据点的“孤立性”和频数等属性作为特征点选取的关键因素,利用熵值法确定最终评价值,自动按照给定数据压缩率进行曲线数据压缩,并对改进算法进行了实验验证.
1 相关工作
在矢量数据中,曲线是由离散的点列组成,曲线数据实际上是一些表示点的数据集合.作为曲线形态的支撑点,数据集的首尾两点在数据压缩算法中是必须要保留的.现在最常用的曲线数据压缩算法是道格拉斯-普克法,该算法的具体步骤是:
步骤1.曲线数据点集合由点序P1,P2,P3,···,Pn组成,设A=P1,B=Pn,用虚线段连接AB;
步骤2.计算AB范围内的所有内点Pi(i=2,···,m-1)到线段AB的距离di,选取其中距离最大的点Pk,相应距离为dk.
步骤3.判断dk是否小于设定阈值δ,若否,则点Pk为压缩后的特征点,设B=Pk,执行步骤2;
步骤4.判断B是否等于Pn,若否,则将A按原顺序放入特征点集合,再设A=Pk,B=Pn,用虚线段连接AB,执行步骤2;
步骤5.将A,B作为特征点放入特征点集合,算法结束.
时间复杂度是衡量算法优劣的主要标准之一.道格拉斯-普克算法第2 步的时间复杂度为O(n),整个算法是通过递归实现的,在一定数据特征下,第3 步和第4 步执行的时间为2T(n/2),此时整个算法执行的时间2T(n/2)+O(n),由主定理[20]可得时间复杂度为O(nlogn);在最坏情况下,第3 步和第4 步执行的时间为T((n-2)+···+1)=T((n-1)(n-2)/2),则整个算法的时间复杂度为O(n2).
道格拉斯-普克法是一个从整体到局部,即由粗到细的方法来确定曲线压缩后保留点的过程,其优点是所有特征点都是原曲线上的数据点,可以较好地保持曲线压缩前后几何特征的相似性,具有平移、旋转的不变性,但是道格拉斯-普克法也有自身的局限性:
(1)阈值的选取具有不确定性,如果阈值选取不合理,可能导致一些特征点被误删除;
(2)选定阈值与数据压缩率没有直接关系,导致不能事先确定压缩点数;
(3)算法中存在递归分段计算,对于复杂的曲线,迭代次数多,计算量大,比较耗费时间;
(4)未考虑频数等非空间属性对数据点的影响,可能导致一些特征点被删除.
目前已有较多研究人员针对道格拉斯-普克法的缺陷进行了相关研究:为了消除迭代、提高算法运行速度,王笑天等[4]提出采用第一特征点法;为了降低压缩带来的面积误差和位置偏差问题,韩晓霞等[5]提出顾及曲线走向及局部面积特征的矢量数据压缩算法;针对压缩后曲线保持无自相交属性的问题,Wu ST 等[6]提出曲线无自相交压缩的算法;针对海洋权益问题,于靖等[7]提出面向自然岸线抽稀的改进道格拉斯—普克算法;针对阈值优化选取问题,Prasad DK 等[8-13]提出阈值优化选取方法;针对连续弯曲问题,Ai TH 等[14-19]提出对连续弯曲进行压缩的方法等.以上这些算法更多考虑的是曲线的空间属性,没有考虑频数等非空间属性;对于阈值优选时,多个属性之间的协调性不强,导致“综合”效果较差.
2 改进的曲线数据压缩算法
对于随机分布的离散数据点,其点集排序的方法是依次寻找距离最近的下一个新点,因此,得到的点序反映的只是逻辑相邻关系,这和物理相邻的程度是有差异的.如果只按逻辑相邻关系进行点序的成串删除,有时就会删去互相远离的特征点[21,22].在测量系统和控制系统中,采集得到的重复数据点在点集中自动合并成唯一数据点,导致数据压缩时,该数据点重要度下降;数据点之间的相似程度往往用“距离”来度量,逻辑相邻的数据点的多少也是特征点选取的关键因素,例如连续小角度变化的复杂曲线.因此,特征点确定不仅与单个离散数据点出现频数有很大关系,还与逻辑相邻离散数据点间出现频数有关.
为了防止删除特征点,不仅要考虑数据点到基线的距离、数据点与相邻数据点间的夹角,还应结合考虑该数据点的“孤立性”和频数等非空间属性来共同决定对它的取舍.改进算法具体步骤如下:
步骤1.根据经验确定直方图的极差、组距、组数m和各组界限值;以固定时间间隔 Δu、从连续信号S(u)上采样得到离散数据点,更新直方图相应组的频数Rk(k=1,2,···,m);计算各组频率fk:
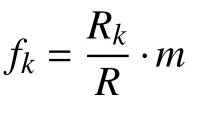
式中,Rk为各组频数;R为总频数;m为 组数.
步骤2.曲线数据点集合由点序P1,P2,P3,···,Pn组成,曲线数据点数为n,内点数为N=n-2.指定需要压缩的数据点数ΔN(1 ≤ΔN≤N),则压缩率σ=ΔN/N.可根据特普费尔公式计算ΔN:

式中,N2为新数据点集的点数;N1为原数据点集的点数;S1为原数据点集的比例尺;S2为新数据点集的比例尺;x为重要度系数,x=0,1,2,分别对应重要,一般和次要;ΔN为要压缩的数据点数.
步骤3.计算P1,Pn范围内的所有内点Pi(i=2,···,n-1)的孤独指标gi:

式中,分子的涵义是当前点Pi到逻辑相邻的两个数据点Pi-1,Pi+1的距离之和;分母的涵义是P1,Pn之间所有相邻数据点间连线的平均长度的两倍.不难看出,孤独指标gi是一个在1 左右摆动的正值.
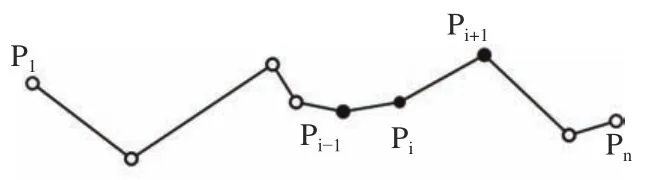
图1 孤独指标的涵义
步骤4.计算P1,Pn范围内的所有内点Pi(i=2,···,n-1)到相邻两个数据点Pi-1,Pi+1连线的距离指标di;
步骤5.计算P1,Pn范围内的所有内点Pi(i=2,···,n-1)到相邻两个数据点Pi-1,Pi+1连线的夹角指标θi;
步骤6.熵值法计算P1,Pn范围内的所有内点Pi(i=2,···,n-1)的综合得分si:
(1)指标归一化:

式中,为第i个数据点的第j项指标的归一化数值(i=2,···,n-1;j=1,···,J),其中j分布对应距离、孤独、夹角和频数等指标;Xij为第i个数据点的第j项指标的数值;
(2)计算第j项指标下第i个数据点占该指标的比重fij:
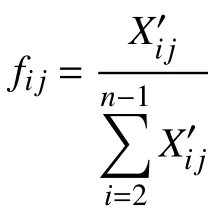
(3)计算第j项指标的熵值hj:

(4)计算各项指标的熵权wj:

式中,0 ≤wj≤1,且;
(5)计算各数据点的综合得分si:
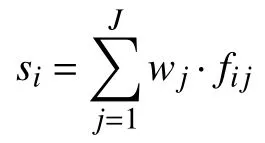
步骤7.依次将 ΔN个数的最小综合得分si对应的数据点Pi从曲线数据点集中删除,算法结束.
本文算法比较简单,包含5个单层循环,分别是第3 至7 步,其中前4个循环的时间复杂度均为O(n),第5个循环的时间复杂度为O(ΔN),所以算法的时间复杂度为O(n).
本文算法不仅继承了道格拉斯-普克算法的优点,如所有特征点都是原曲线上的数据点,具有平移、旋转的不变性等,而且增加了如下优点:
(1)不需要事先设定阈值,算法自动根据加权修正后的综合得分,以从小到大顺序,依次压缩数据;
(2)直接指定数据压缩率,保证压缩算法运行后结果,满足测量系统和控制系统的带宽、分辨率和存储量的要求;
(3)取消迭代运算,对于复杂的曲线,将有效降低计算量,减少运算时间;
(4)特征点的确定,不仅考虑了逻辑相邻和物理相邻关系,而且同时考虑了频数等非空间属性的影响,降低了误删除概率.
3 实验分析
3.1 实验数据来源
实验一:为证明本文算法的有效性和优越性,以我国东北某段国界线1:100 万的数据为实验对象,分别采用道格拉斯-普克算法与改进算法对实验对象进行数据压缩效果对比实验,该部分区域的形态比较曲折,能够很好地检验两种数据压缩方法的效果.
实验二:为了验证频数对测量系统和控制系统采集结果数据压缩的影响,本文选取实测高压共轨柴油机进油计量阀流量特性变化较明显的区间作为实验区,进行滤波、融合等预处理后生成等效数据点集(如图5所示),作为本算法抽稀实验的源数据,共计25个数据点.
3.2 实验设计
矢量曲线数据压缩算法的优劣,一般通过运行时间、压缩率、位移偏差和面积偏差来评价.数据压缩的速度(时间复杂度)主要以运行时间来评价;数据压缩率(空间复杂度)是压缩掉的曲线数据点数与原始曲线点数之比;位移偏差是曲线压缩导致的原始数据点与压缩后曲线数据点的空间偏移量,通过计算原始曲线上数据点到压缩后曲线的最短距离的中值或平均值来度量;面积偏差是曲线压缩带来的面积偏差,通过计算原始曲线所围面积与压缩后曲线所围面积的差值来度量,该指标反映了压缩后曲线与原曲线的贴近程度.
实验一:由于对比的是数据压缩后曲线的局部形态特征变化,因此需要对两种算法应用相同的压缩率.
实验二:频数指标采用两个直方图频数分布来进行计算,分别为方案一和方案二,其直方图频数分布如图2 和图3所示.

图2 方案一直方图频数分布

图3 方案二直方图频数分布
3.3 实验结果及分析
3.3.1 实验一
由于道格拉斯-普克算法不能事先确定压缩率,经过多次优选阈值后确定相同压缩率.从图4 可以看到,道格拉斯-普克算法数据压缩结果虽然能较好地保留曲线特征,但会导致尖锐角的出现,压缩效果比较生硬,平滑度不够,而改进算法较好地保持了曲线的整体形态特征,能够较好地体现出“综合”的本质.

图4 实验一两种算法形态对比
3.3.2 实验二
由于试验方案中各项指标的熵权按表1所示变化,导致各数据点的综合得分发生变化,进而影响到压缩数据点和位移偏差、面积偏差.压缩结果如图5 至图6所示,运行时间、压缩率、位移偏差及面积偏差如表2所示.

表1 各项指标的熵权

图5 曲线数据压缩率为4%的结果
图5中,本文改进算法与道格拉斯-普克算法的压缩率同为4%,即压缩点数为1个.道格拉斯-普克算法迭代次数为45 次.道格拉斯-普克算法删除图5中序号2 点;方案一删除图中序号18 点;方案二删除图5中序号15 点.
图6中,本文改进算法与道格拉斯-普克算法的压缩率同为12%,即压缩点数为3个.道格拉斯-普克算法迭代次数为41 次.道格拉斯-普克算法删除图6中序号2、17 和18 点;本文改进算法方案一删除图6中序号15、18 和21 点.方案二删除图6中序号14、15 和24 点.
从表2 可以看出:
(1)运行时间:压缩率为4%时,本文改进算法运行时间比传统道格拉斯-普克算法减少了68.33%;压缩率为12%时,减少了50.13%.由于道格拉斯-普克算法迭代次数分别为45 次和41 次,即使按时间复杂度为O(nlogn),也远大于本文改进算法的时间复杂度为O(n),导致程序运行时间较长.输入数据量n急剧增加时,传统道格拉斯-普克算法执行次数的增长次数差异显著增加[20].
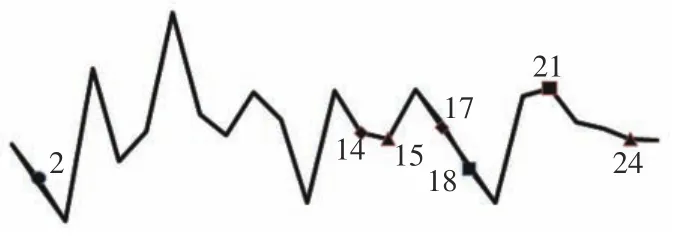
图6 曲线数据压缩率为12%的结果
(2)位移偏差、面积偏差:本文改进算法根据数据点多种属性的相对重要性程度进行压缩,当考虑数据的非空间属性,如频数时,在较好地保持曲线形状的同时,可能导致位移偏差和面积偏差大于传统道格拉斯-普克算法.
(3)压缩率:由于道格拉斯-普克算法最佳阈值选取需要多次试探,Prasad DK 等[8-13]采用曲线拟合等阈值优化选取方法,严重影响压缩计算效率,很难直接给定压缩率.本文改进算法自动按照给定数据压缩率进行曲线数据压缩,容易实现高压缩率与保真效果之间的平衡.

表2 算法的实验结果数据比较
4 结论
本文对传统的曲线压缩算法进行了简单的介绍,分析了道格拉斯-普克数据压缩算法,针对其阈值的选取、数据压缩率、时间复杂度和特征因素等方面存在的不足,保留道格拉斯-普克算法的优点,如所有特征点都是原曲线上的数据点,具有平移、旋转的不变性等,提出了一种改进的特征点提取方法,该算法通过直方图统计数据点的频数,根据数据点到基线的距离、数据点与相邻数据点间的夹角,考虑数据点的“孤立性”和频数,自动按照给定数据压缩率进行曲线数据压缩.在MATLAB 上进行了仿真实验,利用自主研发的控制系统平台,对进油计量阀流量特性进行增量自学习,并在油泵台架和发动机台架上完成了相应的实验.实验结果表明,本算法可以有效的对数据进行压缩处理,满足测量系统和控制系统的数据压缩需求.
猜你喜欢
社会科学战线(2022年2期)2022-03-16
英语文摘(2022年1期)2022-02-16
成都信息工程大学学报(2021年6期)2021-02-12
思维与智慧·上半月(2020年9期)2020-09-15
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
意林·少年版(2020年23期)2020-01-15
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
初中生世界·八年级(2019年3期)2019-04-22
初中生世界·八年级(2017年3期)2017-03-24
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
