
基于聚类分析和XGBoost算法的换机预测模型
2019-07-12 06:13:40卢光跃吕少卿闫真光
西安邮电大学学报 2019年2期
卢光跃, 吴 洋, 吕少卿, 闫真光
(西安邮电大学 陕西省信息通信网络及安全重点实验室, 陕西 西安 710121)
随着移动通信技术的发展和智能手机的普及,用户更换手机的周期逐渐缩短。为了减少不必要的服务成本,运用数据挖掘的方法分析电信用户数据,并在电信用户数据集上训练出分类器,建立换机预测模型,从而区分有意向换机的用户,对其进行换机服务[1-2]。
电信用户数据集存在异常值和正、负样本不平衡等问题。排查用户数据集中的异常用户数据,可提高分类器的预测准确率[3]。过抽样和欠抽样算法通过改变原始数据集的大小,可获得一个等比例的平衡[4]。但是,过抽样算法只能简单地从原始数据集中随机挑选数据,将产生的副本加入到数据集中,存在部分样本实例重复并列的问题,可能会导致分类器训练过程中出现过拟合现象;而欠抽样算法对多数类样本的随机删除,可能会导致分类器无法学习某些多数类的重要信息[5-6]。
针对上述问题,本文建立一种换机预测模型。利用孤立森林算法[7]进行异常值检测;采用K-Medoids聚类[8]的方法综合多方面特征对用户进行精细划分;结合组合采样的人工合成少数类算法(synthetic minority oversampling technique, SMOTE)和Tomek算法[9-11],处理数据集的不平衡问题,改善欠采样和过采样算法的缺陷。最后,采用集成提升决策树(gradient boosting decision trees, GBDT)的改进算法XGBoost[12]进行训练,将电信用户分配到对应的模型中,进而预测用户换机意向。
1 换机预测模型
电信用户数据包括用户的身份属性信息、通信消费信息、手机使用信息和业务信息。身份属性包括用户性别、号码、年龄和入网时间;通信消费信息包括总使用流量、通话时长、总出账收入、流量收入、套包收入和通话收入;手机使用信息包括国际移动设备标识码(international mobile equipment identity,IMEI)、手机支持网别、手机类型、手机品牌和手机型号;业务信息包括用户套餐和运营商定制机信息。通过分析和处理电信用户数据,在用户的历史行为数据上训练模型,进而预测用户是否换机。
1.1 模型的构建
利用孤立森林算法排查数据集的异常值;将排查后的数据集通过K-Medoids聚类分析精细划分为若干个用户簇,采用SMOTE和Tomek组合采样的方法对每个簇中的用户数据进行平衡,最后在各个用户簇数据中使用XGBoost算法训练得出模型。换机预测模型构建流程如图1所示。

图1 换机预测模型构建流程
1.2 孤立森林排查异常值
将电信用户每个月的年龄、网龄、历史换机次数、总使用流量、通话时长、套包费、通话收入和总出账收入的均值和方差作为数据样本,输入孤立森林中进行异常用户排除。
选取100个孤立树组成孤立森林,每个孤立树为二叉树结构,最高深度设为8层,随机依次选取256个样本点放入树的根节点。将数据样本从根节点归类到最终所属叶子节点过程的分割次数,记为路径长度。对100个孤立树集体为样本数据生成的路径长度取平均值,并进行归一化处理。若样本的平均路径长度接近0,则该样本为异常值的可能性越大,故设定阈值为0.1,将平均路径长度低于0.1的样本视为异常点,即可排查与换机预测无关的异常电信用户。
1.3 聚类分析细化用户
将异常电信用户排除后的数据作为聚类分析的输入,结合电信用户数据特征,使用K-Medoids聚类法[8]进行用户细分。选取k=3为最佳聚类数,使得平均轮廓宽度值最大[13]。首先随机选取3个初始中心点和初始簇,计算初始簇中其他所有点到3个中心点的距离,并把每个点到3个中心点距离最短的簇,作为该点的所属簇。在每个簇中依次选取数据样本点,计算每个点到簇中所有点的距离之和,选取最终距离之和最小的点作为新的中心点,依此不断迭代该过程直至各个簇的中心点不再改变。由此以最终确定的3个中心点,将电信用户数据聚类划分为3个用户簇。
1.4 SMOTE和Tomek组合采样
对比用户手机IMEI的异同,获取电信用户的换机标签,3个用户簇中换机标签的比例都不平衡,故采用SMOTE和Tomek link组合采样方法进行处理。SMOTE是通过在一些邻近的少数类样本中,产成新的虚拟样本以处理类别间的不平衡问题,相比较过采样的方法,它不是直接复制重叠的少数类样本,可以一定程度上避免分类器的过拟合问题和规则化。具体实现步骤如下。
协议书模板分为有界桩的界线协议书、无界桩的界线协议书2个模板,分别包括封面、协议主体内容、界线所涉及乡镇政府代表签字3个部分。协议书主体内容包含工作概况、重要问题处理结果、行政区域界线走向和界桩位置说明、行政区域界线的维护和管理、最后条款(补充说明)以及附件6个部分,其中附件包括了附图、界桩登记表、三交点界桩登记表、界桩成果表、界址点成果表、三交点成果表等内容。三交点协议书模板包含标题,协议内容,三交点的位置、坐标,底图所在的图幅以及所涉及的乡镇政府代表签字,所属县民政局代表签字和协议日期。
步骤1相对于多数类样本,设定少数类需合成对应的新样本数目为N。
步骤2搜索少数类样本中样本点x与其近邻的样本点集合,并从该集合中随机选择N个样本,记为t1,t2,…,tN。
步骤3随机选取样本点tj,将x和tj之间的连线上任意一点作为新合成的少数类样本[9]
rj=x+(tj-x)rand(0,1)。
其中rand(0,1)表示区间[0,1]内的随机数。
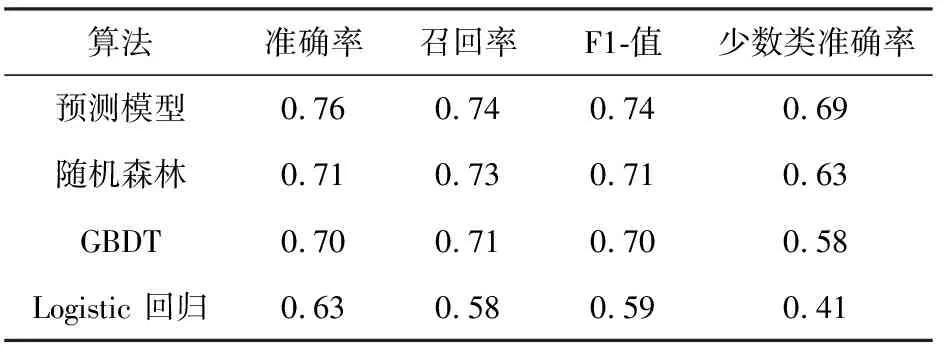
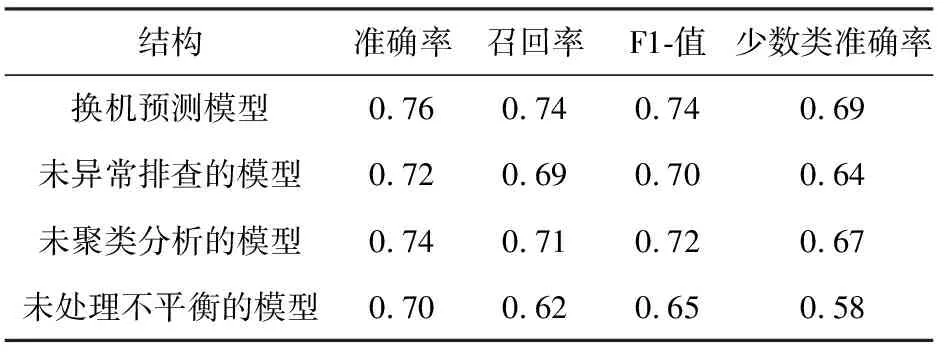
将少数类样本rj加入每个用户簇的原始数据中,组成新的3个用户簇。设每个用户簇中样本点xi和xj属于不同的类,计算该两个样本点之间的欧氏距离,记为d(xi,xj)。若用户簇中不存在样本点xe使得d(xe,xi) SMOTE与Tomek组合采样就是利用SMOTE方法合成新的少数类样本,得到新的用户簇,然后剔除该用户簇中的Tomek link对,使得3个用户簇中的换机标签平衡。 利用XGBoost[14]集成算法在平衡后的3个用户簇数据上进行训练。设每个用户簇中有n个样本和m个特征,记为D={(xi,yi)}(|D|=n,xi∈m,yi∈),其中yi为实际换机标签。根据XGBoost算法中决策树函数fk(x),预测换机标签其中k为迭代次数。 (1) 其中Υ为决策树的复杂度,λ为惩罚因子,T为决策树的叶子节点数目,ω为数据分到决策树中叶子节点的所在层数。 将式(1)进行二阶泰勒展开,则算法第k次的目标函数可近似[14]表示为 (2) 在模型训练阶段,每次迭代选择最优的fk(x),使得式(2)最小化。采用格式搜索的方法,将决策树fk(x)数目和树的最大深度作为寻优参数组合,在用户数据中训练得出每个参数组合的目标函数O1,O2,…,On,选取其中最小目标函数对应的参数组合作为模型的最优参数。根据此方法,在3个用户簇数据上训练得出3组最优参数,即3个最优换机预测模型。在实际应用中,将用户根据聚类分析得到的3个中心点分配到对应用户簇模型中,进而预测用户的换机标签。 选取某运营商10个月内12 000个用户的数据作为原始训练数据,并过滤掉129个字段信息缺失过多的数据。将11 871位电信用户的数据样本通过孤立森林检测出1 458位异常用户。将排查后的10 413位用户电信数据集聚类成3个用户簇,其中用户簇1有4 562位用户,用户簇2有3 245位用户,用户簇3有2 611位用户。利用SMOTE与Tomek组合采样方法分别对3个用户簇数据进行平衡,结果如表1所示。 表1 用户数据集平衡前后结果 由表1可知,用户簇1平衡后的用户为5954位,用户簇2平衡后的用户为4150位,用户簇3平衡后的用户为3808位。 将平衡后的电信用户前8个月的数据,分别利用换机预测模型与随机森林、Logistic回归和GBDT算法预测后2个月用户是否换机。对比用户的预测标签与实际标签,根据预测电信客户离网分类效果评价指标[15-16],预测结果如表2所示。 由表2可以看出,换机预测模型的准确率为76%,召回率为74%,F1-measure为74%,其中少数类准确率为69%,均高于随机森林、GBDT和Logistic回归等算法。 表2 不同算法的换机预测结果对比 换机预测模型的结构为通过孤立森林对数据异常值排查,使用K-Medoids聚类分簇,再对每个簇的数据使用SMOTE与Tomek处理不平衡,最后利用XGBoost训练。将换机预测模型结构分别与未采用孤立森林异常值排查,未采用K-Medoids聚类分簇和未采用SMOTE与Tomek处理不平衡的模型结构,根据预测电信客户离网分类效果评价指标进行换机预测对比,结果如表3所示。 表3 不同结构的换机预测结果对比 由表3可见,换机预测模型比未异常排查、未聚类分析和未处理不平衡的模型预测性能更佳。 基于聚类分析和XGBoost算法的换机预测模型,利用孤立森林对原始数据进行异常检测,使得换机预测模型在训练过程中不受异常点的影响。利用K-Medoids聚类法对原始用户数据精细划分为3个用户簇,采用SMOTE与Tomek组合采样对3个用户簇的数据进行平衡,最后将平衡后的数据通过XGBoost训练。实验结果表明,该换机预测模型比随机森林、Logistic回归和GBDT算法准确率高,且比未异常排查、未聚类分析和未处理不平衡的模型预测性能更佳,可较好地为电信用户提供换机服务。1.5 XGBoost训练模型
2 对比实验及结果分析
2.1 数据描述

2.2 不同算法的换机预测性能比较
2.3 不同结构模型的换机预测性能比较
3 结语
猜你喜欢
建材发展导向(2021年18期)2021-11-05 09:19:12
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
电子制作(2019年20期)2019-12-04 03:52:04
妈妈宝宝(2019年10期)2019-10-26 02:45:42
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
高中生·天天向上(2018年2期)2018-04-14 09:33:14
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
