
随机响应机制效用优化研究
2019-07-11 03:54周异辉鲁来凤吴振强
通信学报 2019年6期
周异辉,鲁来凤,吴振强,3
(1. 陕西师范大学计算机科学学院,陕西 西安 710119;2. 陕西师范大学数学与信息科学学院,陕西 西安 710119;3. 贵州大学贵州省公共大数据重点实验室,贵州 贵阳 550025)
1 引言
在大数据时代,用户隐私和数据安全已经成为人们普遍关注的热点问题。在各种隐私保护模型中,建立在严格数学理论基础上的差分隐私模型[1]能够量化随机机制对用户数据的隐私保护强度,保证统计数据库的查询结果不会受到任何单一用户数据的影响,因此成为当前隐私保护研究领域中备受关注的隐私保护模型之一。
差分隐私主要分为中心化差分隐私和本地化差分隐私,其中中心化差分隐私是数据拥有者将数据提供给数据收集者。数据发布分为交互式和非交互式2种。在交互式环境下,数据分析者向数据管理者提出查询请求,数据管理者根据查询请求对数据集进行操作,并将结果进行扰动后反馈给数据分析者,数据分析者不能看到数据集的全貌,从而保护数据集中的个体隐私。在非交互式环境下,数据管理者针对所有可能的查询,在满足差分隐私的条件下一次性发布所有查询的结果;或者数据管理者发布一个不精确的数据集,即原始数据集的“净化”版本,数据分析者可以对该版本的数据集自行进行所需的查询操作。由于中心化差分隐私存在数据分析者不可信的安全隐患,因此,近年来,本地化差分隐私备受关注。在本地化差分隐私中,数据拥有者将数据进行扰动后发给数据分析者,以抵御不可信数据收集者的隐私攻击。为保证用户信息的隐私性,苹果公司于2016年6月宣布使用本地化差分隐私方法收集用户数据[2],Google也利用本地化差分隐私技术收集用户的行为统计数据[3]。随机响应机制是 Warner[4]于 1965年提出的,现为本地化差分隐私保护技术的主要扰动机制,其主要思想是利用敏感信息的不确定性来保护数据信息,因此,本文针对随机响应机制的效用优化展开研究。
数据的隐私性和效用性是隐私保护技术中最重要的2个衡量指标,如何在隐私预算确定的条件下,寻找效用最高的差分隐私保护机制是许多学者关注的问题。不同研究背景采用不用的效用测度,Comas等[5]以噪声分布在0附近的集中程度作为评价标准;Geng等[6-8]以期望损失为效用测度,证明了阶梯型分布噪声是最优的;Holohan等[9]使用输入数据分布估计误差作为效用函数,探讨了在隐私强度保证的前提下二元随机响应机制的效用优化问题。本文主要研究的问题是在确保隐私预算的前提下,分别针对ε-差分隐私(ε-DP)和(ε,)δ-差分隐私((ε,)δ-DP)这2种隐私保护模型,研究二元随机响应机制的效用优化问题,并将其推广到多元随机响应机制。
下面举例说明本文要研究的问题。假如某校的教务处对全校师生进行问卷调查以了解其对教务管理系统的满意情况,问卷问题为“您对我校的教务管理系统是否满意”。为了保护师生的隐私,师生不必如实回答问卷调查,而是采用随机方法(比如投硬币)以某概率如实回答问卷。本文研究的问题是在保证差分隐私的前提下,以多大的概率如实回答问卷问题才能使如实回答问题的师生比例的数学期望达到最大。本文讨论的问题可抽象如下:设数据提供者的数据x来自输入字母表,经扰动后输出数据为y,属于输出字母表,这里只讨论的情形。假设利用输入与输出相同的记录占总记录比例的数学期望作为效用测度,给定隐私预算ε(和参量δ),在所有满足ε-DP(或((ε,)δ-DP))的机制中,寻求影响效用最优机制和效用最优值的相关因素,探讨效用最优机制的条件概率矩阵和最优效用值。
2 ε-DP下二元随机响应机制效用优化
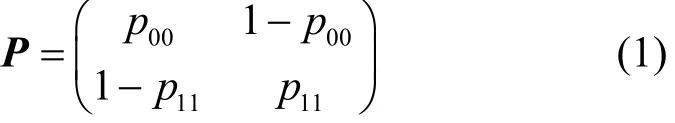
2.1 ε-DP下的效用优化模型I
设πi表示数据i(i∈{0,1})在输入数据库中的比例,则0≤πi≤1且π0+π1=1。对于离散数据,只有输出与输入相同时,数据才有价值,因此结合输入数据库的分布情况,本文用输出关于输入数据库正确率的数学期望作为效用度量,即
优化模型I表示为

约束条件为

2.2 模型求解
优化模型I为线性规划问题。由于变量只有2个,首先用图解法求解,然后用最优性判定定理进行证明,最后用Matlab软件求解验证所得结论。
2.2.1 图解法求解
图1为ε=0.1时优化模型I的可行域,两组平行直线的斜率分别为-eε和,顶点分别为和目标函数等值线的斜率为从图1可以看出5种情形,分别如下。

图1 优化模型I的可行域(ε=0.1)
故可得最优值u*与隐私预算ε和0π的函数关系为

图2为按照式(4)给出的优化模型I的最优值u*与隐私预算ε和输入分布0π的函数关系。

图2 优化模型I中最优效用值与隐私预算和输入分布的关系
2.2.2 模型Ⅰ最优性证明
将线性规划问题化为标准型
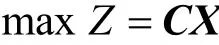
约束条件为

其中,A为m×n矩阵,秩为m。若对于选定的基将式(5)所示的问题化为典则形式(简称典式)使

定理1最优性判别定理[10]。在线性规划问题的典式中,设是对应于基B的一个基可行解,若有
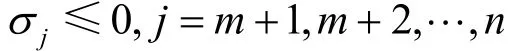
下面利用定理1证明式(4)确为优化模型I的最优值。
证明将优化模型 I化为标准型,其中,

根据定理1,有
1) 取A的1、2、3、4、7、8列作为基B1,将优化模型I化为相应的典式,得到的判别系数为


此对应于图解法的第1)情形。
2) 取矩阵A的1、2、4、6、7、8列作为基B2,将优化模型I化为相应的典式,得到的判别系数为
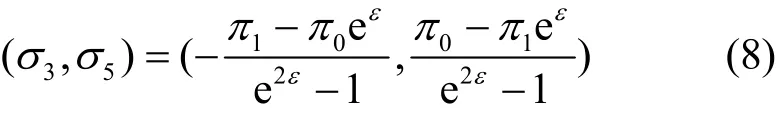

此对应于图解法的第2)情形。
3) 取矩阵A的1、2、3、5、7、8列作为基B3,将优化模型I化为相应的典式,得到的判别系数为

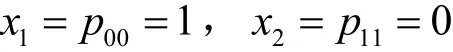
此对应于图解法的第3)情形。

则线段BC上的点对应的效用值为

此对应图解法的第4)情形。


此对应图解法的第5)情形。
证毕。
2.2.3 软件求解验证模型I最优解
求解线性规划问题一般采用单纯形法,有不少现成的数学软件。利用Matlab中的linprog命令求解模型I,并绘制最优值的图形,如图3所示,与图2对比可以发现两者是一致的。但Matlab软件只能对给定的隐私预算和输入分布给出相应的最优解,而不能给出函数关系的解析式。
2.3 模型Ⅰ数值仿真
图4为根据不同的输入数据分布情况按照式(4)给出的最优机制做出的仿真实验。比较图2和图4可以看出,仿真结果与最优值基本一致。因为效用度量是数学期望值,而仿真实验只能重复多次取平均值,所以二者不可能完全吻合。

图3 Matlab软件求解优化模型I最优值的结果
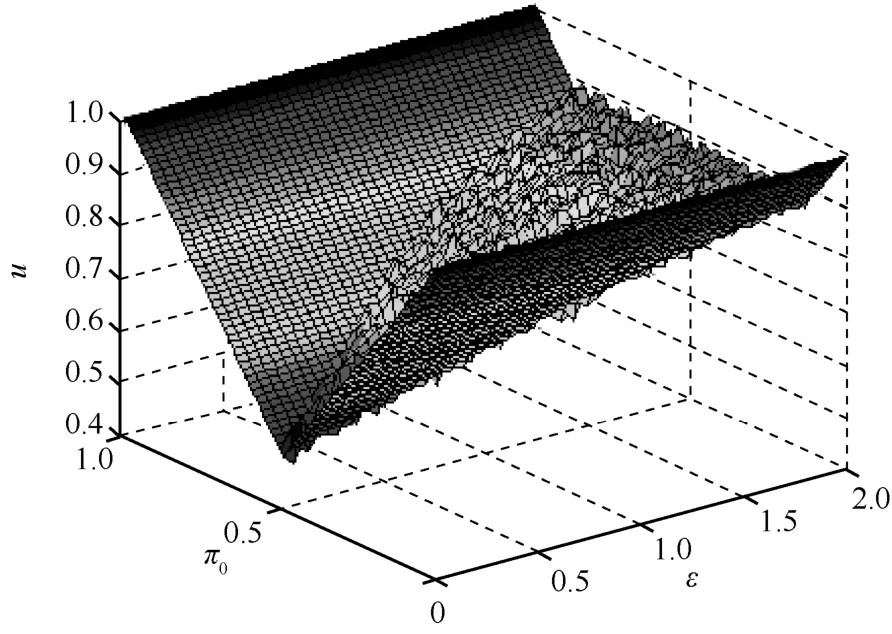
图4 优化模型I效用最优值仿真结果
从式(4)和图3及图4可以看出,给定隐私预算ε,在满足ε-差分隐私的所有机制中,效用最优机制与输入数据库中各记录所占的比例有关:如果记录 0所占比例超过则效用最优机制为即不管输入0还是1,输出总是0,效用最优值为0π;反之,如果记录0所占比例低于,则效用最优机制为即不管输入 0还是1,输出总是1,效用最优值为1-π0。以上2种情况中最优机制均为确定机制,当记录0所占比例介于和之间时,效用最优机制为即不管输入0还是1,输出值与输入值相同的概率为不同的概率为效用最优值为
3 (ε,δ)-DP下二元随机响应机制效用优化
为避免随机机制成为确定的,可以稍微放松隐私要求,采用(ε,)δ-DP模型,并比较二者的效用。
3.1 (ε,δ)-DP下的效用优化模型II
目标函数为

约束条件为

3.2 模型Ⅱ求解
3.2.1 图解法解模型Ⅱ
优化模型II可行域如图5所示,其中,ε=0.1,δ=0.2。顶点为从3种情况进行分析,具体如下。

图5 优化模型II的可行域 (ε=0.1,δ=0.2)
故最优值u*与ε、δ和0π的关系如式(15)所示,函数图像如图6所示。

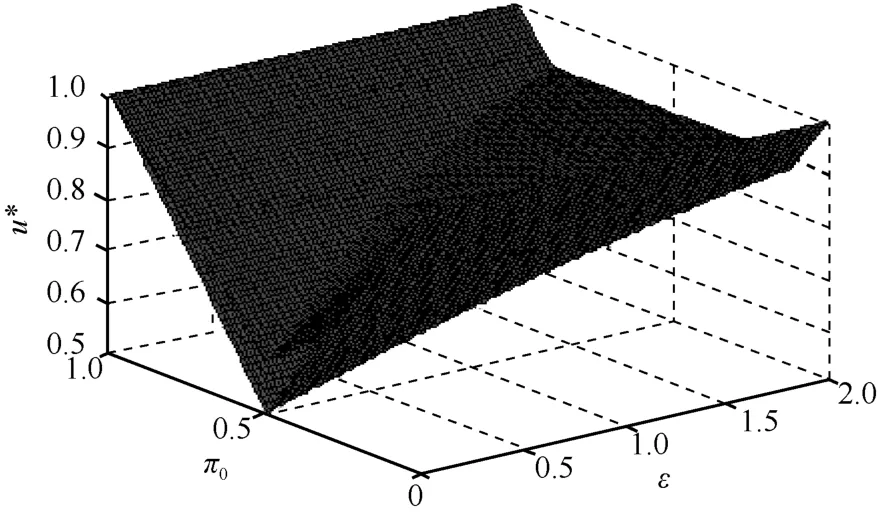
图6 优化模型II中效用最优值与隐私预算和输入分布的关系
3.2.2 模型II最优性证明
证明将模型II化为标准型,其中X、C、A与
1) 取A的1、2、3、4、7、8列作为基B1,将优化模型II化为相应的典式,得到的判别系数为
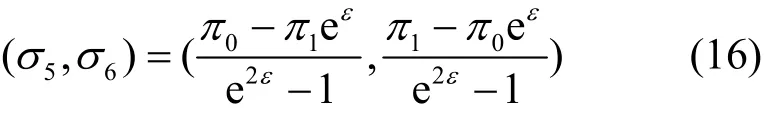

此对应于图解法的第1)情形。
2) 取矩阵A的1、2、3、4、5、8列作为基B2,得到的判别系数为


此对应于图解法的第2)种情形。
3) 取矩阵A的1、2、3、4、6、7列作为基B3,得到的判别系数为


此对应于图解法的第3)种情形。
证毕。
3.2.3 软件求解验证模型II最优解
利用Matlab中的linprog命令求解优化模型II,并绘制最优值的图形,如图7所示,与图6对比发现两者一致。

图7 Matlab软件求解优化模型II最优值结果
3.3 模型II数值仿真
图8为根据不同的输入数据分布情况按照式(15)中的最优机制做出的仿真实验。比较图6和图8可以看出,仿真结果与最优效用值一致、而且从图 8可以看出,(ε,)δ-DP避免了ε-DP中当0π足够大或足够小时,机制退化为确定机制的缺点。

图8 优化模型II最优效用值仿真结果
从式(15)和图7及图8可以看出,给定隐私预算ε和参量δ,在满足(ε,)δ-DP的所有机制中,效用最优机制与输入数据库中各记录所占的比例有关:如果记录0所占比例超过则效用最优机制为即输入0时输出总是0,输入1时,输出1的概率为δ,最优效用值为反之,如果记录 0所占比例低于,则最优效用机制为即输入 1时输出总是1,输入0时,输出是0的概率为δ,效用最优值为当记录 0所占比例介于和之间时,最优效用机制为即不管输入0还是1,输出值与输入值相同的概率为不同的概率效用最优值为
对比ε-DP和(ε,)δ-DP这2种情形可以发现,最优机制中(ε,)δ-DP情形的效用比ε-DP情形好,但会损失一些隐私保护程度。以第1节的例子为例,设全校师生共10 000名,ε=0.1,δ=0.15。用“0”表示对教务系统不满意,“1”表示对教务系统满意。假 设π0=0.2,π1=0.8。 因 为π0=0.2<,所以效用最优的ε-DP机制的设计矩阵为即所有人都回答“满意”,最优效用值为0.8。效用最优的(ε,)δ-DP机制的设计矩阵为最优效用值为 0.83。对其他比例的0π和1π,也可得到相应的结论。
4 多元本地化差分隐私效用

效用优化模型的目标函数为
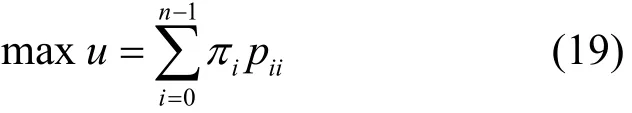
约束条件为

这里有n2个变量,n2(n-1)个差分隐私限制,n个行和为 1限制,2n个非负限制。因为,所以每一行可以保留(n-1)个变量,另一个变量用其他元素表示。比如,令这样有n(n-1)个变量,2(1)nn-个差分隐私限制,n个小于或等于 1的限制和n(n-1)个非负限制。
首先,由于变量个数比较多,不能用图解法求解。其次,由于最优性判定定理只是最优性判定的充分条件,且与基的选择有关系,只能用于检验某自变量取值是否为最优解。随着元数的增加,自变量个数也越来越多,导致给出最优效用值与差分隐私预算及输入数据集分布的关系越来越难。再者,虽然各种数学软件求解线性规划问题很容易,但是只是针对给定的系数,而不能得到最优值与隐私预算及数据分布间关系的解析式。
然而,线性规划问题的最优解在可行域的极值点处取得,因此对差分隐私可行域极值点的研究是广大学者研究的重点[11-12]。本文采用极值点法对优化模型I求解。
证明文献[11]中的结论:如果n元差分隐私机制P中存在,则第j列元素全为 0,换句话说,差分隐私机制的列向量要么全部为 0,要么全部为非0。文献[12]中的结论:n元差分隐私机制恰有一个非0列的极值点为只有一列全部为1其他元素全部为0的矩阵;恰有2个非0列的极值点,机制中非0列元素为或。根据上述结论可得,二元本地化差分隐私可行域的所有极值点为时,对应的效用值为和。因为,所以,因此只需比较0π、的大小,具体如下。
证毕。
5 结束语
本文在大数据环境中隐私泄露严重、隐私保护需求日益增强的背景下,针对差分隐私中随机响应机制的效用优化问题展开研究。首先研究了广义二元随机响应机制的效用优化问题,分别针对ε-DP和(ε,)δ-DP情形建立效用优化模型并求解,得到了最优解与隐私预算和输入数据分布的解析式,给出了相应的最优机制,并通过数值仿真验证所得结论。针对多元广义差分隐私的效用优化问题展开讨论,用差分隐私可行域的极值点去研究最优效用,其中多元随机响应机制的效用最优值与输入分布和隐私预算间的函数表达式有待进一步研究。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
建材发展导向(2021年7期)2021-07-16
南宁师范大学学报(自然科学版)(2021年1期)2021-04-27
中国药学药品知识仓库(2021年18期)2021-02-28
少儿美术(2019年7期)2019-12-14
冰雪运动(2018年3期)2018-12-29
新高考·高二数学(2017年8期)2018-03-13
南北桥(2016年12期)2017-01-10
福建中学数学(2016年9期)2016-12-14
科技与创新(2016年16期)2016-09-23
