
基于故障树的事故分类方法①
2019-07-23 02:08刘康炜万剑华靳熙芳
计算机系统应用 2019年6期
刘康炜,万剑华,靳熙芳
1(中国石油大学(华东)地球科学与技术学院,青岛 266580)
2(中国石化青岛安全工程研究院,青岛 266071)
由于化工生产工艺复杂、自动化控制水平高,事故形成的机理难以捕获且多数发现事故征兆后便难以控制,如何能够汇总历史事故原因机理,进行事故原因的精确分析,尽早发现事故潜在的隐患,将有助于事故预警和预防.然而,虽然形成了大量事故的分析报告,但并没有形成事故相关成因机理的提炼和汇总,难以形成事故分析有效的知识库.同时,化工事故分析专家也基于经验以故障树、FME(C)A 等安全分析模型建模了大量同类事故的成因机理[1],如何基于这些专家经验对事故报告进行快速准确的原因分类,将有助于形成辅助事故分析与决策支持的知识库,实现化工事故的早期预警和预防.由于事故报告、故障树等事故分析模型的表达都是基于自然语言,自然语言的分类技术在各领域已有广泛的研究,如,贝叶斯分类改进方法[2]采用文本中高词频特征的对数平均计算方法,解决了文本分类中参数估计不足问题,但只是单纯使用分类技术,没有探讨文本所含领域模型问题;优化的SVM 故障分类器[3]采用了RS 约简故障指标体系,去除了冗余特征,但是割裂了故障过程间的演化关系;决策树、神经网络等[4,5]改进分类方法基于统计模型、语言模型,主要处理文本的层次化分类问题,可以实现火灾、中毒、爆炸等化工事故的粗略分类,但不能根据事故模型探讨事故成因机理,事故成因机理需要结合专家的领域经验进一步分析、分类.在化工事故分析领域,故障树是一种演绎式失效分析模型,能通过逻辑门连接事故成因关系展示事故成因的演化过程[6].通过割集技术可以实现事故成因的最底层原因分析、也可以实现事故的定量分析和定性分析[7].本文基于化工事故监管部门形成了大量的事故故障树,这些故障树已通过领域专家实现面向事故成因机理分析、并进一步实现同类故障树的成因机理的汇总,形成包含同类事故所有原因的若干标准故障树[8].基于标准故障树,研究事故报告的事故成因精确分类分析,不仅可以准确分类事故报告的类别,也能够对事故报告描述的事故成因进行精确分析,从而能够实现面向事故成因机理的有效分析、分类、存储和管理,逐步完善事故分析与决策支持的知识库,实现化工事故的早期预警和预防.
1 面向故障树的文本分类算法
基于故障树模型的事故成因机理分析,考虑到化工事故的实际特征,故障树的逻辑门仅包含与、或两种门结构.目前本文工作中合作的化工事故监管部门已经形成了大量的事故故障树,并综合同类故障树的成因机理形成该类型的标准故障树如图1,为自然着火型标准故障树的示意图.
事故报告是通过专家对事故进行调查分析,形成的包含事故经过、事故原因、事故处置、事故总结和事故影响五部分的事故调查报告,里面含有事故形成的各种信息,但也有各种杂音信息,目前收集化工事故监管部门已经形成了10 023 个事故报告,已经粗略分类归属于火灾、爆炸、中毒、泄漏等4 类事故,如何根据事故成因将事故报告精确归因于某类标准故障树,是进一步研究事故成因的自动分析和识别的关键技术.
1.1 基于自然语言处理的特征提取技术
事故报告与故障树节点都是采用自然语言描述的,需要研究文本的特征向量生成方法.由于事故报告包含大量的无关、杂音字词,首先根据百度停留词库进行去停留词处理.采用将词嵌入向量生成算法与TFIDF 方法结合生成分词特征向量[9],采用Word2Vec CBOW 模型生成P维词向量Vec(wj)=(v1,v2,…,vP)本文取P=1000.由于Word2Vec 采用通用领域词汇进行向量训练,为突出领域词汇的作用,计算事故报告、故障树节点中领域词的TF-IDF 值,作为词向量的权重,从而实现了文本向量化既考虑词的语义信息,也能考虑领域词的重要度信息.采用如下计算公式生成词的TF-IDF 值:
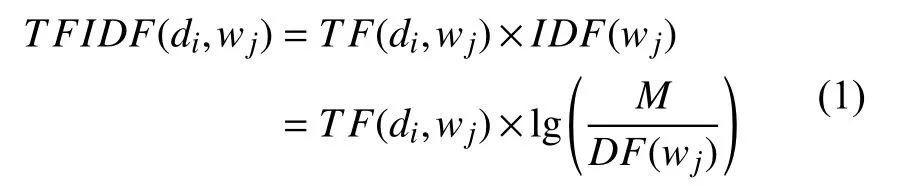
其中,TF(di,wj)表示词wj在文本di中出现的频率.IDF(wj)表示单词wj的逆文档频率.M表示文本总数.DF(wj)表示出现wj单词的文本个数.则包含TFIDF 的词向量为:

则文本di制成相应的向量为:

图1 自然着火型标准故障树
1.2 扩展割集的生成算法
典型的故障树分析多通过分析故障树的最小割集和最小径集[7,10],然而这种分析方法是分析故障树的叶子节点,而无法分析事故成因过程,无法实现事故报告的精确归类,提出了一种面向故障树全部节点的层次析取范式的算法,即可以计算出以基本事件为基准扩展可能的中间节点,而形成的故障树扩展割集.

图2 事故报告的词向量特征生成部分结果
本文扩展下行法、采用广度优先逐层替代计算扩展割集.核心思想:根据故障树逻辑门符号一层层向下判定,即遇到“与”门,将“与”门的上层节点替换为“与”门的所有下层节点,并将替换后的结果加入范式集合;遇到“或”门,将“或”门的上层节点依次替换为“或”门的下层节点,并将替换后的结果加入范式集合.求解故障树的扩展割集CS,算法步骤如下:
Step 1.对故障树每个节点进行预处理.读入树节点Ti,将每个树节点Ti表示为该子树的根节点的文本Wi、孩子节点个数Ni、逻辑门符号Si、孩子节点的文本的集合Cj.其中0≤j≤Ni.即Ti=(Wi,Ni,Si,Cj),0≤j≤Ni.
Step 2.读入故障树的根节点T1,并根据其逻辑门S1进行处理.若是“与”门,则根节点加入集合、将根节点替换为“与”门所有的下层节点Cj,并加入集合,CS=(W1,C1,C2,…,CNi);若是“或”门,则根节点加入集合、将根节点依次替换为“或”门的下层节点Cj,并依次加入集合,CS=(W1,C1,C2,…,CNi).
Step 3.读入故障树的下一个节点Ti=(Wi,Ni,Si,Cj),并根据逻辑门Si进行处理.若是“与”门,则寻找集合CS中存在的与节点文本Wi相同的树节点Te,并用“与”门的所有下层节点Cj替换集合中的树节点文本We,替换后的结果加入结果集CS,CS= (W1,W2,…,We)=CS= (W1,W2,…,C1,C2,…,CNi).若是“或”门,则寻找集合CS中存在的与节点文本相同的树节点Te,并用“或”门的下层节点Cj依次替换集合中的树节点文本We,替换后的结果加入结果集CS,CS= (W1,W2,…,We)=CS= (W1,W2,…,C1,C2,…,CNi).
Step 4.重复Step 3,直到所有的节点Ti都读完,即能求出故障树故障发生的所有扩展割集CS=(W1,W2,…,We).

图3 算法生成的图1故障树的扩展割集
每一个故障树都通过扩展割集算法的计算,形成了大量扩展割集形成的词库集合,通过文本向量生成算法,计算出每个扩展割集的向量空间.这些向量空间也是事故报告分类的中心,需要采用合适的分类算法经每个事故报告分类到相应的扩展割集中,从而能够精确分析到事故报告描述的事故成因机理.本文在计算事故报告提取文本特征与扩展故障树割集的相似度计算方法采用的是,较为成熟的KNN 方法[2,3,9].
1.3 基于权重调整的KNN-W 的事故报告分类方法
本文将事故分析报告和故障树扩展割集的余弦相似度作为距离衡量标志,余弦相似度越大说明两类向量距离越近.标准的KNN 分类方法(记为KNN-S),当样本数量分布不平衡时,实验结果明显偏重于数量多的类[11].由于故障树的扩展割集不唯一,而且每个故障树的割集个数都不相同,会导致样本分布不均匀,从而会导致KNN 分类方法的准确度下降.改进的KNNW 分类方法,充分解决了KNN-S 分类方法中非平衡化样本干扰的难题,并在KNN-S 分类方法的基础上,根据采集样本所属的大类别数目和标准树所包含的扩展割集数目设计权重约束,实现了对KNN-S 分类方法中样本分布不平衡的调节,还在一定程度上提高了事故报告分类的精确度.采用基于权重计算的KNN-W 的算法步骤如下:
Step 1.利用式(3)计算事故分析报告文本向量VecT(d)=(v1,v2,…,vK)与每类故障树的扩展割集向量VecT(CSj)=(cj1,cj2,…,cjK)的余弦相似度c osθj.

Step 2.将所求得的余弦相似度c osθj设置权重weight;加权结果为 cosθj=cosθj×weight,其 中weight=Countj(D)为属于扩展割集CSj所在大类的事故报告数,Countj(CS)为属于扩展割集CSj所在故障树的扩展割集数,即权重与属于类别的事故报告数成正比,与所属类别的故障树扩展割集成反比.
Step 3.将加权余弦值排序,统计K个余弦值cosθj当中每类故障树所占的比重.比重最大的故障树即为所求的该事故报告的类别.
上述基于权重计算的KNN-W 相比于KNN-S 分类方法,充分考虑了样本所属领域的大类别数目,结合样本数据中故障树模型的扩展割集结构分布,利用权重调剂不平衡分类的比例,降低已有类别的故障树割集比重,增加待分类的样本比例权重,使分类方法能够适应不同事故数据集.
2 实验结果与分析
随机选取事故监管部门提供的1000 份事故报告作为事故原因分析待分类的对象,由于报告中的事故处置、事故总结和事故影响不能支撑事故原因分析,首先对事故报告进行预处理,只获取事故经过和事故原因分析两部分文本内容进行文本特征提取,通过贝叶斯方法配合人工确认对这1000 篇事故已经进行了粗略分类,分类结果如表1所示.
基于事故监管部门提供的11 类标准故障树,利用扩展割集算法计算11 个标准故障树的扩展割集,表2为标准的结构信息和通过算法计算的扩展割集信息.这些扩展割集包含事故形成的充分条件,如果事故报告中隐含了相应的割集信息,则表示该事故包含该事故成因信息,这样可以通过分析事故成因来确定事故报告的精确分类.

表1 事故报告粗略分类
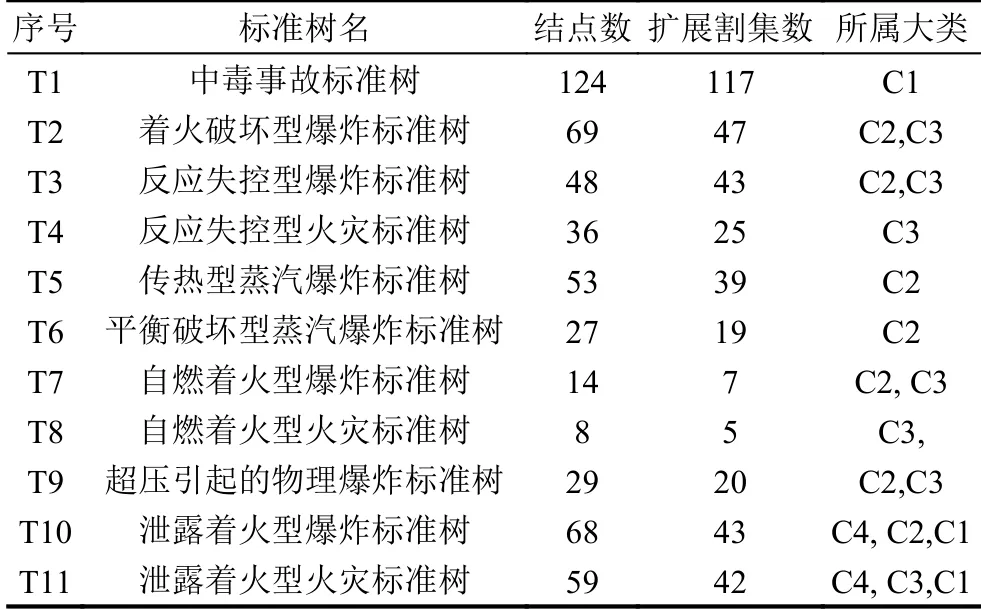
表2 标准故障树的结构信息
在算法设计中,首先采用本文提出的结合树形复杂性和文章分类数的权值调整KNN-W 算法,取K=20 进行实验,表3给出识别的每类标准树所包含的通过算法识别数目,实际应该包含的数目,正确识别的数目,并给出每类故障树的识别的准确率、召回率和F1 值[3,4,10],通过分析发现在样本集较大,故障树结构较复杂的标准树中,整体性能要好于标准树结构简单的分类,算法总体的准确性为89.6%.
为了验证本文提出的的权值调整算法的性能,在对比实验中,采用标准KNN-S 方法和2.3 算法进行对比实验,两类方法的K值分别为10、20、50 进行分析,每一类的F1 值的对比结果如图3所示.表4给出每次实验的各故障树类的平均F1 值,从算法对比分析,可以看出KNN-W 算法整体性能较KNN-S 有不同程度的提高,从K值选择分析可以看出,K=2 0 较K=10 有较大提升,但K=50 较K=20 提升较少.

表3 KNN-W 算法性能分析
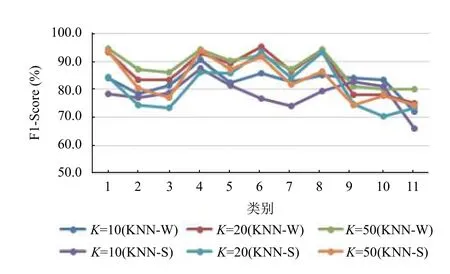
图4 KNN-W 与KNN-S 的F1-Score 对比结果
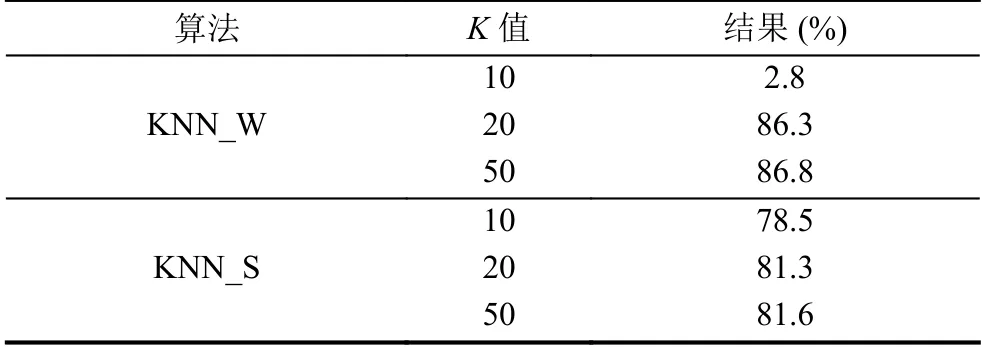
表4 平均指标数据对比
3 总结
直接应用机器学习分类方法难以有效分析领域问题,针对化工事故分析领域,提出一种结合领域专家经验的分析模型进行事故精确分析的思路,基于故障树分析的事故模型,设计故障树的扩展割集,使故障成因的充分必要条件不仅反馈在叶子节点的集合,也反馈到包含中间节点的所有节点组合,这样可以检测出事故报告中描述的事故演化过程,在分类算法上,选择KNN 方法,并根据分类特点改进KNN 算法使其更能有效进行分类,实验结果表明所设计算法能够实现较精确的分类.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
科学家(2022年3期)2022-04-11
甘肃教育(2021年10期)2021-11-02
计算机应用与软件(2021年10期)2021-10-15
科学与财富(2021年36期)2021-05-10
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
智富时代(2018年7期)2018-09-03
