
基于ICO-SPA特征提取的近红外高光谱小麦赤霉病粒呕吐毒素含量预测
2019-07-24 11:24:22韩东燊徐剑宏沈明霞
麦类作物学报 2019年7期
丁 静,梁 琨,韩东燊,徐剑宏,沈明霞
(1.南京农业大学工学院/江苏省现代设施农业技术与装备工程实验室,江苏南京 210031;2.江苏省农业科学研究院农产品质量安全与营养研究所,江苏南京 210014)
小麦在世界范围内种植面积广泛,既是人类主要的食物来源,又是重要的工业原料[1]。赤霉病是小麦的主要病害之一,在小麦抽穗扬花期气候的温、湿度适宜且雨水充沛时容易高发。赤霉病的病原菌主要是禾谷镰刀菌,该菌在小麦籽粒中所产生的代谢产物脱氧雪腐镰刀菌烯醇(DON)严重危害人畜健康,人畜误食带菌病粒会引起腹泻、呕吐等症状,因此DON又被称作呕吐毒素[2-5]。我国GB 2715-2005《粮食卫生标准》中规定小麦及全麦粉中DON限量标准为1 mg·kg-1。传统的检测方法主要是生物化学检测法,包括皮肤毒性实验、气相色谱(GC)、液相色谱(LC)、气(液)质联用(GC-MS)、酶联免疫吸附试验(ELISA)等,这些检测方法耗时、昂贵、重现性差、样本处理过程复杂、需要专门的技术人员操作,难以进行大批量样本的快速无损检测。
高光谱成像技术融合了光谱技术与成像技术,不仅可根据提取的样本光谱特征表征和识别给定的物质,还可通过对给定的物质进行成像,从而达到扩大检测面积、提高检测精确度的目的[6],为进行复杂综合的小麦赤霉病症状检测提供保障。另外,由于样本前处理简单、高光谱图像采集方便及获得的样本信息丰富,已有研究者将高光谱技术应用于小麦赤霉病检测。Shahin等[7]将加拿大西部红春小麦籽粒分为健康、镰刀菌轻度感染和严重感染三个等级,并使用主成分分析(principal component analysis,PCA)在450~950 nm范围内提取6个特征波段(484、567、684、817、900、950 nm)用于线性判别分析(linear discriminant analysis,LDA)建模,结果表明,基于6个特征波段建模与基于全波段建模准确率相当,均高于92%;Delwiche等[8]通过在400~1 000 nm和1 000~1 700 nm两个波段范围寻找能够区分正常籽粒与赤霉病粒的特征波段对(分别为502、678 nm和1 198、1 496nm)建立二等级分类模型,可见光和近红外波段分级准确率分别为94%和97%。梁 琨等[9]比较了连续投影算法(successive projections algorithm,SPA)和竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)在小麦赤霉病籽粒识别上的应用效果,发现SPA选取的特征变量数量少,精度高,模型预测效果优于CARS,结合支持向量机(support vector machines,SVM)模型能够达到94%以上的预测准确率。这些研究结果表明,高光谱技术结合特征波长挑选算法能够通过少数几个特征变量进行赤霉病籽粒识别。以上研究均是对小麦感染赤霉病的定性分析,使用高光谱成像技术进行小麦中呕吐毒素定量分析的报道较少。Barbedo等[10-11]利用基于高光谱图像的处理算法,采用数学形态学操作和光谱波段操作实现对小麦镰刀菌毒素(FHB)的快速自动检测,提出使用镰刀菌指数(FI)计算小麦籽粒中FHB存在的可能性,进而估算DON浓度,准确率约为91%,但是FI值在0.4~0.6范围内的正态分布曲线存在重叠区域,在这个区域FI值存在不确 定性。
感染赤霉病的小麦产生的DON毒素会导致籽粒中的主要大分子有机物成分如淀粉、蛋白质、脂肪、纤维素的含量发生变化[12-13],这种变化能够反映在光谱上[11,14-15],从而具备了使用光谱技术检测DON的可能性。本研究基于近红外高光谱成像技术进行DON定量检测,将1 000~2 500 nm范围内的光谱数据与标准方法测得的DON含量值进行关联,将SPA以及区间组合优化算法(interval combination optimization algorithm,ICO)结合SPA提取的特征变量作为输入建立偏最小二乘回归(partial least squares regression,PLSR)、多元线性回归(multiple linear regression,MLR)和最小二乘支持向量机回归(least squares support vector regression,LS-SVR)模型预测样本中DON含量,比较不同特征波长筛选算法并结合预测模型精度,获得小麦赤霉病检测的优选波长和优化模型,以期实现小麦感染赤霉病等级的高效、智能定量检测,保证粮食食品 安全。
1 材料与方法
1.1 材料与仪器
试验中用于磨粉的小麦籽粒均来自江苏省农业科学研究院农产品质量安全与营养研究所,供试材料是2017年收获的冬小麦,品种为烟农19。所用仪器包括PM8188A谷物水分测定仪(泰州市维科特仪器仪表有限公司)、XA-1型磨粉机(常州越新仪器制造有限公司)、Image-λ-N25E-HS型高光谱成像光谱仪(芬兰 Specim公司)、HSIA-OLE23型镜头(德国施耐德公司)、4个HSIA-LS-T-H型卤素灯(四川双利合谱科技有限公司)、HSIA-T1000-IMS型电控位移平台(四川双利合谱科技有限公司)和GaiaSorter-Dual型暗箱(四川双利合谱科技有限公司)。
1.2 试验方法
1.2.1 样本前处理
对获取的小麦赤霉病籽粒样本人工分拣除去麦秆、石子、土块、塑料等异物,使用谷物水分测定仪检测籽粒含水量,对于含水量过高的样本进行通风干燥,含水量较低的样本暴露在潮湿空气中,最终将所有小麦赤霉病籽粒样本含水量控制在12%~13%范围[16-19],以减少样本含水量差异对光谱的影响,保证建模数据的可靠性。取约25 g小麦籽粒放入磨粉机中研磨30 s,将磨粉机杯盖内壁附着的未磨碎的部分扫入磨粉仓,盖上杯盖继续磨粉30 s,保证全部颗粒均可通过20目筛,以便后续使用标准方法检测样本中DON含量,取出研磨后的全麦粉,混匀,置于直径60 mm、高10 mm的培养皿中,将称量纸附在培养皿中的全麦粉表面起隔离作用,再用塑料平板将培养皿中的全麦粉压平,使全麦粉表面高度与培养皿边缘持平,用于光谱数据采集。
1.2.2 图像获取与标定
高光谱成像光谱仪的成像波段是1 000~ 2 500 nm,光谱分辨率为12 nm,采样率为5.6 nm,像元数为384×288。在高光谱图像数据获取前,打开高光谱成像系统的光源预热30 min。为了得到清晰无畸变的图像,多次调整试验系统参数后将曝光时间设置为10 ms,传送带移动速度为0.36 deg·s-1,样本距镜头310 mm。采集光谱前,需要对仪器进行黑白校正,以减弱光谱仪中暗电流对图像的影响。首先采集反射率为99%的白板漫反射图像,记为W,然后盖上镜头盖采集暗图像,记为B,根据式(1)计算原始漫反射图像R的校正图像Rt:
Rt=(R-B)/(W-B)×100%
(1)
1.2.3 ROI的选取与高光谱数据提取
将采集到的高光谱图像用ENVI 4.8(美国 Exelis Visual Information Solutions公司)进行感兴趣区域(region of interest,ROI)提取。沿图像中每个培养皿的轮廓手动选取轮廓以内的全麦粉作为每个样本的感兴趣区域。将每个样本ROI区域的平均反射率值作为该样本的原始光谱数据,后续数据分析在MATLAB 2014a(美国 The MathWorks公司)软件中完成。
1.2.4 DON毒素含量的测定
采集完高光谱图像后,参考SN/T3137-2012标准中规定的液相色谱-质谱法定量检测每个样本中的DON含量,作为每个样本的理化参考值。提取液由乙腈和水按 84∶16的比例配置,离心时转速为2 500 r·min-1,活化时使用3 mL提取液,提取的样本过柱时的流速为1 mL·min-1。利用型号为3500QTRAP色谱仪-液相色谱质谱联用仪(ABSCIEX公司)进行毒素含量测定,流动相A为5 mmol·L-1的醋酸铵水,按照时间0、3、7、13、13.1、16 min时,流动相A和流动相B分别按照85∶15、30∶70、20∶80、10∶90、85∶15、 85∶15的浓度梯度进行操作,流速为0.6 mL·min-1,进样量为5 μL。毒素检出限为20 μg·kg-1。
1.3 特征变量提取
SPA采用连续投影策略进行变量排序产生一系列变量子集,然后通过比较变量子集模型的预测能力筛选出最优变量子集,能最大限度降低被选变量间的共线性[20]。但对于近红外高光谱而言,有效变量间的投影距离并不一定最大,SPA筛选出的变量子集中可能包含一些无信息甚至是干扰变量[21]。ICO是基于模型集群分析策略(MPA)开发出的变量选择方法,MPA强调从数据集中挖掘有效信息时,应分析大量随机产生的子集模型信息而非单一模型信息[21]。高光谱包含丰富的样本数据,同时也不可避免地包含较多噪声,ICO作为基于柔性收缩策略进行波长区间组合优化的算法,采用波长区间替换波长点作为优化对象,一些与待测指标可能存在偶然相关性的噪声波长点会因为所在光谱区间的重要性不足而被排除,从而能够减少偶然误差,更稳妥地保留反映真实样本信息的有效波长区间。区间挑选算法选择的波长数量一般较多,不便于快速预测,最终选中的变量区间可以采用单一变量选择算法进行精简[22]。将ICO选择的优化组合区间结合SPA进行特征波长提取,既能有效地锁定特征波段区间,又能够减少有效区间内特征变量的冗余,形成优势互补。
1.3.1 连续投影算法(SPA)
设光谱矩阵为XM×J(M为样本数,J为波长数),记xk(0)为初始波长迭代向量,N为需要提取的波长变量个数,该算法从一个波长开始,计算它在未选入波长上的投影,将投影向量最大的波长引入到波长组合,直到循环N次结束计算。具体步骤[23]如下:
(1)第1次迭代之前(n=1),在训练集光谱矩阵X中任选一个列向量xj,记为xk(0);
(2)令S为所有未被选入的波长变量的集合,S={j,1≤j≤J,j∉{k(0),k(1),…k(n-1)}};
(3)利用式(2)计算xj对S中向量的投影:
(2)
(4)根据式(3)获得投影值范数最大的波长 位置:
k(n)=arg(max|Pxj|,j∈S)
(3)
(5)根据将最大投影向量作为下轮的投影向量:xj=Pxj,j∈S;
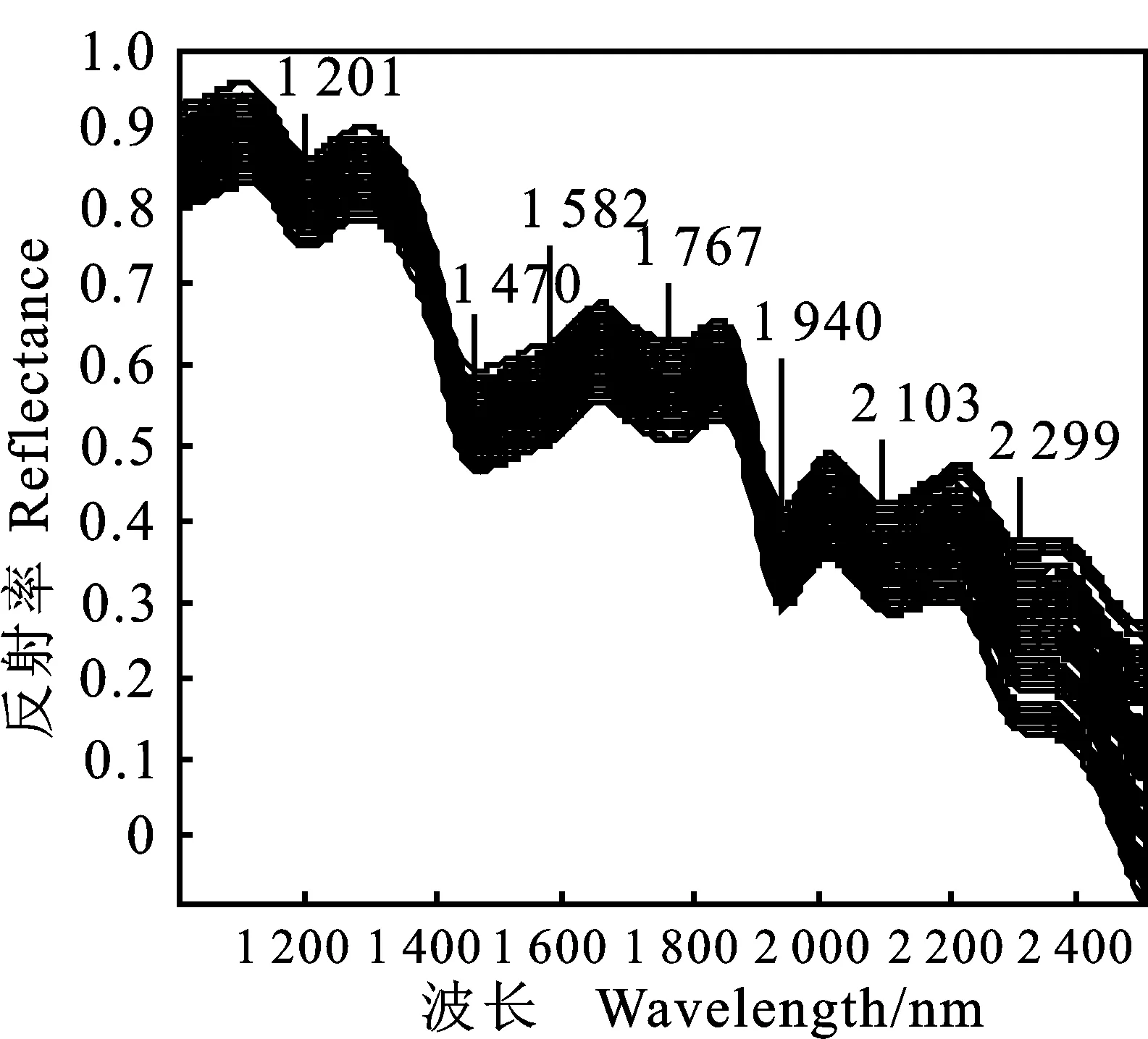
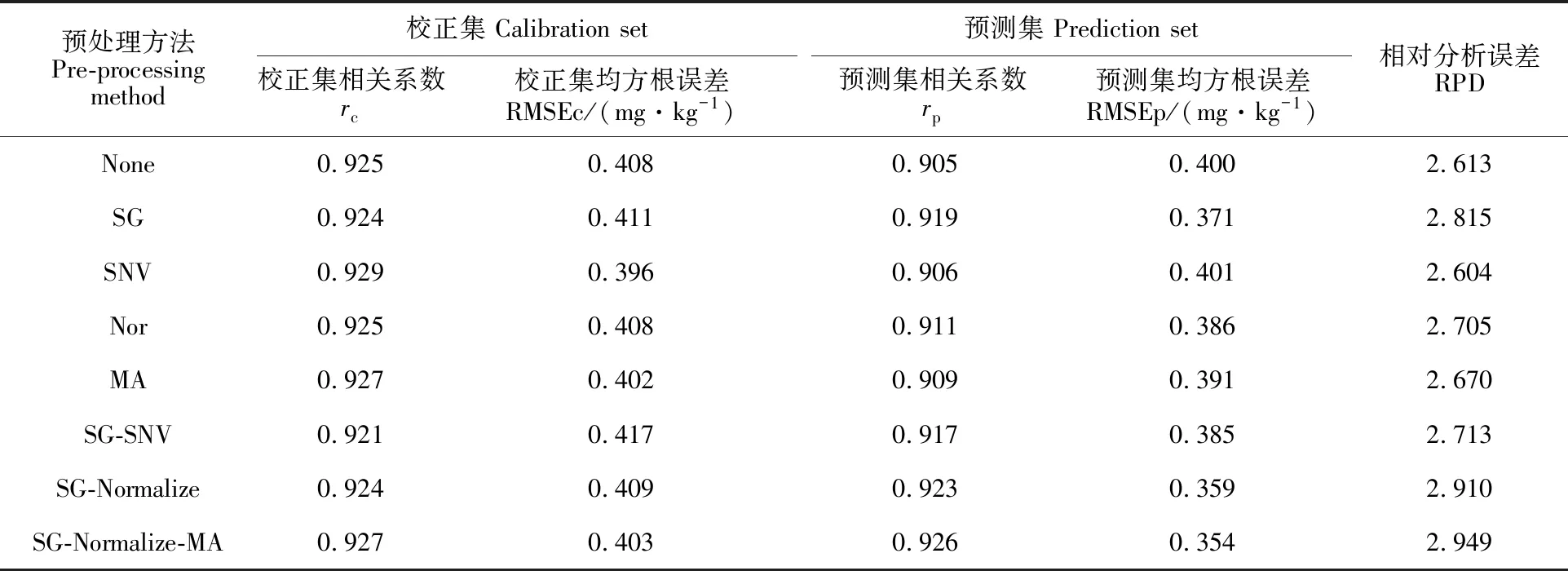
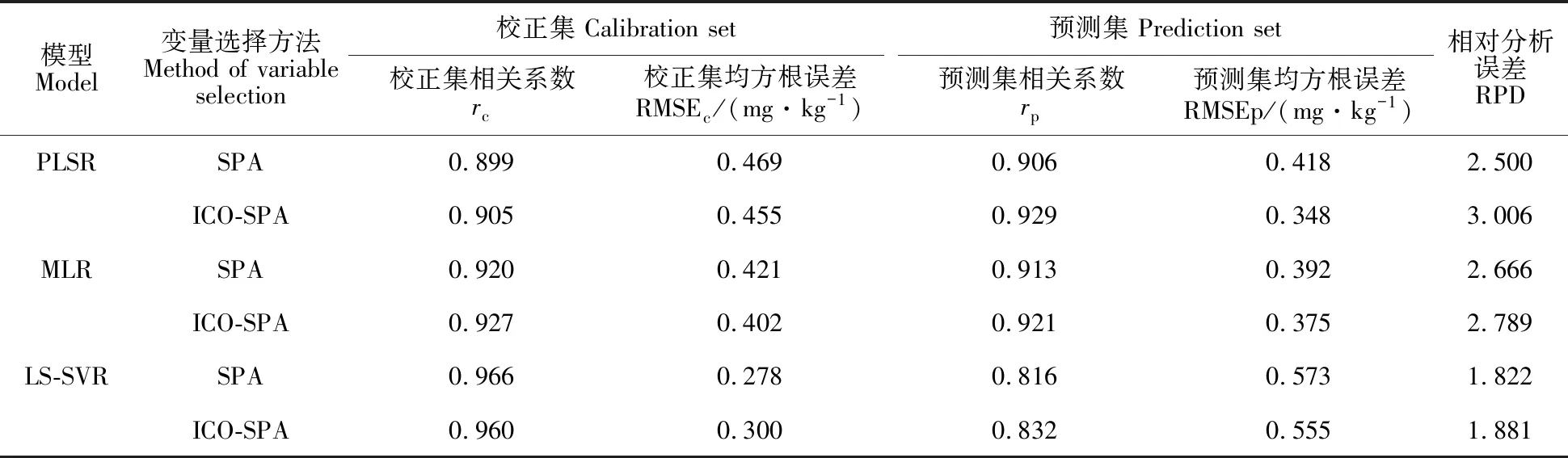
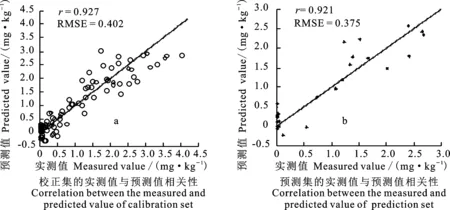
(6)令n=n+1,若n 1.3.2 区间组合优化算法(ICO) ICO算法首先采用软收缩的方式对波长区间组合进行优化,然后采用局部捜索的方式对最终入选区间的宽度进行自动优化,运算过程[24]如下: (1)将样本的近红外光谱划分为宽度大体相当的N等份,每一份即为一个光谱区间; (2)采用加权自举采样(WBS)生成M个不同波长区间随机组合形成的子集,每个波长点初始采样权重都默认为1; (3)采用PLS算法和5折交互检验的方式计算每个区间组合子集对应的RMSECV值; (4)从全部区间组合中提取一定比例(记作α)的最优区间组合子集(α通常可设置为0.1,也可根据数据的实际情况进行优化),并计算出这一部分区间组合子集对应RMSECV的平均值; (5)统计每个区间在那一部分最优区间组合中出现的数目,下一次迭代中第i个区间对应的采样权重可以通过式(4)计算出来: (4) 其中fi是第i个区间在最优区间组合中出现的频次,kbest是提取的最优区间组合的数目; (6)重复步骤2~5形成迭代循环,直到RMSECV平均值出现上升,迭代终止; (7)在最后一次迭代中,RMSECV值最小的那一组波长区间被视为最终选中的波长区间; (8)采用局部捜索策略对步骤7中选出各个波长区间的宽度进行优化。在此策略中,各个被选中波长区间边缘相邻的波长点逐一被纳入或排除建模,并根据该波长点对模型RMSECV值的影响情况进行评价。如果一个相邻波长点的纳入会使模型的RMSECV值下降,则该波长点被选入,反之则被剔除。反复在每次优化后区间上进行局部捜索,直到没有新波长点能够对模型的RMSECV值产生影响,这个时候优化出的区间则可以被视为ICO算法最终选中的波长区间。 1.4.1 异常样本的剔除与光谱数据集划分 异常样本的存在影响定标模型的预测性能和适配性。为避免异常样本对模型精度的干扰,通过基于XY变量联合的异常数据检测算法(outlier sample eliminating algorithm based on joint XY distances,ODXY)[25]剔除异常样本3个。采用基于光谱-理化值共生距离算法(sample set partitioning based on joint X-Y distances,SPXY)[26-27],从样本集中筛选校正集样本。对117个样本按照SPXY算法以3∶1比例划分校正集和预测集,得到校正集样本89个,预测集样本28个,并且DON含量最大值和最小值对应的样本均落在校正集中。 1.4.2 光谱预处理 为减少电噪音、光散射、基线漂移等干扰对光谱数据的影响,本研究采用Savitzky-Golay(SG)平滑、标准正态变量(standard normal variable,SNV)、矢量归一化(normalize)、移动平均算法(moving average,MA)、SG-SNV、SG-Normalize、SG-Normalize-MA等7种算法分别对原始光谱进行预处理,再根据PLSR模型的效果寻找最合适的光谱预处理方法。 1.4.3 模型建立与评价 分别将SPA和ICO-SPA提取的特征变量作为输入建立PLSR、MLR、LS-SVR模型预测样本中DON含量,比较模型性能选取最优模型。模型性能利用以下指标进行评价:校正集相关系数(rc)、校正集均方根误差(root mean square error of calibration,RMSEc)、预测集相关系数(rp)、预测集均方根误差(root mean square error of prediction,RMSEP)、交叉验证均方根误差(RMSECV)和预测相对分析误差(residual predictive deviation,RPD)。相关系数越大,均方根误差越小,所建模型性能越好。当RPD值为1.5~2.0时仅能够区分响应变量的低值和高值;当RPD值为2.0~2.5时能够粗略地定量预测;当RPD值为2.5~3.0或者更高时模型预测精度较高[28]。 试验所采用的光谱仪采集的波长范围为 920~2 528 nm,由于存在系统误差,光谱曲线在首尾端可能存在较大噪声,会直接影响试验的准确性,因此数据处理时取1 000~2 500 nm波段的268个波长的光谱数据作为后续数据处理区域。在图1的样本光谱曲线上,在1 470、1 940 nm处出现明显吸收峰,反映麦粉样本中水分对光谱的影响[8];1 201 nm与脂肪的C-H弯曲振动2倍频带1 195 nm接近[29];1 582 nm与淀粉的特征峰 1 550 nm接近[30];1 767 nm与纤维素C-H弯曲振动1倍频带1 780 nm接近[29]; 2 103 nm与多糖的O-H伸缩和C-O伸缩振动组合频带 2 100 nm接近[29];2 299 nm与蛋白酰胺的C-H伸缩振动二倍频带2 300 nm接近[29]。这说明样本反射光谱曲线反映了试验样本中的淀粉、蛋白质、脂肪、纤维素等大分子成分的含量 信息。 图1 近红外波段下全部小麦赤霉病籽粒样本反射光谱曲线 从光谱经过不同预处理后建立的PLSR模型(表1)看,SG-Normalize-MA的PLSR模型最好,建模的相关系数和均方根误差分别为0.927和0.402 mg·kg-1,模型拟合性较好;预测集的相关系数和均方根误差分别为 0.926和0.354 mg·kg-1,相对分析误差为 2.949,说明模型有较高预测精度。因此,最终选取SG-Normalize-MA处理后的光谱数据进行后续处理。 1 000~2 500 nm采集的光谱共包含268个波段。为简化建模过程,加快计算速度,提高模型的预测能力,需要提取光谱的特征波段,压缩光谱数据,以实现对DON含量的快速定量检测。本研究分别采用SPA及ICO-SPA算法筛选获得特征波段,再根据反映的物质信息结合所建模型的预测准确率判断所提特征波长的合理性。 2.3.1 基于SPA算法的特征波长筛选 设定波长数N的范围为1~25,根据交叉验证均方根误差RMSECV值确定最佳的波长变量个数。从图2a可以看出,随着波长个数的增加,RMSECV值逐渐减小;当波长个数大于16时,RMSECV值变化不再显著,此时RMSECV为 0.544。波长过多时易增加模型的运算量及复杂度,因此本研究选取16个波长作为最终特征波长,依次为1 223、1 285、1 347、1 414、1 526、 1 587、1 660、1 700、1 772、1 812、1 907、1 946、 2 047、2 092、2 137、2 215 nm,所选波长位置如图2b,这些特征波段能够反映小麦蛋白质 (1 526、 1 587、2 047)、脂肪(1 223、1 414、2 137 nm)、纤维素(1 772、1 812 nm)和水(1 946、2 092 nm)等大分子有机物的含量信息[29]。 表1 不同预处理方法的PLSR预测模型Table 1 PLSR prediction models for different pre-processing methods 图2 SPA变量选择 2.3.2 基于ICO-SPA算法的特征波长筛选 基于ICO算法,利用5折交叉验证方法建立PLS模型选择特征变量。PLS模型中最大潜变量数为10,加权自举采样次数为1 000,所选子模型的比例为0.01,等间距光谱间隔的数量为40。图3a为ICO算法迭代过程中每个波长区间的采样权重随迭代次数增加的变化的情况。其中,颜色越红,采样权重值越接近于1;颜色越蓝,采样权重值越接近于0;如果颜色介于深蓝色和深红色之间,则采样权重值处于0和1之间。 从图3a可以看出,第9个波长区间在第1~5次迭代过程中颜色偏绿蓝,权重系数约为0.3~0.5,但是在第6次迭代过程中权重系数仍有机会变大,最终被选中。该区间包含淀粉的O-H伸缩振动1倍频带(1 490 nm)[29],是进行DON定量检测重要依据。第14个波长区间的采样权重值在第1次迭代过程中已经变为1,其采样权重值在第2次迭代过程中依然有可能变得小于1,最终该区间由于权重过小被淘汰。由图3b看出,经过8次迭代后均方根误差趋于稳定,此时其值 0.520。最终,在ICO挑选的特征波长区间内,共挑选了22个特征波长 (1 083、1 089、1 100、 1 117、1 137、1 145、1 156、 1 319、1 324、1 335、 1 347、1 363、1 375、1 380、 1 475、1 487、1 498、 1 711、1 722、1 733、1 739、 2 445 nm)(图4),这些基于ICO-SPA提取出的特征波波段也可反映小麦赤霉病籽粒中淀粉、蛋白质、脂肪、纤维素等有机物大分子含量的特征[29,31]。 图3 ICO变量选择 图4 ICO-SPA变量选择 Fig.4 Variable selection by ICO-SPA 将SPA挑选出的16个敏感波长和ICO-SPA优选出的22个敏感波长作为输入变量,分别使用PLSR、MLR、LS-SVR 3种方法对DON含量进行建模,结果(表2)表明,基于两种特征波长的MLR模型的RPD均达到2.5以上,建模效果比LS-SVR(RPD低于2)好,且不存在PLSR模型中出现的欠拟合现象。PLSR模型出现的欠拟合现象可能是由于提取的特征变量过少,后期可以考虑增加新的特征或特征组合用于增大假设空间,减小欠拟合现象。所建模型中,ICO-SPA-MLR模型预测效果最优,预测集相关系数rp为0.921,相对分析误差为2.789,大于 2.5,能实现精准预测,且预测效果与全波段的PLSR模型建模效果相当(rp=0.926,RPD=2.949)。基于ICO-SPA提取的22个敏感波长建立的MLR模型预测效果与基于全波段268个波长建立的PLSR模型相当,说明ICO-SPA是一种有效的特征波长挑选方法,结合MLR模型能够接近全波段的预测效果。另外,基于ICO-SPA建立的PLSR、MLR、LS-SVR模型相较于基于SPA建立的PLSR、MLR、LS-SVR模型,其rp分别提高了 2.3%、0.7%、1.6%,RMSEp分别下降了 0.070、0.017、0.018 mg·kg-1,RPD分别提高了 0.506、0.123、0.059,表明ICO-SPA筛选出的变量有效性比SPA高,在ICO选定的有效区间上进行SPA特征波长挑选,最终获得的特征变量既有效又精简。ICO-SPA比SPA多提取了淀粉含量的信息,对于控制在同一水平的水分含量信息,ICO-SPA没有提取,表明淀粉含量信息的加入和水分含量信息的减少有助于DON含量 预测。 从图5可以看出,DON含量的实测值与预测值的相关性很好,数据集的预测样本点基本均匀分布在y=x线两侧,说明ICO-SPA-MLR预 测模型能够实现对样本中DON含量的定量 检测。 表2 三种定量模型预测结果Table 2 Prediction results with the three quantitative models 图5 小麦赤霉病籽粒中DON含量的ICO-SPA-MLR预测模型 本研究是在小麦赤霉病病害发生后,通过近红外高光谱技术预测小麦赤霉病粒中的DON含量,与国家标准中的相关限量比对,确认该批小麦是否安全,以减小病粒对人畜健康的威胁,保证粮食食品安全;另外,面粉厂等大型小麦原粮收购单位一般会依据原粮的DON含量进行等级划分,不同等级的原粮存入不同的谷仓,传统的理化方法由于耗时较长,会严重延长原粮入库的时间,使用近红外高光谱的方法能够快速获得小麦籽粒的DON含量结果,从而指导原粮及时入库,减少对运粮车或运粮船的长时间占用,提高原粮收购单位的经济效益。 高光谱技术对光谱范围内的每一个波段进行成像,在获得样品外部特征信息的同时,还提供反映样品内部物理结构和化学成分的光谱信息,但因此产生的巨大的信息量一方面会影响检测速度,另一方面由于大量噪声或冗余信息的存在也会影响检测精度。为了简化近红外高光谱分析模型,提高检测的实时性和有效性,本研究分别采用连续投影算法(SPA)、区间组合优化结合连续投影算法(ICO-SPA)进行特征波长提取,结合偏最小二乘回归(PLSR)、多元线性回归(MLR)和最小二乘支持向量机回归(LS-SVR)模型,比较两种特征波长提取方法输入三种模型后的预测效果,结果表明,ICO算法的引入有助于提高SPA算法所选波长的有效性,基于ICO-SPA挑选出的特征波长作为输入变量建立的模型可以用来进行小麦赤霉病籽粒样本的DON含量预测,其中最优模型为基于ICO-SPA提取的特征波段建立的MLR模型,预测集相关系数为0.921,预测集均方根误差为0.375 mg·kg-1,相对分析误差为2.789,大于2.5,预测精度略高于前人的研究结果[10-11]。这种将光谱区间挑选算法与单一波长挑选算法联合使用的策略充分利用了算法之间优势的互补性,因此所建模型的预测效果比算法单独使用时有所提升。 在特征波长挑选之前一般要对光谱进行预处理,光谱预处理方法不仅会影响模型的预测性能,还会影响变量选择算法的结果[22,32]。对SG-Normal-ize-MA预处理后的光谱进行ICO-SPA特征波长提取,所得特征波长能较充分地反映试验样本中各有机物成分含量差异,但是光谱预处理方法的组合及运算顺序仍需要配合变量选择算法作进一步优化,这一问题有待进一步探索。本研究针对小麦品种烟农19进行小麦赤霉病粒DON含量预测试验,ICO-SPA的特征波长挑选算法获得了让人满意的结果,若换成其他小麦品种,ICO-SPA的效果如何有待进一步的研究和验证,后期还可以进行多个品种混合的小麦赤霉病籽粒DON含量预测,从而提高先进技术和算法对于粮食食品安全以及原粮收购单位经济效益的应用价值。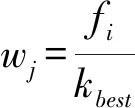
1.4 建模方法与模型评价
2 结果与分析
2.1 样本光谱特征
2.2 光谱预处理效果比较
2.3 样本特征波长提取



2.4 建模方法优选
3 讨 论
猜你喜欢
中学数学研究(广东)(2023年9期)2023-06-03 03:32:40
特产研究(2022年6期)2023-01-17 05:06:16
中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:48
天津农林科技(2022年2期)2022-04-19 10:48:18
今日农业(2021年9期)2021-11-26 07:41:24
农药科学与管理(2019年5期)2019-08-13 00:47:58
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
中国照明(2016年4期)2016-05-17 06:16:15
食品界(2016年4期)2016-02-27 07:36:41
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
