
基于灰色模型的全国肺结核疫情预测及分析
2019-07-11 06:45:30薛亚妮张梅李存龙
中国防痨杂志 2019年7期
薛亚妮 张梅 李存龙
结核病是一种慢性传染病,若能及时发现并进行合理治疗,大多数患者可获得临床治愈[1-3]。2016年中国疾病预防控制中心共报告法定传染病发病6 944 240例,死亡18 237例,其中肺结核发病836 200例,较上一年减少27 779例[4-8]。但由于传染病具有潜伏期和可能产生大面积人群感染的特性,我国肺结核防治工作仍然面临严峻形势,提前预测肺结核的发病数对肺结核的防治工作将大有助益。本研究利用灰色预测的方法,对未来几年全国肺结核疫情相关数据进行预测,并进一步利用自组织映射(self organizing maps,SOM)神经网络方法依据发病率将全国及31个省(自治区、直辖市;不包含我国台湾、香港和澳门地区,下同)聚类成4个不同层次,为肺结核防治工作提供相关数据支持。
资料和方法
一、资料来源
选取2008—2015年全国和各省(自治区、直辖市)的肺结核疫情相关数据。数据来源于《中国疾病预防控制信息系统》。结果见表1、2。
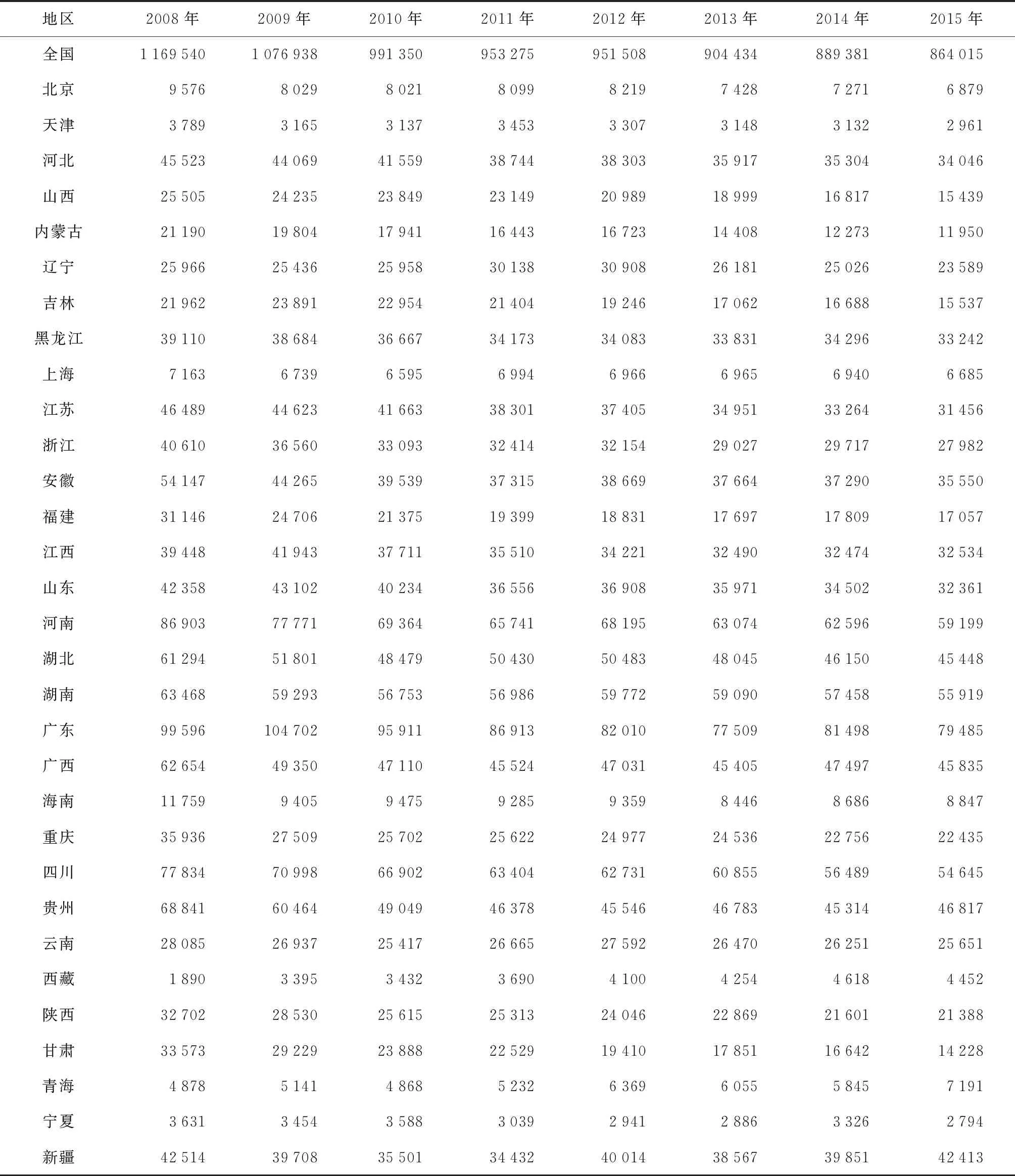
表1 全国及各省(自治区、直辖市)2008—2015年肺结核报告发病情况(例)

表2 全国及各省(自治区、直辖市)2008—2015年肺结核报告发病率(/10万)
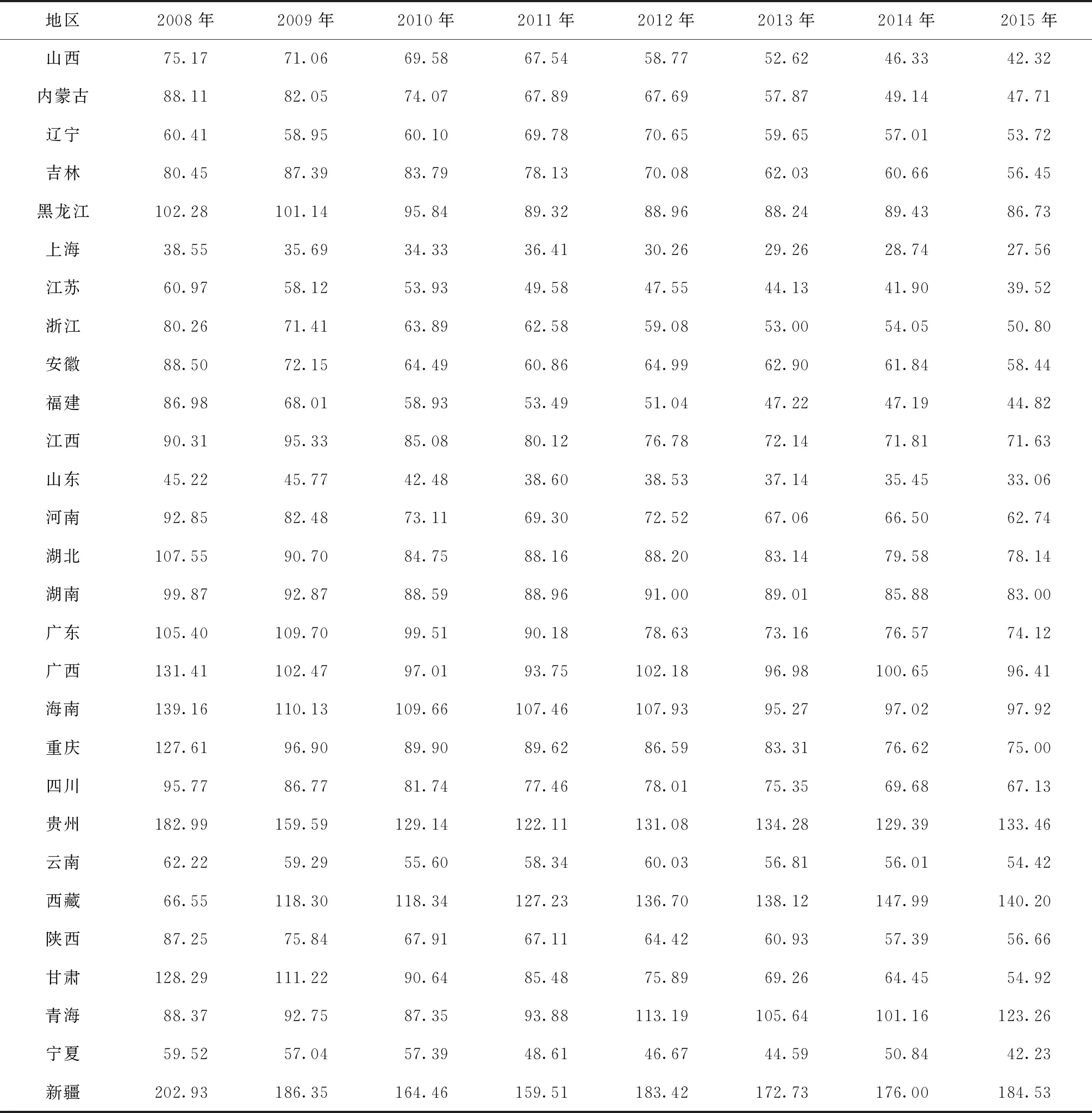
续表2
二、实验方法
(一)灰色预测
灰色预测是用灰色模型GM(1,1)来进行定量分析的,GM(1,1)模型适合具有较强的指数规律的数列,可有效描述单调的变化过程[9-11]。已知元素序列数据:
X(0)=x(0)(1),x(0)(2),…,x(0)(n)
(1)
其中,X(0)为初始元素序列数据,x(0)(k), (k=1,…,n)代表初始序列中的数据,k代表数据序号,n为数据总个数。
做一次累加生成运算得到如下序列:
X(1)=x(1)(1),x(1)(2),…,x(1)(n)
(2)
X(1)为一次累加生成后的元素序列数据,x(1)(k),(k=1,…,n)代表一次累加生成后序列中的数据,其中,
(3)
令Z(1)为X(1)的紧邻均值生成序列,z为Z序列中的变量:
Z(1)=z(1)(2),z(1)(3),…,z(1)(n)
(4)
其中,
z(1)(k)=0.5x(1)(k)+0.5x(1)(k-1)
(5)
建立GM(1,1)的灰微分方程模型为:
x(0)(k)+az(1)(k)=b
(6)
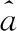
(7)
其中,
(8)
再建立灰色微分方程的白化方程(也叫影子方程):
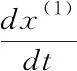
(9)
白化方程的解(也叫时间响应函数)为:
(10)
那么相应的GM(1,1)灰色微分方程的时间响应序列为:
(11)
取x(1)(0)=x(0)(1),则:
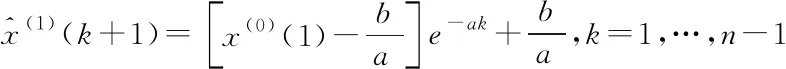
(12)
即为预测方程。
(二)SOM神经网络
SOM神经网络是聚类分析的一种经典方法,可以通过将任意维度的输入向量映射到一维或二维空间中,将相似的样本映射到同一个二维输出节点上。通常SOM神经网络的具体实现过程可概括如下[12]:
首先进行网络初始化。用较小的随机数初始化输入层和竞争层之间的连接权值,且设定竞争层的神经元个数H。训练时间计数为t=0。
然后给定输入向量X=(x1,x2,…,xn),m表示样本的维度是m维。
接着计算输入向量X和所有竞争层神经元所连的权向量的距离(欧氏距离)。其中公式(12)是计算X和第j个竞争层神经元所连的权向量的欧氏距离。
(13)
wij为输入层i神经元和竞争层j神经元之间的连接权值。所有距离中最小的距离竞争层神经元获胜。分别调节获胜神经元和获胜神经周围神经元与输入层的连接权值。公式(14)给出权值更新:
Δwij=η(t)(xi(t)-wij)
(14)
η(t)为t时刻的权重调整的学习率,一般可以设置η=1/t。如果样本没有训练完毕,则重复输入向量循环。若样本训练完毕,则SOM网络建立成功。
结 果
一、模型参数
利用表1和表2中的数据及Python编写算法,分别得出全国和其他31个省(自治区、直辖市)的发病数和发病率的灰色预测模型参数(注:因地区过多,此处仅列出全国的预测模型,其他地区预测模型通过参数方式列出,如表3所示):
发病数(例):
发病率(/10万):
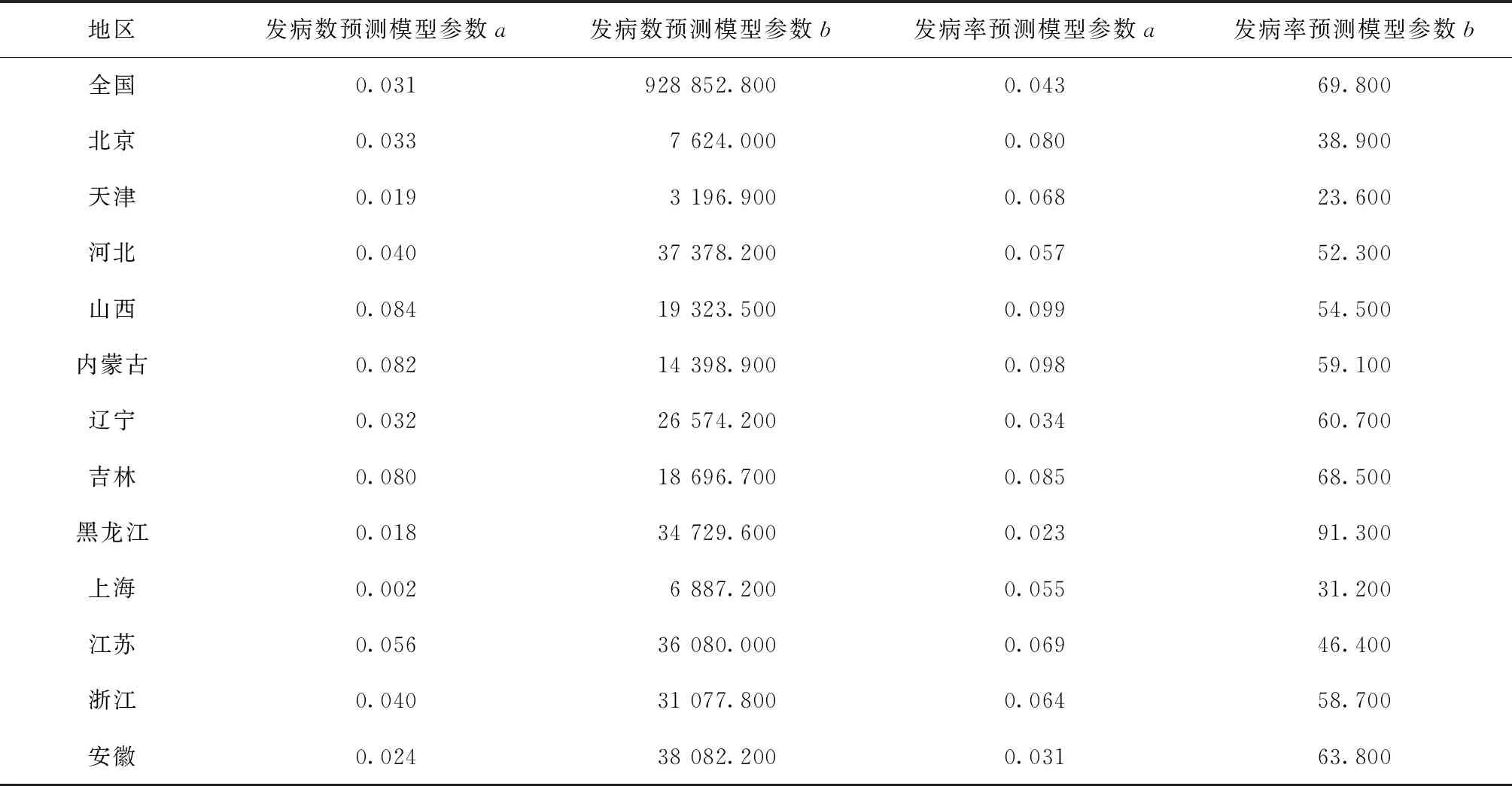
表3 全国及各省(自治区、直辖市)预测模型参数表

续表3
注a和b为通过历史数据拟合得到的灰色预测模型参数,其中a为发展系数,b为灰色作用量,如公式(6)所述
二、精度检验
采用后验差检验的方法对得到的灰色预测模型进行精度检验。后验差检验是按照精度检验c(后验差)和p(小概率误差)两个指标进行检验。记原始数列及残差数列的方差分别是S12和S22,然后用下式计算后验差c及小概率误差p。
(13)
根据表4判定模型的精度[7]。
经过模型拟合计算后验差c为0.0713,小概率误差p为1,根据表中判定标准,模型的拟合效果为好,随后进行外推预测。

表4 灰色预测模型精度表
三、外推预测
利用GM(1,1)模型,以2008—2015年共8年的数据作为已知数据序列,预测2016—2021年共6年的全国肺结核发病数和发病率。如表5和表6所示。
四、聚类分析
通过预测2016—2021年全国及31个省(自治区、直辖市)的肺结核发病率时间轨迹序列,并将预测的发病率时间轨迹序列输入到SOM聚类模型中,设置聚类的类别数为4,SOM聚类模型将自动地组织特征进行训练并将32个时间轨迹序列聚为4类。分别计算4类的类中心序列(类中心序列表示计算一个类所包含的所有序列的平均序列)。通过比较4类的类中心序列的差异,判断SOM聚类的表现力。表7分别记录了由SOM聚类出的第1~4类中包含的地区编号和地区名。由表7可知,通过SOM方法将全国及31个省(自治区、直辖市)的肺结核发病率时间轨迹聚为4类,用类中心来分析4类的聚类效果和类与类之间的差异(图1)。
在所有的4类中,第1类类中心序列均高于其他3类,包含青海、西藏和新疆,其发病率轨迹具有很强的相似性,且这3个地区的发病率轨迹值普遍高于其他3类。第2类类中心序列低于第1类,位居第二高的水平,且与其他3类类中心有一定差异性,包括黑龙江、湖南、广西、海南和贵州等省(自治区)。第3类类中心序列异于其他3类,包括辽宁、安徽、江西、河南、湖北、广东、重庆、四川、云南和陕西等,类中心序列略低于第2类。第4类类中心序列普遍低于50/10万,但也异于其他3类,包括北京、天津、河北、山西、内蒙古、吉林、上海、江苏、浙江、福建、山东、甘肃和宁夏等省(自治区、直辖市)。

表6 全国及各省(自治区、直辖市)2016—2021年肺结核发病率预测结果(/10万)
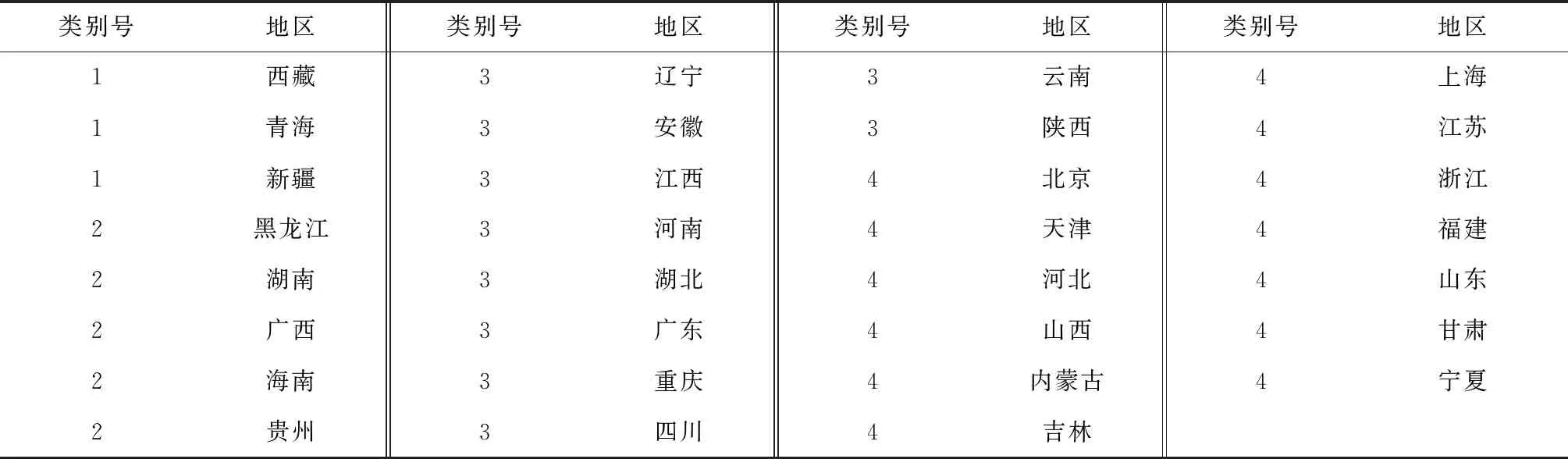
表7 全国各省(自治区、直辖市)聚类分类
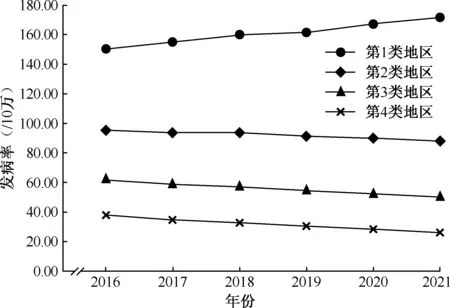
各个点表示各类地区发病率的均值;本图根据表6、7数据和内容绘制图1 全国各省(自治区、直辖市)聚类分析第1~4类类中心序列发病率轨迹
讨 论
2008—2016年期间,全国的肺结核发病情况呈现出在波动中缓慢下降的趋势,其趋势与各省(自治区、直辖市)的预测趋势大致相同[13-17],2009—2010年处于死亡数和死亡率的高峰期,随后缓慢下降,但2009—2010年的发病率相较于2008年是下降的,整个肺结核疫情的情况处于较为平稳的态势。根据灰色预测结果,未来几年内肺结核的发病情况处于缓慢下降的态势,这与逐渐发展的医学技术和人们健康意识的提高有关,也与人口的流动性有很大的关系。随着社会的发展,未来人口的流动性会日趋升高,这也给肺结核的防治工作提出了新的挑战。
通过聚类分析结果显示,在所有的4类中,第1类类中心序列均高于其他三类,且趋势异于其他3类中心序列,这意味着第1类包含的青海、西藏和新疆的发病率轨迹具有很强的相似性,并且这3个地区的发病率轨迹值普遍高于其他3类,所以这3个地区应该给予重点对待。第2类类中心序列低于第1类,位居第二高的水平,且与其他3类类中心有明显的差异性,说明第2类包含的地区(黑龙江、湖南、广西、海南和贵州)具有相似的发病率时间轨迹,并应该给予足够的相同水平的防治重视和卫生资源。第3类类中心序列略低于第2类,因此可以给予第3类地区(辽宁、安徽、江西、河南、湖北、广东、重庆、四川、云南和陕西)略低于第2类地区的防治重视和卫生资源。第4类类中心序列普遍低于50/10万,以此可知第4类包含的地区(北京、天津、河北、山西、内蒙古、吉林、上海、江苏、浙江、福建、山东、甘肃和宁夏)发病率时间轨迹具有较高的相似性,可以制订一般性防治措施。
灰色预测方法作为一种数据处理的预测方法,不需要大量样本,样本不需要有规律性分布,计算工作量小,可以充分利用最少的信息来进行预测,但由于数据的局限性,影响肺结核疫情的数据肯定是多样和复杂的。因此,基于单一的病情数据和历史数据对病情的预测,也必然存在局限性,所以,在数据和其他条件允许的情况下,尽可能综合考虑其他因素,如气候条件、人口流动性、医疗条件等,运用多种组合方法[18],更加准确地预测肺结核疫情的变化情况,为国家对疫情的防治提供有效决策和数据支撑。
志谢延安大学医学院王兴宁老师对本研究数据统计方面进行了悉心指导和帮助。
猜你喜欢
前进(2023年12期)2023-12-20 08:52:22
小学生学习指导(低年级)(2020年3期)2020-06-02 08:50:40
伙伴(2019年7期)2019-08-13 06:40:49
中国财政年鉴(2018年0期)2018-07-08 08:12:14
中国财政年鉴(2018年0期)2018-07-08 08:12:14
中国铸造装备与技术(2017年3期)2017-06-21 11:33:35
Coco薇(2017年2期)2017-04-25 17:59:38
Coco薇(2017年2期)2017-04-25 17:57:49
中国财政年鉴(2016年0期)2016-06-05 15:23:30
为了孩子(3~7岁)(2016年8期)2016-05-14 09:06:17
